







Automatic Keyphrase Extraction via Topic Decomposition
TRP简介
现基于图的关键字抽取算法都是通过单个单词的在网络中的随机游走,来得出每个单词的重要性得分。文档和单词能被混合语义主题呈现,作者提出将传统的随机游走算法分解成多个不同主题的随机游走。作者建立了一个Topical PageRank算法在不同主题图上进行随机游走,来获得每个单词的重要性。然后,给定文档主题分布,再进一步计算单词的排名分数,并提取排名靠前的词作为关键词。
TRP思想
目前基于图的关键词抽取算法主要面临以下两个问题:
1、好的关键词应该和被给文档的主题密切相关。在基于图的方式上,这个字应该和其他字广泛相连接,并且排名分数很高,但是不能代表文档的主要主题。
2、一个恰当的关键词集合应该很好地覆盖文档主要的主题,在基于图的方式上,可能会陷入文档单个主题上,而不能覆盖文档其他的主题。
TRP需要先进行主题分类,相对于传统的PageRank算法,TRP将进入多个精细化主题进行随机游走,以获得不同主题下的关键字。
TRP关键词抽取算法的实现步骤:
1、构建主题解析器,来获取每个文档或者段落的主题。
2、执行TRP算法进行短语抽取。
TRP实现
主题的字分布获取方式存在两种:
- 使用人工标注的数据库,WordNet。(可能不涉及所有的字)
- 无监督的机器学习算法在大范围语料中获取。(Latent Dirichlet Allocation(LDA), Latent Semantic Analysis(LSA),probabilistic LSA(pLSA))。
TPR实现关键词抽取算法图:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-AMTC1Xl6-1663643844570)(D:\Python\project\weekly_work\2022-09-19_2022-09-25\imgs\image-20220919184915518.png)]](https://i-blog.csdnimg.cn/blog_migrate/d6565149f9f5ec090ba45c5df33bb38b.png)
具体流程如下所示:
- 构建文档 d d d的字图,字图上边的关系遵循文档 d d d上字共现关系。
- 执行TPR算法来计算每个主题下字的得分情况。
- 使用字来构建词,分别对每个主题的词进行排名。
- 对于给定文档 d d d的主题,将候选关键词的主题按照特定排名整合到最终的排名中,排名靠前的关键词被选为最终的关键词。
常规的PageRank算法:
R
(
w
i
)
=
λ
∑
j
:
w
j
→
w
i
w
(
w
j
,
w
i
)
O
(
w
j
)
R
(
w
j
)
+
(
1
−
λ
)
1
∣
V
∣
R(w_i)=\lambda \sum_{j:w_j \to w_i} \frac{w(w_j,w_i)}{O(w_j)}R(w_j)+(1-\lambda) \frac{1}{|V|}
R(wi)=λj:wj→wi∑O(wj)w(wj,wi)R(wj)+(1−λ)∣V∣1
将所有的词按照主题进行划分后,新的TPR计算公式如下:
R
z
(
w
i
)
=
λ
∑
j
:
w
j
→
w
i
e
(
w
j
,
w
i
)
O
(
w
j
)
R
z
(
w
j
)
+
(
1
−
λ
)
p
z
(
w
i
)
R_z(w_i)=\lambda \sum_{j:w_j \to w_i} \frac{e(w_j,w_i)}{O(w_j)}R_z(w_j)+(1-\lambda)p_z(w_i)
Rz(wi)=λj:wj→wi∑O(wj)e(wj,wi)Rz(wj)+(1−λ)pz(wi)
其中每个字在不同主题中的偏置值
p
z
(
w
)
p_z (w)
pz(w)不太一样
∑
w
∈
V
p
z
(
w
)
=
1
\sum_{w \in V}p_z(w)=1
∑w∈Vpz(w)=1,并且
p
z
(
w
)
p_z(w)
pz(w)将会严重影响TPR的效果,
p
z
(
w
)
p_z(w)
pz(w)计算可以使用两种方式:
- p z ( w ) = p r ( w ∣ z ) p_z(w)=pr(w|z) pz(w)=pr(w∣z),字 w w w出现在主题 z z z的概率,主要侧重点是字出现的次数。
- p z ( w ) = p r ( z ∣ w ) p_z(w)=pr(z|w) pz(w)=pr(z∣w),字 w w w的主题是 z z z的概率,主要侧重点是字对主题的关注程度。
- p z ( w ) = p r ( w ∣ z ) ∗ p r ( z ∣ w ) p_z(w)=pr(w|z)*pr(z|w) pz(w)=pr(w∣z)∗pr(z∣w),是前面两者的均衡。
筛选候选关键词:
- 关键词通常都是名词/名词短语。所以需要使用序列标注(POS)对文档的词性进行标注,提取出“(形容词)*(名词)+”的一个形式,表示零个或多个形容词后面跟着一个或者多个子名词。
- 每个主题的候选关键词将有每个主题中的字来构成,每个主题中的词的得分计算公式如下所示:
R z ( p ) = ∑ w i ∈ p R z ( w i ) R_z(p)=\sum_{w_i \in p}R_z(w_i) Rz(p)=wi∈p∑Rz(wi)
- 最终将每个文档的主题和词的得分进行结合,得到最终每个候选关键词的得分:
R ( p ) = ∑ z = 1 K R z ( p ) × p r ( z ∣ d ) R(p)=\sum_{z=1}^K R_z(p) \times pr(z|d) R(p)=z=1∑KRz(p)×pr(z∣d)
TPR评估
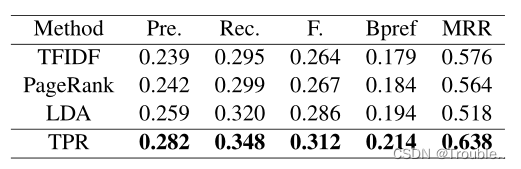
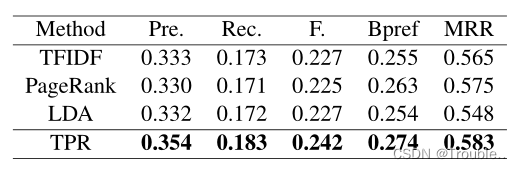
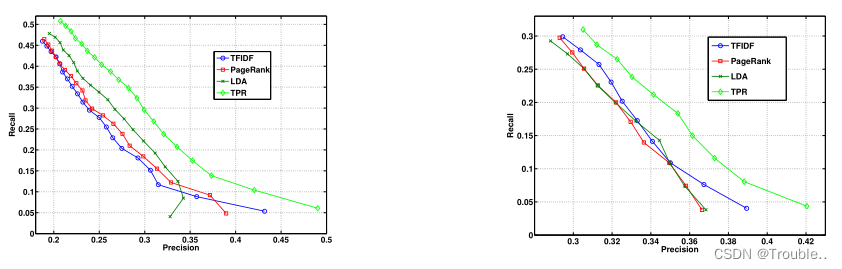
数据集:DUC2001(NEWS)、Hulth(RESEARCH)。
评价指标:precision、recall、F-measure、binary preference measure(Bpref)、mean reciprocal rank(MMR)。
- Bpref是用于描述关键词的排名顺序的评价指标,对于一个文档而言,存在 R R R个正确的关键字,使用一个关键词提取方法抽取出 M M M个关键词,其中存在 r r r个是一个正确的关键词, n n n个错误的关键词,具体计算公式如下式所示:
B p r e f = 1 R ∑ r ∈ R 1 − ∣ n r a n k e d h i g h e r t h a n r ∣ M Bpref=\frac{1}{R} \sum_{r \in R} 1-\frac{|n \ ranked \ higher \ than \ r|}{M} Bpref=R1r∈R∑1−M∣n ranked higher than r∣
- MMR算法用于评价每个文档第一个候选关键词的排名。对于文档 d d d, r a n k d rank_d rankd表示为具有所有提取关键词的第一个正确关键词的秩,其中 D D D是文档所有的候选关键词列表,具体计算如下式所示:
M R R = 1 ∣ D ∣ ∑ d ∈ D 1 r a n k d MRR=\frac{1}{|D|} \sum_{d \in D} \frac{1}{rank_d} MRR=∣D∣1d∈D∑rankd1
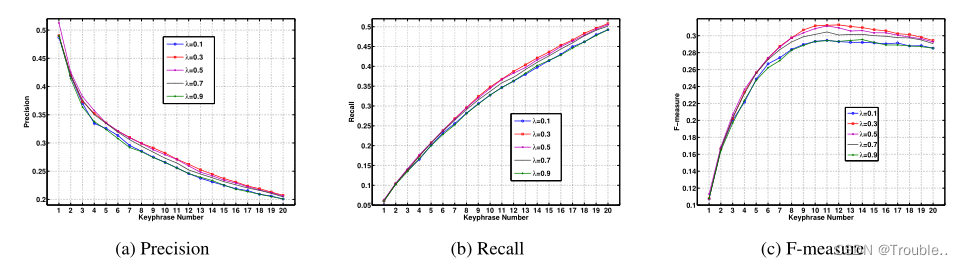
作者主要考虑了以下四点因素对模型效果的影响:
- 词共现窗口的大小 w w w。
- 使用LDA算法对文档主题的提取数量。(LDA算法没有考虑字/词的词频信息,TPR主要是利用外部主题LDA、内部文档结构PageRank等)
- 单词在每个主题的得分计算情况 p z ( w ) p_z(w) pz(w)。
- 阻尼因子 λ \lambda λ对图随机游走的效果。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-mCVwxKjw-1663643844572)(D:\Python\project\weekly_work\2022-09-19_2022-09-25\imgs\image-20220920102711649.png)]](https://i-blog.csdnimg.cn/blog_migrate/9dfcfb0c84791ad984047814bb5e6db3.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-qB8XjKcx-1663643844573)(D:\Python\project\weekly_work\2022-09-19_2022-09-25\imgs\image-20220920102922556.png)]](https://i-blog.csdnimg.cn/blog_migrate/d854c73b2f9f39dd8957ae623f02e166.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-J9uM6hfd-1663643844575)(D:\Python\project\weekly_work\2022-09-19_2022-09-25\imgs\image-20220920103206268.png)]](https://i-blog.csdnimg.cn/blog_migrate/e403d171891e9ac8d5d6358a25f7a8d7.png)
TPR总结
TPR是一种无监督的关键词抽取算法,其主要特点是对文档进行分主题分别计算每个字在不同主题下的重要程度,利用一定规则得出每个主题下词的得分,最终结合多个主题得出每个候选词的最终得分,得出最终的关键词集合。
文章的重点在于文章主题的提取,并可以对文档中的字分类到各个主题中去,也就是LDA算法实现是文章的最终要一个点。作者是这样解决的:使用Wikipedia的大范围语料来训练LDA,最终得出的模型在应用到每个具体的文档上来。
个候选词的最终得分,得出最终的关键词集合。
文章的重点在于文章主题的提取,并可以对文档中的字分类到各个主题中去,也就是LDA算法实现是文章的最终要一个点。作者是这样解决的:使用Wikipedia的大范围语料来训练LDA,最终得出的模型在应用到每个具体的文档上来。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











