







Spark
简介
Spark是一种基于内存的快速、通用、可扩展的大数据分析引擎。
内置模块

SparkCore:实现了Spark的基本功能,包含任务调度、内存管理、错误恢复、与存储系统交互等模块。SparkCore中还包含了对弹性分布式数据集(RDD)
SparkSQL:是Spark用来操作结构化数据的程序包。通过SparkSQL,我们可以使用SQL或HQL来查询数据。支持多种数据源:Hive、Parquet、JSON
SparkStreaming:是Spark提供的对实时数据进行流式计算的组件,提供了用来操作数据流API,并且与SparkCore中的RDD高度对应
SparkMlb:提供常见的机器学习功能的程序库。包括分类、回归、聚类、协同过滤等,还提供了模型评估、数据导入等额外功能
集群管理器:Spark可以搞笑的在一个计算节点到数千个计算节点之间神所计算。为了实现这样的要求,同时还不会丧失灵活性,Spark支持在各种集群管理器(Cluster Manager)上运行:Hadoop YARN、Apache Mesos,以及一个自带的建议调度器独立调度器
Spark特点:
1.快:与Hadoop的MR相比,Spark基于内存的运算要快100倍以上,基于硬盘的运算也要快10倍以上。Spark实现了高效的DAG执行引擎,可以通过基于内存来高效处理数据流。计算的中间结果存在于内存中。
2.易用:支持Java、Python和Scala的API,还支持超过80种高级算法,使用和可以快速构建不同的应用。
3.通用:Spark提供了一种统一的解决方案。Spark可以用于批处理、交互式查询(Spark SQL)、实时流处理(Spark Streaming)、机器学习(Spark MLib)、图计算(GraphX)。这些不同类型的处理都可以在同一个应用中无缝使用,减少了开发和维护的人力成本.
4.兼容性:Spark可以非常方便的与其它开源产品进行融合,比如,Spark可以使用Hadoop的Yarn和Apache的Mesos作为它的资源管理和调度器,并且可以处理所有Hadoop支持的数据,包括HDFS、Hbase等。不需要任何数据迁移。
、
Spark中重要角色
1.Driver:驱动器
Spark的驱动器是执行开发程序中的main方法的进程,负责开发人员编写的用来创建SparkContext、创建RDD、以及进行RDD的转换操作和行动操作代码的执行。(当启动Spark Shell时,后台会自启一个Spark驱动器程序,就是在Spark中预加载了一个叫sc的SparkContext对象。如果驱动器程序终止,那么Spark应用也就结束了)
主要负责:
把用户程序转为作业(JOB)
跟踪Exector的运行状况
为执行器节点调度任务
UI栈实应用运行状态
2.Exector:执行器
是一个工作进程,负责在Spark作业中运行任务,多个任务间相互独立。Spark应用启动时,Exector节点被同时启动,并且始终伴随着整个Spark应用的生命周期而存在。如果Exector节点发生了故障或者崩溃Spark应用也可以继续执行,会将出错节点上的任务调度到其它Executor节点上继续运行。
主要负责:
负责运行组成Spark应用的任务,并将结果返回给驱动进程
通过自身的块管理器(BlockManager)为用户程序中要求缓存的RDD提供内存式存储。RDD是直接缓存在Exector进程内的,因此任务可以在运行时充分利用缓存数据加速运算。
Local模式:
上传解压直接用
local[K]:指定运算线程数量
local[*]:按照CPU核数来设置线程数
用Spark来WordCount
在bin下./spark-shell
简便写法和复杂点的
scala> sc.textFile("input").flatMap(s=>s.split(" ")).map(s=>(s,1)).reduceByKey(_+_).collect
res6: Array[(String, Int)] = Array((Java,1), (hello,3), (Scala,1), (world,1), (spark,1), (hadoop,1), (Hi,2))
scala> sc.textFile("input").flatMap(s=>s.split(" ")).map((_,1)).reduceByKey(_+_).collect
res7: Array[(String, Int)] = Array((Java,1), (hello,3), (Scala,1), (world,1), (spark,1), (hadoop,1), (Hi,2))
Yarn模式
简介:
Spark客户端直接连接Spark集群。主要有两种模式yarn-client、yarn-cluster,区别在于:Driver的运行节点
yarn-client:Driver程序在客户端,适用于交互、调试、希望立刻看到app输出
yarn-cluster:Driver程序运行在RM(ResourceManager)启动的AP(AppMaster),适用于生产环境。

1.配置yarn.site.xml
添加
vi yarn-site.xml
<!--是否启动一个线程检查每个任务正使用的物理内存量,如果任务超出分配值,则直接将其杀掉,默认是true -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<!--是否启动一个线程检查每个任务正使用的虚拟内存量,如果任务超出分配值,则直接将其杀掉,默认是true -->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
2.修改spark-env.sh
YARN_CONF_DIR=/opt/module/hadoop-2.7.2/etc/hadoop
3.将修改后的文件分发给另外两台虚拟机
[yyx@hadoop01 spark]$ xsync /opt/module/spark/conf/spark-env.sh
[yyx@hadoop01 spark]$ xsync /opt/module/hadoop-2.7.2/etc/hadoop/yarn-site.xml
4.执行Pi操作:
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode client \
./examples/jars/spark-examples_2.11-2.1.1.jar \
100
结果:
Pi is roughly 3.141909514190951
配置Yarn模式历史服务器
在spark-default.conf中开启log,并配置文件存储路径(HDFS上),以及历史服务器端口号
spark.eventLog.enabled true
spark.eventLog.dir hdfs://hadoop01:9000/directory
spark.yarn.historyServer.address=hadoop01:18080
spark.history.ui.port=18080
创建文件存储路径

配置spark-env.sh
export SPARK_HISTORY_OPTS="
-Dspark.history.ui.port=18080
-Dspark.history.fs.logDirectory=hdfs://hadoop01:9000/directory
-Dspark.history.retainedApplications=30"
启动spark历史服务
[yyx@hadoop01 spark]$ sbin/start-history-server.sh
starting org.apache.spark.deploy.history.HistoryServer, logging to /opt/module/spark/logs/spark-yyx-org.apache.spark.deploy.history.HistoryServer-1-hadoop01.out
再次执行


查看日志:
[yyx@hadoop01 ~]$ hdfs dfs -cat /directory/application_1619170866863_0001
此时,在shell中运行scala> sc.textFile("input").flatMap(s=>s.split(" ")).map(s=>(s,1)).reduceByKey(_+_).collect会报错,显示HDFS中没有这个文件,我们将文件上传
[yyx@hadoop01 spark]$ hdfs dfs -put input /input
shell运行
scala> sc.textFile("/input").flatMap(s=>s.split(" ")).map(s=>(s,1)).reduceByKey(_+_).collect
res3: Array[(String, Int)] = Array((Java,1), (hello,3), (Scala,1), (world,1), (spark,1), (hadoop,1), (Hi,2))
SparkCore
RDD
RDD叫做分布式数据集,是Spark中最基本的数据抽象,代码中是一个抽象类,代表了一个不可变、可分区、里面的元素可以并行计算的集合
RDD属性
一组分区,即数据集的基本组成单位
一个计算每个分区的函数
RDD之间的依赖关系
一个Partitioner,每个RDD的分片函数
一个列表,存储每个Paratition的优先位置
RDD特点
RDD表示只读的分区数据集,对RDD进行改动,只能通过RDD的转换操作得到一个新的RDD,新的RDD与原来的RDD之间存在依赖,RDD的执行是按照血缘关系延时执行的(是最后一个RDD向前一个要东西,这样的机制)。如果RDD的血缘关系较长我们可以通过持久化RDD来切断血缘关系。
分区
RDD逻辑上可分,每个分区的数据是抽象存在的,计算的时候会通过一个compute函数得到每个分区的的数据。如果RDD是通过已有文件系统构建,compute函数是读取指定文件系统中的数据,如果RDD是其它RDD转换得到的,compute函数是执行转换逻辑将其它RDD的数据进行转换。

只读
RDD和String类似,是只读的,要想改变RDD中的数据,只能在现有的RDD基础上创建新的RDD
算子:操作
实现一个RDD到另一个RDD的转换,可以通过操作算子实现,而不是MR的那种方式

RDD的操作算子包括两类:transformations,是用来将RDD进行转化,构建RDD的血缘关系;另一类叫actions,用来触发RDD计算,得到RDD的相关计算结果或者将RDD保存在文件系统中
缓存
如果一个程序中多次使用同一个RDD,可以将这个RDD缓存起来,该RDD只有第一次计算时会根据血缘关系得到分区的数据,在后续其他地方进行使用时回直接从缓存处取,加快后期的重用
CheckPoint
当RDD某个分区数据丢失时,会因为血缘关系重建,所以,RDD有相当好的容错性,但是对于长时间迭代来说,过长的血缘关系会非常影响性能,而且出了问题会花费很多时间去重建,影响性能。
所以RDD支持checkpoint将数据保存到持久化的存储中,这样就可以切断之前的血缘关系,checkpoint后的数据不需要直到它的父RDD是谁,而是直接从checkpoint处取数据
RDD编程
在Spark中,只有遇到action才会执行RDD的计算(延时计算),这样在运行时可以通过管道的方式传输多个转换。
RDD创建
从集合中创建、从外部存储中创建、从其它RDD创建
集合中创建
从集合中创建RDD,主要提供了两个函数parallelize和makeRDD,本质上是一样的,makeRDD底层调用了parallelize
parallelize使用:
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Spark01_makeRDD {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setAppName("new RDD").setMaster("local")
val sc: SparkContext = new SparkContext(conf)
val value: RDD[Int] = sc.parallelize(Array(11, 2, 3, 4))
value.foreach(println)
}
}
/*
11
2
3
4
*/
makeRDD:
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Spark01_makeRDD {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setAppName("new RDD").setMaster("local")
val sc: SparkContext = new SparkContext(conf)
// val value: RDD[Int] = sc.parallelize(Array(11, 2, 3, 4))
// value.foreach(println)
val value1: RDD[String] = sc.makeRDD(List("A", "B", "C", "D"))
value1.foreach(print)
}
}
/*
ABCD
*/
RDD的几个分区:
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Spark01_makeRDD {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setAppName("new RDD").setMaster("local")
val sc: SparkContext = new SparkContext(conf)
val value: RDD[Int] = sc.makeRDD(Array(1, 2, 4, 5),4)
value.saveAsTextFile("output")
}
}

默认分区数为电脑核数(makeRDD分区数默认为电脑核数和2的最小值)
可以自己设置
而sc.textFile("InputWordCount.txt")则是默认核数和2取小,不过,这个自己设置的值可能会和结果不一样,因为默认走Hadoop分片,如果分区数设为2,表示最小分区数为2,如果输入5个数,会出现三个分区。
RDD转换(重点)
RDD整体上分为Value类型和Key-Value类型
Value类型
map(func)
返回一个新的RDD,该类型RDD由每一个输入元素经过func函数转换后得到
需求:创建一个1-10的数组,将所有数组*2形成新的RDD
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Spark01_RDD_Map {
def main(args: Array[String]): Unit = {
// 创建新的RDD
val rDD_Map: SparkConf = new SparkConf().setMaster("local").setAppName("RDD_Map")
val sc: SparkContext = new SparkContext(rDD_Map)
val value: RDD[Int] = sc.makeRDD(1 to 10)
val value1 = value.map(_ * 2)
value1.foreach(x=>print(x + " "))
}
}
/*2 4 6 8 10 12 14 16 18 20*/
mapPartitions
map理论上运行4次

mapPartitions运行两次

作用:类似于map,但是独立在RDD每一个分片(分区)上运行, func的函数类型必须是Iterator[T] => Iterator[U] (可以理解为一批数据)
可以加快传输速率,但是有可能造成内存溢出(OOM)
和map需求相同:
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Spark01_MapPartitions {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setAppName("mapPartitions").setMaster("local")
val sc: SparkContext = new SparkContext(conf)
val value: RDD[Int] = sc.makeRDD(1 to 10)
value.mapPartitions(
// 将数据遍历
datas=>{
datas.map(_*2)
}
).foreach(println)
}
}
/*
2
4
6
8
10
12
14
16
18
20
*/
mapPartitionsWithIndex
带有分区号
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Spark01_RDD_mapPartitionsIndex {
def main(args: Array[String]): Unit = {
// 有分区号设置
val conf: SparkConf = new SparkConf().setAppName("mapPartitions").setMaster("local")
val sc: SparkContext = new SparkContext(conf)
val value: RDD[Int] = sc.makeRDD(1 to 10)
val value1: RDD[(Int, String)] = value.mapPartitionsWithIndex {
case (num, datas) => {
datas.map((_, "分区号" + num))
}
}
value1.foreach(println)
}
}
/*
(1,分区号0)
(2,分区号0)
(3,分区号0)
(4,分区号0)
(5,分区号0)
(6,分区号0)
(7,分区号0)
(8,分区号0)
(9,分区号0)
(10,分区号0)
*/
修改一下分区数
val value: RDD[Int] = sc.makeRDD(1 to 10,5)
/*
(1,分区号0)
(2,分区号0)
(3,分区号1)
(4,分区号1)
(5,分区号2)
(6,分区号2)
(7,分区号3)
(8,分区号3)
(9,分区号4)
(10,分区号4)
*/
flatMap算子
可以对多个集合的元素进行合并
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Spark01_RDD_flatMap {
def main(args: Array[String]): Unit = {
// 创建新的RDD
val rDD_Map: SparkConf = new SparkConf().setMaster("local").setAppName("RDD_flatMap")
val sc: SparkContext = new SparkContext(rDD_Map)
val value: RDD[List[Int]] = sc makeRDD (Array(List(1, 2), List(3, 4)))
val value1: RDD[Int] = value.flatMap(datas => datas)
value1.foreach(print)
}
}
/*
1234
*/
glom
将每一个分区形成新的数组,形成新的RDD类型RDD[Array[T]]
object Spark01_RDD_glom {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setAppName("mapPartitions").setMaster("local")
val sc: SparkContext = new SparkContext(conf)
val value: RDD[Int] = sc.makeRDD(1 to 15, 2)
val value1: RDD[Array[Int]] = value.glom()
value1.foreach(array=> {
// println(array.mkString(","))
//})
// 返回每个分区中最大值
println(array.max)
})
}
}
/*
1,2,3,4,5,6,7
8,9,10,11,12,13,14,15
*/
// 每个分区最大值
/*
7
15
*/
groupBy
按照模4进行分组
object Spark01_RDD_groupBy {
def main(args: Array[String]): Unit = {
// 有分区号设置
val conf: SparkConf = new SparkConf().setAppName("mapPartitions").setMaster("local")
val sc: SparkContext = new SparkContext(conf)
val value: RDD[Int] = sc.makeRDD(1 to 25)
// 分组
// 按照模4进行分组
val value1: RDD[(Int, Iterable[Int])] = value.groupBy(i => i % 4)
value1.foreach(println)
}
}
/*
(0,CompactBuffer(4, 8, 12, 16, 20, 24))
(1,CompactBuffer(1, 5, 9, 13, 17, 21, 25))
(3,CompactBuffer(3, 7, 11, 15, 19, 23))
(2,CompactBuffer(2, 6, 10, 14, 18, 22))
*/
结果以KV形式表先:K表示计算结果,V表示分组后集合
filter过滤
object Spark01_RDD_filter {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setAppName("mapPartitions").setMaster("local")
val sc: SparkContext = new SparkContext(conf)
val value: RDD[Int] = sc.makeRDD(1 to 50)
// 过滤能否整除7
val value1: RDD[Int] = value.filter(x => x % 7 == 0)
value1.foreach(println)
}
}
/*
7
14
21
28
35
42
49
*/
sample
取随机数
第一个参数表示取样是否放回,true为泊松,false为伯努利
第二个参数表示一个打分的概念:
false情况下,1数据全部保留,0数据都不保留
object Spark01_RDD_sample {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setAppName("mapPartitions").setMaster("local")
val sc: SparkContext = new SparkContext(conf)
val value: RDD[Int] = sc.makeRDD(1 to 10)
val value1: RDD[Int] = value.sample(false, 0.1, 7)
value1.foreach(println)
}
}
/*
2
8
*/
distinct


因为去重后可能会有分区为空,可以在算子distinct中添加参数n,来设置去重后分区数
缩减分区数
object Spark01_RDD_coalesce {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setAppName("mapPartitions").setMaster("local")
val sc: SparkContext = new SparkContext(conf)
val value: RDD[Int] = sc.makeRDD(1 to 16,5)
// 刚开始为5个分区,将其缩减(将最后几个分区合为一个)
val value1: RDD[Int] = value.coalesce(2)
println(value1.partitions.size)
/*
2
*/
}
}
repartition
和coalesce类似,只不过默认情况下coalesce可能出现数据倾斜,所以repartition=shuffer的coalesce(底层一样)
package Spark
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Spark01_RDD_reparation {
def main(args: Array[String]): Unit = {
// 创建新的RDD
val rDD_Map: SparkConf = new SparkConf().setMaster("local").setAppName("RDD_Map")
val sc: SparkContext = new SparkContext(rDD_Map)
val value: RDD[Int] = sc.makeRDD(1 to 50)
// reparation和coalesce是类似的,只不过reparation经过了suffer的过程,
// coalesce也可以经过suffer,底层是一样的
//val value1: RDD[Int] = value.repartition(5)
val value1: RDD[Int] = value.coalesce(5, true)
val value2: RDD[Array[Int]] = value1.glom()
value2.foreach(array=>{
println(array.mkString(" "))
/* repartition
2 7 12 17 22 27 32 37 42 47
3 8 13 18 23 28 33 38 43 48
4 9 14 19 24 29 34 39 44 49
coalesce结果一样
2 7 12 17 22 27 32 37 42 47
3 8 13 18 23 28 33 38 43 48
4 9 14 19 24 29 34 39 44 49
*/
})
}
}
srotBy
降序可以添加参数false,还可以指定分区数
package Spark
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Spark01_RDD_sortBy {
def main(args: Array[String]): Unit = {
// 创建新的RDD
val rDD_Map: SparkConf = new SparkConf().setMaster("local").setAppName("RDD_Map")
val sc: SparkContext = new SparkContext(rDD_Map)
val value: RDD[Int] = sc.makeRDD(Array(1, 7, 5, 5, 4, 3, 7, 6, 8, 2, 4))
//val value1: RDD[Int] = value.sortBy(x => x) //按自身排序
//value1.foreach(x=>print(x+" "))// 1 2 3 4 4 5 5 6 7 7 8
// 按照%3的结果排序
//val value1: RDD[Int] = value.sortBy(x => x % 3)
//value1.foreach(x => print(x + " "))// 3 6 1 7 4 7 4 5 5 8 2
// 指定分区数,并且倒叙
val value1: RDD[Int] = value.sortBy(x => x, false, 4)
// 查看分区数
value1.glom().foreach(array=>{
println(array.mkString(" "))
/*
8
7 7 6
5 5 4 4
3 2 1
*/
})
}
}
两个value交互的算子
union 交集,并集,差集
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Spark01_RDD_unionSubtractCartesian {
def main(args: Array[String]): Unit = {
// 创建新的RDD
val rDD_Map: SparkConf = new SparkConf().setMaster("local").setAppName("RDD_Map")
val sc: SparkContext = new SparkContext(rDD_Map)
val value: RDD[Int] = sc.makeRDD(1 to 10)
val value1: RDD[Int] = sc.makeRDD(5 to 15)
// 交集 1 2 3 4 5 6 7 8 9 10 5 6 7 8 9 10 11 12 13 14 15
value.union(value1).foreach(x => print(x + " "))
// 并集 (1,5) (1,6) (1,7) (1,8) (1,9) (1,10) (1,11) (1,12) (1,13) (1,14) (1,15)
// (2,5) (2,6) (2,7) (2,8) (2,9) (2,10) (2,11) (2,12) (2,13) (2,14) (2,15) (3,5) (3,6) (3,7) (3,8) (3,9) (3,10) (3,11) (3,12) (3,13) (3,14) (3,15) (4,5) (4,6) (4,7) (4,8) (4,9) (4,10) (4,11) (4,12) (4,13) (4,14) (4,15) (5,5) (5,6) (5,7) (5,8) (5,9) (5,10) (5,11) (5,12) (5,13) (5,14) (5,15) (6,5) (6,6) (6,7) (6,8) (6,9) (6,10) (6,11) (6,12) (6,13) (6,14) (6,15) (7,5) (7,6) (7,7) (7,8) (7,9) (7,10) (7,11) (7,12) (7,13) (7,14) (7,15) (8,5) (8,6) (8,7) (8,8) (8,9) (8,10) (8,11) (8,12) (8,13) (8,14) (8,15) (9,5) (9,6) (9,7)
// (9,8) (9,9) (9,10) (9,11) (9,12) (9,13) (9,14) (9,15)
// (10,5) (10,6) (10,7) (10,8) (10,9) (10,10) (10,11) (10,12) (10,13) (10,14) (10,15)
value.cartesian(value1).foreach(x => print(x + " "))
// 差集1 2 3 4
value.subtract(value1).foreach(x => print(x + " "))
}
}
zip
Spark中的zip和scala中zip相比更加的严格
必须要求分区数和数字数相同,且两个value都要相同
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Spark01_RDD_zip {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setAppName("new RDD").setMaster("local")
val sc: SparkContext = new SparkContext(conf)
val value: RDD[Int] = sc.makeRDD(Array(1, 2, 3), 3)
//2 Can't zip RDDs with unequal numbers of partitions: List(2, 3)
// (4, 5, 6,7)Can only zip RDDs with same number of elements in each partition
val value1: RDD[Int] = sc.makeRDD(Array(4, 5, 6), 3)
value.zip(value1).foreach(x => print(x + " ")) // (1,4) (2,5) (3,6)
}
}
K-V算子
partitionBy
设置元组到哪个分区
import org.apache.spark.rdd.RDD
import org.apache.spark.{Partitioner, SparkConf, SparkContext}
object Spark01_RDD_partitionBy {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setAppName("mapPartitions").setMaster("local")
val sc: SparkContext = new SparkContext(conf)
val value: RDD[(String, Int)] = sc.makeRDD(List(("a", 1), ("b", 2), ("c", 3)))
// partitionBy针对的是元组类型
val value1: RDD[(String, Int)] = value.partitionBy(new MyPartitioner(5)) // 要传入一个分区器,我们自定义一个
value1.saveAsTextFile("output")
}
class MyPartitioner(int: Int) extends Partitioner{
override def numPartitions: Int = {
// 方法
int
}
override def getPartition(key: Any): Int = {
// 可以根据hash数来计算到哪个分区,我们这里简单点,到%2的分区
key.hashCode()%2
}
}
}
最终结果:
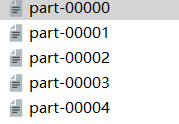
共有五个分区,只有第一个和第二个分区有元素
groupByKey
案例:用groupByKey来做词频统计
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Spark01_RDD_groupByKey {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setAppName("mapPartitions").setMaster("local")
val sc: SparkContext = new SparkContext(conf)
val value: RDD[String] = sc.makeRDD(List("three", "three", "three", "two", "two", "one"))
// 词频统计 groupByKey
val value1: RDD[(String, Int)] = value.map(x => (x, 1))
val value2: RDD[(String, Iterable[Int])] = value1.groupByKey()
val value3: RDD[(String, Int)] = value2.map(x => (x._1, x._2.sum))
value3.foreach(print)
/*
(two,2)(one,1)(three,3)
*/
}
}
reduceByKey和groupByKey的区别:
reduceByKey有一个预聚合操作,而groupByKey并没有,因此,reduceByKey的性能高一些(shuffle次数少)


aggregateByKey
参数:(zeroValue:U,[partitioner: Partitioner]) (seqOp: (U, V) => U,combOp: (U, U) => U)
在KV对的RDD中,按照key将value进行分组合并,合并时将每个value和初始值作为seq的参数,进行计算,返回一个新的KV对,然后再将结果按照key进行合并,最后将每个组的value传递给combine函数进行计算
即,将分区中的不同数据按照某个函数进行操作之后再对每个分区的数据进行另一项操作
例如:
取出每个分区内相同key的对应值的最大值,然后相加
先查看一下分区:
package Spark
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Spark01_RDD_aggregateByKey {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setAppName("mapPartitions").setMaster("local")
val sc: SparkContext = new SparkContext(conf)
val value: RDD[(String, Int)] = sc.makeRDD(List(("a", 1), ("c", 2), ("c", 9), ("a", 5), ("a", 7), ("b", 4), ("b", 9), ("c", 4), ("c", 6)), 2)
value.glom().foreach(x=>{
print("-------------")
x.foreach(x=>print(x + " "))
})
}
}
/* 可以看到被分为两个区
-------------(a,1) (c,2) (c,9) (a,5) -------------(a,7) (b,4) (b,9) (c,4) (c,6)
*/
package Spark
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Spark01_RDD_aggregateByKey {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setAppName("mapPartitions").setMaster("local")
val sc: SparkContext = new SparkContext(conf)
val value: RDD[(String, Int)] = sc.makeRDD(List(("a", 1), ("c", 2), ("c", 9), ("a", 5), ("a", 7), ("b", 4), ("b", 9), ("c", 4), ("c", 6)), 2)
// value.glom().foreach(x=>{
// print("-------------")
// x.foreach(x=>print(x + " "))
// }
val value1: RDD[(String, Int)] = value.aggregateByKey(0)(math.max(_, _), _ + _)
value1.foreach(x=>print(x+" "))// (b,9) (a,12) (c,15)
}
}

foldByKey
简单的说,就是分区内和分区外执行同一个操作:
package Spark
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Spark01_RDD_foldByKey {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setAppName("mapPartitions").setMaster("local")
val sc: SparkContext = new SparkContext(conf)
val value: RDD[(String, Int)] = sc.makeRDD(List(("a", 1), ("c", 2), ("c", 9), ("a", 5), ("a", 7), ("b", 4), ("b", 9), ("c", 4), ("c", 6)), 2)
val value1: RDD[(String, Int)] = value.foldByKey(0)(_ + _)
value1.foreach(x => print(x + " "))// 计算两个分区的和,词频统计:(b,13) (a,13) (c,21)
}
}
combineByKey
(createCombiner: V => C, mergeValue: (C, V) => C, mergeCombiners: (C, C) => C)
对相同的K,把V形成一个新的集合
(1)createCombiner: combineByKey() 会遍历分区中的所有元素,因此每个元素的键要么还没有遇到过,要么就和之前的某个元素的键相同。如果这是一个新的元素,combineByKey()会使用一个叫作createCombiner()的函数来创建那个键对应的累加器的初始值
(2)mergeValue: 如果这是一个在处理当前分区之前已经遇到的键,它会使用mergeValue()方法将该键的累加器对应的当前值与这个新的值进行合并
(3)mergeCombiners: 由于每个分区都是独立处理的, 因此对于同一个键可以有多个累加器。如果有两个或者更多的分区都有对应同一个键的累加器, 就需要使用用户提供的 mergeCombiners() 方法将各个分区的结果进行合并。
需求:根据key计算每种key的均值。(先计算每个key出现的次数以及可以对应值的总和,再相除得到结果)
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Spark01_RDD_combineByKey {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setAppName("mapPartitions").setMaster("local")
val sc: SparkContext = new SparkContext(conf)
val value: RDD[(String, Int)] = sc.makeRDD(List(("a", 1), ("c", 2), ("c", 9), ("a", 5), ("a", 7), ("b", 4), ("b", 9), ("c", 4), ("c", 6)), 2)
// 计算平均值
val value1: RDD[(String, (Int, Int))] = value.combineByKey(
(_, 1), // ("a", 1) -> (("a",1),1)
(acc: (Int, Int), v) => (acc._1 + v, acc._2 + 1), // 碰到("a", 5) =》(("a",5),2)
(acc1: (Int, Int), acc2: (Int, Int)) => (acc1._1 + acc2._1, acc1._2 + acc2._2) // 两个分区对应值相加
)
val value2: RDD[(String, Int)] = value1.map(x => {
(x._1, x._2._1 / x._2._2)
})
value2.foreach(x => print(x + " "))// (b,6) (a,4) (c,5)
}
}

sortByKey
根据key排序
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Spark01_RDD_sortByKey {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setAppName("mapPartitions").setMaster("local")
val sc: SparkContext = new SparkContext(conf)
val value: RDD[(String, Int)] = sc.makeRDD(List(("a", 1), ("c", 2), ("c", 9), ("a", 5), ("a", 7), ("b", 4), ("b", 9), ("c", 4), ("c", 6)), 2)
// 根据key排序
value.sortByKey(false).foreach(print)//(c,2)(c,9)(c,4)(c,6)(b,4)(b,9)(a,1)(a,5)(a,7)
value.sortByKey(true).foreach(print)// (a,1)(a,5)(a,7)(b,4)(b,9)(c,2)(c,9)(c,4)(c,6)
}
}
mapValues
只对V进行操作
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Spark01_RDD_mapValues {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setAppName("mapPartitions").setMaster("local")
val sc: SparkContext = new SparkContext(conf)
val value: RDD[(String, Int)] = sc.makeRDD(List(("a", 1), ("c", 2), ("c", 9), ("a", 5), ("a", 7), ("b", 4), ("b", 9), ("c", 4), ("c", 6)), 2)
// 对所有的V编程字符串再加"%%"
val value1: RDD[(String, String)] = value.mapValues(x => {
val str = String.valueOf(x)
str + "%%"
})
value1.foreach(println)
/*
(a,1%%)
(c,2%%)
(c,9%%)
(a,5%%)
(a,7%%)
(b,4%%)
(b,9%%)
(c,4%%)
(c,6%%)
*/
}
}
join
将(K,V)和(K,W) =>(K,(V,W))元组
需求:创建两个RDD,并按照相同的K形成一个元组
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Spark01_RDD_join {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setAppName("mapPartitions").setMaster("local")
val sc: SparkContext = new SparkContext(conf)
val rdd = sc.parallelize(Array((1,"a"),(2,"b"),(3,"c")))
val rdd1 = sc.parallelize(Array((1,4),(2,5),(3,6)))
//rdd.join(rdd1).foreach(println)
/*
(1,(a,4))
(3,(c,6))
(2,(b,5))
*/
// 稍微修改一下
val rdd2 = sc.parallelize(Array((1, 4), (2, 5), (3, 6), (4, 7)))
// 无论哪个在前,只要没有相同的K,就不会在结果中出现
/*
rdd.join(rdd2).foreach(println)
(1,(a,4))
(3,(c,6))
(2,(b,5))
*/
/*
rdd2.join(rdd).foreach(println)
(1,(4,a))
(3,(6,c))
(2,(5,b))
*/
}
}
cogroup
作用:在类型为(K,V)和(K,W)的RDD上调用,返回一个(K,(Iterable<V>,Iterable<W>))类型的RDD
和join的区别是,不相同的K也会出现
import org.apache.spark.{SparkConf, SparkContext}
object Spark01_RDD_cogroup {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setAppName("mapPartitions").setMaster("local")
val sc: SparkContext = new SparkContext(conf)
val rdd = sc.parallelize(Array((1,"a"),(2,"b"),(3,"c")))
val rdd1 = sc.parallelize(Array((1,4),(2,5),(3,6)))
/*
rdd.cogroup(rdd1).foreach(println)
(1,(CompactBuffer(a),CompactBuffer(4)))
(3,(CompactBuffer(c),CompactBuffer(6)))
(2,(CompactBuffer(b),CompactBuffer(5)))
*/
val rdd2 = sc.parallelize(Array((1, 4), (2, 5), (3, 6), (4, 9)))
rdd.cogroup(rdd2).foreach(println)
/*
(4,(CompactBuffer(),CompactBuffer(9)))
(1,(CompactBuffer(a),CompactBuffer(4)))
(3,(CompactBuffer(c),CompactBuffer(6)))
(2,(CompactBuffer(b),CompactBuffer(5)))
*/
}
}
实操
一个简单的需求:统计出每一个省份广告被点击次数的TOP3
数据形式:
时间戳,省份,城市,用户,广告,中间字段使用空格分割。
1516609143867 6 7 64 16
1516609143869 9 4 75 18
1516609143869 1 7 87 12
1516609143869 2 8 92 9
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object RDD_Test {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setAppName("RDD_Test").setMaster("local")
val sc: SparkContext = new SparkContext(conf)
val value = sc.textFile("F:\\spark_RDDtest")
// 先将数据按照空格切分,并且生成数组
val value1: RDD[((String, String), Int)] = value.map(x => {
val fields: Array[String] = x.split(" ")
// 要数组中1,4,并且要转换形式
((fields(1), fields(4)), 1) //后面这个1是为了计数使用,前面分别为数据省份和广告
})
val value2: RDD[((String, String), Int)] = value1.reduceByKey(_ + _) // 将后面的计数聚合((1,4),17)
// 省份作为K,聚合数记为V
val value3: RDD[(String, (String, Int))] = value2.map(x => {
(x._1._1, (x._1.x._2, x._2))
}) // (省份,(广告名,广告数))
// 对同一省份所有广告进行聚合
val value4: RDD[(String, Iterable[(String, Int)])] = value3.groupByKey()
// 取前三条
val value5: RDD[(String, List[(String, Int)])] = value4.mapValues(x => {
x.toList.sortWith((x, y) => {
x._2 > y._2 //排序
}).take(3) // 前三
})
value5.foreach(x=>{
println("省份:"+x._1)
println("前三分别是:")
for (elem <- x._2) {
println(elem._1)
}
println("其点击数是:")
for (elem <- x._2) {
println(elem._2)
}
println("-----------------------------")
})
}
}
输出(一部分):
省份:4
前三分别是:
12
2
16
其点击数是:
25
22
22
行动算子
reduce(func)案例
作用:通过func函数聚集RDD中所有元素,先聚合分区内,在聚合分区间
scala> val rdd1 = sc.makeRDD(1 to 10,2)
rdd1: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[0] at makeRDD at <console>:24
scala> rdd1.reduce(_+_)
res0: Int = 55
scala> val rdd1 = sc.makeRDD(Array(("a",1),("b",2),("c",3)))
rdd1: org.apache.spark.rdd.RDD[(String, Int)] = ParallelCollectionRDD[1] at makeRDD at <console>:24
scala> rdd1.reduce((x,y)=>(x._1+y._1,x._2*2+y._2))
res1: (String, Int) = (abc,11)
collect()
在驱动程序中,以数组的形式返回数据集内所有的元素
scala> val rdd = sc.makeRDD(1 to 10,5)
rdd: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[3] at makeRDD at <console>:24
scala> rdd.collect()
res3: Array[Int] = Array(1, 2, 3, 4, 5, 6, 7, 8, 9, 10)
count()
返回RDD中元素个数
scala> val rdd = sc.makeRDD(1 to 10,5)
rdd: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[3] at makeRDD at <console>:24
scala> rdd.collect()
res3: Array[Int] = Array(1, 2, 3, 4, 5, 6, 7, 8, 9, 10)
scala> rdd.count()
res4: Long = 10
first
返回RDD中第一个元素
scala> rdd.collect()
res3: Array[Int] = Array(1, 2, 3, 4, 5, 6, 7, 8, 9, 10)
scala> rdd.count()
res4: Long = 10
scala> rdd.first()
res5: Int = 1
take(n)
返回一个由RDD的前n个元素组成的数组
scala> rdd.take(5)
res6: Array[Int] = Array(1, 2, 3, 4, 5)
takeOrdered(n)
scala> val rdd = sc.makeRDD(Array(1,5,3,4,46,1,4,655,0,3,4,2))
rdd: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[4] at makeRDD at <console>:24
scala> rdd.takeOrdered(5)
res7: Array[Int] = Array(0, 1, 1, 2, 3)
aggregate
(zeroValue: U)(seqOp: (U, T) ⇒ U, combOp: (U, U) ⇒ U)
作用和aggregateByKey类似,先分区内seqOp,分区间combOp
scala> val rdd = sc.makeRDD(Array(1,5,3,4,46,1,4,655,0,3,4,2),3)
rdd: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[6] at makeRDD at <console>:24
scala> rdd.aggregate(0)(_+_,_+_)
res11: Int = 728
和aggregate还是有区别的
scala> val rdd = sc.makeRDD(1 to 10,5)
rdd: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[8] at makeRDD at <console>:24
scala> rdd.aggregate(10)(_+_,_+_)
res12: Int = 115
也就是说,不仅是分区内,两个分区之间元素做计算时也会调用初始值
fold(num)(func)
折叠操作,aggregate的简化操作,seqop和combop一样。
scala> val rdd = sc.makeRDD(1 to 10,5)
rdd: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[8] at makeRDD at <console>:24
scala> rdd.aggregate(10)(_+_,_+_)
res12: Int = 115
scala> rdd.fold(0)(_+_)
res13: Int = 55
scala> rdd.fold(10)(_+_)
res14: Int = 115
saveAxTextFile(path)
将数据集的元素以textfile的形式保存到文件系统,Spark会调用toString的方式为它转换为文本
saveAsSequenceFile(path)
将数据集中的元素以Hadoop sequencefile的格式保存到指定目录下,可以使用HDFS或者其他的Hadoop文件系统
saveAsObjectFile(path)
用于将RDD中的元素序列化成对象,存储到文件中
countByKey()
针对KV类型,返回一个K Int类型的map
scala> val rdd = sc.parallelize(List((1,3),(1,2),(1,4),(2,3),(3,6),(3,8)),3)
rdd: org.apache.spark.rdd.RDD[(Int, Int)] = ParallelCollectionRDD[9] at parallelize at <console>:24
scala> rdd.countByKey()
res15: scala.collection.Map[Int,Long] = Map(3 -> 2, 1 -> 3, 2 -> 1)
foreach(func)
在数据集的每一个元素上,运行func
scala> val rdd = sc.makeRDD(1 to 5,2)
rdd: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[12] at makeRDD at <console>:24
scala> rdd.foreach(x=>{print(x * 2 + " ")})
2 4 6 8 10
collect后foreach和直接foreach有点区别:

Driver和Executor的区别

每一个计算功能都是在Executor中完成的(具体由Driver分配)
简单来看一个程序

除了圈中部分,剩下的都是在Driver中完成的,但是这样就会出现一个问题,即,对代码进行修改

同样也是只有圈中的元素会进入Executor中,不过,i值也会进入,并且是通过序列化进入。
所以,如果是一个自定义对象进行计算时,要设置为可以序列化与反序列化的接口
RDD中传递函数
在实际开发中我们自己定义一些对于RDD的操作时,需要注意初始化操作实在Driver端进行的,而实际的运行程序实在Executor端进行的,这就涉及到跨进程通信,需要进行序列化
传递一个方法
以下代码会报错:Task not serializable
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Test_Serializable {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setAppName("RDD_Test").setMaster("local")
val sc: SparkContext = new SparkContext(conf)
val value: RDD[String] = sc.makeRDD(Array("hadoop", "java", "hbase", "Hive", "Spark", "kylin"))
val search: Search = new Search("h") //用来判断是否含有h
val value1: RDD[String] = search.getMatch1(value) // 过滤出包含h的字符
value1.foreach(println(_))
}
}
class Search(query: String) { // Task not serializable
//过滤出包含字符串的数据
def isMatch(s: String): Boolean = {
s.contains(query)
}
//过滤出包含字符串的RDD
def getMatch1(rdd: RDD[String]): RDD[String] = {
rdd.filter(isMatch)
}
//过滤出包含字符串的RDD
def getMatche2(rdd: RDD[String]): RDD[String] = {
rdd.filter(x => x.contains(query))
}
}
在这个方法中调用isMatch()时定义在Search这个类中的,实际上调用的是this.isMatch(),this表示Search这个对象,程序在运行过程中需要将Search这个对象序列化后传递到Executor端
def getMatch1(rdd: RDD[String]): RDD[String] = {
rdd.filter(isMatch)
}
解决方案:
class Search(query: String) extends Serializable {
结果:
hadoop
hbase
传递一个属性
(将上面的extends取消)
package Spark.test
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Test_Serializable {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setAppName("RDD_Test").setMaster("local")
val sc: SparkContext = new SparkContext(conf)
val value: RDD[String] = sc.makeRDD(Array("hadoop", "java", "hbase", "Hive", "Spark", "kylin"))
val search: Search = new Search("h") //用来判断是否含有h
val value1: RDD[String] = search.getMatch2(value) // 过滤出包含h的字符
value1.foreach(println(_))
}
}
//class Search(query: String) extends Serializable {
class Search(query: String) { // Task not serializable
//过滤出包含字符串的数据
def isMatch(s: String): Boolean = {
s.contains(query)
}
//过滤出包含字符串的RDD
def getMatch1(rdd: RDD[String]): RDD[String] = {
rdd.filter(isMatch)
}
//过滤出包含字符串的RDD
def getMatch2(rdd: RDD[String]): RDD[String] = {
rdd.filter(x => x.contains(query))
}
}
还是会报错
//过滤出包含字符串的RDD
def getMatche2(rdd: RDD[String]): RDD[String] = {
rdd.filter(x => x.contains(query))
}
这个方法所调用的query是定义在Serch中的,实际上调用的是this.query,this表示Search这个对象,程序在运行过程中需要将Search对象序列化以传递到Executor端
解决方法:(网络传输传输的是字符串,所以)
1.可以和上面一样,继承Serializable类
2.将变量query赋值给局部变量
//过滤出包含字符串的RDD
def getMatch2(rdd: RDD[String]): RDD[String] = {
val q:String = query;
rdd.filter(x => x.contains(q))
}
/*
hadoop
hbase
*/
RDD依赖关系
Lineage(血统)
RDD只支持粗粒度转换,在大量记录上执行的单个操作。 将创建RDD的一系列Lineage(血统)记录下来,以便恢复丢失部分的分区。RDD的Lineage会记录RDD的元数据信息和转换行为,当RDD的部分分区数据丢失时,它可以根据这些信息来恢复运算和恢复对是的数据分区
查看
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object RDD_Lineage {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setAppName("RDD_Test").setMaster("local")
val sc: SparkContext = new SparkContext(conf)
val value: RDD[Int] = sc.makeRDD(1 to 10)
val value1: RDD[(Int, Int)] = value.map((_, 1))
val string: String = value1.reduceByKey(_ + _).toDebugString
println(string)
}
}
结果:
value1reduceBykey的Lineage
(1) ShuffledRDD[2] at reduceByKey at RDD_Lineage.scala:12 []
±(1) MapPartitionsRDD[1] at map at RDD_Lineage.scala:11 []
| ParallelCollectionRDD[0] at makeRDD at RDD_Lineage.scala:10 []
value1的Lineage
(1) MapPartitionsRDD[1] at map at RDD_Lineage.scala:11 []
| ParallelCollectionRDD[0] at makeRDD at RDD_Lineage.scala:10 []
value1的依赖类型、value1.reduceByKey的依赖类型
import org.apache.spark.rdd.RDD
import org.apache.spark.{Dependency, SparkConf, SparkContext}
object RDD_Lineage {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setAppName("RDD_Test").setMaster("local")
val sc: SparkContext = new SparkContext(conf)
val value: RDD[Int] = sc.makeRDD(1 to 10)
val value1: RDD[(Int, Int)] = value.map((_, 1))
//val string: String = value1.reduceByKey(_ + _).toDebugString
//val dependencies: Seq[Dependency[_]] = value1.dependencies// List(org.apache.spark.OneToOneDependency@538cd0f2)
val dependencies: Seq[Dependency[_]] = value1.reduceByKey(_ + _).dependencies// List(org.apache.spark.ShuffleDependency@5eb97ced)
println(dependencies)
}
}
依赖可以分为两种,宽依赖和窄依赖:
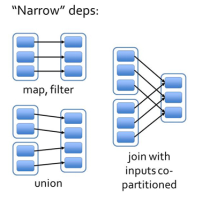
窄依赖
每一个父RDD的partition最多倍自已来的一个Partition使用:
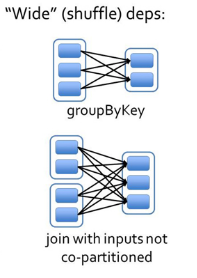
宽依赖
多个子RDD的partition会依赖同一个父RDD的partition,引起shuffer
DAG
有向无环图,原始的RDD通过一系列转换形成了DAG,根据RDD之间的依赖关系的不同将DAG划分成不同的Stage,
对于窄依赖,partition的转换处理在Stage中完成。
对于宽依赖,由于shuffer的存在,只能在父RDD处理完成后,才能开始接下来的计算
因此,宽依赖是划分Stage的依据

任务划分(重点)
RDD中任务划分分为:Application、Job、Stage、Task
1.Application:初始化一个SparkContext(sc)即生成一个Application
2.Job:一个Action算子会生成一个Job
3.Stage:根据RDD之间的依赖关系不同将Job划分成不同的Stage,遇到一个宽依赖则划分一个Stage(初始是一个大的Stage)
4.Task:Stage划分的结果发送到不同的Executor执行即为一个Task

计算Stage数:从后往前看,1+shuffer数量
Task数:分Stage看分区数:Stage1->3,Stage2->5,共8个,但是前五个任务并行,后三个任务并行,不能同时进行
遇到一个Stage(Shuffler/宽依赖)必须等前一个Stage执行完才能继续执行。
RDD缓存
RDD通过persist方法或cache方法可以将前面的计算结果缓存,默认情况下,persist会把数据以序列化的形式缓存在JVM堆中。并不是这两个方法被调用后立即缓存,而是触发后面的action时RDD就被缓存在计算节点的内存中,并供后面重用。

cache最终也是调用了persist方法,默认的存储都是仅在内存存储一份,还有很多种存储级别

_2表示持久化数据两份

缓存有可能会丢失,或者存储于内存中的数据由于内存不足而被删除,RDD的缓存容错机制保证了即使缓存丢失计算也能正确执行即丢失的数据经过RDD的一系列转换会被重算。由于RDD的各个分区时独立的,只需要计算数据丢失的部分即可
举例:
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Spark01_RDD_persist {
def main(args: Array[String]): Unit = {
// 检验persist/cache的效果
val conf: SparkConf = new SparkConf().setAppName("persist").setMaster("local")
val sc: SparkContext = new SparkContext(conf)
val nameRDD: RDD[String] = sc.makeRDD(Array("name"))
val mapRDD: RDD[String] = nameRDD.map(_ + System.currentTimeMillis())//加上时间戳
mapRDD.cache()//加入缓存机制
mapRDD.foreach(println)
mapRDD.foreach(println)
mapRDD.foreach(println)
/* 可以看出结果不一样,如果我们在中间加入缓存呢
name1620002793255
name1620002793315
name1620002793335
*/
/* 加入了缓存机制后,都一样了
name1620002896065
name1620002896065
name1620002896065
*/
}
}
但是如果我们打印血统:发现就算经过缓存,也会存储正常的血统
RDD CheckPoint
Spark中除了对数据做持久化操作,还增加了检查点机制。这种机制是为了辅助血统的容错血统过长会造成容错成本过高,不如在中间阶段做检查点容错,如果之后有节点出现问题而丢失分区,从做检查点的RDD开始重做Lineage,用来减少开销,通过将数据写入到文件来实现检查点功能。
为当前RDD设置检查点,该函数会创建一个二进制的文件,并且存储到SparkContext.setCheckpointDir()设置的文件目录中。在checkpiont的过程中,该RDD的所有依赖与父RDD的信息都会被删除。注意,只有Action操作才能出发checkpoint操作
举例:正常情况下
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Spark01_RDD_checkPoint {
def main(args: Array[String]): Unit = {
// 检验persist/cache的效果
val conf: SparkConf = new SparkConf().setAppName("persist").setMaster("local")
val sc: SparkContext = new SparkContext(conf)
//sc.setCheckpointDir("out") //正常开发应该是HDFS文件
// 随便做点什么
val value: RDD[Int] = sc.makeRDD(Array(1, 2, 4, 5, 68, 7, 2, 3, 76, 46, 32))
val value1: RDD[(Int, Int)] = value.map((_, 1))
val value2: RDD[(Int, Int)] = value1.reduceByKey(_ + _)
value2.foreach(println)
println("*******************")
// 打印血统
println(value2.toDebugString)
}
}
/*
(4,1)
(76,1)
(46,1)
(32,1)
(1,1)
(3,1)
(7,1)
(68,1)
(5,1)
(2,2)
*******************
(1) ShuffledRDD[2] at reduceByKey at Spark01_RDD_checkPoint.scala:15 []
+-(1) MapPartitionsRDD[1] at map at Spark01_RDD_checkPoint.scala:14 []
| ParallelCollectionRDD[0] at makeRDD at Spark01_RDD_checkPoint.scala:13 []
*/
当我们取消注释,并且在value2加入checkPoint后
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Spark01_RDD_checkPoint {
def main(args: Array[String]): Unit = {
// 检验persist/cache的效果
val conf: SparkConf = new SparkConf().setAppName("persist").setMaster("local")
val sc: SparkContext = new SparkContext(conf)
sc.setCheckpointDir("output") //正常开发应该是HDFS文件
// 随便做点什么
val value: RDD[Int] = sc.makeRDD(Array(1, 2, 4, 5, 68, 7, 2, 3, 76, 46, 32))
val value1: RDD[(Int, Int)] = value.map((_, 1))
val value2: RDD[(Int, Int)] = value1.reduceByKey(_ + _)
//value2.checkpoint()
value2.foreach(println)
// 打印血统
println(value2.toDebugString)
/*
checkpoint的
(1) ShuffledRDD[2] at reduceByKey at Spark01_RDD_checkPoint.scala:15 []
| ReliableCheckpointRDD[3] at foreach at Spark01_RDD_checkPoint.scala:17 []
*/
}
}
SparkRDD分区
Spark支持Hash分区、Range分区、自定义分区,Hash分区为当前的默认分区,Spark中分区器直接决定了RDD中分区的个数、RDD中每条数据经过shuffle过程数据哪个分区、Reduce个数
只有KV的RDD采用普分区器,非KV类型的RDD分区器值位None
每个RDD的分区ID范围:0-numPartitions-1,决定这个值时属于那个分区的
获取RDD分区
可以通过使用RDD的partitioner属性来获取RDD的分区,它会返回一个scala.Option对象,通过get方法获取其中的值
Hash分区
Hash分区原理:对于给定的K,计算其HashCode,并且除以分区的个数取余,如果余数小于0,余数+分区个数(否则加0),最后返回的就是这个key所属分区ID
Ranger分区
Hash分区的弊端:数据倾斜
Ranger分区作用:将一定范围内的数据映射到某一个分区内,保证每个分区中数据量的均匀,并且分区与分区之间是有序的(一个分区的元素肯定比另一个分区的元素大或小)。但是分区内不能保证顺序
先将整个RDD中抽取出样本数据,将样本数据排序,计算出每个分区的最大key,形成一个array【key】类型的数组变量rangeBounds
判断ket在rangeBounds中所处范围,给出该key值在下一个RDD中的分区id下标。该分区器要求RDD中KEY类型必须是可以排序的
自定义分区器
要实现自定义的分区器,你需要继承 org.apache.spark.Partitioner 类并实现下面三个方法。
(1)numPartitions: Int:返回创建出来的分区数。
(2)getPartition(key: Any): Int:返回给定键的分区编号(0到numPartitions-1)。
(3)equals():Java 判断相等性的标准方法。这个方法的实现非常重要,Spark 需要用这个方法来检查你的分区器对象是否和其他分区器实例相同,这样 Spark 才可以判断两个 RDD 的分区方式是否相同。
数据读取与保存
文件格式:Text文件、Json文件、Csv文件、Sequence文件、Object文件
文件系统:本地文件系统、HDFS、HBASE、数据库
文件类数据的读取与保存
Text文件
textFile(path)// 读取
saveAsTextFile(path)//保存
Json文件
必须保证JSON文件中每一行是一个JSON记录
准备数据
.json会报错,但是Spark可以读取
{"name":"yyx","age":21}
{"name":"dlq","age":21}
{"name":"nm","age":2}
{"name":"luck","age":1}
// 导包
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
import scala.util.parsing.json.JSON
object Spark01_JSON {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local").setAppName("JSON")
val sc: SparkContext = new SparkContext(conf)
//读取文件
val value: RDD[String] = sc.textFile("user.json")
//解析数据
val value1: RDD[Option[Any]] = value.map(JSON.parseFull)
// 打印
value1.foreach(println)
}
}
结果:
Some(Map(name -> yyx, age -> 21.0))
Some(Map(name -> dlq, age -> 21.0))
Some(Map(name -> nm, age -> 2.0))
Some(Map(name -> luck, age -> 1.0))
Sequence文件
SequenceFile文件是Hadoop用来存储二进制形式的key-value对而设计的一种平面文件(Flat File)。Spark 有专门用来读取 SequenceFile 的接口。在 SparkContext 中,可以调用 sequenceFile[ keyClass, valueClass](path)。
Object文件
对象文件是将对象序列化后保存的文件,采用Java的序列化机制。可以通过objectFile[k,v](path) 函数接收一个路径,读取对象文件,返回对应的 RDD,也可以通过调用saveAsObjectFile() 实现对对象文件的输出。因为是序列化所以要指定类型。
Spark操作MySQL
简单点,不用Linux的Mysql了
导入依赖
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.27</version>
</dependency>
新建查询:
数据表:

import java.sql.{Driver, DriverManager}
import org.apache.spark.rdd.JdbcRDD
import org.apache.spark.{SparkConf, SparkContext}
object Spark01_JDBC {
def main(args: Array[String]): Unit = {
//1.创建spark配置信息
val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("JdbcRDD")
//2.创建SparkContext
val sc = new SparkContext(sparkConf)
//3.定义连接mysql的参数
val driver = "com.mysql.jdbc.Driver"
val url = "jdbc:mysql://localhost:3306/test"
val userName = "root"
val passWord = "123456"
val sql:String = "select * from studentTest where Sid>? and Sid <?"
// 4.JDBC rdd
/*
sc: SparkContext,
getConnection: () => Connection,
sql: String,
lowerBound: Long,
upperBound: Long,
numPartitions: Int,
mapRow: (ResultSet) => T = JdbcRDD.resultSetToObjectArray _) 对数据的操作
*/
val value: JdbcRDD[(Int, String, String, String)] = new JdbcRDD(
sc,
() => { // 获取连接的函数
Class.forName(driver)
DriverManager.getConnection(url, userName, passWord)
},
sql,
0,
9,
1,
r => (r.getInt(1), r.getString(2), r.getString(3), r.getString(4))
)
value.foreach(println)
sc.stop()
}
/*
(1,赵雷,1990-01-01 00:00:00.0,男)
(2,钱电,1990-12-21 00:00:00.0,男)
(3,孙风,1990-12-20 00:00:00.0,男)
(4,李云,1990-12-06 00:00:00.0,男)
(5,周梅,1991-12-01 00:00:00.0,女)
(6,吴兰,1992-01-01 00:00:00.0,女)
(7,郑竹,1989-01-01 00:00:00.0,女)
*/
}
查询总体来看比较简单,但是插入数据有难度了
import java.sql.{Connection, DriverManager, PreparedStatement}
import org.apache.spark.{SparkConf, SparkContext}
object Spark01_JDBC_insert {
def main(args: Array[String]): Unit = {
//1.创建spark配置信息
val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("JdbcRDD")
//2.创建SparkContext
val sc = new SparkContext(sparkConf)
//3.定义连接mysql的参数
val driver = "com.mysql.jdbc.Driver"
val url = "jdbc:mysql://localhost:3306/test"
val userName = "root"
val passWord = "123456"
// 4.JDBC rdd
val dates = sc.makeRDD(Array((1, "李四"), (2, "张三"), (3, "王五")))
dates.foreach {
// 向mysql中添加数据
// 1.获取连接
// 2.模式匹配
case (sid, name) => {
Class.forName(driver)
val connection: Connection = java.sql.DriverManager.getConnection(url, userName, passWord)
val sql: String = "insert into userTest (userid,username) values(?,?)"
val statement: PreparedStatement = connection.prepareStatement(sql)
statement.setInt(1, sid)
statement.setString(2, name)
statement.execute()
statement.close()
connection.close()
}
}
sc.stop()
}
}
可是只有三条数据还好,如果1万条数据insert,那么每条数据都创建一个connection嘛,那样会很慢
我们可以将connection挪到foreach外,但是这样会报错(因为foreach外是Driver,foreach内是Executer)而又不能在Connection后extends Serializable
我们可以这样修改(使用foreachPartition)
import java.sql.{Connection, DriverManager, PreparedStatement}
import org.apache.spark.{SparkConf, SparkContext}
object Spark01_JDBC_insert {
def main(args: Array[String]): Unit = {
//1.创建spark配置信息
val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("JdbcRDD")
//2.创建SparkContext
val sc = new SparkContext(sparkConf)
//3.定义连接mysql的参数
val driver = "com.mysql.jdbc.Driver"
val url = "jdbc:mysql://localhost:3306/test"
val userName = "root"
val passWord = "123456"
// 4.JDBC rdd
val dates = sc.makeRDD(Array((1, "李四"), (2, "张三"), (3, "王五")))
dates.foreachPartition ( data =>{
//这里就几个分区创建几个对象
Class.forName(driver)
val connection: Connection = java.sql.DriverManager.getConnection(url, userName, passWord)
data.foreach {
// 向mysql中添加数据
// 1.获取连接
// 2.模式匹配
case (sid, name) => {
val sql: String = "insert into userTest (userid,username) values(?,?)"
val statement: PreparedStatement = connection.prepareStatement(sql)
statement.setInt(1, sid)
statement.setString(2, name)
statement.execute()
statement.close()
}
}
connection.close()
})
sc.stop()
}
}
Spark操作HBase
导入依赖
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-server</artifactId>
<version>1.3.1</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>1.3.1</version>
</dependency>
数据:
ROW COLUMN+CELL
1001 column=info:age, timestamp=1616465185183, value=18
1001 column=info:friend, timestamp=1616469520398, value=yyx
1001 column=info:name, timestamp=1616465185183, value=ccc
1001 column=info:sex, timestamp=1616465185183, value=male
1002 column=info:boyfriend, timestamp=1616465185183, value=yyx
1002 column=info:name, timestamp=1616465185183, value=yyx
2 row(s) in 0.0510 seconds
代码:

import org.apache.hadoop.conf.Configuration
import org.apache.hadoop.hbase.{Cell, CellUtil, HBaseConfiguration}
import org.apache.hadoop.hbase.client.Result
import org.apache.hadoop.hbase.io.ImmutableBytesWritable
import org.apache.hadoop.hbase.mapreduce.TableInputFormat
import org.apache.hadoop.hbase.util.Bytes
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Spark_JDBC_HBase {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setAppName("Hbase").setMaster("local")
val sc: SparkContext = new SparkContext(conf)
// 创建一个HBase连接,要查询的数据表
val confs: Configuration = HBaseConfiguration.create()
confs.set("hbase.zookeeper.quorum", "hadoop01,hadoop02,hadoop03")
confs.set(TableInputFormat.INPUT_TABLE, "student")
val value: RDD[(ImmutableBytesWritable, Result)] = sc.newAPIHadoopRDD(
confs,
classOf[TableInputFormat],
classOf[ImmutableBytesWritable],
classOf[Result]
)
value.foreach {
case (rowkey, result) =>
val cells: Array[Cell] = result.rawCells()
for (elem <- cells) {
/*
age
18
friend
yyx
name
ccc
sex
male
boyfriend
yyx
name
yyx
*/
println(Bytes.toString(CellUtil.cloneQualifier(elem)))
println(Bytes.toString(CellUtil.cloneValue(elem)))
}
}
}
}
向HBase写入数据
import org.apache.hadoop.conf.Configuration
import org.apache.hadoop.hbase.{Cell, CellUtil, HBaseConfiguration}
import org.apache.hadoop.hbase.client.{Put, Result}
import org.apache.hadoop.hbase.io.ImmutableBytesWritable
import org.apache.hadoop.hbase.mapred.TableOutputFormat
import org.apache.hadoop.hbase.mapreduce.TableInputFormat
import org.apache.hadoop.hbase.util.Bytes
import org.apache.hadoop.mapred.JobConf
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Spark_JDBC_HBase {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setAppName("Hbase").setMaster("local")
val sc: SparkContext = new SparkContext(conf)
// 创建一个HBase连接,要查询的数据表
val confs: Configuration = HBaseConfiguration.create()
confs.set("hbase.zookeeper.quorum", "hadoop01,hadoop02,hadoop03")
// confs.set(TableInputFormat.INPUT_TABLE, "student")
// val value: RDD[(ImmutableBytesWritable, Result)] = sc.newAPIHadoopRDD(
// confs,
// classOf[TableInputFormat],
// classOf[ImmutableBytesWritable],
// classOf[Result]
// )
// value.foreach {
// case (rowkey, result) =>
// val cells: Array[Cell] = result.rawCells()
// for (elem <- cells) {
// /*
// age
// 18
// friend
// yyx
// name
// ccc
// sex
// male
// boyfriend
// yyx
// name
// yyx
// */
// println(Bytes.toString(CellUtil.cloneQualifier(elem)))
// println(Bytes.toString(CellUtil.cloneValue(elem)))
// }
// }
// 向HBase中插入数据
// 要插入的数据
val data: RDD[(String, String)] = sc.makeRDD(List(("1003", "zhangsan"), ("1004", "lisi"), ("1005", "wangwu")))
val putRDD: RDD[(ImmutableBytesWritable, Put)] = data.map {
case (rowkey, name) => {
val put: Put = new Put(Bytes.toBytes(rowkey))
// 列族、列名、数据
put.addColumn(Bytes.toBytes("info"), Bytes.toBytes("name"), Bytes.toBytes(name))
(new ImmutableBytesWritable(Bytes.toBytes(rowkey)), put)
}
}
val conf1: JobConf = new JobConf(confs)
conf1.setOutputFormat(classOf[TableOutputFormat])
conf1.set(TableOutputFormat.OUTPUT_TABLE,"student")
putRDD.saveAsHadoopDataset(conf1)
sc.stop()
}
}
hbase(main):012:0> scan "student"
ROW COLUMN+CELL
1001 column=info:age, timestamp=1616465185183, value=18
1001 column=info:friend, timestamp=1616469520398, value=yyx
1001 column=info:name, timestamp=1616465185183, value=ccc
1001 column=info:sex, timestamp=1616465185183, value=male
1002 column=info:boyfriend, timestamp=1616465185183, value=yyx
1002 column=info:name, timestamp=1616465185183, value=yyx
2 row(s) in 0.0510 seconds
hbase(main):013:0> scan "student"
ROW COLUMN+CELL
1001 column=info:age, timestamp=1616465185183, value=18
1001 column=info:friend, timestamp=1616469520398, value=yyx
1001 column=info:name, timestamp=1616465185183, value=ccc
1001 column=info:sex, timestamp=1616465185183, value=male
1002 column=info:boyfriend, timestamp=1616465185183, value=yyx
1002 column=info:name, timestamp=1616465185183, value=yyx
1003 column=info:name, timestamp=1620023936893, value=zhangsan
1004 column=info:name, timestamp=1620023936893, value=lisi
1005 column=info:name, timestamp=1620023936893, value=wangwu
5 row(s) in 0.0800 seconds
累加器


如果我们想实现所有分片处理时更新共享变量的功能,那么累加器可以实现我们想要的效果。
累加器的用法如下所示。
通过在驱动器中调用SparkContext.accumulator(initialValue)方法,创建出存有初始值的累加器。返回值为 org.apache.spark.Accumulator[T] 对象,其中 T 是初始值 initialValue 的类型。Spark闭包里的执行器代码可以使用累加器的 += 方法(在Java中是 add)增加累加器的值。 驱动器程序可以调用累加器的value属性(在Java中使用value()或setValue())来访问累加器的值。
注意:工作节点上的任务不能访问累加器的值。从这些任务的角度来看,累加器是一个只写变量。
对于要在行动操作中使用的累加器,Spark只会把每个任务对各累加器的修改应用一次。因此,如果想要一个无论在失败还是重复计算时都绝对可靠的累加器,我们必须把它放在 foreach() 这样的行动操作中。转化操作中累加器可能会发生不止一次更新
使用累加器:
import org.apache.spark.rdd.RDD
import org.apache.spark.{Accumulator, SparkConf, SparkContext}
object Spark01_accumulator {
def main(args: Array[String]): Unit = {
val sparkConf: SparkConf = new SparkConf().setMaster("local").setAppName("accumulator")
val sc = new SparkContext(sparkConf)
val value: RDD[Int] = sc.makeRDD(Array(1, 2, 3, 4), 2) //分为两个分区
val sum: Accumulator[Int] = sc.accumulator(0)
value.foreach(i=>sum+=i)
println(sum)// 10
}
}
广播变量
广播变量用来高效分发较大的对象。向所有工作节点发送一个较大的只读的对象,以供一个或多个Spark操作使用。比如,如果你的应用需要向所有节点发送一个较大的只读查询表,甚至是机器学习算法中一个很大的特证向量。都可以使用广播变量。在多个并行操作中使用同一个变量
val broadcastVar = sc.broadcast(Array(1, 2, 3))
过程:
1.通过对一个类型T对象调用SparkContext.boardcast创建出一个Broadcast[T]对象,任何可序列化的类型都可以这样实现
2.通过value属性访问该对象的值
3.变量只会被发到每个节点一次,应作为只读处理(修改这个值不会影响到其它节点)















 1284
1284











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









