







1.阻塞队列简介
1.1 什么是阻塞队列?
阻塞队列是一个队列
- ①:当队列是空的,从队列中获取元素的操作将会被阻塞,直到其他线程插入新元素
- ②:当队列是满的,从队列中添加元素的操作将会被阻塞,直到其他线程取出队列元素
1.2 阻塞队列和栈的区别?
- 栈:先进后出、后进先出
- 队列:先进先出
1.3 阻塞队列有什么用处?
在有阻塞队列之前,线程并发时,我们需要自己去控制什么时候阻塞线程,什么时候唤醒线程,还要兼顾效率和安全。增加开发难度。阻塞队列使我们不用关心线程的阻塞和唤醒,它帮我们一手包办了这个过程,使我们更注重业务逻辑。
1.4 阻塞队列分类
ArrayBlockingQueue:由数组结构组成的有界阻塞队列。LinkedBlockingQueue:由链表结构组成的有界(但大小默认值为integer.MAX_VALUE)阻塞队列。虽有最大值,但基本也算无界了PriorityBlockingQueue:支持优先级排序的无界阻塞队列。DelayQueue:使用优先级队列实现的延迟无界阻塞队列。SynchronousQueue:不存储元素的阻塞队列,也即单个元素的队列。LinkedTransferQueue:由链表组成的无界阻塞队列。LinkedBlockingDeque:由链表组成的双端阻塞队列。
1.5 线程池中如何选择阻塞队列?
当任务耗时较长时可能会导致大量新任务在队列中堆积时,尽量不要使用无界阻塞队列。如LinkedBlockingQueue最大值为Integer.max,一直堆积的话肯定会OOM,Executors.newFixedThreadPool 采用就是 LinkedBlockingQueue,当QPS很高,发送数据很大,大量的任务被添加到这个无界LinkedBlockingQueue 中,导致cpu和内存飙升服务器挂掉。
当任务堆积严重时,可以使用遵循FIFO先进先出原则的队列如ArrayBlockingQueue,适当通过拒绝策略阻止任务继续他添加。虽然会有部分任务被丢失,但是配合日志搜集系统,对部分对丢失是可以容忍的。
如果不希望任务在队列中等待而是希望将任务直接移交给工作线程,可使用SynchronousQueue作为等待队列。SynchronousQueue不是一个真正的队列,而是一种线程之间移交的机制。要将一个元素放入SynchronousQueue中,必须有另一个线程正在等待接收这个元素。只有在使用无界线程池或者有饱和策略时才建议使用该队列。
1.6 阻塞队列核心API
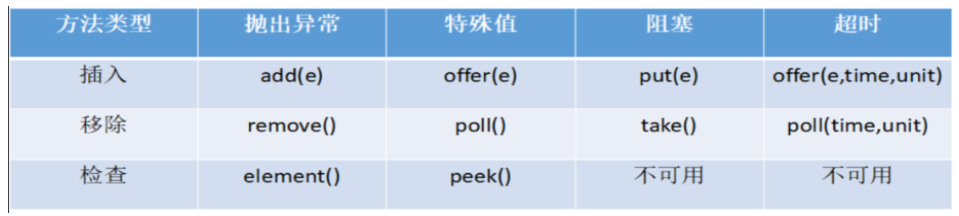
| 方法结果 | 方法详情 |
|---|---|
| 抛出异常 | 当阻塞队列满时,再往队列里add插入元素会抛IllegalStateException:Queue full 当阻塞队列空时,再往队列里remove移除元素会抛NoSuchElementException |
| 特殊值 | 插入方法,成功ture失败false 移除方法,成功返回出队列的元素,队列里没有就返回null |
| 阻塞 | 当阻塞队列满时,生产者线程继续往队列里put元素,队列会一直阻塞生产者线程直到put数据or响应中断退出 当阻塞队列空时,消费者线程试图从队列里take元素,队列会一直阻塞消费者线程直到队列可用 |
| 超时 | 当阻塞队列满时,队列会阻塞生产者线程一定时间,超过限时后生产者线程会退出 |
1.7 BlockingQueue的应用
应用场景为:线程池、Eureka的三级缓存、Nacos、Netty、MQ等!
2. BlockingQueue源码分析
2.1 BlockingQueue的架构如下
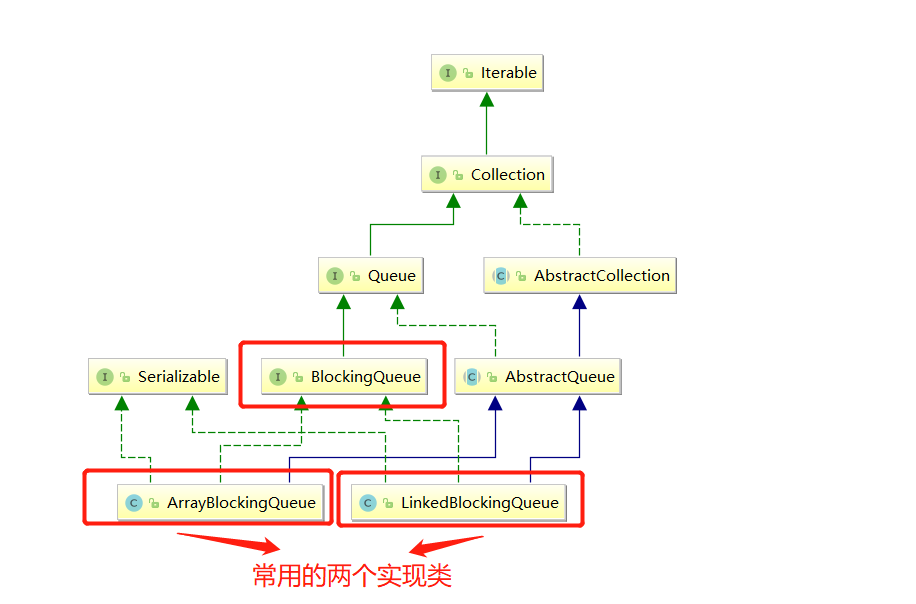
BlockingQueue是线程通信的一个工具,在任意时刻,不管并发有多高。在单jvm上,同一时间永远只有一个线程能对队列进行入队或出队操作,它是一个线程安全的队列!
那么BlockingQueue是怎么保证线程安全的呢?下面深入源码来看:
//创建一个ArrayBlockingQueue
BlockingQueue<Integer> queue = new ArrayBlockingQueue<>(10);
//内部构造器源码如下
public ArrayBlockingQueue(int capacity, boolean fair) {
if (capacity <= 0)
throw new IllegalArgumentException();
this.items = new Object[capacity]; //开辟一个容量为capacity大小的对象数组
lock = new ReentrantLock(fair); //创建一个ReentrantLock非公平锁,因为fair为false
notEmpty = lock.newCondition(); //取数据时的等待条件--数组不为空
notFull = lock.newCondition(); //插数据时的等待条件--数组没放满
}
生产者往对象数组中插数据的put()方法 源码如下:
public void put(E e) throws InterruptedException {
checkNotNull(e);
//获取锁
final ReentrantLock lock = this.lock;
//生产者给当前的put操作加锁
lock.lockInterruptibly();
try {
//如果元素的个数等于数组长度,表示数组已放满
while (count == items.length)
//调用AQS的await()方法,生产者入队、阻塞并释放锁
notFull.await();
//如果数组没放满,就放入对象数组,并发出signal通知消费者争抢
enqueue(e);
} finally {
lock.unlock();
}
}
消费者往对象数组中取数据的take()方法 源码如下:
public E take() throws InterruptedException {
final ReentrantLock lock = this.lock;
//消费者获取锁
lock.lockInterruptibly();
try {
//当对象数组为空
while (count == 0)
//调用AQS的await()方法,消费者者入队、阻塞并释放锁
notEmpty.await();
//消费一个数据并发出signal通知生产者生产数据
return dequeue();
} finally {
lock.unlock();
}
}
流程总结:
- ①:首先创建一个长度为
capacity的对象数组,用于存储数据资源 - ②:生产者生产数据到
capacity中时,用ReentrantLock公平锁来保证并发安全 - ③:生产者生产数据时,
- 如果
capacity数组没满,就往里边放数据,并发出signal标记通知消费者争抢; - 如果
capacity数组满了,调用AQS的await()方法,使生产者线程进入条件等待队列,并释放掉手中的锁。
- 如果
④:消费者同理
lock.lock()和lock.lockInterruptibly()的区别是什么?
ReentrantLock的中断和非中断加锁模式的区别在于:线程尝试获取锁操作失败后,在等待过程中,如果该线程被其他线程中断了,它是如何响应中断请求的。
-
lock.lock():正常加锁,会忽略中断请求,继续争抢锁直到成功,在成功获取锁之后,再根据中断标识为true或者false,自己处理中断,即selfInterrupt中断自己。public final void acquire(int arg) { if (!tryAcquire(arg) && acquireQueued(addWaiter(Node.EXCLUSIVE), arg)) //根据中断标识,自己中断自己! selfInterrupt(); } -
lock.lockInterruptibly():加可中断锁,即在锁获取过程中不处理中断状态,而是直接抛出中断异常,由上层调用者处理中断public final void acquireInterruptibly(int arg) throws InterruptedException { //如果线程被中断,直接抛出中断异常 if (Thread.interrupted()) throw new InterruptedException(); if (!tryAcquire(arg)) doAcquireInterruptibly(arg); }
那么,为什么要分为这两种模式呢?
这两种加锁方式分别适用于什么场合呢?
lock()适用于锁获取操作不受中断影响的情况,此时可以忽略中断请求正常执行加锁操作,因为该操作仅仅记录了中断状态(通过Thread.currentThread().interrupt()操作,只是恢复了中断状态为true,并没有对中断进行响应)。- 如果要求被中断线程不能参与锁的竞争操作,则此时应该使用
lockInterruptibly方法,一旦检测到中断请求,立即返回不再参与锁的竞争并且取消锁获取操作(即finally中的cancelAcquire操作)
3. 生产者消费者模型如何保证信息不会丢失?
BlockingQueue的生产者消费者模型,通过控制capacity对象数组的大小,可以达到流量削峰的效果。可以在自己系统的内部达到一种MQ的效果。
在开发之前我们先要结合自己项目的业务场景设计出一个临时任务表,以保证任务的“安全”。
设计思路如下:
①:在数据库设计一个临时任务表,字段包括(主键id、需要处理的业务id、业务是否放入BlockingQueue、创建时间等)。把需要处理的任务先放入这个临时任务表中。
@Data
public class TestTempMo {
// id
private Integer id;
// 待处理业务的Id
private Integer logicId;
// 是否塞入任务队列
private Boolean isTask;
// 创建时间
private Date createDate;
}
②:定义一个单例的阻塞队列BlockingQueue,生产者无限循环从临时表中取出一批任务,放入BlockingQueue,并更新临时表任务状态,防止重复入队。
单例BlockingQueue:
public class BlockingQueueUtils {
public static volatile BlockingQueue<TestTempMo> testTaskQueue;
private BlockingQueueUtils() {}
public BlockingQueue<TestTempMo> getInstance() {
if (Objects.isNull(testTaskQueue)) {
synchronized (this) {
if (Objects.isNull(testTaskQueue)) {
int cpuCores = Runtime.getRuntime().availableProcessors();
testTaskQueue = new ArrayBlockingQueue<>(cpuCores * 10);
}
}
}
return ocrScanTaskQueue;
}
}
生产者生产任务入队:
@Override
@Transactional(rollbackFor = Throwable.class)
public void run() {
//循环取
while(true) {
//从临时表取一批任务
List<TestTempMo> taskTempMoList = produceTaskBatch();
if(CollectionUtils.isNotEmpty(taskTempMoList)) {
for (TestTempMo taskTempMo : taskTempMoList) {
//将任务塞入阻塞队列
testTaskQueue.put(taskTempMo);
//改变临时表状态,防止重复塞入任务队列
taskTempMo.setIsTask(true);
//更新临时表
testTempMapper.updateByPrimaryKeySelective(taskTempMo);
}
}
}
③:消费者从阻塞队列BlockingQueue中取出任务进行消费,并删除临时表任务,代表当前任务已结束。
@Override
public void run() {
while(true) {
//从阻塞队列里取出任务(如果没有任务这里会阻塞)
TestTempMo taskTempMo = acquireTask();
//使用线程池多线程处理任务
ThreadPoolUtil.TestPool.execute(() -> {
//具体的消费逻辑
consume(taskTempMo);
//删除任务表数据
selectForMasterMapper.delScanTemp(taskTempMo.getId());
});
}
}
④:为了防止服务器重启时有未处理的任务处理不掉,需要在生产者的初始化方法中对临时表的状态进行初始化。
/**
* 初始化临时表状态(每台机器只负责自己的任务)
*/
private void initTempTaskState(){
//取出所有任务状态为true的任务
TestTempExample example = new TestTempExample();
example.createCriteria().andIpEqualTo(ExternalOcrConstant.IP).andIsTaskEqualTo(true);
List<TestTempMo> testTempMos = testTempMapper.selectByExample(example);
//存在遗留数据
if (CollectionUtils.isNotEmpty(testTempMos)){
for (TestTempMo testTempMo : testTempMos) {
//修改true===>false
testTempMo.setIsTask(false);
//将临时表状态改为初始状态
testTempMapper.updateByPrimaryKeySelective(testTempMo);
}
}
}
当然仅仅只有上边这些代码这个模型还是不够可靠的,因为如果集群中某台机器宕机的话则该台机器上的所有未处理完成的任务都会停止执行,因此这个时候就需要其他的兄弟进行“接盘”操作了,比如zookeeper,下次再絮















 1227
1227











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









