







一、概念
- G1的目的:Garbage First,优先回收需要收集的垃圾(垃圾优先原则)。也就是重点考虑的是空间方面的问题,同时兼顾了吞吐量和停顿时间
- 官网介绍:G1的设计就是避免Full GC,但是当并发收集不能快速的回收垃圾的时候,也会产生Full GC(用的是MSC算法压缩堆内存,跟CMS的并发失败时用的一样)
- 内存划分的重新定义
- 更短的停顿时间,要多短就多短,可以设置
- 某种程度上去解决空间碎片的问题
- 别动G1的新生代大小(官网禁止的,除非你是大佬),会影响全局停顿时间
二、空间的重新定义(Region 1~32M)
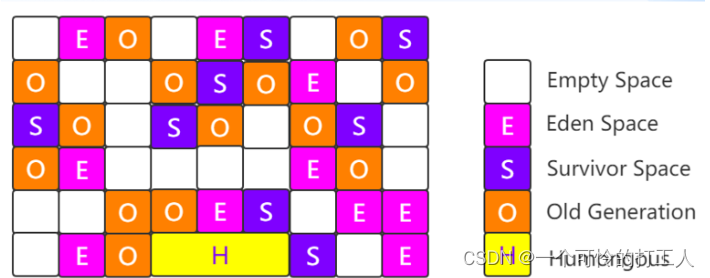
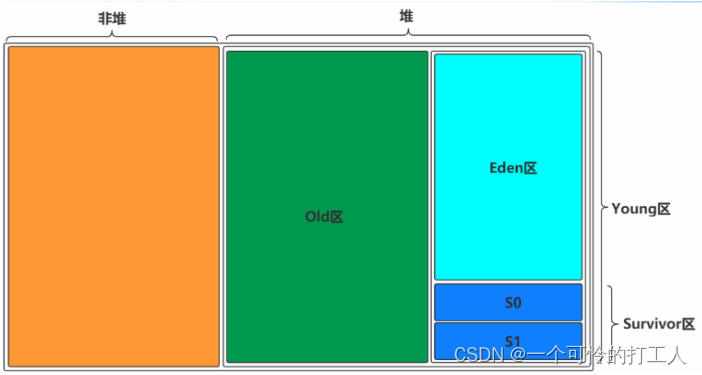
- Region可以继续细分的:
- FreeTag:Empty Space
- YoungHeapRegion:Eden Space、Survivor Space
- HHR(大对象区:当一个对象大小超过Region的1.5倍时):大对象头分区、大对象连续区
- 老年代分区:Old Generation
- 在jdk11后,还有归档区(关闭归档区,开启归档区),用的是堆外内存
- Region总共2048个,大小1~32M。
- 为什么都是2的N次幂?2的N次在位运算的时候效率是最高的
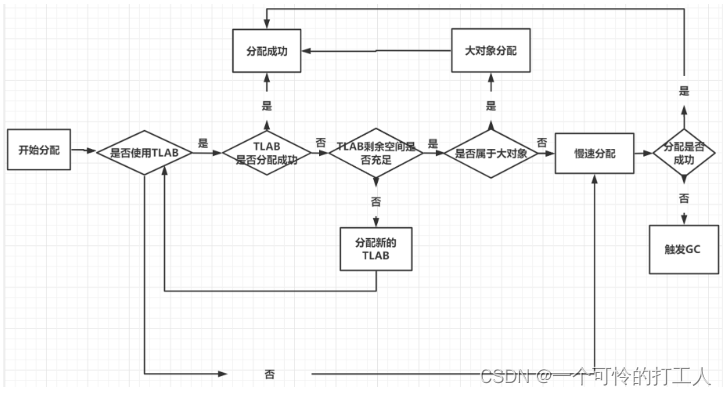
三、TLAB(线程本地分配缓冲区)
- 默认开启的,可以关闭
- 给新对象分配空间的时候,可能会导致多个线程同时访问统一个资源,这个时候一般用全局锁去解决,但是太慢了,就引入了TLAB。
- 在每个Region上开辟一小块区域,用于存放某个线程的TLAB区。
- 流程:
- 当新对象分配内存的时候,看是否开启了TLAB
- 判断TLAB状态
关闭:慢速分配,就是走以前的流程,可能会产生线程竞争同一个资源,然后分配内存空间
开启:则查看TLAB区的内存够不够 - TLAB区内存不够,分配新的TLAB用于存放对象
- 要是大对象,则直接去大对象区
- 要是以上都不满足,就GC把
四、RSET(引用集)
- 其实就是记忆集的一种实现,CMS用的是卡表,这里用的是REST
- G1的REST用来解决新生代对象引用老年代对象问题。
老年代对象引用新生代对象的问题,G1是不存在的。因为G1的垃圾回收分为3中:Young GC、Mix GC(Young GC + 回收部分老年代)、Full GC。所以不管怎么样,都会进行Young GC - 通常用两种方式存引用关系:
obj1.filed = obj2- Point Out:在obj所在的Region中里面有一个Rest,然后在这个Rest里面存放obj2的位置
- Point in:在obj2所在的Region中里面有一个Rest,在这个Rest里面存放看谁都引用了obj2
G1采用的是Point in,省内存。但是Point in也消耗内存啊,所以用了3种表来减小内存的消耗。
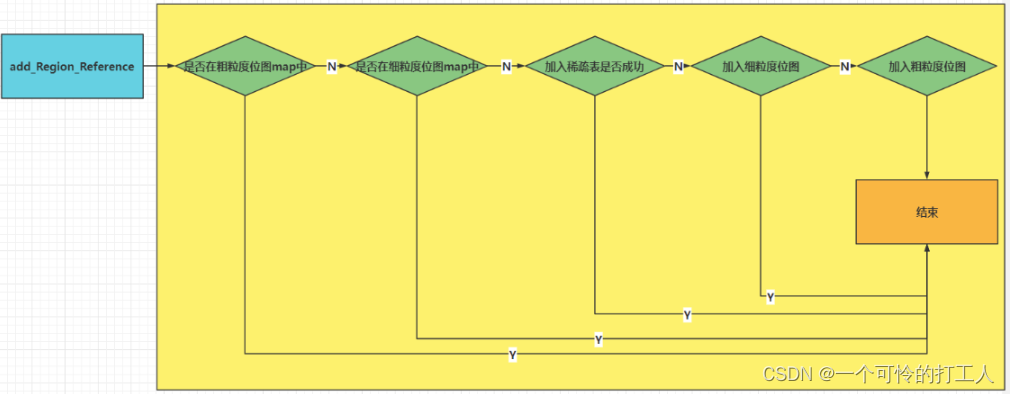
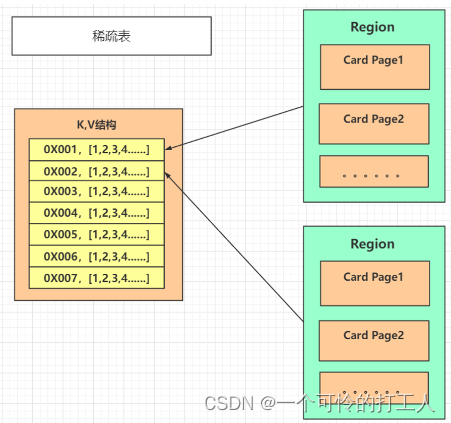
稀疏表
- 本质上就是一个Hash表,在内存上开一块区域,存的K-V对; K只是Region的起始地址,V是一个数组,存的是这个Region里面Card Page的索引号
- 当某个新生代对象被老年代对象引用了,那么就会变成脏卡,那么通过稀疏表我就知道Young GC的时候要把这块的对象也带上
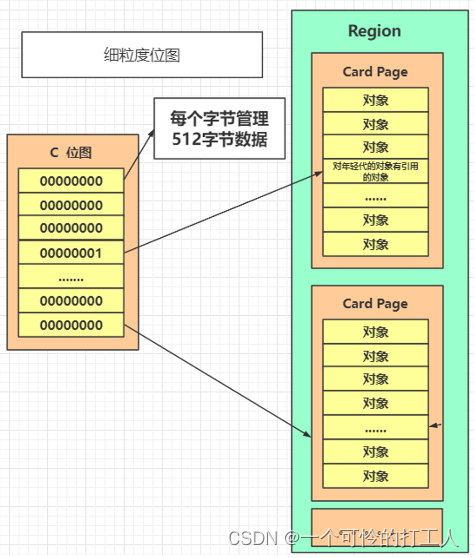
细粒度位图
- 稀疏表有个问题,就是当Card越来越多的时候,会很耗费内存。当超过一个阈值的时候,就变成细粒度位图。
- 用位图的方式来表示这个Card Page是否是脏卡。
这样就用了一个字节来管理一个512字节数据 - 是一个链表,一个Region是一个BitMap
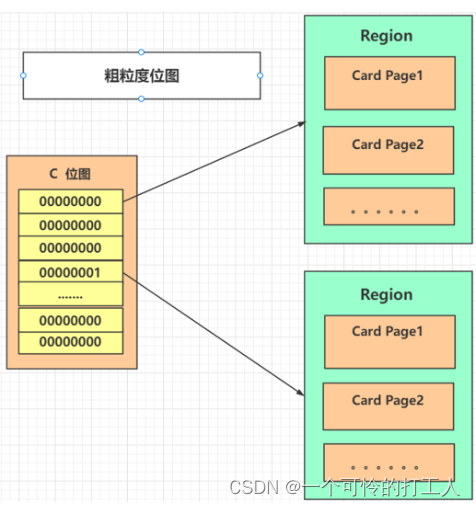
粗粒度位图
- 当细粒度位图的Size也很大咋办?那就把粒度放宽,所有Region用一个bitMap。一位表示一个Region,当这个Region中只要有老年代对象指向新生代,那么就标记
写平常伪共享问题
- 问题
我们一个Cache Line(不会了看一下以前的笔记)是64个字节,当如果有某几个卡表正好位于同一个Cache Line。且同时有某几个线程正好要分别处理他们卡表。
这个时候就是伪共享了:慢。 - 解决方法:
不采用无条件的写屏障,就是在写屏障前,我们先判断一下卡表,只有当这个卡表没有被标记,才会进去标记成脏卡。
-XX:+UseCondCardMark
五、常用参数
- -XX: +UseG1GC 开启G1垃圾收集器
- -XX: G1HeapReginSiz 设置每一个Region的大小,在1~32M之前,2的n次幂
- -XX:MaxGCPauseMillis 最大停顿时间
- -XX:ParallelGCThread 并行GC线程数
- -XX:ConcGCThreads 并发标记的线程数
- -XX:InitiatingHeapOcccupancyPercent 默认是45%,代表GC堆占用多少内存的时候,开始垃圾回收了
六、G1比CMS好在哪里
- G1在空间压缩方面有优势
- G1通过Region的方式,很大程度上解决了内存碎片的问题
- Eden,S,Old区不在固定,内存使用上很灵活
- G1可以通过预设停顿时间来控制垃圾回收的时间,避免了应用雪崩的问题
- G1在垃圾回收后会马上同时做合并空闲内存的工作,而CMS则需要STW去干
七、Cset
- 收集集合(CSet)代表每次GC暂停时回收的一系列目标分区。在任意一次收集暂停中,CSet所有分区都会被释放,内部存活的对象都会被转移到分配的空闲分区中。因此无论是年轻代收集,还是混合收集,工作的机制都是一致的。年轻代收集CSet只容纳年轻代分区,而混合收集会通过启发式算法,在老年代候选回收分区中,筛选出回收收益最高的分区添加到CSet中。
- 说白了,Cset里面存放的就是Young、Old区需要回收的Region集合
- YoungGC的时候就是将所有的Eden、S的Region扔进去,Mixed GC或Full GC是通过算法将回收收益最高的分区扔进去
- 分成2种Cset
- CSet of Young Collection 只专注回收 Young Region 跟 Survivor Region
- CSet of Mix Collection 模式下的CSet 则会通过RSet计算Region中对象的活跃度,活跃度阈值-XX:G1MixedGCLiveThresholdPercent(默认85%),只有活跃度高于这个阈值的才会准入CSet,混合模式下CSet还可以通过-XX:G1OldCSetRegionThresholdPercent(默认10%)设置,CSet跟整个堆的比例的数量上限。
八、Concurrence Refinement Thread(同步优化线程)
- 这个线程主要用来处理代间引用之间的关系用的。当赋值语句发生后,G1通过Writer Barrier技术,跟G1自己的筛选算法,筛选出此次索引赋值是否是跨区(Region)之间的引用。如果是跨区索引赋值,在线程的内存缓冲区写一条log,一旦日志缓冲区写满,就重新起一块缓冲重新写,而原有的缓冲区则进入全局缓冲区。
- Concurrence Refinement Thread 扫描全局缓冲区的日志,根据日志更新各个区(Region)的RSet。这块逻辑跟后面讲到的SATB技术十分相似,但又不同SATB技术主要更新的是存活对象的位图。
- Concurrence Refinement Thread(同步优化线程) 可通过
-XX:G1ConcRefinementThreads (默认等于-XX:ParellelGCThreads)设置。 - 如果发现全局缓冲区日志积累较多,G1会调用更多的线程来出来缓冲区日志,甚至会调用App Thread 来处理,造成应用任务堵塞,所以必须要尽量避免这样的现象出现。可以通过阈值
-XX:G1ConcRefinementGreenZone
-XX:G1ConcRefinementYellowZone
-XX:G1ConcRefinementRedZone
这三个参数来设置G1调用线程的数量来处理全局缓存的积累的日志。
九、Young GC、Mixed GC、Full GC
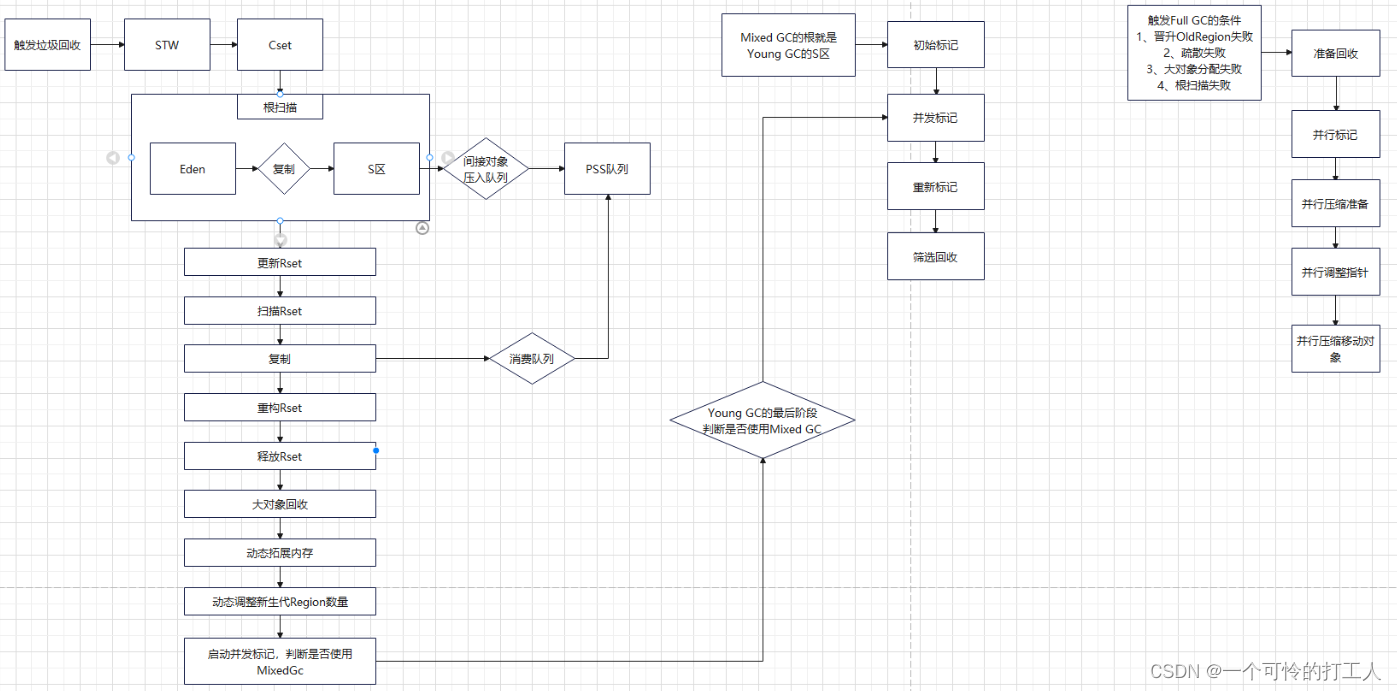
Young GC
- 触发条件
- Eden区的大小 = [ -XX:G1NewSizePercent, -XX:G1MaxNewSizePercent ] = [ 整堆5%, 整堆60% ]
- 在a这个大小的基础上,G1会计算当前回收Eden区的时间,如果远远小于-XX:MaxGCPauseMillis设定的值(每次GC的停顿时间默认200ms),那么就会继续增加Eden区的数量,不会马上进行Young GC
- 当计算的时间接近MaxGCPauseMillis值得时候,触发YoungGC
- 流程
- 根扫描
java根:处理已经加载类的数据、java线程当前栈帧的引用和虚拟机内部的线程
JVM根:处理JVM内部使用的引用(Universe和SystemDictionary)、处理JNI句柄、处理对象锁的引用、处理java.lang.management管理和监控相关类的引用、处理JVMTI(JVM Tool Interface)的引用、处理AOT静态编译的引用
String table根:处理StringTable JVM字符串哈希表的引用 - 对象复制
判断对象是否在CSet中,如是则判断对象是否已经copy过了
如果已经copy过,则直接找到新对象
如果没有copy过,则调用copy_to_survivor_space函数copy对象到survivor区
修改老对象的对象头,指向新对象地址,并将锁标志位置为11
- 根扫描
Mixed GC
- 流程
- 初始标记子阶段
- 并发标记子阶段
- 再标记子阶段
- 清理子阶段
- 垃圾回收
- 是否进入并发标记判断
- YGC最后阶段判断是否启动并发标记
- 判断的依据是分配和即将分配的内存占比是否大于阈值
- 阈值受JVM参数InitiatingHeapOccupancyPercent控制,默认45
- 初始标记
- 需要STW
- 混合式GC的根GC就是YGC的Survivor Region
- 并发标记
- 跟用户线程一起工作
- G1ConcMarkStepDurationMillis JVM参数定义了每次并发标记的最大时长,默认10毫秒
- 重新标记
- 由于并发标记子阶段与用户线程同时运行,对象引用关系仍然有可能发生变化,因此需要再标记阶段STW后处理完成
- 并发清除
- 清理子阶段是指RSet清理、选择回收的Region等,但并不会复制对象和回收Region。清理子阶段仍然需要STW
- gc_efficiency=可回收的字节数 / 预计的回收毫秒数,对Region继续排序,从order_regions函数可以看出,排序依据是gc_efficiency
- 判断CSet中可回收空间占比是否小于阈值
- 阈值受JVM参数 G1HeapWastePercent控制,默认5。只有当可回收空间占比大于阈值时,才会启动混合式GC回收
Full GC
- JDK10之前,都是单线程,JDK10以及以后 多线程收集
- 准备阶段
- 清理软引用,柿子挑软的捏
- 由于Full GC过程中,永久代(元空间)中的方法可能被移动,需要保存bcp字节码指针数据或者转化为bci字节码索引
- 保存轻量级锁和重量级锁的对象头
- 清理和处理对象的派生关系
- 回收阶段
- 并行标记对象
- 并行准备压缩
- 并行调整指针
- 并行压缩
- 并行标记
- 从GC roots出发,递归标记所有的活跃对象。
- 清理弱引用
- 卸载类的元数据(complete_cleaning)或仅清理字符串(partial_cleaning)
- 清理字符串会清理StringTable和字符串去重(JEP 192: String Deduplication in G1)
- 准备压缩
- 计算每个活跃对象应该在什么位置,即计算对象压缩后的新位置指针并写入对象头。
- 如果任务没有空闲Region,则调用prepare_serial_compaction串行合并所有线程的最后一个分区,以避免OOM
- 调整指针
- 在上一步计算出所有活跃对象的新位置后,需要修改引用到新地址。
- 调整之前保存的轻量级锁和重量级锁对象的引用地址
- 调整弱根
- 调整全部根对象
- 处理字符串去重逻辑
- 一个region一个region的调整引用地址
- 移动对象
对象的新地址和引用都已经更新,现在需要把对象移动到新位置














 896
896











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









