







1.导入需要的库
import numpy as np
import pandas as pd
2.导入数据集
dataset = pd.read_csv('Data.csv')
X = dataset.iloc[ : , :-1].values # 该values()方法返回一个视图对象,该对象显示字典中所有值的列表。
Y = dataset.iloc[ : , 3].values
loc是根据dataframe的具体标签选取列,而iloc是根据标签所在的位置,从0开始计数。
dataset.iloc[行,列]
[a] 第a+1行 or 列
[:] 表示选取整行或整列
[0 : 2] 表示选取第0行到第二行,这里的0:2相当于[0,2)左闭右开,2是不在范围之内的。
# 行
data.iloc[0] # 数据第一行
data.iloc[1] # 数据第二行
data.iloc[-1] # 数据最后一行
# 列
data.iloc[:,0] # 数据第一列
data.iloc[:,1] # 数据第二列
data.iloc[:,-1] # 数据最后一列
# 同时选择多行多列
data.iloc[0:5] # 数据前五行 data.iloc[0:5]等同于data.iloc[:5]
data.iloc[:, 0:2] # 数据前两列
data.iloc[[0,3,6,24], [0,5,6]] # 第1、4、7、25行+第1、6、7列
data.iloc[0:5, 5:8] # 数据前5行和第6、7、8列
3.处理丢失的数据
from sklearn.impute import SimpleImputer
imputer = SimpleImputer(missing_values=np.nan, strategy="mean")
imputer = imputer.fit(X[:, 1:3])
X[:, 1:3] = imputer.transform(X[:, 1:3])
函数用法:

函数输入参数:
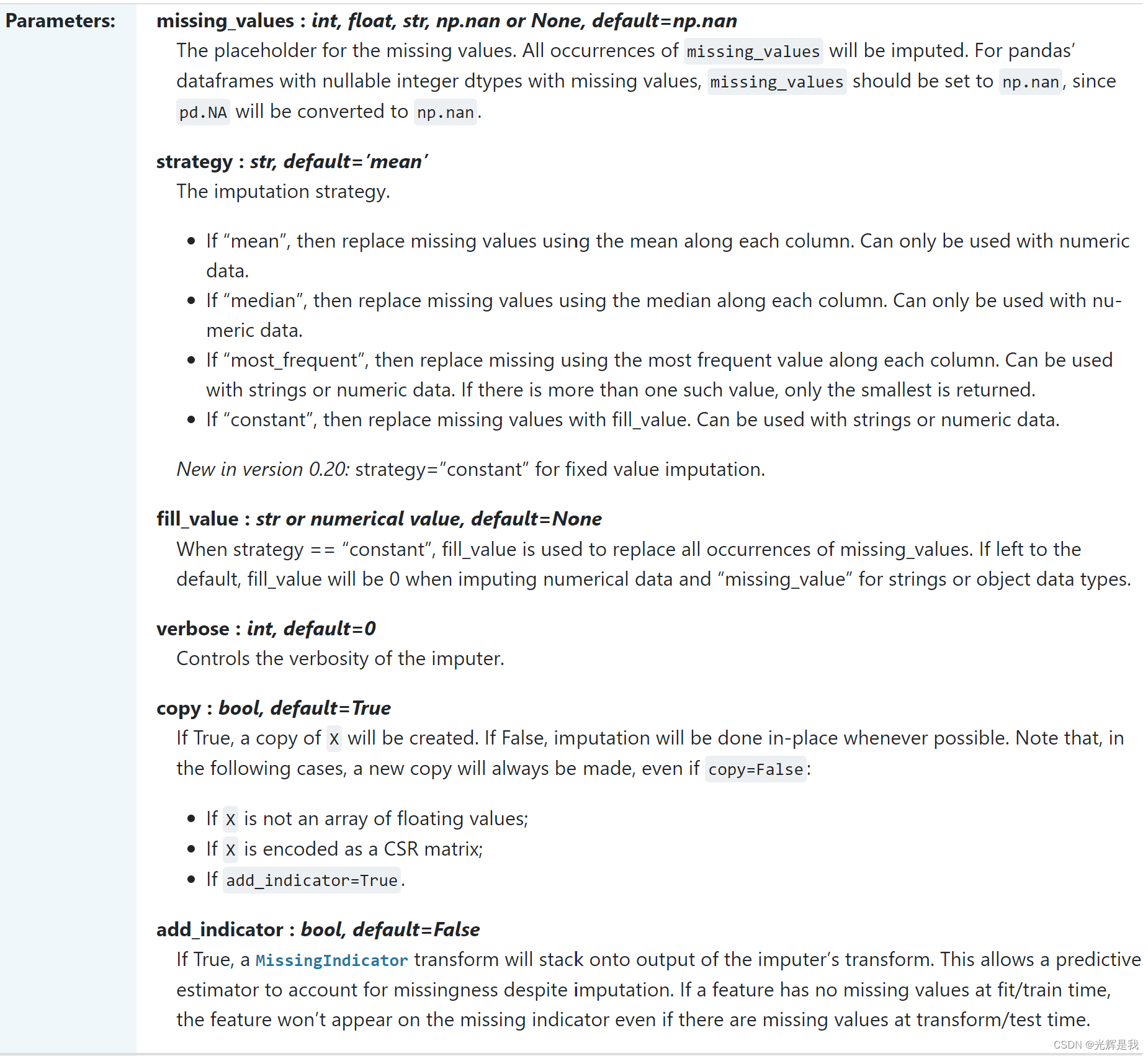

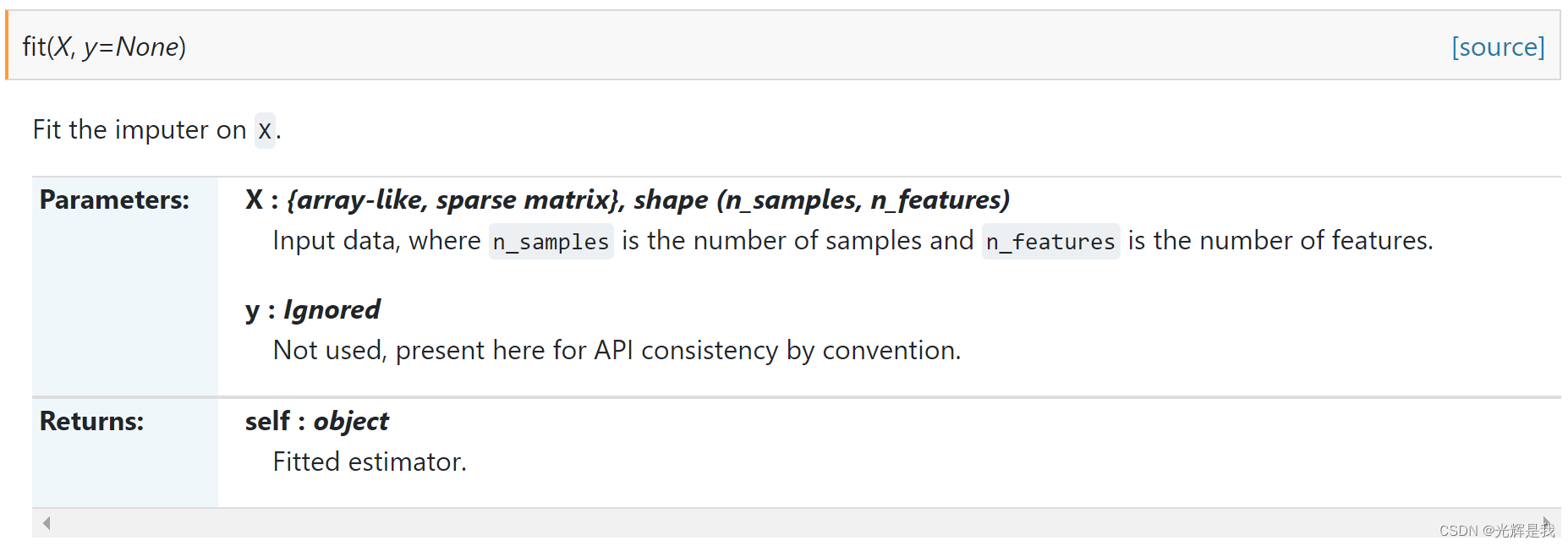

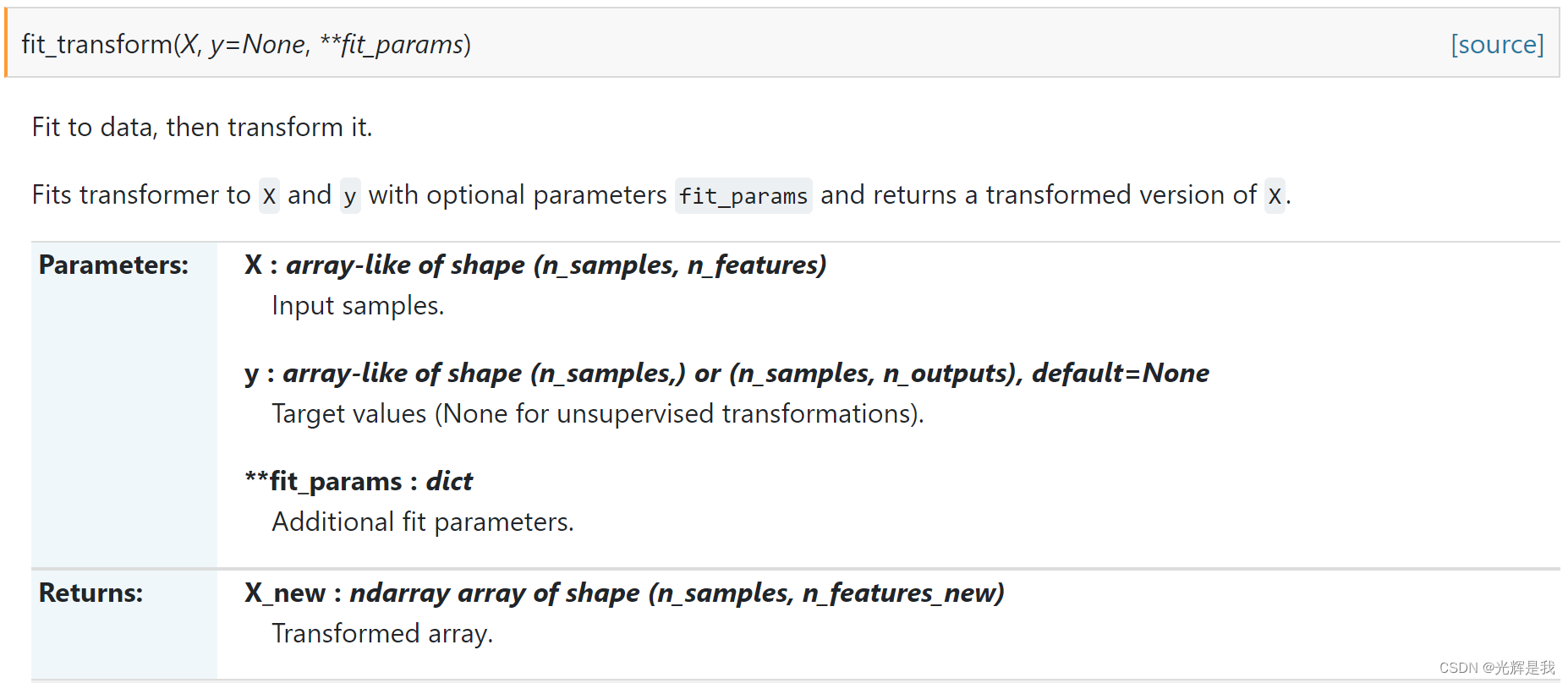
SimpleImputer 例子:

4.解析分类数据
from sklearn.preprocessing import LabelEncoder, OneHotEncoder
labelencoder_X = LabelEncoder()
X[:, 0] = labelencoder_X.fit_transform(X[:, 0])
# 创建虚拟变量
from sklearn.compose import ColumnTransformer
ct = ColumnTransformer([('encoder', OneHotEncoder(), [0])], remainder='passthrough')
# 默认情况下,从数据集中删除任何未在“转换器”列表中指定的列;这可以通过设置“remainder”参数来改变。
# 设置remainder='passthrough'将意味着所有未在“转换器”列表中指定的列将不经转换直接通过,而不是被丢弃。
X = ct.fit_transform(X)
labelencoder_Y = LabelEncoder()
Y = labelencoder_Y.fit_transform(Y)
sklearn.preprocessing.LabelEncoder
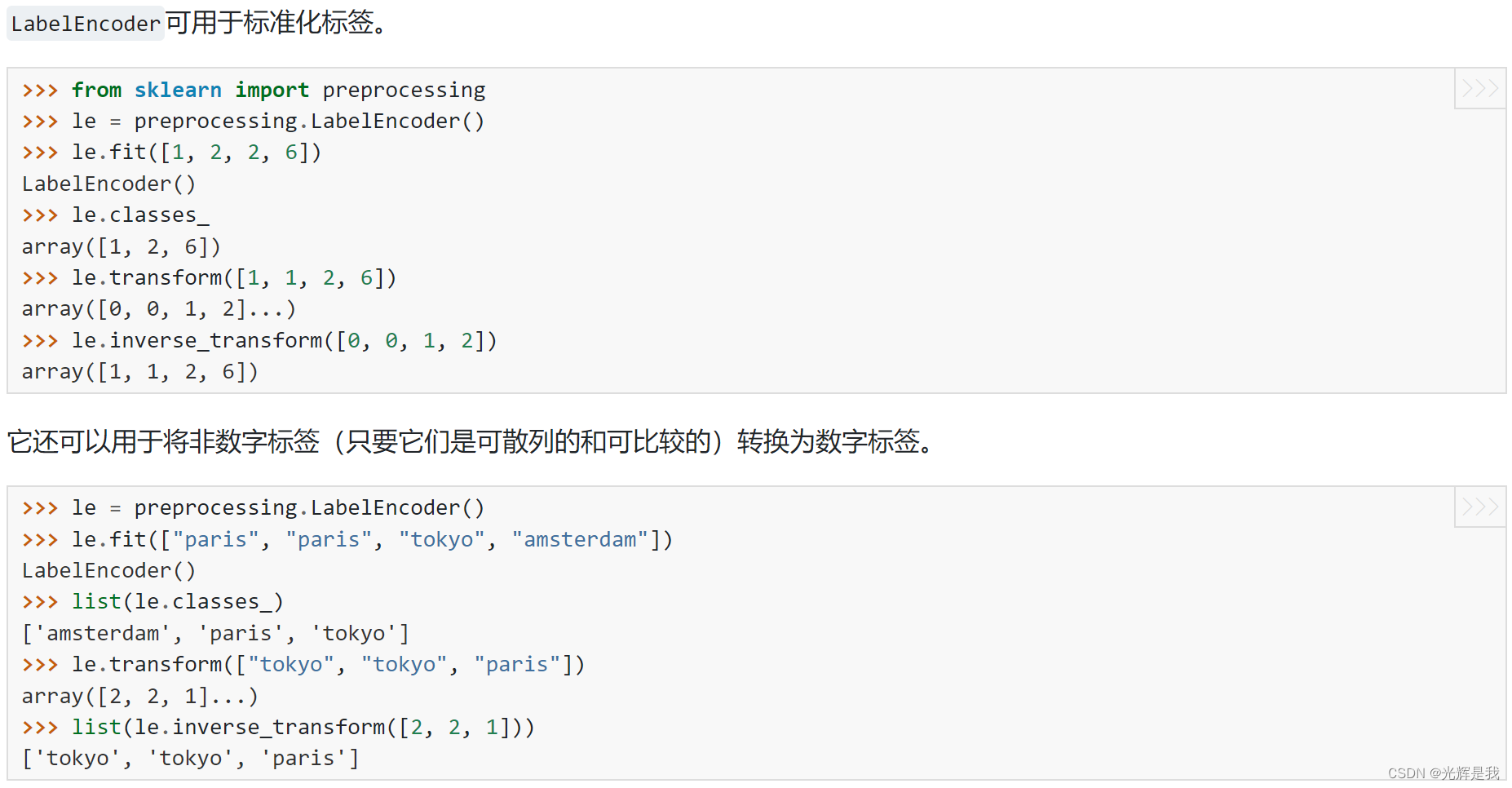
inverse_transform(y) 将标签转换回原始编码。


使用 SciKit 中的 ColumnTransformer 代替 LabelEncoding 和 OneHotEncoding 进行机器学习中的数据预处理


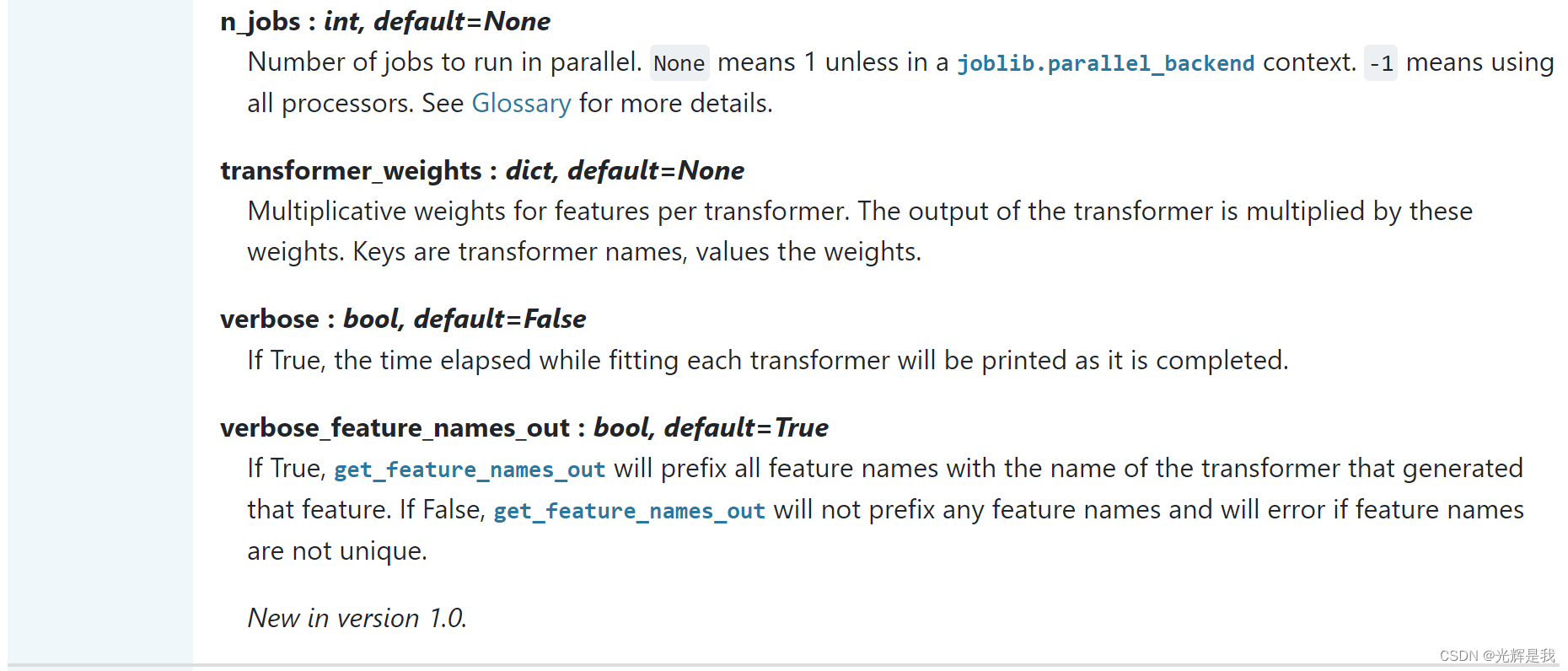


例子

5.拆分数据集为训练集合和测试集合
from sklearn.model_selection import train_test_split
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.2, random_state=0)
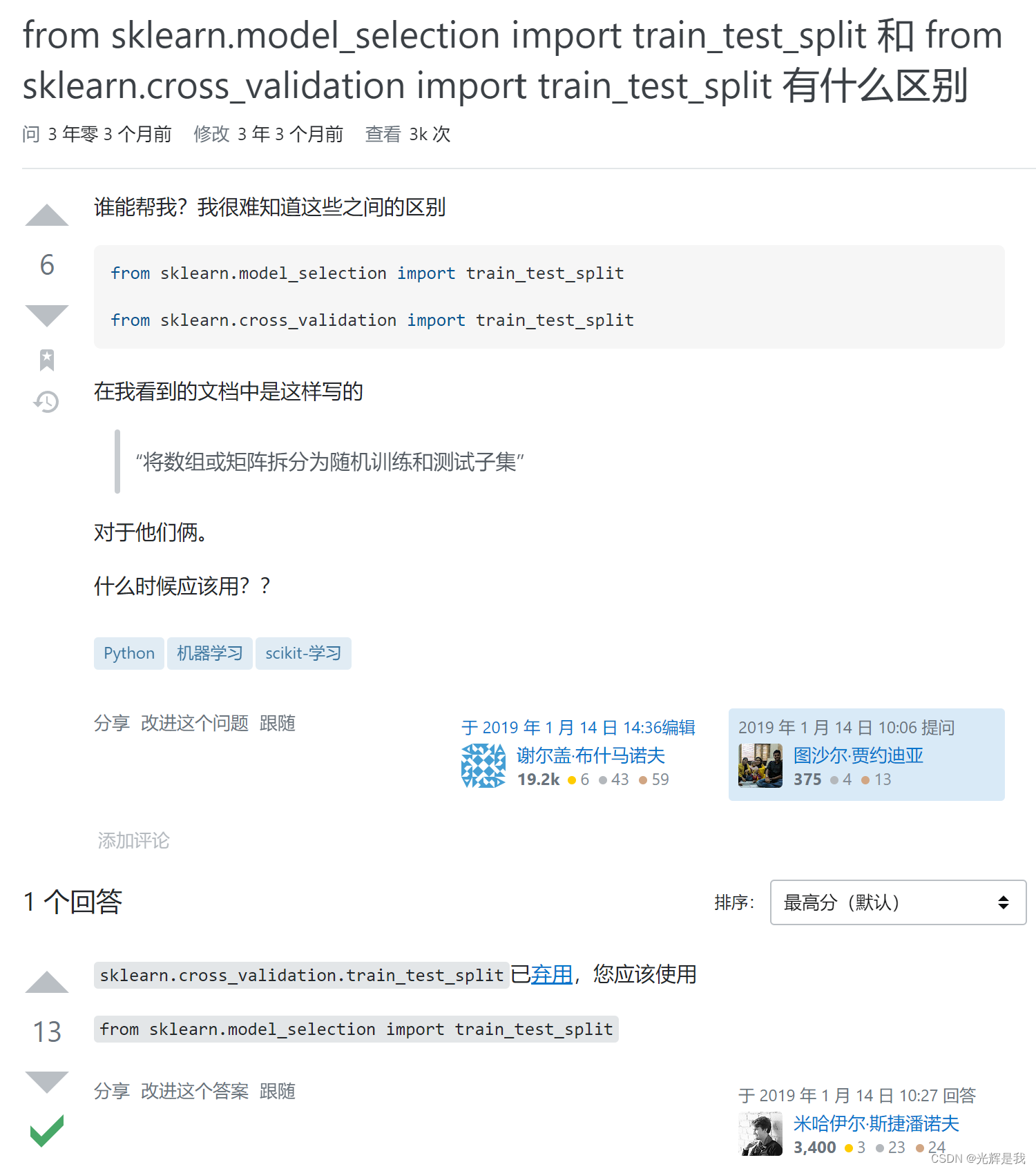
sklearn.model_selection.train_test_split



可以使用shuffle=False命令关闭数据混洗和随机拆分
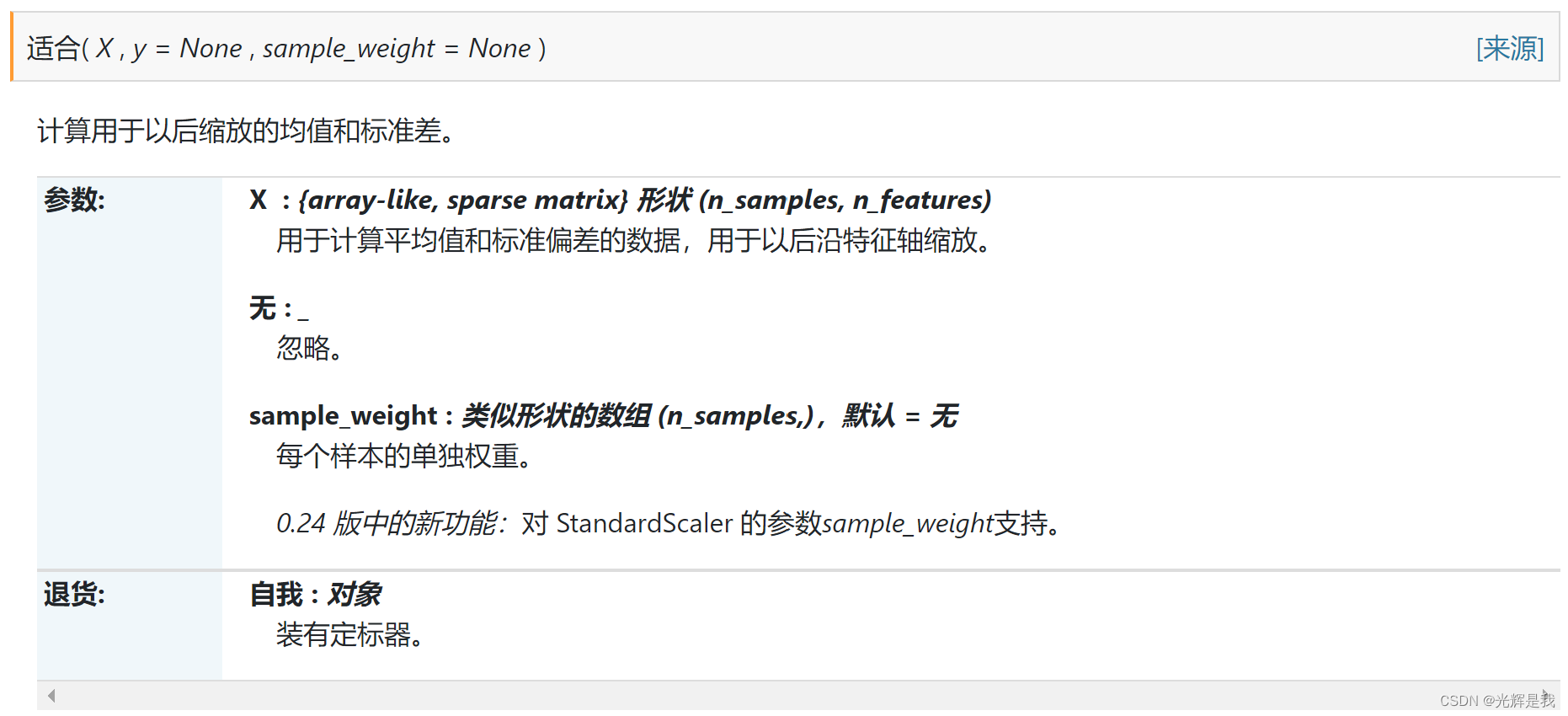
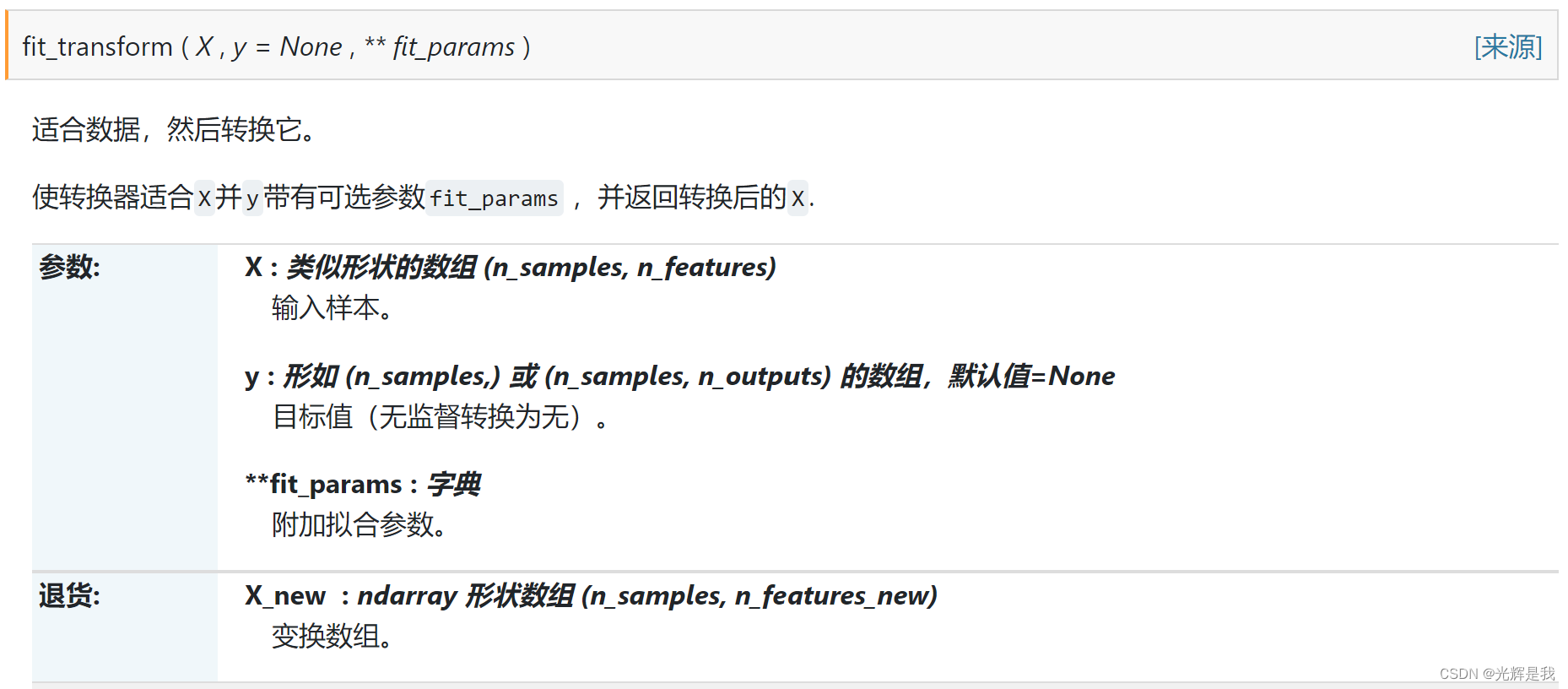
6.特征缩放
from sklearn.preprocessing import StandardScaler
sc_X = StandardScaler()
X_train = sc_X.fit_transform(X_train)
X_test = sc_X.transform(X_test)
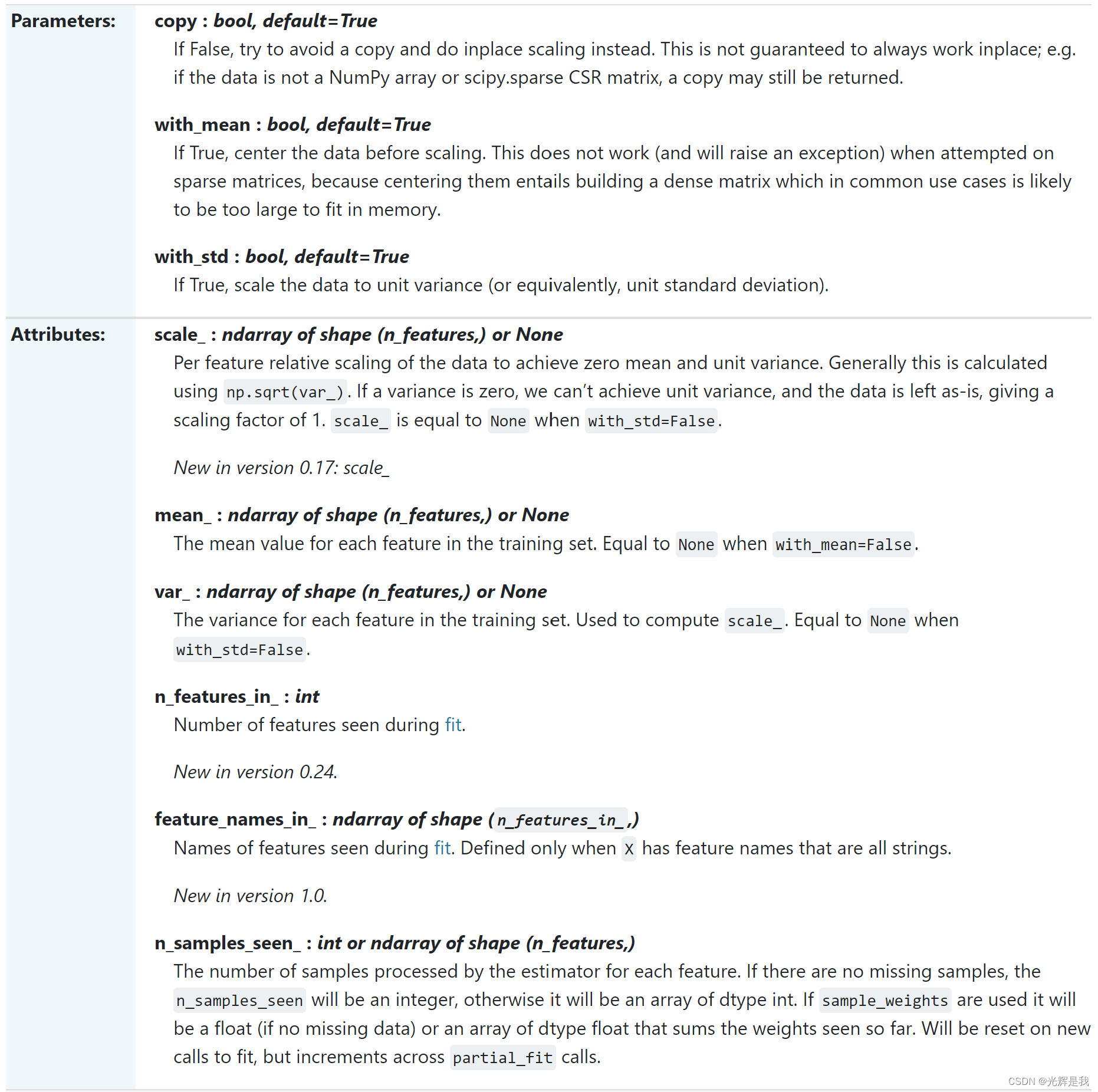
sklearn.preprocessing.StandardScaler
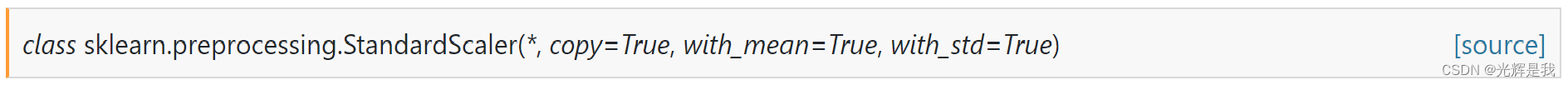


















 937
937











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









