







 本文介绍如何使用Hadoop MapReduce编程模型来计算公司各部门员工的工资总和,通过具体实例详细展示了MapReduce程序的设计与实现过程。
本文介绍如何使用Hadoop MapReduce编程模型来计算公司各部门员工的工资总和,通过具体实例详细展示了MapReduce程序的设计与实现过程。
Hadoop MapReduce 求公司部门工资总和案例实现目录
1.回顾MapReduce的WordCount程序
这是MapReduce Wordcount程序,结合起来看感觉更容易理解MapReduce程序的写法。这是WordcCount程序:MapReduce的WordCount程序
2.公司各部门员工薪水表
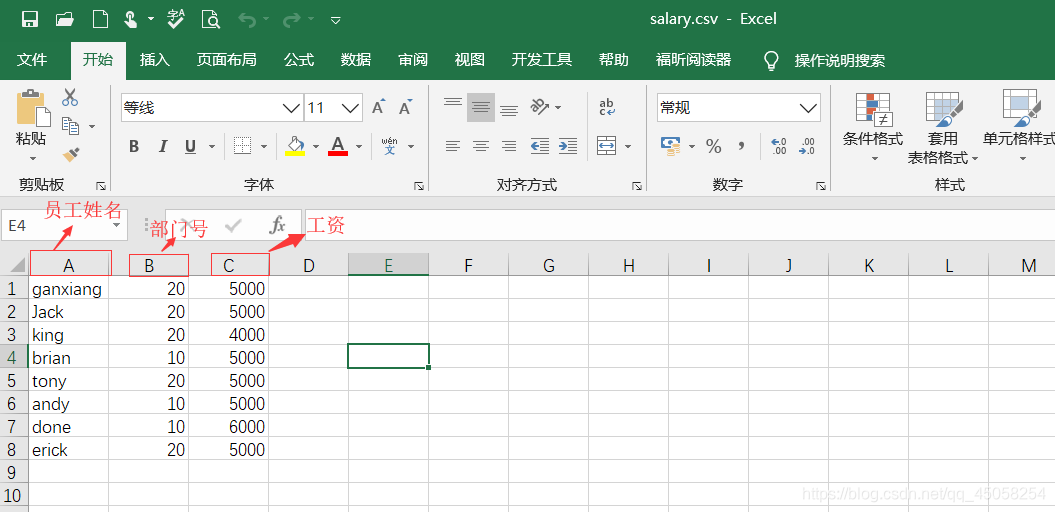
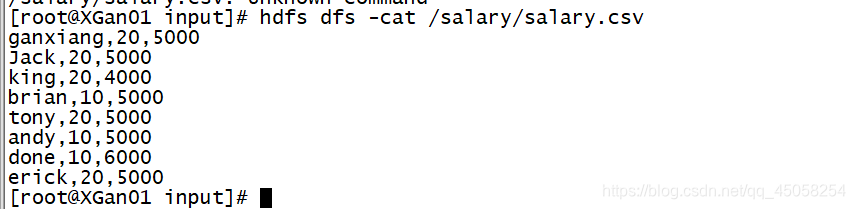
这是一张员工工资表,是csv文件类型,这里用两个部门举例分别是10号部门和20号部门,我们要做的是将10号部门与20号部门的员工工资总和分别求取出来。
3.编写MapReduce程序
其实编写这个程序和变写MapReduce WordCount程序是一样的,只需修改我们Mapper端,Reducer端的输入输出的数据类型,以及我们的主程序的Mapper端,Reducer端的输出的数据类型,即可。
Mapper端
package infoSalary;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
/**
* @author ganxiang
* IDE IntelliJ IDEA
* @project_name and filename HadoopTraining SalaryMapper
* @date 2020/04/25 0025 13:41
*/
public class SalaryMapper extends Mapper<LongWritable, Text, IntWritable,IntWritable> {
@Override
protected void map(LongWritable key1, Text value1, Context context) throws IOException, InterruptedException {
//1,获取数据
String line =value1.toString();
//2,分割数据
String [] data =line.split(",");
//3,写出数据
context.write(new IntWritable(Integer.parseInt(data[1])),new IntWritable(Integer.parseInt(data[2])));
}
}
Reducer端
package infoSalary;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
/**
* @author ganxiang
* IDE IntelliJ IDEA
* @project_name and filename HadoopTraining SalaryReducer
* @date 2020/04/25 0025 13:47
*/
public class SalaryReducer extends Reducer<IntWritable,IntWritable,IntWritable,IntWritable> {
@Override
protected void reduce(IntWritable key3, Iterable<IntWritable> values3, Context context) throws IOException, InterruptedException {
int sum =0;
//1,求取部门工资总和
for (IntWritable count:values3){
sum+=count.get();
}
//2,写出部门号以及部门员工工资总和
context.write(key3,new IntWritable(sum));
}
}
Job端
package infoSalary;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
/**
* @author ganxiang
* IDE IntelliJ IDEA
* @project_name and filename HadoopTraining SalaryJob
* @date 2020/04/25 0025 13:53
*/
public class SalaryJob {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
//1,创建一个job
Job salaryJob =Job.getInstance(new Configuration());
//2,设置job的入口函数
salaryJob.setJarByClass(SalaryJob.class);
//3,设置mapper
salaryJob.setMapperClass(SalaryMapper.class);
salaryJob.setMapOutputKeyClass(IntWritable.class);
salaryJob.setMapOutputValueClass(IntWritable.class);
//4,设置reducer
salaryJob.setReducerClass(SalaryReducer.class);
salaryJob.setOutputKeyClass(IntWritable.class);
salaryJob.setOutputValueClass(IntWritable.class);
//5,设置数据的存放路径
FileInputFormat.setInputPaths(salaryJob,new Path(args[0]));
FileOutputFormat.setOutputPath(salaryJob,new Path(args[1]));
//6,提交任务
salaryJob.waitForCompletion(true);
}
}
4.上传jar包以及执行jar需要注意的地方
从IDEA中打好jar包,上传到我们的虚拟环境中。在执行jar的时候需要注意一点,如果我们在同一个项目中编写了多个MapReduce程序并打成jar执行,需要在执行的时候指定package在的主函数名,如果不指定将报错无法找到主函数运行失败。如果没有在一个项目中写多个MapReduce程序打成jar包,忽略此信息。
1,此时我们的项目结构为这样的。
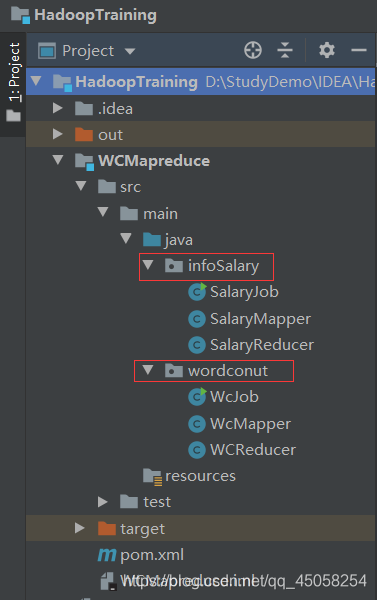
2,如果这样hadoop jar jar名执行将报错,因为同一个项目中存在多个MapReduce程序。

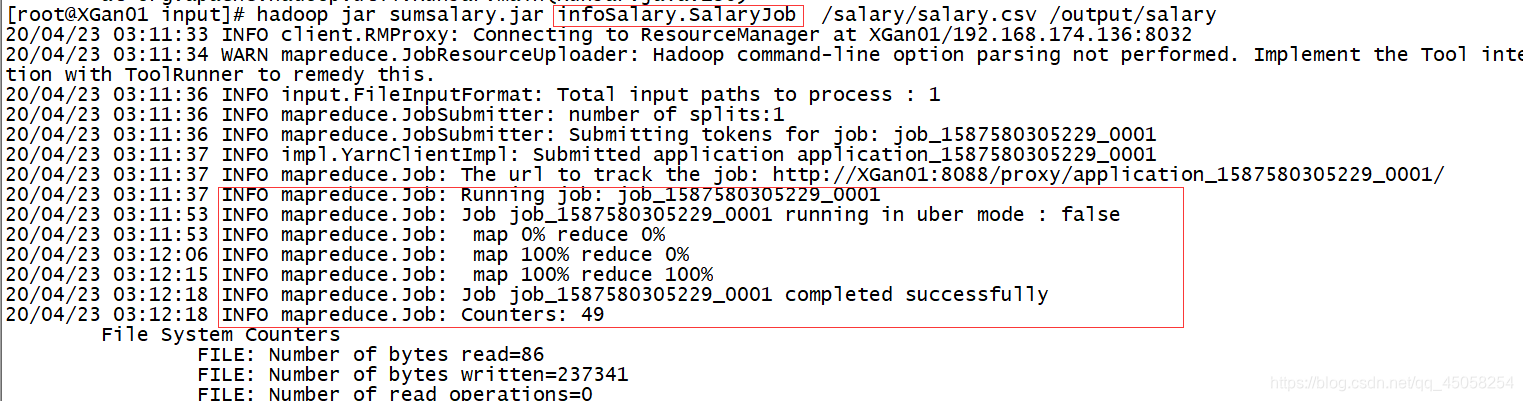
3,这样执行即可解决问题,hadoop jar jar名 package名.主函数名 。
hadoop jar sumsalary.jar infoSalary.SalaryJob /salary/salary.csv /output/salary
5.查看执行结果
5.1,任务执行成功
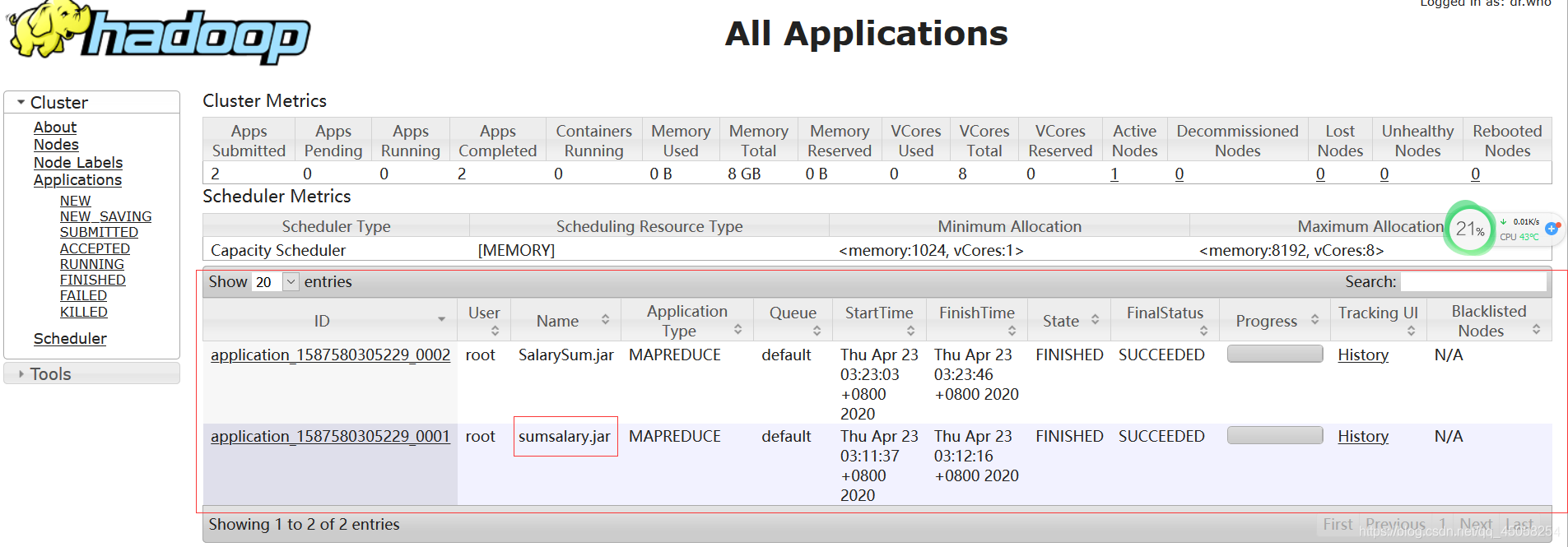
2,各部门的员工工资总和为10号部门1600,20号部门2400,经过计算没有误差。

ok,完工,都看到这儿了,点赞在走呗🤞🤞🤞🤞。

















 1308
1308

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









