






补充前几天的中文分词
对一本小说进行分词
import jieba
from zhon.hanzi import punctuation
file = open('b.txt', 'r', encoding='utf-8')
data=file.read()
data = jieba.cut(data)
string = re.sub(r"[%s]+" %punctuation, "",data)
fW = open('a.txt', 'w', encoding='UTF-8')
fW.write(''.join(string))
fW.close()
原始数据jieba分词

去除标点

构图和解码
接下来开始基于WFST解码器的语音识别系统
HCLG 构建
| 组成 | 转换器 | 输入序列 | 输出序列 |
|---|---|---|---|
| H | HMM | HMM的转移-id | 单音子/三音子(triphone) |
| C | 上下文相关 | 单音子/三音子 | 单音子(monophone) |
| L | 发音词典 | 单音子 | 词(word) |
| G | 语言模型 | 词 | 词(word) |
- 构建G
以yesno为例,在local/ 中

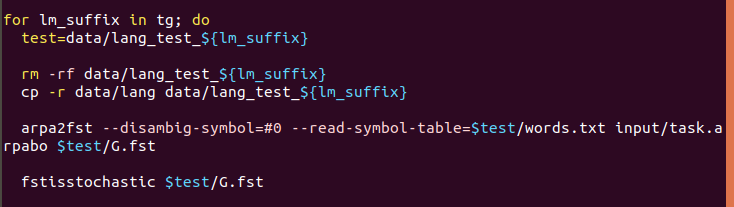 该脚本对tg的语言模型进行了G构建操作
该脚本对tg的语言模型进行了G构建操作
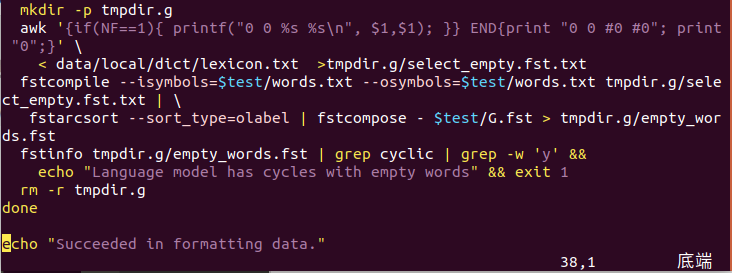 对APRA格式的语言模型文件解压后,直接输入到apra2fst程序中,就得到目标输出G.fst
对APRA格式的语言模型文件解压后,直接输入到apra2fst程序中,就得到目标输出G.fst
- 构建L
在utils/ 中
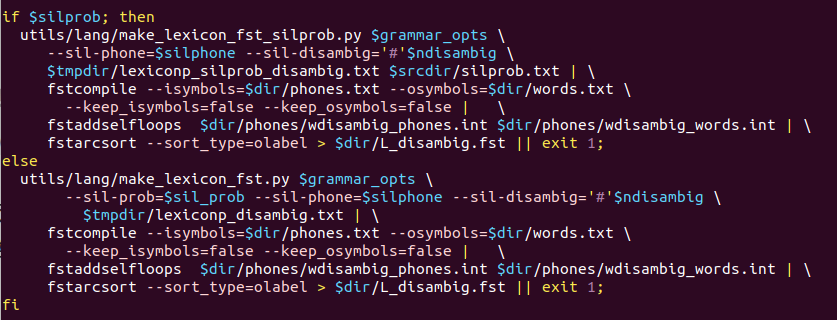 L的构图算法是由脚本 utils/lang/make_lexicon_fst_silprob.py,这个脚本用来构建不带静音概率的L,而utils/lang/make_lexicon_fst.py用来构建带静音概率的L,由变量silprob来控制构建哪一种
L的构图算法是由脚本 utils/lang/make_lexicon_fst_silprob.py,这个脚本用来构建不带静音概率的L,而utils/lang/make_lexicon_fst.py用来构建带静音概率的L,由变量silprob来控制构建哪一种
 之后通过fstcompile进行编译,使用fstarcsort工具对生成的图按照输出标签做排序
之后通过fstcompile进行编译,使用fstarcsort工具对生成的图按照输出标签做排序 - 合并得到LG.fst

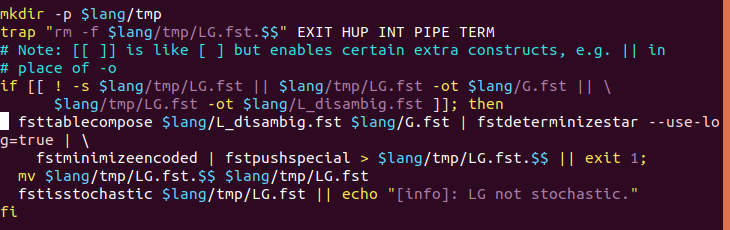
4. 再进一步与字典的单音子与上下文相关转换器C.fst合并

5. 构造H.fst
 6. 最后与HMM转换器H.fst合并得到HCLG.fst
6. 最后与HMM转换器H.fst合并得到HCLG.fst
总结:

通过HLCG的合并,把词典、声学模型、语言模型编译在一起,在识别之前产生识别用的静态解码网络,然后用WFST解码器,得到输入语音的解码效果
WFST解码
两种类型offline&online
- 离线解码
书中介绍的解码器是SimpleDecoder
我在看另外一篇博客还有介绍另一个解码器LatticeFasterDecoder
参考博客
SimpleDecoder
SimpleDecoder是Kaldi中最简单的解码器
gmm-decode-simple是一个基于SimpleDecoder实现的针对GMM声学模型的解码器
参考博文
程序需要输入GMM声学模型、HCLG解码图、声学特征,输出单词解码结果
















 1013
1013











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











