







MySQL写入顺序与读取顺序


7中JOIN
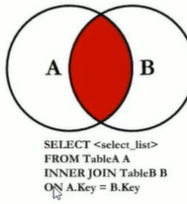
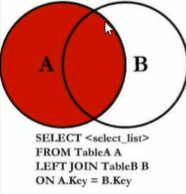
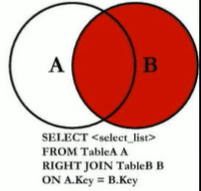
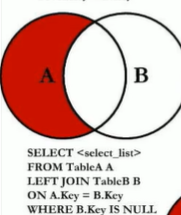
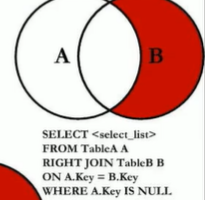

这里MySQL不支持Full Outer Join,我们可以使用union连接(全A+全B)

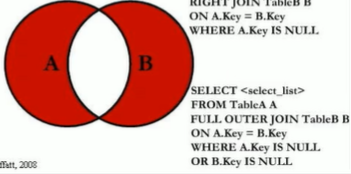
可以使用A独有+B独有
索引
什么是索引
一种帮助数据库高效访问数据的数据结构
排好序的快速查找的数据结构
索引优缺点
优点:加快查询速率
缺点:
- 维护索引会耗费数据库资源
- 索引占用磁盘空间
- 对表进行增删改的时候,因为需要维护索引,会降低性能所以索引不是越多越好
索引分类
1.主键索引
设立为主键后数据库会自动创建索引(Innodb为聚簇索引)
2.单列索引
一个索引只包含单个列,一个表可以有多个单列索引,也叫普通索引
3.唯一索引
索引的列的值必须唯一,但可以是空值,和主键索引的区别:主键索引索引列的值不能为null,而唯一索引可以存在null,但只能存在一个
4.复合索引
多个列组和在一起共同构建的索引
索引的操作
1.查看索引:show index from (表名)
show index from teacher
主键索引创建表时自动创建

普通索引创建
建表后创建 create index index_name on table_name(col)
CREATE index teachername on teacher(tname)
查看一下
show index from teacher

创建表时创建索引
CREATE table index_text (id VARCHAR(20) PRIMARY KEY, name VARCHAR(20), KEY(name))
show index from index_text

唯一索引的创建
建表时创建
CREATE table index_text1 (id VARCHAR(20) PRIMARY KEY, name VARCHAR(20), UNIQUE(name))
show index from index_text1

建表后创建
CREATE UNIQUE index uniqueKey on index_text(name)
show index from index_text

复合索引创建
建表时创建
create table index_text2(id VARCHAR(20) PRIMARY key,name VARCHAR(20),age INTEGER,key(name,age))
show index from index_text2

建表后创建
create index aindex on index_text2(id,name,age)
show index from index_text2

使用复合索引必须基于最左前缀原则:可以用id查,可以id+name,还可以id+name+age,其余情况都不能用
不但使用最左前缀原则,MySQL还会自动调整查询字段以便利用索引:综上,一个字段包含id的,两个字段包含id和name的,三个字段就是都包含的
索引的数据结构
主键索引排了序
innodb默认一页存储16kb
其上还有页目录(也是一个页,但是并不包含数据,只包含指针)
B树
1.所有的键值分布在整棵树中
2.搜索可能在非叶子节点结束(性能逼近二分查找)
3.每棵树最多有m个子树
4.根节点最少有两个子树
5.分支节点至少m/2棵子树(非根非叶子的节点)
6.所有叶子节点都在同一层,每一个节点最6,多有m - 1个key,并且升序排列
实例
比如查找28
- 根据根节点找到磁盘1,读入内存(IO)
- 比较关键字28在区间(16,34)的范围,找到指针P2
- 根据磁盘一的P2找到磁盘三,读入内存(IO)
- 比较28所在(27,29)找到磁盘3所在指针P2
- 根据磁盘三的P2指针找到磁盘8,读入内存(IO)
- 在磁盘8中找到关键字
缺点1:每个节点都有key,也有data,而每页的存储空间有限,如果data较大的话会导致每个节点存储key数量变小
缺点2:当存储数据量很大的时候会导致深度很大,也就是有多次IO,影响性能

4.B+树
B+树是在B树上做的优化:
- B+树的每个节点可以包含更多的节点:降低了书的高度,将数据范围变为多个区间,区间越多,数据检索越快
- 非叶子节点存储key,叶子节点存储key和数据
- 叶子节点的两两指针相互连接,顺序查询的性能更高
支持两种查找:基于主键的范围查找和分页查找或者从根开始随即查找

B+树最大的好处是只有叶子节点存储数据,非叶子节点不存储数据,降低了B+树的高度,减少了IO次数(Innodb最顶层根节点为常驻内存)
B树非叶子节点就要春初数据,这样每个非叶子节点存储的指针就要少一些,同样多的数据,B树深度更深,增加磁盘IO次数,影响效率。
区别:
- B+树非叶子节点只存储键值信息
- B+树的叶子节点之间存在一个链指针
- B+数据记录都放在叶子节点中
什么是聚簇索引,什么是非聚簇索引
聚簇索引:将数据存储与索引放到了一块,索引结构的叶子节点保存了行数据。聚簇索引不一定是主键索引,但是主键索引一定是聚簇索引,一张表中只有一个聚簇索引
非聚簇索引(辅助索引):将数据和索引分开存储,索引结构的叶子节点指向了数据对应位置

小问题:为什么非聚簇索引要用主键而不是行数据物理位置(偏移量)
因为如果使用地址的话当增删后地址有可能发生改变
Innodb中
- Innodb中使用主键索引,会将主键构成一棵B+树,并且行数据就存储在叶子节点上,若是使用where id = 14,就会按照B+树的算法直接找到对应行数据
- 对Name列进行条件搜索,需要两个步骤,1:在B+树中检索Name,到达其叶子节点获取对应主键,之后再根据主键索引B+树中再执行一次B+树检索操作,最终达到叶子节点获取整行数据。(使用其他建想这样操作要创建辅助索引(非聚簇索引))
- 聚簇索引默认主键,若表中没有定义主键,InnoDB会自动选择唯一且非空的索引代替,如果没有这样的索引,InnoDB会隐式定义一个主键作为聚簇索引,如果设置了主键所谓聚簇索引又想单独设置聚簇索引,只能先删除主键,之后添加想要的聚簇索引后再恢复主键
MyISAM(不支持事务)

MyISAM中使用非聚簇索引,非聚簇索引的两颗B+树没什么不同,节点的结构完全一致只是存储的内容不同,主键B+树存储了主键,辅助键索引B+树存储了辅助键。表数据存储在独立的位置。这两颗B+树的叶子节点都使用一个地址指向真正的表数据,对于表数据来说,两个键没有区别,和InnoDB的区别就是索引树是独立的,通过辅助键检索也不用访问主键的索引树
Innodb聚簇索引优势
- 由于行数据和聚簇索引的叶子节点存储在一起,同一页中有多条行数据,访问同一数据页不同行记录时,已经将页加载到了缓存器中,再次访问时会在内存中完成访问,不必IO=》找到了叶子节点就可以直接返回数据,(使用主键更快)
- 辅助索引的叶子节点,存储主键值而不是数据地址值,好处时当行数据进行增删等,索引树节点也需要分裂变化;当我们要炸找的数据在上一次IO没有,需要发生一个新的IO时,可以避免对辅助索引的维护工作,只要维护聚簇索引树(主键那个)即可。另一个好处:辅助索引树叶子节点存放的主键值,减少了辅助索引占用的存储空间
使用注意
最好不用UUID=》不适合排序
建议使用自增(对索引树结构影响小)
为什么自增id
只要索引相邻,那么数据也是相邻的页,同时碎片少
什么没法用索引
1.使用Like关键字(%在右面能用到,但是在左边不行)
2.使用多列索引(复合索引)=》必须使用了第一个字段
3.使用or关键字(如果or前后都有索引,那么会使用索引,但是如果有一个不是,就不能用到索引)

也会失效
哪些情况建立索引
- 自动建立唯一索引
- 频繁查找的字段应该建立索引
- 查询中与其他表关联的字段,外键关系建立索引
- 高并发下倾向创建组合索引
- 排序了的字段
- 统计或者分组字段
哪些情况不需要建立
- 数据少
- 经常增删改的表
- 很多重复的字段没必要建立
优化
explain:简称执行计划
事务
事务的ACID
A:原子性
事务开始后的所有操作,要么全都做完,要么全都不做,不可能停滞在中间环节,当事务执行过程中报错,事务会回滚到开始前的状态。
C:一致性
事务开始和结束后,数据库的完整性约束并没有被破坏。比如表中唯一字段的某个值,在事务回滚后变为非唯一字段,就违背了一致性
I:隔离性
同一时间,只允许一个事务请求统一数据,不同事物之间彼此没有干扰
D:持久性
事务完成后,事务对数据库的所有更新将会保存到数据库中,不能回滚
MySQL事务隔离级别

脏读:事务A读取了事务B更新的数据,然后B回滚了,那么A读到的就是脏数据
不可重复读:事务A多次读取同一数据,事务B在事务A多次读取数据过程中,对数据进行了修改并且提交,导致A多次读取同一数据不一致
幻读:A用户使用将数据进行字段修改,此时B用户插入一条原有字段的数据,那么A改后就会发现有一条数据没有动
解决不可重复读的问题只需要锁住满足条件的行,解决幻读要锁住整个表
常见SQL题
1.用一条SQL语句查询出每门课都大于80分的学生姓名
name kecheng fenshu
张三 语文 81
张三 数学 75
李四 语文 76
李四 数学 90
王五 语文 81
王五 数学 100
王五 英语 90
A: select distinct name from table where name not in (select distinct name from table where fenshu<=80)
B:select name from table group by name having min(fenshu)>80
- 学生表 如下:
自动编号 学号 姓名 课程编号 课程名称 分数
1 2005001 张三 0001 数学 69
2 2005002 李四 0001 数学 89
3 2005001 张三 0001 数学 69
删除除了自动编号不同, 其他都相同的学生冗余信息
A: delete tablename where 自动编号 not in(select min(自动编号) from tablename group by学号, 姓名, 课程编号, 课程名称, 分数)
3.一个叫team的表,里面只有一个字段name,一共有4条纪录,分别是a,b,c,d,对应四个球队,现在四个球队进行比赛,用一条sql语句显示所有可能的比赛组合.
答:select a.name, b.name
from team a, team b
where a.name < b.name
4.面试题:怎么把这样一个
year month amount
1991 1 1.1
1991 2 1.2
1991 3 1.3
1991 4 1.4
1992 1 2.1
1992 2 2.2
1992 3 2.3
1992 4 2.4
查成这样一个结果
year m1 m2 m3 m4
1991 1.1 1.2 1.3 1.4
1992 2.1 2.2 2.3 2.4
答案
select year,
(select amount from aaa m where month=1 and m.year=aaa.year) as m1,
(select amount from aaa m where month=2 and m.year=aaa.year) as m2,
(select amount from aaa m where month=3 and m.year=aaa.year) as m3,
(select amount from aaa m where month=4 and m.year=aaa.year) as m4
from aaa group by year
5.说明:复制表(只复制结构,源表名:a新表名:b)
SQL: select * into b from a where 1<>1 (where1=1,拷贝表结构和数据内容)
ORACLE:create table b
As
Select * from a where 1=2
[<>(不等于)(SQL Server Compact)
比较两个表达式。 当使用此运算符比较非空表达式时,如果左操作数不等于右操作数,则结果为 TRUE。 否则,结果为 FALSE。]
原表:
courseid coursename score
1 java 70
2 oracle 90
3 xml 40
4 jsp 30
5 servlet 80
为了便于阅读,查询此表后的结果显式如下(及格分数为60):
courseid coursename score mark
1 java 70 pass
2 oracle 90 pass
3 xml 40 fail
4 jsp 30 fail
5 servlet 80 pass
写出此查询语句
select courseid, coursename ,score ,if(score>=60, “pass”,“fail”) as mark from course
7.表名:购物信息
购物人 商品名称 数量
A 甲 2
B 乙 4
C 丙 1
A 丁 2
B 丙 5
……
给出所有购入商品为两种或两种以上的购物人记录
答:select * from 购物信息 where 购物人 in (select 购物人 from 购物信息 group by 购物人 having count(*) >= 2);
8.
info 表
date result
2005-05-09 win
2005-05-09 lose
2005-05-09 lose
2005-05-09 lose
2005-05-10 win
2005-05-10 lose
2005-05-10 lose
如果要生成下列结果, 该如何写sql语句?
win lose
2005-05-09 2 2
2005-05-10 1 2
答案:
(1) select date, sum(case when result = “win” then 1 else 0 end) as “win”, sum(case when result = “lose” then 1 else 0 end) as “lose” from info group by date;
(2) select a.date, a.result as win, b.result as lose
from
(select date, count(result) as result from info where result = “win” group by date) as a
join
(select date, count(result) as result from info where result = “lose” group by date) as b
on a.date = b.date;
找出所有科目成绩都大于某一学科平均水平的学生

用户每个月的累计访问次数

计算店铺访问数

计算订单相关(having)
已知一个表 STG.ORDER,有如下字段:Date,Order_id,User_id,amount。请给出 sql 进
行统计:数据样例:2017-01-01,10029028,1000003251,33.57。
- 给出 2017 年每个月的订单数、用户数、总成交金额。
- 给出2017年11月的新客户数
也就是指在11月才有第一笔订单
(最小的订单时间是2017-11)
求所有用户和活跃用户的总数以及平均年龄(活跃用户指连续两天都有访问记录的用户)
日期、用户、年龄
2019-02-11,test_1,23
2019-02-11,test_2,19
2019-02-11,test_3,39
2019-02-11,test_1,23
2019-02-11,test_3,39
2019-02-11,test_1,23
2019-02-12,test_2,19
2019-02-13,test_1,23
2019-02-15,test_2,19
2019-02-16,test_2,19















 910
910











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









