







MapReduce是一种程序开发模式,可以使用大量服务器来并行处理。MapReduce,简单地说,Map就是分配工作,Reduce就是将工作结果汇总整理。
·首先使用Map将待处理的数据分割成很多的小分数据,由每台服务器分别运行。再通过Reduce程序进行数据合并,最后汇总整理出结果。
本章将以WordCount.java作为范例来介绍MapReduce。
7.1简单介绍WordCount.java
下列为WordCount范例,要计算文件中每一个英文单词出现的次数。

范例程序计算英文单词出现次数的大致步骤
WordCount开发步骤
| 顺序 | 开发步骤 | 说明 |
|---|---|---|
| 1 | 编辑WordCount.java | 使用gedit编辑WordCount.java |
| 2 | 编译WordCount.java | 编译、打包WordCount.java程序 |
| 3 | 创建测试文本 | 使用Hadoop目录下的LICENSE.txt文件作为测试文件,并上传文本至HDFS |
| 4 | 运行WordCount.java | 在Hadoop环境运行WordCount |
| 5 | 查看运行结果 | 运行产生的结果会存储到HDFS中,可使用HDFS命令查看 |
7.2编辑WordCount.java
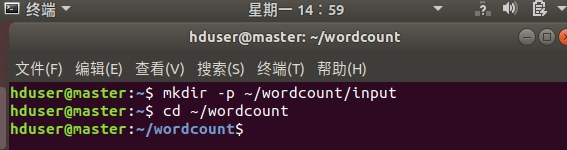
7.2.1创建wordcount目录
mkdir -p ~/wordcount/input
cd ~/wordcount
7.2.2复制WordCount.java程序代码
在游览器中输入下列网站,后续我们将复制WordCount.java源代码
http://hadoop.apache.org/docs/current/hadoop-mapreduce-client/hadoop-mapreduce-client-core/MapReduceTutorial.html#Example
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 369
369











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









