







github地址: https://github.com/CodeWang-Ay/DataProcess
类型1
需求1:
类似于数据格式: https://blog.csdn.net/qq_44072222/article/details/120884158
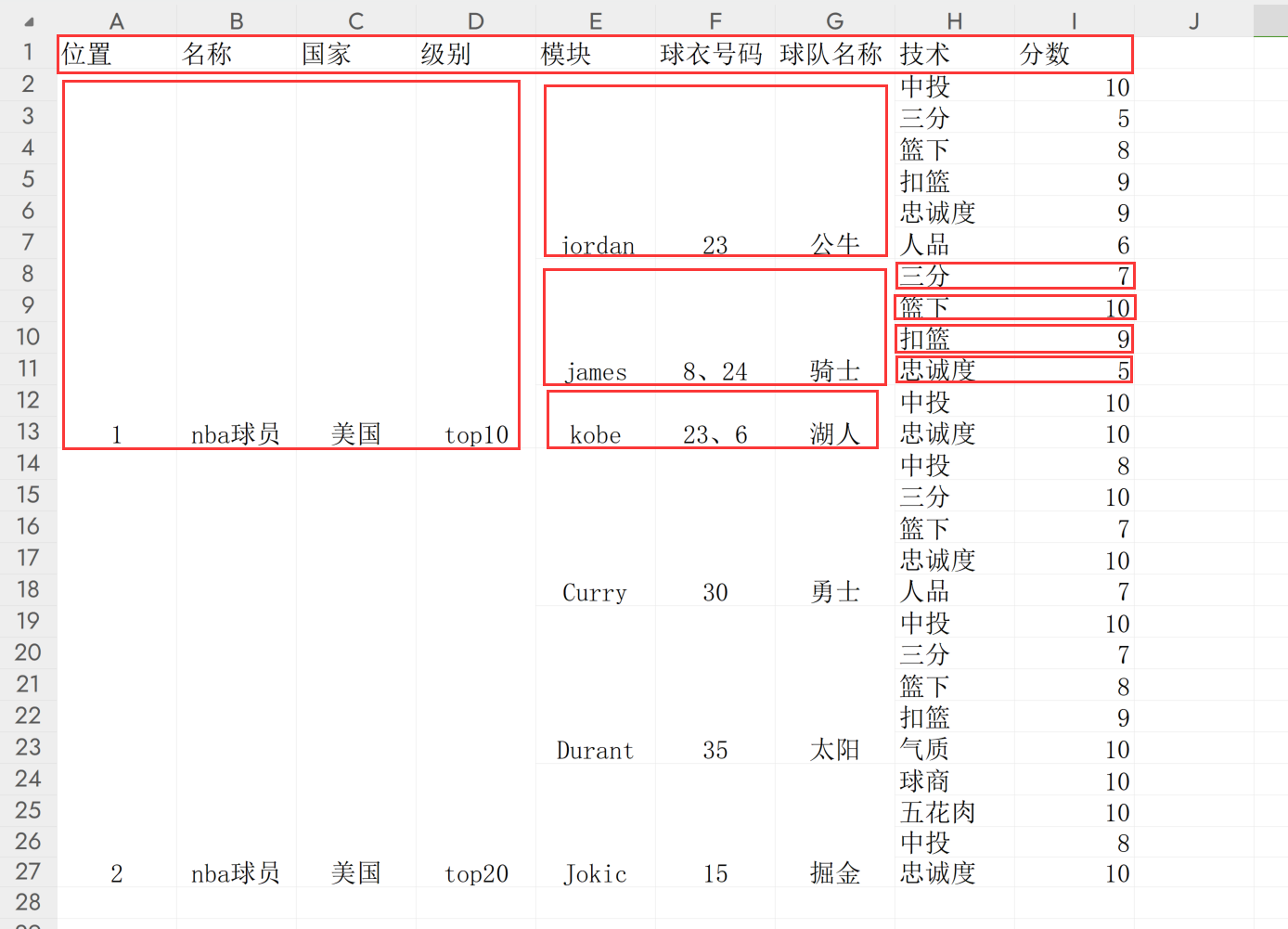
目标json格式
{"位置": 1, "名称": "nba球员", "国家": "美国", "级别": "top10", "level2": [{"模块": "jordan", "球衣号码": 23, "球队名称": "公牛", "level3": [{"技术": "中投", "分数": 10}, {"技术": "三分", "分数": 5}, {"技术": "篮下", "分数": 8}, {"技术": "扣篮", "分数": 9}, {"技术": "忠诚度", "分数": 9}, {"技术": "人品", "分数": 6}]}, {"模块": "james", "球衣号码": "8、24", "球队名称": "骑士", "level3": [{"技术": "三分", "分数": 7}, {"技术": "篮下", "分数": 10}, {"技术": "扣篮", "分数": 9}, {"技术": "忠诚度", "分数": 5}]}, {"模块": "kobe", "球衣号码": "23、6", "球队名称": "湖人", "level3": [{"技术": "中投", "分数": 10}, {"技术": "忠诚度", "分数": 10}]}]}
转json格式链接: https://www.json.cn/#google_vignette

整体思路
数据格式相等于是一个三层的的树,一次遍历第一层,第二层, 第三层然后构建一颗树即可
第一层: 列范围 1-4
第二层: 列范围 5-7
第三层: 列范围 8-9
关键参数
表示三层
每次定位到第一层然后范围依次缩小取位置
col_level_index = [1, 5, 8, 10] # level1, level2, level3, level4
使用 openpyxl 工具包
openpyxl 中文文档: https://openpyxl-chinese-docs.readthedocs.io/zh-cn/latest/tutorial.html
解决代码:
import json
import openpyxl as xl
import pandas as pd
def get_merge_cell_by_no(sheet_, column_no):
"""
:param sheet: sheet对象
:param column_no: 列索引 从1开始
:return: 返回给定的索引下的所有合并单元格
"""
merger_cell = [] # 第一列合并的单元格
merged_ranges = sheet_.merged_cells.ranges # 获取当前工作表的所有合并区域列表
for merged_cell_range in merged_ranges:
if merged_cell_range.min_col == column_no and merged_cell_range.max_col == column_no:
merger_cell.append(merged_cell_range)
return sorted(merger_cell, key=lambda x: x.min_row) # 排序返回 默认不排序
def get_merge_cell_by_special(sheet, start_row, end_row, start_col, end_col):
"""
在特定范围内的合并单元格坐标
:param sheet:
:param start_row:
:param end_row:
:param start_col:
:param end_col:
:return:
"""
merger_cell = [] # 第一列合并的单元格
merged_ranges = sheet.merged_cells.ranges # 获取当前工作表的所有合并区域列表
for merged_cell_range in merged_ranges:
up = merged_cell_range.min_row >= start_row
down = merged_cell_range.max_row <= end_row
left = merged_cell_range.min_col >= start_col
right = merged_cell_range.max_col <= end_col
if up and down and left and right:
merger_cell.append(merged_cell_range)
return sorted(merger_cell, key=lambda x: x.min_row) # 排序返回 默认不排序
def get_filed_by_row_id(sheet_, keys, row_id, col_level_index):
"""
get_filed_by_row_id 通过行id得到所有的json
"""
# for row_id in row_list:
filed_json = {}
for row in sheet_.iter_rows(min_row=row_id, max_row=row_id, min_col=col_level_index[2], max_col=col_level_index[3], values_only=True):
filed_json = get_dict_by_list(keys, row)
# print(row)
return filed_json
def get_dict_by_list(keys, values):
"""
get_dict_by_list
"""
data_dict = {}
for key, value in zip(keys, values):
data_dict[key] = value
return data_dict
def save_jsonline_json(json_list, target_path):
"""
json_list ---> jsonline
:param json_list:
:param target_path:
:return:
"""
with open(target_path, 'w', encoding="utf-8") as json_file:
for item in json_list:
json.dump(item, json_file, ensure_ascii=False)
json_file.write("\n")
print("Json列表已经保存到 {} 文件中。 每一行为一个json对象".format(target_path))
def excel_to_json_tree_e2e(sheet_, col_level_index):
alphabet = " ABCDEFGHIJKLMNOPQRSTUVWXYZ"
level_merge_list = get_merge_cell_by_no(sheet_, col_level_index[0]) # 一级逻辑关系所有的列\
json_list = []
for index_level1, merge_level1 in enumerate(level_merge_list):
start_row_level1 = merge_level1.min_row
end_row_level1 = merge_level1.max_row
level1_map = {}
for col in range(col_level_index[0], col_level_index[1]): # 列A是1,列D是4
key = sheet_[alphabet[col] + str(1)].value
cell_ref = sheet_[alphabet[col] + str(start_row_level1)].value # 因为第二行,所以+1
level1_map[key] = cell_ref # 第一个阶段结束
level1_map["level2"] = []
level2_merge_list = get_merge_cell_by_special(sheet_, start_row_level1, end_row_level1,
col_level_index[1], col_level_index[1])
level2_list = []
for index_level2, merge_cell_level2 in enumerate(level2_merge_list):
start_row_level2 = merge_cell_level2.min_row
end_row_level2 = merge_cell_level2.max_row
level2_list.append([i for i in range(start_row_level2, end_row_level2 + 1)])
level2_map = {}
for col in range(col_level_index[1], col_level_index[2]): # 列A是1,列D是4
key = sheet_[alphabet[col] + str(1)].value
cell_ref = sheet_[alphabet[col] + str(start_row_level2)].value # 因为第二行,所以+1
level2_map[key] = cell_ref # 第一个阶段结束
column_name_list = []
for col in range(col_level_index[2], col_level_index[3]): # 列A是1,列D是4
key = sheet_[alphabet[col] + str(1)].value
column_name_list.append(key)
level2_map["level3"] = []
for row_id in range(start_row_level2, end_row_level2+1):
current_filed_json = get_filed_by_row_id(sheet_, column_name_list, row_id, col_level_index)
level2_map["level3"].append(current_filed_json)
level1_map["level2"].append(level2_map)
json_list.append(level1_map)
return json_list
if __name__ == '__main__':
excel_file = "excel/merge_new.xlsx"
output_path = "output/nba_json.json"
wb = xl.load_workbook(excel_file)
sheet = wb["nba"]
col_level_index = [1, 5, 8, 10] # level1, level2, level3, level4
json_list = excel_to_json_tree_e2e(sheet, col_level_index)
save_jsonline_json(json_list, output_path)
类型2
需求2:
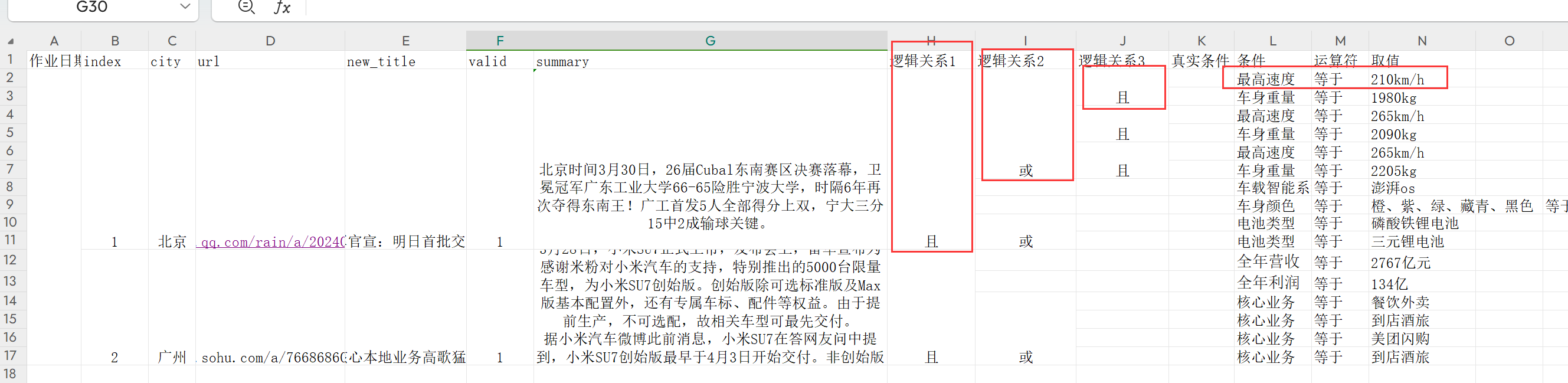
转成:
数据格式相等于是一个三层的的树,一次遍历第一层,第二层, 第三层然后构建一颗树即可
第一层: 列范围 H
第二层: 列范围 I
第三层: 列范围 J
第四层: 列范围 KLMN
关键参数
每次定位到第一层然后范围依次缩小取位置
{"source": "北京时间3月30日,26届Cubal东南赛区决赛落幕,卫冕冠军广东工业大学66-65险胜宁波大学,时隔6年再次夺得东南王!广工首发5人全部得分上双,宁大三分15中2成输球关键。\n", "label": {"relation": "且", "conditions": [{"relation": "或", "conditions": [{"relation": "且", "conditions": [{"description": "最高速度", "option": "等于", "requirement": "210km/h"}, {"description": "车身重量", "option": "等于", "requirement": "1980kg"}]}, {"relation": "且", "conditions": [{"description": "最高速度", "option": "等于", "requirement": "265km/h"}, {"description": "车身重量", "option": "等于", "requirement": "2090kg"}]}, {"relation": "且", "conditions": [{"description": "最高速度", "option": "等于", "requirement": "265km/h"}, {"description": "车身重量", "option": "等于", "requirement": "2205kg"}]}]}, {"description": "车载智能系统", "option": "等于", "requirement": "澎湃os"}, {"description": "车身颜色", "option": "等于", "requirement": "橙、紫、绿、藏青、黑色"}, {"relation": "或", "conditions": [{"description": "电池类型", "option": "等于", "requirement": "磷酸铁锂电池"}, {"description": "电池类型", "option": "等于", "requirement": "三元锂电池"}]}]}}
解决代码:
import openpyxl as xl
import json
import itertools
import copy
def get_merge_cell_by_no(sheet_, column_no):
"""
:param sheet:
:param column_no:
:return:
"""
merger_cell = [] # 第一列合并的单元格
merged_ranges = sheet_.merged_cells.ranges # 获取当前工作表的所有合并区域列表
for merged_cell_range in merged_ranges:
if merged_cell_range.min_col == column_no and merged_cell_range.max_col == column_no:
merger_cell.append(merged_cell_range)
return sorted(merger_cell, key=lambda x: x.min_row) # 排序返回 默认不排序
def get_merge_cell_by_special(sheet, start_row, end_row, start_col, end_col):
"""
在特定范围内的合并单元格坐标
:param sheet:
:param start_row:
:param end_row:
:param start_col:
:param end_col:
:return:
"""
merger_cell = [] # 第一列合并的单元格
merged_ranges = sheet.merged_cells.ranges # 获取当前工作表的所有合并区域列表
for merged_cell_range in merged_ranges:
up = merged_cell_range.min_row >= start_row
down = merged_cell_range.max_row <= end_row
left = merged_cell_range.min_col >= start_col
right = merged_cell_range.max_col <= end_col
if up and down and left and right:
merger_cell.append(merged_cell_range)
return sorted(merger_cell, key=lambda x: x.min_row) # 排序返回 默认不排序
def get_dict_by_list(keys, values):
"""
get_dict_by_list
"""
data_dict = {}
for key, value in zip(keys, values):
data_dict[key] = value
return data_dict
def get_filed_by_row_id(sheet_, keys, row_id, use_align):
"""
get_filed_by_row_id 通过行id得到所有的json
"""
# for row_id in row_list:
filed_json = {}
for row in sheet_.iter_rows(min_row=row_id, max_row=row_id, min_col=11, max_col=14, values_only=True):
if use_align:
row = [row[0], row[2], row[3]] # 取数配置那一列不要
else:
row = [row[1], row[2], row[3]] # 取数配置那一列不要
filed_json = get_dict_by_list(keys, row)
# print(row)
return filed_json
def custom_sort_key(item):
"""
合并单元格排序
"""
if isinstance(item, list):
return item[0]
else:
return item
def excel_to_json_tree_e2e(sheet_, column_name_list, logic_level, level1_col_index, isvalid_col, use_align):
"""
excel_to_json_tree. 读取excel文件,转换成json树结构
:param sheet_:
:param column_name_list: key_list
:param logic_level: summary, 一级, 二级, 三级列名
:param level1_col_index: 第一级逻辑关系的索引 8
:param isvalid_col: 是否有效列, 有效我们才进行转化
:return:
"""
level_merge_list = get_merge_cell_by_no(sheet_, level1_col_index) # 一级逻辑关系所有的列
e2e_json_list = []
pre_json_list = []
post_json_list = []
relation_key = "relation"
condition_key = "conditions"
for index_level1, merge_cell_level1 in enumerate(level_merge_list):
e2e_json = {}
pre_json_total = {}
post_json_label = {}
post_json_total = {}
start_row_level1 = merge_cell_level1.min_row
end_row_level1 = merge_cell_level1.max_row
level1_merge = [i for i in range(start_row_level1, end_row_level1 + 1)] # level的所有列索引
summary_content = sheet_[logic_level[0] + str(start_row_level1)].value # G2 内容用于构建 source: target使用
level1_json = {}
level1_logic = sheet_[logic_level[1] + str(start_row_level1)].value # H2
level1_json[relation_key] = level1_logic # relation : logic
level1_json[condition_key] = [] #
level1_json_pre = copy.deepcopy(level1_json) # 拷贝
isvalid = sheet_[isvalid_col + str(start_row_level1)].value # F2 验证有效字段是否有效 无效则直接跳过
if isvalid != 1: # 验证是否有效字段
continue
# post
post_json_label[condition_key] = []
for row_id in level1_merge:
current_post_json = get_filed_by_row_id(sheet_, column_name_list, row_id, use_align)
post_json_label[condition_key].append(current_post_json)
level2_merge = []
level2_merge_cell_list = get_merge_cell_by_special(sheet_, start_row_level1, end_row_level1,
level1_col_index + 1, level1_col_index + 1)
for index_level2, merge_cell_level2 in enumerate(level2_merge_cell_list):
start_row_level2 = merge_cell_level2.min_row
end_row_level2 = merge_cell_level2.max_row
level2_merge.append([i for i in range(start_row_level2, end_row_level2 + 1)])
level2_merge_one_dimension = list(itertools.chain.from_iterable(level2_merge))
level2_single = [i for i in level1_merge if i not in level2_merge_one_dimension]
level2 = level2_merge + level2_single
level2 = sorted(level2, key=custom_sort_key) # 为了保证顺序
for element in level2:
if type(element) is int:
# 没有二级逻辑关系
row_id = element
current_filed_json = get_filed_by_row_id(sheet_, column_name_list, row_id, use_align)
level1_json[condition_key].append(current_filed_json)
value = current_filed_json[column_name_list[0]] # pre dataset
level1_json_pre[condition_key].append(value)
elif type(element) is list:
# 二级逻辑关系
current_level2_merge = element
start = element[0]
end = element[-1]
level3_merge_list = get_merge_cell_by_special(sheet_, start, end,
level1_col_index + 2, level1_col_index + 2)
level2_json = {}
level2_logic = sheet_[logic_level[2] + str(start)].value
level2_json[relation_key] = level2_logic
level2_json[condition_key] = []
level2_json_pre = copy.deepcopy(level2_json)
if len(level3_merge_list) == 0:
# 没有三级逻辑关系
for row_id in element:
current_filed_json = get_filed_by_row_id(sheet_, column_name_list, row_id, use_align)
level2_json[condition_key].append(current_filed_json)
level2_json_pre[condition_key].append(current_filed_json[column_name_list[0]])
else:
# 有三级逻辑关系
level3_merge = []
for merge_cell_level3 in level3_merge_list:
start_row_level3 = merge_cell_level3.min_row
end_row_level3 = merge_cell_level3.max_row
level3_merge.append([i for i in range(start_row_level3, end_row_level3 + 1)])
level3_merge_one_dimension = list(itertools.chain.from_iterable(level3_merge))
level3_single = [i for i in current_level2_merge if i not in level3_merge_one_dimension]
level3 = level3_single + level3_merge
level3 = sorted(level3, key=custom_sort_key)
for element_level3 in level3:
if type(element_level3) is int:
current_filed_json = get_filed_by_row_id(sheet_, column_name_list, element_level3, use_align)
level2_json[condition_key].append(current_filed_json)
level2_json_pre[condition_key].append(current_filed_json[column_name_list[0]])
elif type(element_level3) is list:
level3_start = element_level3[0]
level3_end = element_level3[-1]
level3_json = {}
level3_logic = sheet_[logic_level[3] + str(level3_start)].value
level3_json[relation_key] = level3_logic
level3_json[condition_key] = []
level3_json_pre = copy.deepcopy(level3_json)
for row_id in element_level3:
current_filed_json = get_filed_by_row_id(sheet_, column_name_list, row_id, use_align)
level3_json[condition_key].append(current_filed_json)
field = current_filed_json[column_name_list[0]]
level3_json_pre[condition_key].append(field)
level2_json[condition_key].append(level3_json)
level2_json_pre[condition_key].append(level3_json_pre)
level1_json[condition_key].append(level2_json)
level1_json_pre[condition_key].append(level2_json_pre)
e2e_json["source"] = summary_content
e2e_json["label"] = level1_json
pre_json_total["source"] = summary_content
pre_json_total["label"] = level1_json_pre
post_json_total["source"] = summary_content
post_json_total["label"] = post_json_label
# print(json.dumps(e2e_json, ensure_ascii=False))
# print(json.dumps(pre_json_total, ensure_ascii=False))
# print(json.dumps(post_json_total, ensure_ascii=False))
e2e_json_list.append(e2e_json)
pre_json_list.append(pre_json_total)
post_json_list.append(post_json_total)
return e2e_json_list, pre_json_list, post_json_list
def save_jsonline_json(json_list, target_path):
"""
json_list ---> jsonline
:param json_list:
:param target_path:
:return:
"""
with open(target_path, 'w', encoding="utf-8") as json_file:
for item in json_list:
json.dump(item, json_file, ensure_ascii=False)
json_file.write("\n")
print("Json列表已经保存到 {} 文件中。 每一行为一个json对象".format(target_path))
# 按顺序读取
"""
openpyxl 中文文档
https://openpyxl-chinese-docs.readthedocs.io/zh-cn/latest/tutorial.html
"""
if __name__ == "__main__":
source_file = "excel/merge_new.xlsx" # excel path
wb = xl.load_workbook(source_file)
sheet = wb["news"] # 子表对象
key_name_list = ["description", "option", "requirement"]
target_e2e_path = "output/train_e2e.json"
target_pre_path = "output/train_pre.json"
target_post_path = "output/train_post.json"
target_logic_level = ["G", "H", "I", "J"] # 逻辑关系所对应的列
valid_col = "F" # 是否有效列的字母
align_flag = 0 # 是否使用对齐列
e2e_list, pre_list, post_list = excel_to_json_tree_e2e(sheet, key_name_list, target_logic_level,
8, valid_col, align_flag)
# json_list = excel_to_json_tree_post(sheet, key_name_list, target_logic_level, 8, isvalid_col)
save_jsonline_json(e2e_list, target_e2e_path)
save_jsonline_json(pre_list, target_pre_path)
save_jsonline_json(post_list, target_post_path)

















 878
878

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









