







tips:因为是翻译给自己看的,所以作者什么的没提了。
论文名称:Learning Channel-wise Interactions for Binary Convolutional Neural Networks
论文链接:下载下来了没链接,上传到资源里了,要是网上找不到可以去我的资源那里下载。
二元卷积神经网络的通道交互学习
摘要
本文提出了一种基于通道交互的二进制卷积神经网络学习方法(CI-BCNN)。传统的方法在二值卷积中采用xnor和位计数运算,量化误差较大,与全精度卷积相比,二值特征图中的符号往往不一致,导致信息丢失。相比之下,我们的CI-BCNN挖掘了通道交互,通过它提供先验知识来缓解二值特征映射中符号的不一致性,并在推理过程中保留输入样本的信息。
具体地说,我们通过一个强化学习模型来挖掘通道间的交互,并通过交互的比特数函数在中间特征映射上施加通道间的先验信息。在CIFAR-10和ImageNet数据集上的大量实验表明,该方法比现有的二进制卷积神经网络具有更低的计算和存储开销。
一.介绍
深度卷积神经网络在各种视觉应用中取得了最先进的性能,如目标检测[10,33,22]、跟踪[13,28,1]、人脸识别[38,29,7]等。然而,在便携式设备中部署深度卷积神经网络进行推理,由于计算和存储成本巨大,仍然受到限制。此外,经过良好训练的模型的参数具有高度的冗余性[5]。因此,设计参数较少、结构较轻的深度卷积神经网络是实现高效推理的理想途径。
最近,人们提出了几种神经网络压缩方法,包括剪枝[9,21,12]、量化[23,17,8]、低秩分解[6,39,43]和高效的结构设计[18,15,26]。在这些方法中,网络量化以有限的带宽表示神经网络的参数,以便更快的处理和更少的内存消耗。具有二元权值的神经网络用累加代替乘法累加运算[3,42,14],以节省存储成本和加速计算。然而,实值计算仍然是昂贵的计算。为了解决这个问题,具有二进制权重和激活的神经网络用xnor和位计数操作代替乘法累加[32,23,24]。然而,使用xnor和bitcount运算会导致并累积显著的量化误差,这通常会导致二值特征映射中的符号与其全精度对应的符号不一致。
二值神经网络中的信息丢失解释了与实值神经网络相比,特别是在大规模数据集(如ImageNet)中进行评估时,性能显著下降[4]
本文提出一种CI-BCNN方法来学习具有通道交互作用的二元神经网络,以实现有效的推理。与现有的直接应用xnor和bitcount操作的方法不同,我们的方法根据挖掘出的通道交互来学习交互比特数。
基于通道交互提供的先验知识,对二值特征映射中的不一致符号进行校正,从而在二值神经网络的前向传播中保留输入图像的信息。
更具体地说,我们使用强化学习模型来学习每个卷积层的有向无环图,它代表隐式信道方式互动。我们通过根据图形所施加的效果调整原始位计数的输出来获得交互位计数。我们同时训练二元卷积神经网络和图的结构。图1描述了我们的CI-BCNN和传统的二元神经网络之间的比较,其中二元特征映射中的不一致符号根据通道交互作用进行校正。在CIFAR-10[19]和ImageNet数据集上的实验表明,我们的CI-BCNN在各种网络结构上都比最先进的二进制神经网络有很大的优势。

图1.实值神经网络(top)、Xnor网络(黄色框)和CI-BCNN(绿色框)中的卷积运算。由于xnor和比特计数运算产生的量化误差,xnor网通常输出的二进制特征映射与全精度对应的特征映射(红圈)符号不一致。我们的CI-BCNN根据通道交互提供先验信息,以纠正不一致的符号(蓝色圆圈),从而保留中间特征映射的信息(最好以颜色查看)。
二.相关工作
2.1网络量化:
网络量化由于网络复杂度的降低而引起了机器学习和计算机视觉的广泛关注。现有的方法可分为两类:权重量化的神经网络[3、32、42、14]与权重和激活[32、17、23、24]的比较。基于权值量化的深部神经网络权值量化方法,节约存储成本,用累积代替原有的多重累积,实现快速处理.库尔巴利奥克斯通过刚性符号函数对实值权进行二值化,并在小数据集上获得了足够高的精度。Rastegari等人用比例因子逼近二值化的重值,以提高精度。张志刚等人根据其分布训练了一个自适应量化器,使量化误差最小化,同时保持与位操作兼容。侯等应用泰勒展开方法,将量化扰动引起的损失降到最小,并提出了一种最近的牛顿算法,以求得量化策略的最优解。实证研究表明,更宽的权重表示带宽导致了它们与全精度对应的性能,三值和其他多比特量化方法[44,36,25]的性能相比较,以获得更好的性能。然而,实际值激活会防止由于已有的累积操作而导致实质性加速。
在后一方面,权重和激活都被量化,以便用xnor和比特计数操作代替乘法累积,从而减少计算复杂度。Rastegari等人和Hubara等人提出了权值和激活二值化的神经网络,并应用xnor和位计数运算来替代乘法累积,以获得可观的结果加速。林利用更多的基值和激活二值化,特别是在大型数据集中,提高了性能。刘志强等人将连续块的实值激活与二值化前的身份快捷方式连接起来,以增强网络的表示能力。他们还使用了一种新的训练算法来精确地反向传播梯度。然而,应用
xnor和比特计数操作导致并累积量化误差,导致二值特征映射中的符号与实值对应项不一致,导致信息丢失严重。
2.2深度强化学习:
深度强化学习的目的是学习决策问题的策略,在游戏[27,34]、目标检测[30,31]、视觉跟踪[16,35,40,41]等方面取得了很好的效果。近年来,强化学习被广泛应用于网络压缩。
Lin等人采用策略梯度模型来判断特征映射的重要性,并根据输入图像和当前特征映射对网络进行自适应剪枝,以充分保持网络的能力。Ashok等人通过去除冗余层并缩小剩余层的大小,将大型教师网络缩小为小型学生网络,并采用强化学习模型来学习策略。他等人利用强化学习模型对网络结构空间进行了有效的采样,使得模型在没有预定义管道的情况下被自动压缩。本文将增强学习模型推广到具有二元权值和激活的卷积神经网络中,通过增强学习模型对由xnor和位计数操作引起的不一致符号进行校正,并在前向传播过程中保留输入图像的信息。
三.实现方法
在这一节中,我们首先简要介绍具有二元权值和激活的神经网络,它们是有效的,但是在中间特征映射中存在不一致的符号。然后,我们通过相互作用的位计数来呈现施加通道性相互作用的细节。最后,我们提出了一个策略梯度模型来挖掘渠道交互。
3.1二值神经网络
(由于编辑器问题,以下内容中的形如wlf的公式中,l为右上角的角标,f为右下角的角标)
让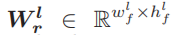 作为给定的L层CNN模型中的第l个卷积层的实值权重并且让
作为给定的L层CNN模型中的第l个卷积层的实值权重并且让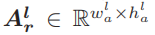 作为给定的L层CNN模型中的第l个卷积层的全精度激活值,在这里(whf,hlf)和(wla,hla)表示第l层中滤波器和特征图的宽度和高度。Alr携带了没有二值化误差的输入样本的信息:
作为给定的L层CNN模型中的第l个卷积层的全精度激活值,在这里(whf,hlf)和(wla,hla)表示第l层中滤波器和特征图的宽度和高度。Alr携带了没有二值化误差的输入样本的信息:
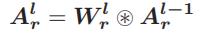
其中,\circledast (以上公式的运算符号)代表标准卷积,为了简单起见,省略了激活层。为了获得计算和存储成本较低的神经网络,我们利用二进制权重和激活,用xnor和位计数操作[32]替换前向传播中的多重累积:
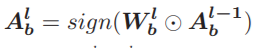
其中,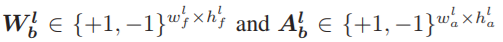 分别是第lth层的二进制权重和激活。⊙表示表示二进制神经网络中表示xnor和位计数运算的按元素的二进制乘积,其中位计数是计算每个卷积中xnor运算结果中的个数。符号是指将大于一的数映射为一,否则映射为负一的符号函数。
分别是第lth层的二进制权重和激活。⊙表示表示二进制神经网络中表示xnor和位计数运算的按元素的二进制乘积,其中位计数是计算每个卷积中xnor运算结果中的个数。符号是指将大于一的数映射为一,否则映射为负一的符号函数。
卷积神经网络二值化的目标是使二值和重值特征映射之间的距离最小化,从而使信息损失最小化,具体如下:
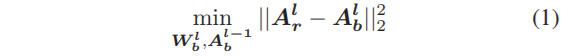
其中优化问题是NP-hard的,等价方程是Alb=sign(Alr).传统方法通过假设:
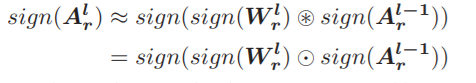
得到近似解Wlb=sign(Wlr)和A(l-1)b=sign(A(l-1)r)。
然而,由于xnor和位计数操作中带来的量化错误,该假设并不总是如图1所示。近似解在Alb中的符号与sign(Alr)不一致,使得方程(1)远离最优状态。此外,在前向传播过程中,误差会跨层累积,造成输入图像的严重信息丢失。我们的目标是通过纠正Alb中不一致的符号,使Alb与各层sign(Alr)之间的差异最小化。
3.2位运算的相互作用
与全精度乘法相比,xnor运算带来了较大的量化误差。此外,原始比特数会累积错误,这通常会在特征映射中输出与其实值对应的符号不一致的符号。实验结果表明,滤波器之间存在隐式依赖关系,通过这种依赖关系可以提供可靠的先验信息来抵消xnor和位计数运算所产生的误差。交互位计数修改原始位计数,如下所示:
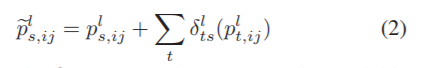
其中升序l表示第lth卷积层中的相应变量。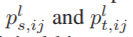 分别是由指示(学生)特征图Fls和指示(教师)特征图Flt中第i行和第j列中的原始位计数输出的整像素值。
分别是由指示(学生)特征图Fls和指示(教师)特征图Flt中第i行和第j列中的原始位计数输出的整像素值。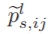 交互位计数输出的相应像素值。
交互位计数输出的相应像素值。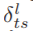 表示从Flt施加在Fls上的影响函数。
表示从Flt施加在Fls上的影响函数。
为了避免网络中交互比特数的计算开销过大,我们简单地将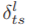 设计为一个离散函数。在考虑Flt与Fls的相互作用时,我们将Flt中像素的取值范围划分为等长的| Kl ts |(l是右上角标,ts是右下角标)区间。Kl ts是一个奇整数,因此如果
设计为一个离散函数。在考虑Flt与Fls的相互作用时,我们将Flt中像素的取值范围划分为等长的| Kl ts |(l是右上角标,ts是右下角标)区间。Kl ts是一个奇整数,因此如果 在没有足够信息的情况下保持接近零,则不存在交互作用。的整数输出如下:
在没有足够信息的情况下保持接近零,则不存在交互作用。的整数输出如下:
其中pk是教师特征图Flt的值范围划分中的第k个间隔的原点。N0是Flt值范围内的最大值,对于同一层中的所有特征图都是相同的。U0表示单位像素修改与N0的比率,手动设置该比率以决定先验信息的重要性。[U0N0]表示大于U0N0的最小整数。同时,Klts可以是一个负整数,这意味着学生和教师的特征图是负相关的。对于函数 的输出,我们有从
的输出,我们有从 到
到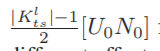 的| Klts |选择,表示Flt对Fls的不同影响。
的| Klts |选择,表示Flt对Fls的不同影响。

图2。基于挖掘图的状态转换和交互位计数的图示。(a) 图挖掘的一个例子。我们创建边,重新分配KLT和删除不同通道之间的边,直到最终确定图形结构(最好用颜色查看)。
(b) 一种通过阶梯函数根据教师特征图中的像素值快速计算图形对交互比特数影响的方法,示例中N0=288,U0设置为0.001
3.3基于策略梯度的信道交互挖掘
道间的交互作用定义为通道间的边,表示为存在和影响。边的存在证明了两个连接节点之间的相关性,如果一致性足够显著,则用一表示,否则用零表示。
边的影响是指如果相关存在。因为将教师特征图的值范围划分为更多的区间代表了通道关系的更大影响,我们用Klts描述了这种影响。挖掘信道交互可以看作是一个Marcov决策过程(MDP),定义为M={S,a,T(S,a),R(S,a)}。在每个步骤中,代理都会执行创建、删除或取消更改边的操作,以修改图中边的存在性,并将不同的值分配给klt,以表示对所有现有边的各种影响。agent迭代地修改图的结构,使获得的报酬最大化,直至收敛或达到步长上限。
状态:状态空间S表示所有卷积层中图的当前结构,表示为存在空间Sle和影响空间Sli跨层索引l的直积:
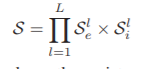
其中Sle定义为存在矩阵(l是右上角标,es是右下)Wles∈{1,0}cl×cl(clxcl是右上角标,l又是右上角标),cl表示第l层中的信道数。对于在Wles中的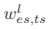 元素,如果第t层到第s层的有向相互作用存在,则等于1,否则等于0。CI-BCNN中的零矩阵等价于传统的二值卷积神经网络,无需通道交互作用。影响空间Sli由具有奇数整数的影响矩阵Wl is来建模。本文将有限离散数空间限定为Wl is∈{±3,±5,±7,…,±(2K0+1)}cl×cl,其中K0是表示作用空间大小的超参数。在我们的实现中,在Wl is中的元素wl is,ts被缩放为
元素,如果第t层到第s层的有向相互作用存在,则等于1,否则等于0。CI-BCNN中的零矩阵等价于传统的二值卷积神经网络,无需通道交互作用。影响空间Sli由具有奇数整数的影响矩阵Wl is来建模。本文将有限离散数空间限定为Wl is∈{±3,±5,±7,…,±(2K0+1)}cl×cl,其中K0是表示作用空间大小的超参数。在我们的实现中,在Wl is中的元素wl is,ts被缩放为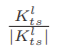 。
。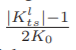 表示正则化,它度量了相应交互作用的影响。
表示正则化,它度量了相应交互作用的影响。
动作:动作集A是存在的动作空间Ale和影响Ali在所有层次上的直接乘积。
Ale由三个合成集组成:Al e,c用于创建边,Al e,d用于删除边,而{unchange}用于保持存在不变。Ali描述了Wl is中所有可能的奇数整数。此外,当图收敛或达到最大步长时,我们停止策略网络。整个动作集描述如下:

图2展示了一个带有动作的阶段转换示例,以及实现交互位计数的快速方法。
过渡函数:T(S,A)→S′是表示新旧状态转换概率的过渡函数。T是在定义状态空间和动作空间后构造的,它是所有卷积层中两个转移函数的直积,Tl e表示存在变换,Tl i表示影响变化:
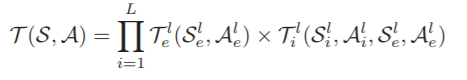
Tl e由一个存在转移矩阵Wl et∈[0,1]cl×cl表示,其元素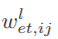 用归一化
用归一化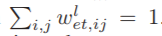 证明了从第i个通道到第j个通道的有向边的连接概率。我们根据以下规则选择动作:
证明了从第i个通道到第j个通道的有向边的连接概率。我们根据以下规则选择动作:
(1)创造:存在矩阵的密度ρ定义为存在矩阵中的密度之比。当存在矩阵的密度比超参数ρmax稀疏时,如果基于Wl et的采样策略选择元素Wl et,ij,并且边缘没有连通,则从第i个通道生成一条指向第j个通道的边缘。
(2)删除:删除的概率表示为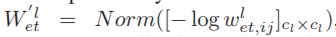 ,其中Norm表示确保
,其中Norm表示确保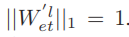 的规范化操作。创建和删除的概率是负相关的,因为低连接概率表示断开连接的趋势边缘。与此同时, Wl et中低概率的差异很小,只能用它们的幂指数来表示,所以我们用对数来表示删除的可能性。如果采样策略选择W’l et中的
的规范化操作。创建和删除的概率是负相关的,因为低连接概率表示断开连接的趋势边缘。与此同时, Wl et中低概率的差异很小,只能用它们的幂指数来表示,所以我们用对数来表示删除的可能性。如果采样策略选择W’l et中的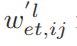 元素,则删除第i个信道到第j个信道之间的现有边缘。
元素,则删除第i个信道到第j个信道之间的现有边缘。
(3)不变:如果没有创建或删除,我们保持边的存在不变。
对于影响部分,我们用影响矩阵Wl it∈[−1,1]cl×cl参数化Tl i,并根据阶梯函数在Al i中为Kts(ts为右下角标)确定地选择奇数:
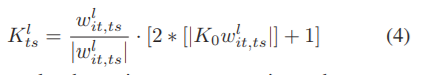
最后,当策略网络收敛或达到最大步长时,我们采取动作停止终止当前的信道交互挖掘的轮次。
奖赏函数:τ轮中的奖赏函数R(S,A)建模如下:
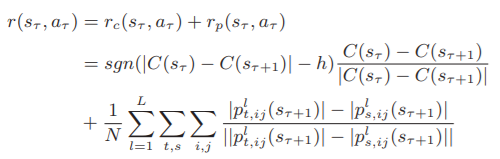
式中,C(sτ)表示在圆τ中挖掘的图下用于预测的二元神经网络的交叉熵损失,h是手动赋值的正阈值。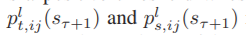 表示学生和教师特征图的第i行和第j列中的像素值,这些像素值是通过与在第t+1轮中挖掘的图形的交互位计数输出的。N表示二元神经网络中特征映射的总像素数,等于
表示学生和教师特征图的第i行和第j列中的像素值,这些像素值是通过与在第t+1轮中挖掘的图形的交互位计数输出的。N表示二元神经网络中特征映射的总像素数,等于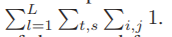 。
。
奖励函数的物理意义用两个术语来说明。rc鼓励对二元神经网络施加图来减少分类中的交叉熵损失。如果减少或增加的交叉熵损失大于设定的阈值h,则代理获得+1或-1奖励,而当损失没有明显变化时,代理不获得奖励。rp旨在确保教师特征图比学生特征图更具信息性,从而提供可靠的先验信息。由于像素携带更多的信息通常被显著激活或停用,我们期望教师特征图中的平均绝对值高于学生特征图中的平均绝对值。
在策略网络中,我们采用了一个编解码器RNN,它将图wles和Wlis的当前状态作为输入,同时输出二进制卷积层的转换矩阵Wl et和Wl it。图3显示了使用策略网络培训CI-BCNN的总体框架。我们利用强化算法[37]来优化策略网络。目标是在整个CI-BCNN学习过程中实现预期收益最大化:
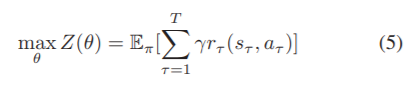
其中θ表示策略网络中的参数,π表示所选策略。T为每一训练批的抽样时间,γ为折扣因素。根据对于策略梯度法,我们计算目标的期望梯度如下:
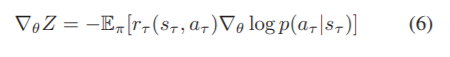
由于对所有可能状态穷竭的困难性,我们采用蒙特卡罗抽样来获得近似梯度。同时,p(aτ|sτ)被探索边缘存在和影响的作用所纠缠,选择影响的概率具有确定性和确定性不可微的为了反向传播梯度,我们将优化问题近似为另一个可微问题(在补充材料中表述)。
正好翻译到第四章:实验前面一段,暂时不翻译了。














 3402
3402











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









