








摘要
知识蒸馏是一种技术,其目的是利用dark知识压缩信息,并将信息从一个庞大、训练有素的神经网络(教师模型)传输到一个较小、能力较差的神经网络(学生模型),从而提高推理效率。由于在边缘计算设备上部署这种笨重模型的复杂性令人望而却步,这种提取知识的方法得到了普及。一般来说,用于教授较小学生模型的教师模型本质上很麻烦,培训成本也很高。为了彻底消除繁琐教师模型的必要性,我们提出了一个简单而有效的知识提取框架,我们称之为动态校正知识提取(DR-KD)。我们的方法将学生转化为自己的老师,如果自己的老师在提取信息时做出错误的预测,那么错误会在提取知识之前得到纠正。 具体而言,教师目标由真实标签代理动态调整,同时提取从传统培训中获得的知识。我们提出的DR-KD在没有复杂、繁琐的教师模型的情况下表现出色,并且在由低成本、动态、有礼貌的教师实施时,实现了与现有最先进的无教师知识提炼框架相当的性能。我们的方法是Allincomparsing,可以用于任何需要分类或对象识别的深度神经网络训练。DRKD在Tiny ImageNet上的测试精度比显著的基线模型提高了2.65%,显著优于任何其他知识蒸馏方法,同时不需要额外的培训成本。
1.介绍
本文旨在没有复杂笨重的教师网络的情况下,在有真实标签的前提下,把学生网络当作弱教师网络(St),再将St的预测的logit与真实标签的logit进行对比,若不正确则把St的预测logit替换为真实标签的logit,以保证弱教师网络St的输出正确率。
总之,这项研究做出了以下重要贡献:
1.我们的策略避免了对教师模型进行整体或大型模型培训的要求,因为一个有效的模型可以被教导充当自己的教师。在这种情况下,不需要大量的培训时间和计算资源,这有利于边缘设备的实时数据处理和部署。
2.DR-KD确保老师从不提取错误的知识。这种安排优于现有的最先进的知识提炼技术。
3.DR-KD在不牺牲响应时间的情况下显著提高了分类任务的性能。
4.我们提出的知识提炼框架与平台无关。因此,它可以在任何深度学习管道中使用,而无需进行大量修改。

图1。假设(a)和(b)中教师模型的输入都是蛇的图像。如(a)所示,教师模型会将错误的知识提取到学生模型中。如(b)所示,DR-KD技术能够在知识提取过程之前纠正错误的知识。
2.相关工作
3.方法&背景知识
4.动态校正知识蒸馏

图2。图示DR-KD的示意图。教师和学生模型都接收输入“X”。教师错误预测的logit在传递到softmax函数之前会被纠正,但学生logit会被直接传递。Kullback-Leibler散度(KLD)由教师和学生的softmax激活确定。同时,学生模型的logit在温度为1时被转换为softmax激活,学生模型的交叉熵使用真实值确定。最后,通过将其与之前计算的KLD相结合来计算总损失。
当一个小模型被训练生成一个教师模型时,如果训练不足,它可能会对样本进行错误分类。如果保持这种配置,并且教师模型做出了不准确的预测,那么学生模型将通过方程式(2)中提到的损失函数的KL散度分量受到错误数据的影响。如果需要,例如,当老师出错时,我们建议在向学生提供信息之前纠正信息。这种纠正过程可以采取多种不同的形式。在本文中,我们提出了一种简单而有效的校正技术作为概念证明。
我们维持了一个与Hinton的知识提炼框架类似的过程,其中有一个教师模型,其知识将被蒸馏成学生。与Tf-KDself一样,我们按照惯例训练学生模型S,以生成预先训练过的教师模型St。然而,我们试图通过使用交换方法纠正错误预测的实例来提高教师的表现,我们称之为动态校正(DR),如等式(3)所示。我们没有直接使用教师的logit,而是对照标签交叉检查logit,以确定教师预测的最高logit是否映射到真实标签。如果没有,我们使用DR函数交换logits,以提取正确的信息作为知识。
校正过程背后的概念如下:如果St模型中的最高logit表示一个不准确的类,我们将用该不准确类的最大logit替换准确类的logit。这将产生一个准确的类,指向最高的logit。使用这种策略,St模型将始终是更好的老师,能够有效地进行知识提炼,同时使S模型能够更有效地学习。
S的输出分数为Ps,St的输出分数为Pt。使用温度为τ的修正softmax(方程式(1))直接软化Ps,以生成Pτs=σ(Ps,τ)。然而,首先通过等式(3)中的整流函数对Pt进行整流,以生成Pt_rect=DR(Pt,Y)。这里Y是一个one-hot编码的真实标签,j=argmax(Y),它是Y的最大值的索引。类似地,l=argmax(Pt),这是Pt最大值的索引。随后,将Pt_rect传递给温度为τ的修改过的softmax,以生成Pτ t_rect。
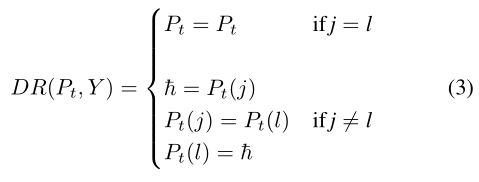
然后用Pτs和Pτt_rect计算KL散度。随后,将KL散度与交叉熵损失相结合,以计算公式(4)中所示的总加权损失,其中与之前一样,CE为交叉熵,α为超参数,以加权损失的不同部分:
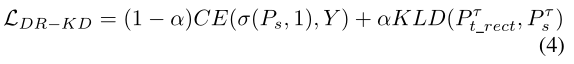
5.实验准备
6.结果
7.结论
传统的知识蒸馏需要培训一个非常庞大的教师模型,这可能需要昂贵的处理时间和金钱。有人提出了完全不需要教师模式的自蒸馏方法,也有人提出了培训训练有素的教师并提供可接受结果的方法。在本文中,我们提出了一种新的方法,即我们采用一个低资源的弱教师模型,然后通过一个校正机制对其输出进行处理,以训练学生模型。为了衡量我们方法的有效性,我们在三个数据集上评估了六个模型的性能。我们证明,这种非常简单的操作产生的结果明显优于之前发表的研究。最值得注意的是,在Tiny ImageNet上,我们的DR-KD技术将测试准确率提高了2.65%,在CIFAR100上,它比基线提高了3.28%。除了先进的技术外,我们的工作还使缺乏高性能计算机的机器学习实践者受益。更大的数据集,如ImageNet,仍然无法在Google Colab上进行训练。按照惯例,为了训练一个小模型,我们必须先训练一个需要昂贵资源的大模型。这种技术使我们只需一个小模型就能获得显著的性能,从而使机器学习在经济上对大众可行。
















 376
376











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









