







目录
走进语言的微观世界,了解Token在自然语言处理中的作用。
什么是Token
在人工智能和计算机语言处理领域中,理解和生成人类的自然语言一直是一项极具挑战的任务。
随着技术的发展,我们已经能够设计出复杂的算法和模型,如大型语言模型(LLM),以模拟人类的语言理解和生成过程。
作为这一切的基础,“Token”扮演着至关重要的角色,它是信息处理的最小单位,是构建这些高度复杂系统的基石。
想象一下,语言就像是一个巨大的、连续的信息流,信息在其中自由流动、在不同的系统、计算机之间奔腾流淌。
如果我们要让机器理解这个信息流,就需要某种方式来“量化”或“切分”这个流,使得机器能够抓住、分析和重新组合这些信息。
这就是Token发挥作用的地方。Token化的过程,可以比作是将信息流切割成一系列可管理的小块,每个小块都携带着特定的意义。这些小块,或者说Token,可以是单词、短语、符号或任何语言的基本单位,根据处理的需要而定。
在这个框架下,Token不仅仅是数据处理的技术手段,它也是一种理解语言结构和意义的方法。
通过将连续的语言流转化为一系列离散的Token,计算机系统可以更容易地模拟人类的语言处理机制,包括语法分析、意义理解、情感分析等等。
也就是说这种方法并不是简单将信息流切成小块,分而治之,更为重要的是它为机器提供了一种以接近人类理解语言的方式来处理和生成语言的途径。
从这个角度来看,Token不仅是信息处理的基本单位,更是连接人类语言与机器处理能力之间的桥梁。

Token化的方法
Token化的方法多种多样,包括基于规则的方法和基于机器学习的方法。
基于规则的方法
基于规则的Token化方法依靠一套预定义的规则来识别和分割文本中的单词、短语或其他语言单位。这些规则通常包括标点符号、空格、特定字符的使用等,用来界定Token的边界。
一个典型的例子是使用空格和标点符号来分割英语文本中的单词。
例如我们有一个简单的规则:使用空格分割单词,使用标点符号来标识句子的结束。这是英语及许多使用拉丁字母系统的语言中常见的Token化方法。
假设我们有以下的句子:
Hello, world! This is an example of tokenization.
根据我们的规则,我们首先识别空格和标点符号。在这个例子中,逗号(,)和句号(.)用来界定句子的结束,而空格用来分割单词。
Token化过程
-
识别标点符号和空格:首先,我们按照空格分割句子,得到一系列单词和标点符号的组合。同时,我们也识别出句子结束的标点符号(逗号和句号)。
-
分割单词:基于空格和标点符号的位置,我们可以将句子分割成以下的Token:
-
Hello
-
,
-
world
-
!
-
This
-
is
-
an
-
example
-
of
-
tokenization
-
.
-
通过这个过程,我们将原始的文本字符串分割成了一系列更小的单元,每个单元都是处理语言的基本单位。
通过简单的分词规则将复杂的句子结构简化为易于管理的Token,为深入的语言分析奠定基础。
基于机器学习的方法
基于机器学习的方法,如Byte-Pair Encoding, BPE或WordPiece,通过学习文本数据来动态确定Token的边界,这种方法在处理多样化和复杂语言时表现更佳。
Byte-Pair Encoding(BPE)是一种流行且高效的文本Token化技术,它在近年来被广泛应用于各种NLP任务中,尤其是在大型语言模型的训练和生成任务上。
BPE的基本思想源自于数据压缩领域,它通过迭代地合并频繁出现的字符对来减少整个数据集中的不同字符对的总数。
在NLP中,这种方法被用来识别和合并文本中频繁出现的字符序列,从而有效地减少了模型需要处理的Token的数量,同时保留了文本的核心语义信息。
BPE的工作过程可以分为以下几个步骤:
-
准备阶段:将文本分割成基础的字符单位,例如,将单词分割为字符,每个字符作为初始的Token。
-
统计阶段:统计所有相邻字符对(或Token对)的出现频率。
-
合并阶段:选择最频繁出现的字符对,将它们合并为一个新的Token。这个新的Token会被添加到词汇表中。
-
迭代重复:重复统计和合并步骤,直到达到预定的Token数量或无法进一步合并为止。
我们看一个BPE的例子。假设我们有一个文本:"aaabdaaabac",我们希望使用BPE对其进行Token化。下面是BPE操作的简化示例:
-
初始分割:
-
初始Token:a, a, a, b, d, a, a, a, b, a, c
-
-
第一次迭代:
-
统计发现"aa"是最频繁的字符对。
-
合并"aa"为一个新Token:"A"(假设"A"代表"aa")。
-
新的Token序列:A, a, b, d, A, a, b, a, c
-
-
第二次迭代:
-
此时,"Aa"成为一个频繁的序列。
-
合并"Aa"为一个新Token:"B"(假设"B"代表"Aa")。
-
新的Token序列:B, b, d, B, b, a, c
-
-
继续迭代,直到满足特定条件或无法进一步合并。
通过这个过程,原始的字符序列被有效地压缩成了较少的Token,同时保留了原始文本的核心结构和信息。这种方法特别适用于处理大规模文本数据,它可以显著减少模型的复杂性,提高处理效率和性能。
如果我们把上面的文本换成一个语言序列,如大量的文章,这个过程也是类似的。例如我们的句子是:"it is essential to process natural language data efficiently with algorithms."
首先初始分割,将句子按字符进行分割,包括空格。
第一次迭代中,将统计所有相邻字符对的出现频率。在这个例子中,考虑到所有字符对的出现频率,假设"a", "l"是最频繁出现的字符对之一,因为它们出现在essential、natural和algorithms之中。为了简化,我们先选择将"a", "l" "合并为一个新Token,例如用"AL"代表。
更新Token序列后,第二次迭代再次统计频率。
继续这个过程,每次选择当前最频繁的字符对进行合并。这样的选择取决于文本的内容和已经进行的合并。
最终,通过BPE的迭代合并过程,原始的长句子被逐步转换成包含少量复合Token的序列,既减少了唯一Token的数量,也保留了文本的主要结构和意义。
这种方法不仅提高了文本处理的效率,而且通过减少Token的数量来简化了模型的训练和推理过程,是提升NLP任务性能的关键技术之一。
Tiktoken
TikToken是OpenAI开源的一个快速的BPE(Byte Pair Encoding)分词工具,用于OpenAI的多种模型。
我们上面介绍过:BPE的核心思想是将常见的字符或字符序列合并为单个Token,这个过程是迭代进行的,直到达到预设的Token数量或无法进一步合并为止。
这个算法的Github地址为:https://github.com/openai/tiktoken。
具体而言,TikToken又支持的三种编码(cl100k_base、p50k_base和r50k_base)主要用于不同的OpenAI模型,它们的区别主要在于模型的应用和编码的规则。
-
cl100k_base:这种编码被用于gpt-4、gpt-3.5-turbo、text-embedding-ada-002、text-embedding-3-small和text-embedding-3-large等模型。
-
p50k_base:这种编码被用于Codex模型、text-davinci-002和text-davinci-003等模型。
-
r50k_base(或gpt2):这种编码被用于GPT-3模型,如davinci等。r50k_base和p50k_base在非代码应用中,它们通常会给出相同的tokens。
如果好奇Tiktoken到底是如何编码的,可以访问https://platform.openai.com/tokenizer。
我们演示几个例子,先看一个在GTP-4中汉字的token化例子,我们给出的句子是:“清晨第一缕阳光”。
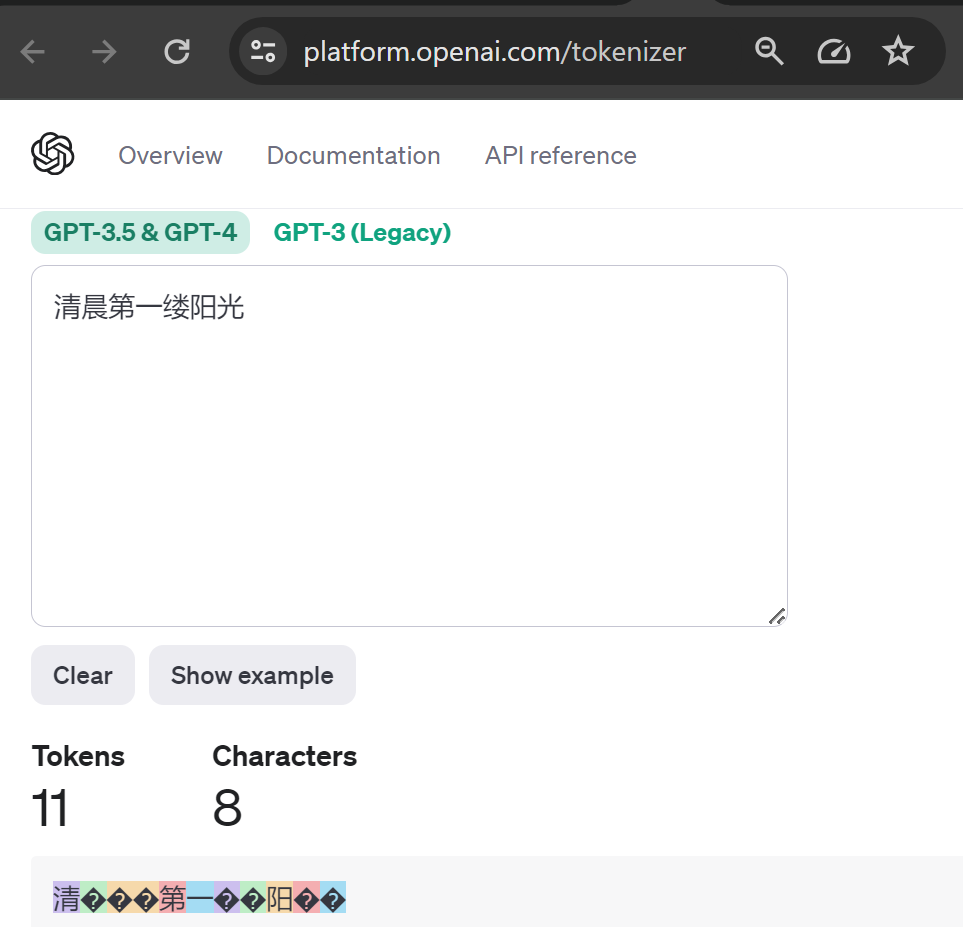
在上面例子中,“清”是一个token,“晨”则被作为3个token。整个句子一共被分成11个token。
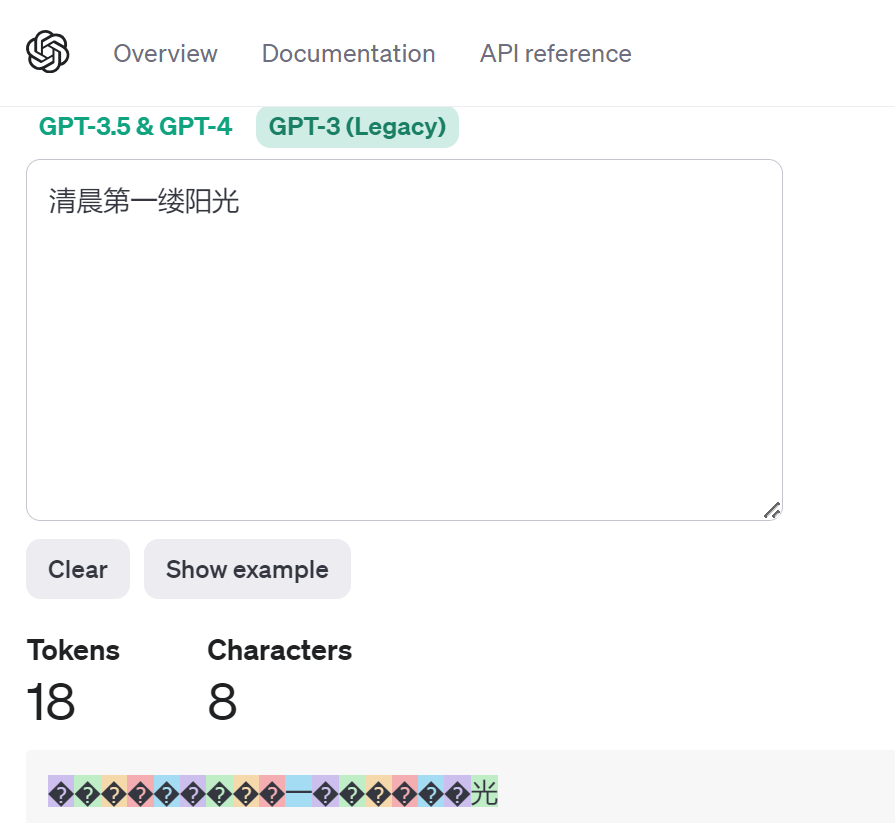
在GTP-3中,这一段汉字则被分割成18个token。除了“一”和“光”,其他汉字都被拆分成多个token。
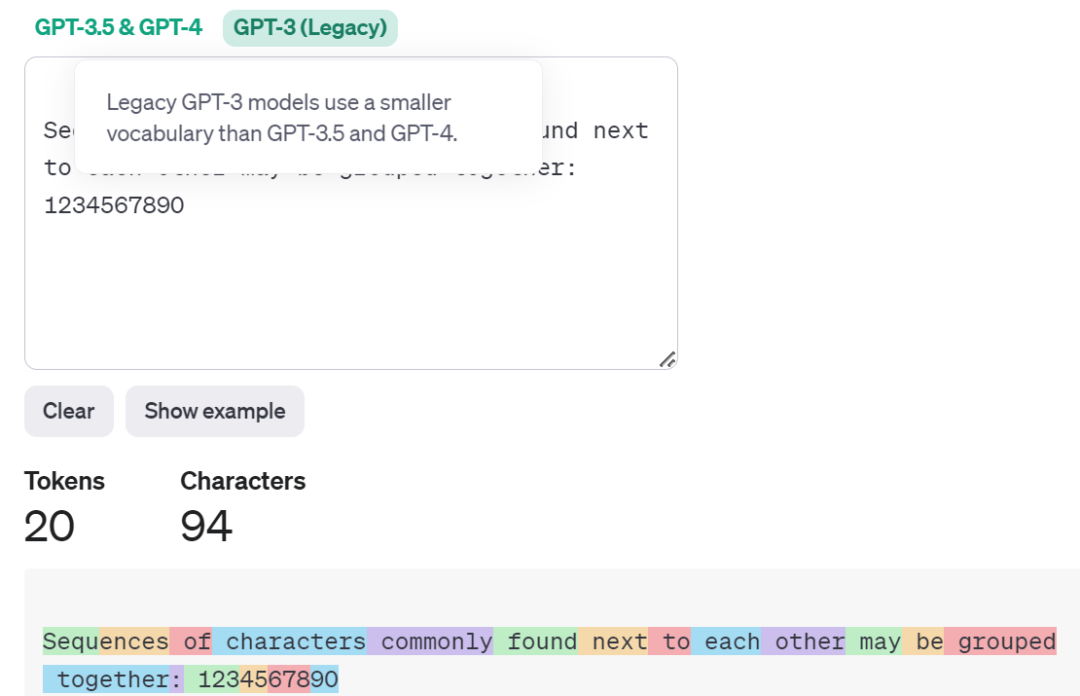
下面是一个英文句子的例子: “Sequences of characters commonly found next to each other may be grouped together: 1234567890”。
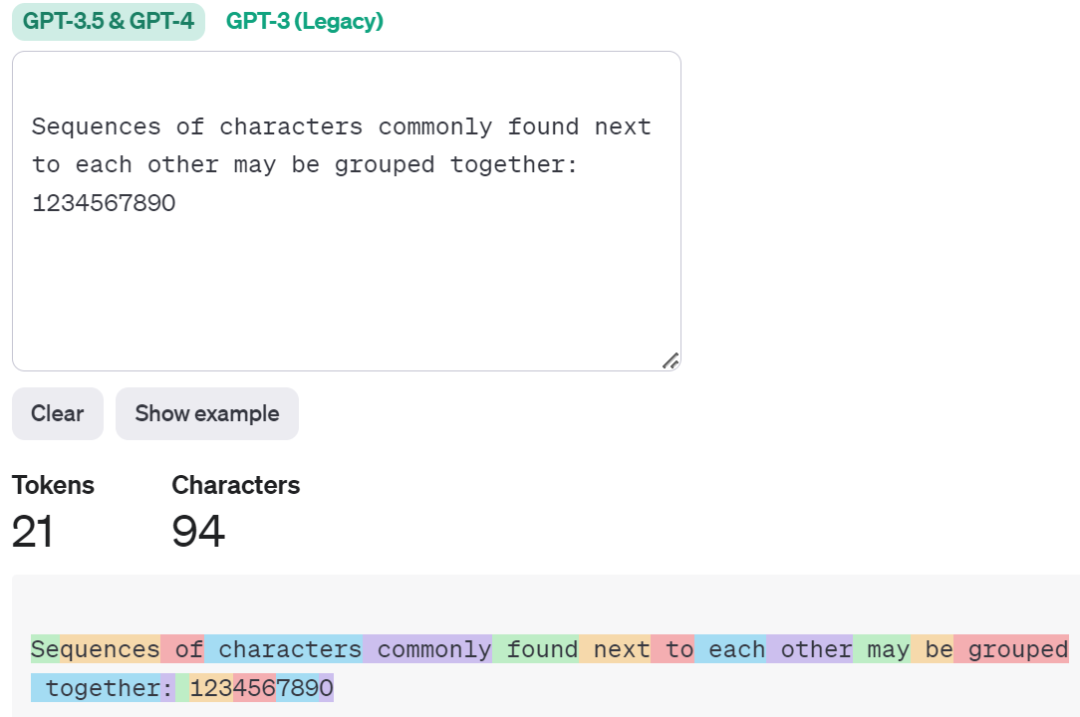
可以看到Sequences被分拆为两个token。
Token还是OpenAI收费的依据
OpenAI API的收费是基于输入和输出的token数量。既包括发送给API的tokens(例如,问题或提示),又包括API返回的tokens(例如,生成的文本或答案)。
具体的收费标准为每1000个token收取一定的费用。具体的价格会根据模型和使用的API而不同。
例如下面为GTP-4 OpenAI API 收费的价格。

对于图像模型,如gpt-4-1106-vision-preview,其收费方式也是按照token的数量来计算的。在处理图像时,模型会将图像转换为一系列的tokens,然后对这些tokens进行处理。因此,处理的图像的大小和复杂度可能会影响到token的数量,从而影响到费用。
结语
Token在构建和优化大型语言模型(LLM)的过程中起着核心作用。通过细致地将复杂的语言结构拆解为更小、更易于管理的单元,LLM能够以更高的效率和精度处理和理解自然语言数据。
这一过程不仅提高了模型的性能,还增强了模型对语言多样性的适应能力,从而使得机器能够更好地完成诸如文本理解、生成和翻译等任务。
在本文中,我们还探索了OpenAI提供的Token化工具——TikToken,并通过具体的例子展示了它是如何应用于不同语言的Token化过程中的。
感谢大家的阅读!
















 635
635











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











