










实现内容:
使用scala语言编写独立应用程序,读取HDFS系统文件“/user/hadoop/test.txt”,统计文件行数。
通过使用sbt工具将整个应用程序打包成jar包,并将jar包通过spark-submit提交到spark中运行。
代码:
SimpleApp.scala
import org.apache.spark.SparkContext
import org.apache.spark.SparkContext._
import org.apache.spark.SparkConf
object SimpleApp{
def main(args:Array[String]){
val logFile = "/user/hadoop/test.txt"
val conf = new SparkConf().setAppName("Simple Application")
val sc = new SparkContext(conf)
val logData = sc.textFile(logFile,2).cache()
val num = logData.count()
println("Long: %s".format(num))
}
}
Simple.sbt
输入spark中显示的对应版本即可!
name :="Simple Project"
version := "1.0"
scalaVersion := "2.12.10"
libraryDependencies += "org.apache.spark" %% "spark-core" % "3.1.2"
打包并运行:
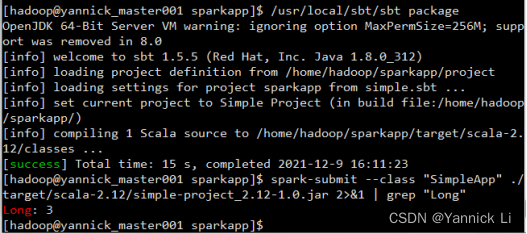
如果不加grep锁定,会显示很多其他不需要的信息。
我们可以看到标红的地方就是最后输出的结果。















 2789
2789











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









