







论文地址:Deep learning for drug repurposing: Methods, databases, and application
本文是一篇利用深度学习方法和工具进行药物重定位主题的综述文章。
1. Introduction
药物重定位:从已批准或已确立的临床药物中有效识别新适应症。
总的来说,药物再利用在药物发现过程中提供了多种优势,例如失败风险更低、投资更少和开发时间更短。最近,药物发现和开发中可用的化学和生物医学数据数量稳步增加。如何有效地挖掘大规模领域数据成为药物再利用的关键任务。不同于传统的机器学习技术,深度学习的优势在于它能够从大规模数据中学习输入特征和输出决策之间的复杂关系,这得益于硬件设备计算能力的不断增强。特别是,深度学习方法可以仅从其输入数据自动学习多个级别的表示,而无需额外的用户输入。尽管它们在药物再利用中的应用仍处于初级阶段,但已经显示出巨大的潜力。
我们首先总结了与药物再利用相关的广泛使用的数据库。然后,我们分别简要概述了基于序列和基于图的表示方法。此外,我们还研究了两种药物再利用深度学习模型,基于目标和基于疾病。我们还全面概述了药物再利用技术的几种应用,包括2019年冠状病毒病(新冠肺炎),一种由严重急性呼吸综合征冠状病毒2(SARS-CoV-2)引起的传染病。最后,我们强调了药物再利用方面深入学习未来发展面临的挑战。
2. Database
KEGG(京都基因和基因组百科全书)是一个综合数据库,包含来自基因、蛋白质、生物途径和人类疾病的大规模分子数据集,用于更好地理解生物系统的高级功能和应用。
DrugBank是一个综合数据库,它将详细的药物信息与相应的药物靶点相结合。最新发布的版本DrugBank(V5.1.7)包含13791个药物条目,其中包含2653个经食品和药物管理局(FDA)批准的小分子药物。
Pubchem是一个化学分子及其生物检测活性的数据库。它由三个动态增长的初级数据库组成,其中包括1.1亿个化合物、2.71亿种物质和2.97亿种生物活性物质。
常用的数据库如下表所示:
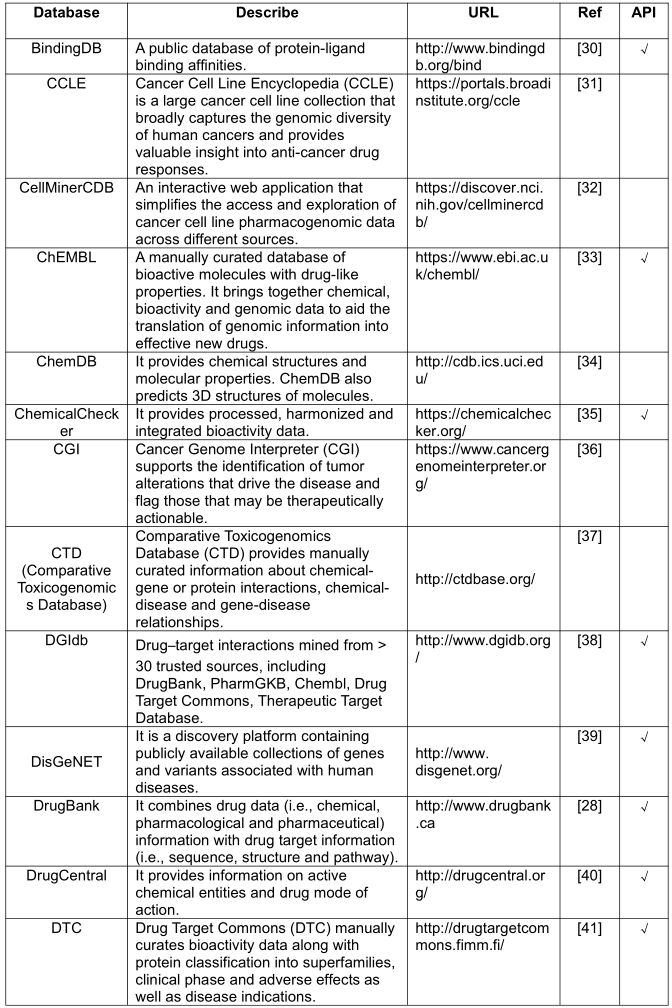
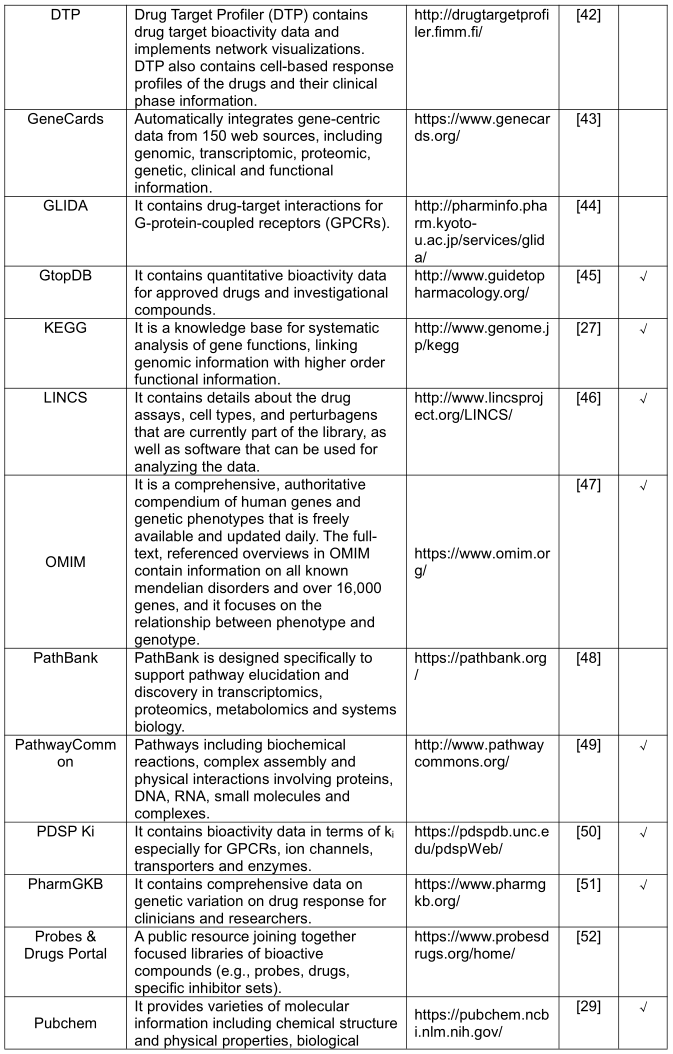
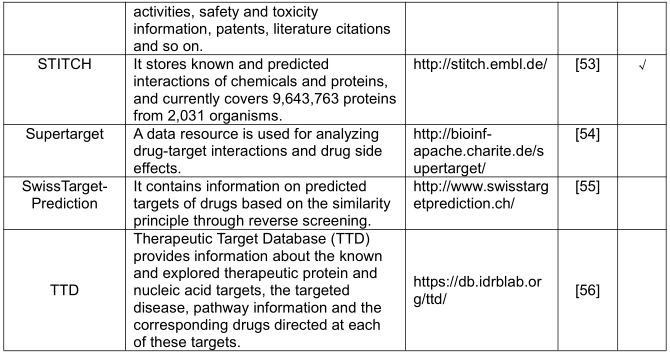
本综述涵盖的数据库可分为四大类,包括化学、生物分子、药物靶点相互作用和疾病数据库。为了更好地利用这些数据,主要考虑的是易于下载或易于通过 API 访问的在线公开可用的数据集。例如,DrugBank 提供药物-靶标相互作用数据,可以通过阅读其描述和检查数据统计获得,但它还提供临床、药物分类、化学结构、途径和药物组合信息。实际上,深度学习非常适合集成异构数据源。最近一项名为 CDRscan 的研究被提议与来自 CCLE 的基因组数据、来自 GDSC 的药物反应分析数据、基于结构指纹的虚拟对接以及来自 DrugBank 的定量结构-活性关系(QSAR)信息相结合。它可以预测1487种批准的药物的抗癌活性,这导致 14 种肿瘤药物和 23 种非肿瘤药物具有新的潜在癌症适应症。此外,考虑更多的组学数据可以进一步为电子药物重新定位创造新的机会。
AOPEDF 旨在分别从 DrugBank、TTD 和 PharmGKB 收集物理药物靶标相互作用,利用来自 ChEMBL 和 BindingDB 的药物靶标对的生物活性数据,并从 DrugBank 提取 SMILES 格式的每种药物的化学结构。它根据唯一的 UniProt 登录号和结合亲和力阈值对数据进行清理,以构建涵盖化学、基因组和表型数据源的异构网络。构建了级联深度森林分类器来推断新的 DTI,该分类器在从 DrugCentral 和 ChEMBL 收集的两个外部验证集上实现了高精度。与依赖于使用矩阵分解或网络建模构建复杂特征的方法相比,这里我们只关注依赖于原始数据的深度学习方法(即针对药物的 SMILES 和针对靶点的蛋白质序列),这些方法可以通过设计高效的表示学习(即基于序列的方法和基于图形的方法)来自动提取分子特征。
3. Representation Learning
表征学习是指从原始数据中自动发现特征提取或分类所需的表示,是端到端深度学习的基本步骤之一。用于药物再利用的表征学习主要分为基于序列的方法和基于图形的方法。
3.1 Sequence-based representation
基于序列的表征学习方法可以克服部分现有蛋白质/靶结构数据的局限性和昂贵的分子对接模拟的要求,而现有的蛋白质和分子序列的生物数据为快速推进药物再利用提供了可能性。对于分子化合物,1D表示—SMILES,基于化学键规则的拓扑信息的文本符号。2D表示—化学指纹,反复搜索每个原子周围的部分结构,然后使用哈希函数将分子转换为二元向量。但是生成的向量不仅高维而且稀疏话可能产生"位冲突"。基于序列的表示方法不考虑化合物的三维结构。
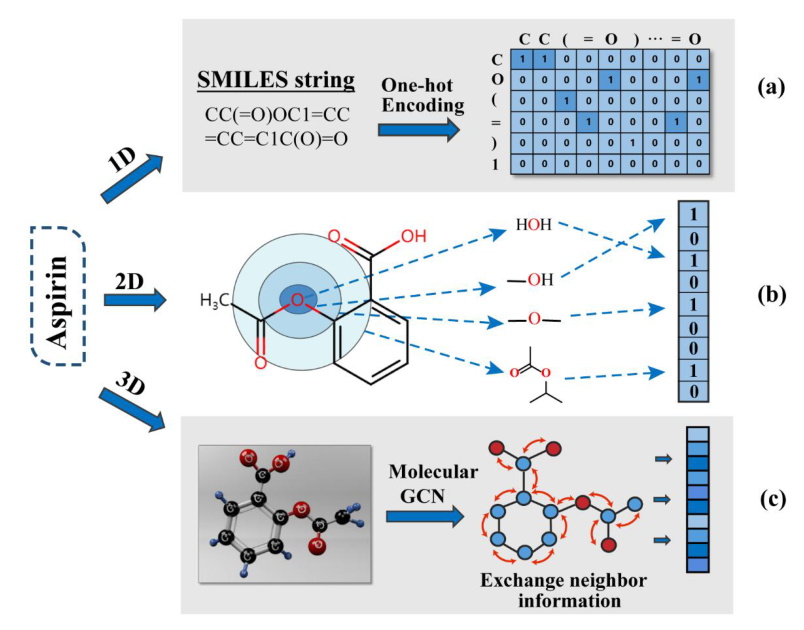
3.2 Network/graph-based representation learning
最近,图神经网络已经发展为用于图形相关任务的最先进的方法,其优点是通过考虑相邻节点的结构并聚合层间信息自动提取潜在特征。另一种很有前途的技术,称为网络嵌入,被用来学习全局特征。具体来说,它通常将节点、边及其特征映射到向量,从而最大限度地保留全局属性(例如结构信息)。一旦获得节点表示,深度学习模型就可以应用于基于网络的任务,包括节点分类、节点聚类和链接预测。另一种重要的基于图形的深度学习方法,称为概率图,它结合了各种神经生成模型、基于梯度的优化和神经推理技术。此外,在生物序列上训练的变分自动编码器(VAE)已被证明能够学习对各种下游任务有益的生物意义表示。简而言之,VAE是自动编码器的变体,它在输入空间和潜在空间之间提供了一个随机映射。该映射在训练期间进行了正则化,以确保其潜在空间能够生成一些新数据。
4. Deep Learning Models for Drug Repurposing
药物再利用工具通常旨在预测未知的药物靶点或药物与疾病的相互作用,这可以分为 以靶点为中心 或 以疾病为中心 的方法。靶捕获策略编码了药物的化学结构以筛选靶蛋白,从而提供了详细的多药理学解释。然而,单一的预测目标不能完全描述疾病的特征。因此,有效地识别药物与疾病之间的联系对于理解潜在的生物学机制至关重要。每种方法都提出了信息学的独特挑战,本综述分别侧重于过去几年中用于药物再利用中基于目标的和基于疾病的深度学习方法。
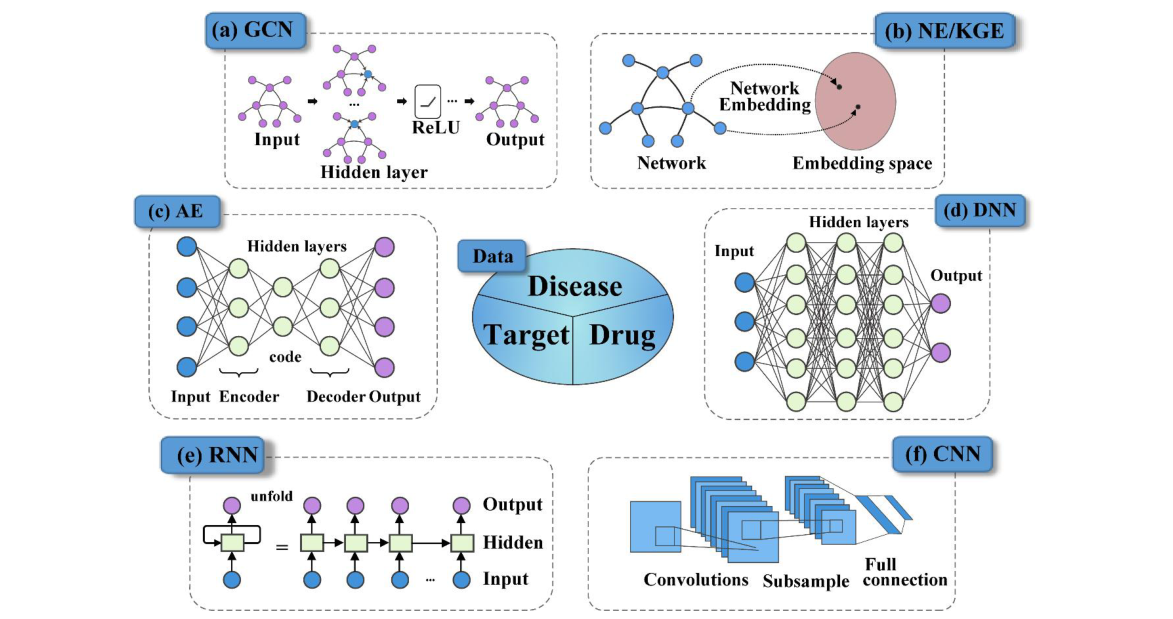
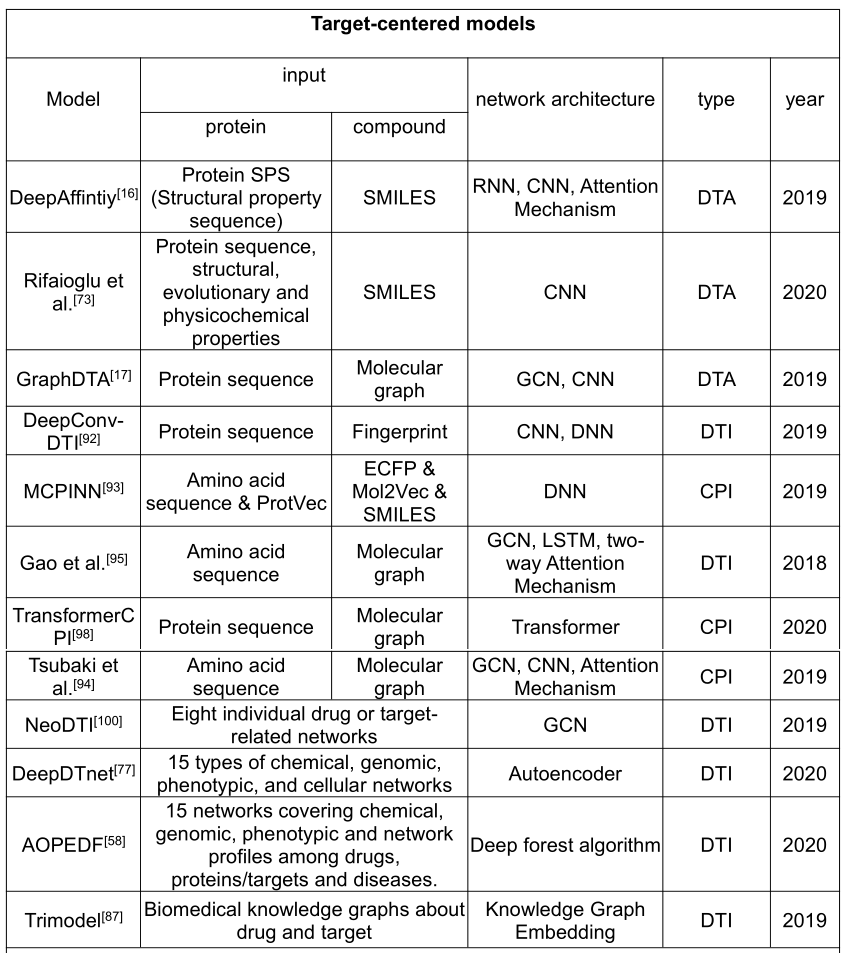
4.1 Target-centered models
卷积运算用于对不同长度的氨基酸序列进行操作,并捕获在药物靶点相互作用(DTI)预测中起关键作用的广义蛋白质类的局部残基模式。为了充分利用复合蛋白相互作用(CPI)数据,提出了一种新的 基于多通道PCM的DNN(d),名为 MCPINN,用于预测 DTI。它使用了特征抽取器、端到端学习器和分类器三个模块,以化合物 SMILES、ECFPs 和 Mol2vec 嵌入的载体以及ProtVec嵌入的氨基酸序列作为输入。Tsubaki等人通过 结合化合物的 GNN 和蛋白质的 CNN(f),开发了一种新的 CPI 预测端到端方法,可以学习分子图和蛋白质序列的低维真值矢量表示。Gao等人利用 LSTM 和 GCN(a)分别将蛋白质和药物结构投影到向量空间,并使用双向注意力机制来计算蛋白质-药物结构对如何相互作用,从而实现可解释性。然而,基于序列的CPI模型仍有一些局限性,例如分裂方法以及隐藏的配体偏差,这导致预测性能被高估。为了解决这些局限性,提出了一种具有名为TransformerCPI的自我注意机制的转换器架构,其中使用GCN来学习每个原子的表示,并通过嵌入将蛋白质转换为序列表示。与以前的模型相比,TransformerCPI在更严格的标签反转实验中取得了最佳性能。
基于网络的方法已被用来识别已知药物的靶点,以帮助对抗副作用并加速药物的再利用。例如,Luo等人首先采用无监督方法从异构网络中学习药物和靶点的低维向量表示,然后采用归纳矩阵完成法预测新的DTI。
然而,将特征学习与预测任务分离可能不会产生最佳解决方案。
随后,该小组进一步提出了一种基于神经网络的 DTI 预测方法,称为 NeoDTI。NeoDTI 集成了异构网络中节点的邻域信息,并自动学习药物和靶点的拓扑保持表示。然而,这些方法往往只保留局部邻近性。因此,采用 deep 自动编码器从异构网络中自动学习高质量特征,Zeng等人采用正无标记矩阵补全来预测新的DTI,称为deepDTnet,该DTI集成了大型生物医学网络数据集,用于目标识别,并将药物开发中的翻译差距降至最低。对比实验表明,所提出的deepDTnet在识别已知药物的新分子靶点方面达到了0.963的高 AUC-ROC 度量,优于传统的机器学习方法,包括随机森林(0.911)、SVM(0.869)、k近邻(0.839)和Naive Bayes(0.783)。此外,与 deepDTnet 不同的是,提出了一个名为 AOPEDF 的基于深度学习的框架,它是一个嵌入深度森林的任意阶邻近度,用于预测 DTI。具体而言,它构建了9个药物网络,包括临床报道的药物-药物相互作用,以考虑不同网络的互补顺序邻近信息,并且它还以较少的超参数实现了更高的性能。此外,在一个案例研究中显示,AOPEDF预测的多个分子靶点与几种上市药物(如阿立哌唑)的药物滥用障碍的作用机制有关。
通过烧蚀实验进一步分析了其潜在优势。特别是,它被 LINE(即LINE1st和LINE2nd)代替进行特征提取,并将设计的深度森林分类器与具有相同特征的传统方法进行了比较,包括支持向量机、随机森林和深度神经网络,其中,结果表明,AROPE 保留的高阶近似值可以为分类提供更有效的信息,而深森林分类器的性能最佳。利用当前可用的知识库生成生物实体的知识图谱(KG),并分别使用一个称为 Trimodel 的特定 KG 嵌入模型来学习药物和靶点的低维矢量表示。当然,DTI 预测也可以建模为以KG为单位的链路预测。上述大多数研究都侧重于二分类,其目标是确定药物-靶点对是否相互作用。虽然蛋白质-配体相互作用(PLIs)可以预测结合亲和力值,但药物再利用更具挑战性。例如,利用结构注释蛋白质序列(SPS)的新表示,Karimi等人提出了一种称为DeepAffinity的半监督深度学习模型。DeepAffinity统一了RNN(e)和CNN,共同编码分子表示,并使用未标记和标记数据预测亲和力。此外,DeepAffinity 引入了一些注意机制,通过分离分子片段或其主要贡献者来解释预测,可以进一步应用于预测结合位点和结合特异性来源。GraphDTA也用于预测 DTA(药物靶点结合亲和力),但不同之处在于,使用 GNN 而不是 CNN 来学习化合物的表示。然而,在上述方法中,蛋白质的物理、化学和生物特性通常被忽略。因此,Rifaioglu等人提出了一种新的蛋白质特征化方法,该方法将多种类型的蛋白质特征(如序列、结构、进化和物理化学性质)集成到二维向量中,并在 CPA(复合蛋白质亲和力)预测性能方面取得了显著改进。
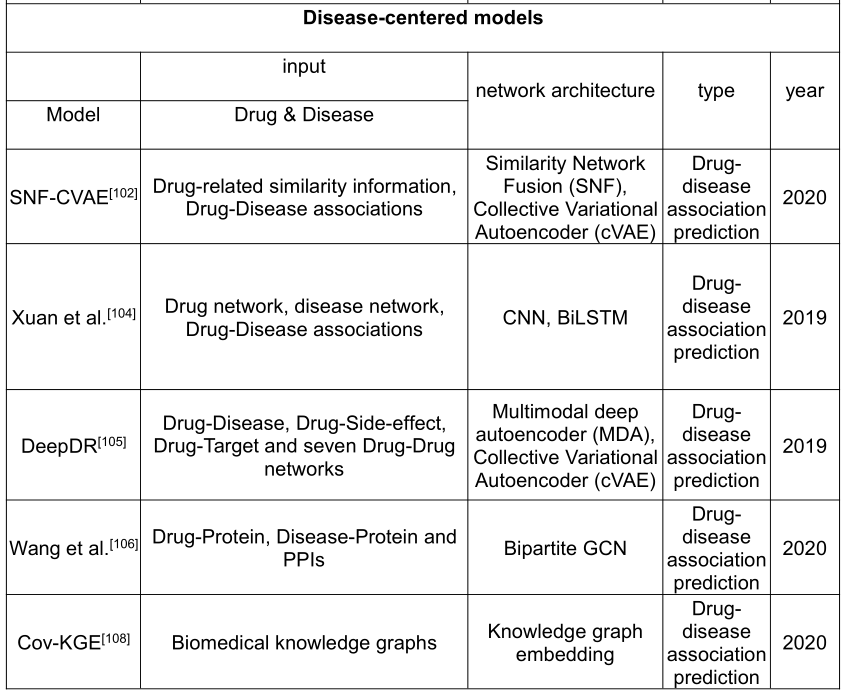
4.2 Disease-centered models
确定药物-疾病对之间的相互作用对于以疾病为中心的药物再利用至关重要。目前,现有方法大致可分为基于相似性的方法和基于网络的方法。
SNF-CVAE 集成了相似性度量、相似性选择、相似性网络融合(SNF)和集合变分自动编码器(CVAE)进行非线性分析,提高了药物-疾病相互作用预测的准确性。
Xuan等人提出了一种基于 CNN 和 BiLSTM 的药物再利用新方法,其中基于 CNN 的模块用于从药物疾病对的相似性和关联性中学习其原始表示;然而,基于 BiLSTM 的模块被用于学习药物疾病的路径表示,以通过注意机制平衡不同路径的贡献。此外,开发了一种基于网络的深度学习方法,称为 deepDR(c),用于电子药物再利用。具体来说,它首先通过多模式深度自动编码器从10个网络中学习药物的高级特征。然后结合临床报告的药物-疾病对,对学习到的药物表示进行编码,最后由可变自动编码器解码,以推断候选药物。然而,deepDR 只考虑药物领域的信息源,而不考虑疾病领域的相互作用。
4.3 Model evaluation
药物再利用的任务大致分为分类和回归。对于回归任务,采用均方根误差(RMSE)、平均绝对误差(MAE)和一致性指数(CI)来评估模型性能。

对于分类任务,采用准确度、接收器工作特性曲线下的面积(AUC-ROC)、精确召回曲线下的区域(AUPR)和F1分数来评估模型性能。
此外,还有几个系统基准和平台可以加速机器学习模型的开发、验证和过渡到生物医学和药物发现。例如:开发了一个名为 MoleculeNet 的大规模分子机器学习基准,为之前提出的多个分子特征化和学习算法提供高质量的开源实现。同时,设计了一个全面且易于使用的深度学习库来预测药物-靶标相互作用(DTI),它通过实现15个化合物和蛋白质编码器以及50多个神经架构来支持定制DTI预测模型的训练,并提供许多其他有用的功能。最近,发布了第一个名为Therapeutics Data Commons(TDC)的统一框架,以系统地访问和评估整个治疗范围内的机器学习。
5. Concluding Remarks and Future Challenges
与传统的依赖领域知识手动构建分子描述符的机器学习方法相比,深度学习可以从简单的输入中自动学习,并提取化学结构的特定任务表示。然而,深度学习方法的局限性在于需要大规模、高质量的数据集来进行模型训练,以及为了揭示预测背后的生物学意义而需要的可解释性。尽管传统的机器学习方法可以很好地解决某些领域的特定任务,但随着数据的爆炸性增长和AlphaFold2的成功登陆,有理由相信,深度学习将在不久的将来为药物再利用带来里程碑。
药物再利用的深度学习方法的一个主要挑战是 数据质量。深度学习方法需要大型数据库用于模型训练。而生物医学数据实际上由于较高的噪声、不完整性和不精确性而趋于不确定性。
新的深度学习方法最重要的挑战仍然是 可解释性,特别是在药物再利用方面。由于深层神经网络的复杂性,它总是难以为药物发现和开发社区提供生物学解释。在生物信息学和健康相关领域,重要的是评估模型性能,并通过可解释性更好地理解潜在机制。微妙架构的设计必须考虑到解释或可视化复杂关系,这也被视为深入学习药物再利用的挑战和机会。一个潜在的方向是采用 注意机制,其中模型系数可以推断出每个特征的相对“重要性”,另一个方向可能是 可视化网络或其内部机制 以提供可解释性。

















 6543
6543

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









