









 本文深入介绍了A-Priori算法及其改进版FP树在关联规则挖掘中的应用。通过实例解析了算法的基本概念、步骤和挑战,并展示了FP树的建立与挖掘过程,强调了其完整性与紧凑性的优势。最后,给出了Python代码示例来实现关联规则挖掘。
本文深入介绍了A-Priori算法及其改进版FP树在关联规则挖掘中的应用。通过实例解析了算法的基本概念、步骤和挑战,并展示了FP树的建立与挖掘过程,强调了其完整性与紧凑性的优势。最后,给出了Python代码示例来实现关联规则挖掘。
引子
在本文中,我们将通过示例先了解A-Priori算法,其基本思路是:若一个集合的子集不是频繁项集,那么该集合也不可能是频繁项集。基于此,该算法可以通过检查小集合而去掉大部分不合格的大集合。
接着,我们介绍基本的A-Priori算法的改进——FP树,并通过图文结合的方式来协助理解。
文章由本人汇总而成,内容源来自专业课PPT(关联分析部分)、博客园(借用图已标明出处)、网络及书籍《斯坦福数据挖掘教程》、《数据挖掘导论》。
A-Priori算法
1.一些基本概念
关联规则:如果一个商品组合A和另一个商品组合B同时出现在一个或者多个顾客的购物清单上,那么我们称这两个商品组合存在关联规则。
支持度:某个商品组合出现的次数与总次数之间的比例

置信度:购买了商品A的客户中,有多大比例购买了商品B,实际上是一个条件概率求解问题。

注意:A=>B和B=>A是两条不一样的规则
提升度:购买了商品A的顾客,相比于一般顾客,多大程度更倾向于购买商品B。
关联规则是关联分析的特殊表达形式,下面将通过一个简单的例子来加深对上述概念的理解。

不难看出,AC同时出现了两次,A的3次出现里有两次C也出现了,而C的两次出现都伴随着A的出现
故:

2.算法步骤
用K项集来探索K+1项集,穷尽数据集中所有的频繁项集。
- 首先会生成所有单个物品的项集列表 I I I
- 扫描交易记录来查看哪些项集满足最小支持度要求,那些不满足最小支持度的集合会被去掉
- 对剩下的集合进行组合以生成包含两个元素的项集
- 以此类推,迭代下去,直到无法找到频繁k+1项集为止,对应的频繁k项集的集合即为算法的输出结果
为便于理解,此处借用一位博主博客中的一张图
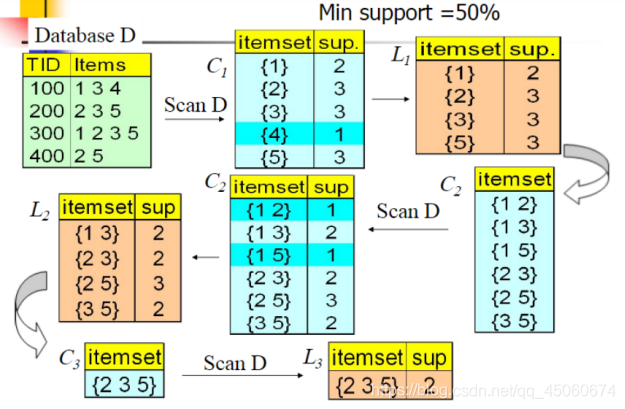
该算法的主要挑战:
要对数据进行多次扫描
会产生大量的候选项集
对候选集支持度的计算很繁琐
解决思路:
减少扫描次数(FP树)
缩小产生的候选项集
改进对候选项支持度的计算方法
3.示例
1.给定下表所示的一个数据库,写出 Apriori 算法生成频繁项目集的过程。(假定最小支持度=0.5)




不产生候选频繁项集的算法-FP树
本质:分治策略
1.项头表的建立
注意对项列的书写(按pointer降序排,pointer一样时可按如下字母表顺序排,这样便于后续的书写计算)


2.FP树的建立
插入第一条数据ACEBF。此时FP树没有节点,因此ACEBF是一个独立的路径,所有节点计数为1, 项头表通过节点链表链接上对应的新增节点。

插入数据ACG。由于ACG和现有的FP树可以有共有的祖先节点序列AC,因此只需要增加一个新节点G,将新节点G的计数记为1。同时A和C的计数加1成为2。当然,对应的G节点的节点链表要更新

同理,依次更新后面的数据

最终结果为:

3.FP树挖掘
1. 原理概述:
得到了FP树和项头表以及节点链表,如何从FP树里挖掘频繁项集。首先要从项头表的底部项依次向上挖掘。对于项头表对应于FP树的每一项,我们要找到它的条件模式基。
所谓条件模式基是以我们要挖掘的节点作为叶子节点所对应的FP子树。
得到这个FP子树,我们将子树中每个节点的的计数设置为叶子节点的计数,并删除计数低于支持度的节点。从这个条件模式基,就可以递归挖掘得到频繁项集了
2. 应用
从最底下的F节点开始,我们先来寻找F节点的条件模式基,由于F在FP树中只有一个节点,因此候选就只有下图左所示的一条路径,对应{A:8,C:8,E:6,B:2, F:2}。
我们接着将所有的祖先节点计数设置为叶子节点的计数,即FP子树变成{A:2,C:2,E:2,B:2, F:2}。一般我们的条件模式基可以不写叶子节点,因此最终的F的条件模式基如下图所示。

通过它,很容易得到F的频繁2项集为{A:2,F:2}, {C:2,F:2}, {E:2,F:2}, {B:2,F:2}。递归合并二项集,得到频繁三项集为{A:2,C:2,F:2},{A:2,E:2,F:2},…还有一些频繁三项集,就不写了。当然一直递归下去,最大的频繁项集为频繁5项集,为{A:2,C:2,E:2,B:2,F:2}
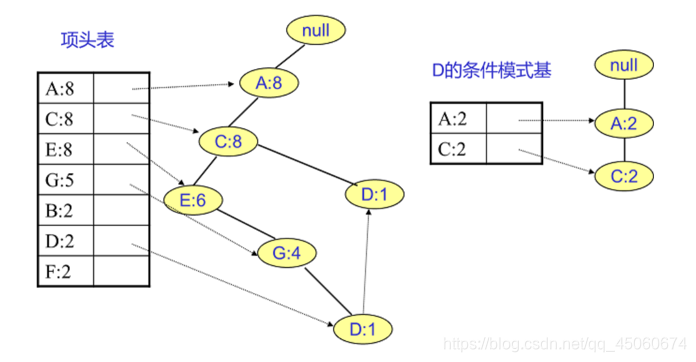
D节点比F节点复杂一些,因为它有两个叶子节点,首先得到的FP子树如下图左。接着将所有的祖先节点计数设置为叶子节点的计数,即变成{A:2, C:2,E:1 G:1,D:1, D:1}此时E节点和G节点由于在条件模式基里面的支持度低于阈值,被我们删除,最终在去除低支持度节点并不包括叶子节点后D的条件模式基为{A:2, C:2}。
通过它,我们很容易得到F的频繁2项集为{A:2,D:2}, {C:2,D:2}。递归合并二项集,得到频繁三项集为{A:2,C:2,D:2}。D对应的最大的频繁项集为频繁3项集。

其他节点的条件模式基依次如下:




FP树结构的好处
完整性
- 不会打破任何事务数据中的长模式
- 为频繁模式的挖掘保留了完整的信息
紧凑性
- 减少了不相关的信息——非频繁的项被删除
- 按频率递减排列——使得更频繁的项更容易在树结构中被共享 数据量比原数据库要小
附:python代码(关联规则)
import pandas as pd
import numpy as np
from mlxtend.preprocessing import TransactionEncoder
from mlxtend.frequent_patterns import apriori, association_rules
pd.set_option('display.unicode.ambiguous_as_wide', True)
pd.set_option('display.unicode.east_asian_width', True)#对齐
pd.set_option("display.max_columns",None)#显示所有行
pd.set_option("display.max_rows",None)
raw_data = np.genfromtxt(
'https://media-zip1.baydn.com/storage_media_zip/qkklny/a77f0c6443b6f5594b8f80d4aa7dfed1.42db6c0445109c28f3e3b9ad444e1ea6.csv',
delimiter=',',
skip_header=True,
dtype=None,
encoding='utf8'
)
# 处理后的数据
dataset = []
for row in raw_data:
# 去除空数据
new_row = [v for v in row if v != '']
dataset.append(new_row)
te = TransactionEncoder() #对交易记录进行编码
encorder = te.fit(dataset) #统计唯一的商品列表
one_hot_encoded_array = encorder.transform(dataset) #热编码
df = pd.DataFrame(one_hot_encoded_array, columns=encorder.columns_)
#print(df)
#1.找出支持度大于0.3的商品,仅对它们进行分析
frequent_itemsets = apriori(df, min_support=0.3, use_colnames=True)
#2.找置信度大于0.5的关联规则
rules = association_rules(frequent_itemsets, metric="confidence",min_threshold=0.5) #metric:作为条件的数据指标
#3显示满足条件的规则,按提升度从高到低排序
print(rules.sort_values("lift",ascending=False))
#df.to_csv(r"C:\Users\JSJSYS\Desktop\data.csv",index=False,encoding="utf-8")#保存数据
关联分析是数据挖掘中独具特色的技术,因关联规则不受因变量个数的限制,故能在大型数据库中发现数据之间的关联关系,应用很广泛。但关于关联分析输出规则的解释与应用,我们仍不得不谨慎对待。


















 1455
1455

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









