







一、编译期优化(执行引擎)

二、JVM执行引擎
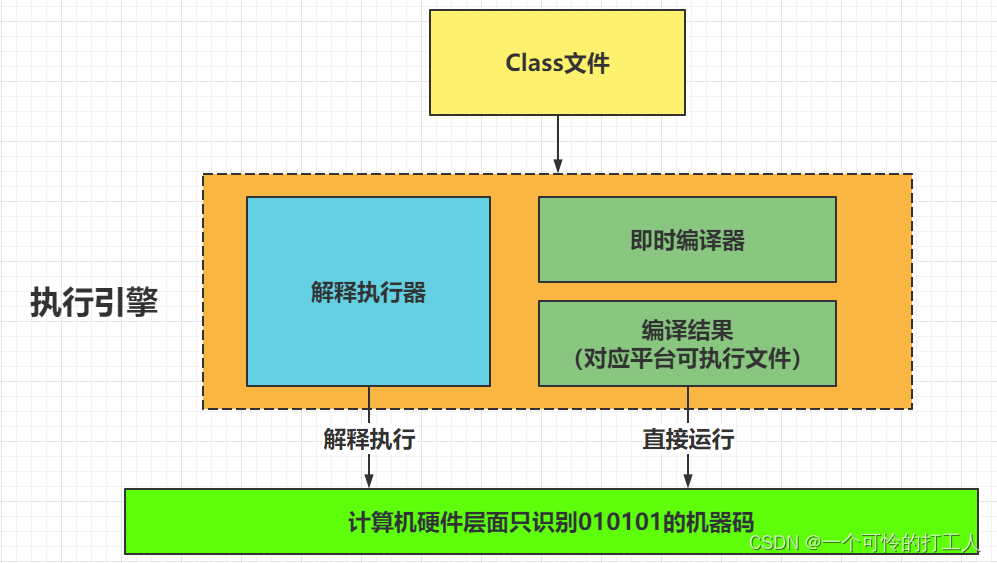
- 编译器将.java文件编译成.class文件,然后交给JVM运行,JVM只认识.class文件。所以很多语言只要能编译成.class文件就能运行,且还能在不同的操作系统上运行
- 最终将.class文件转化成机器码,其实就是00101010这种玩意,然后机器才能运行,那么这个步骤就是执行引擎干的活
- JVM采用的是混合执行模式(默认的,当然你也可以指定用哪一种,看你自己的业务了)
解释执行器
- Interpreter,将字节码(.class)逐行翻译成机器码执行
- 其实刚开始的时候,只有这种模式,但是到后面发现了有些代码块或者方法会被频繁执行,这就是“热点代码”
即时编译器(JIT)
概念
- Just-In-Time compilation(JIT)
- 将字节码编译成对应平台的可执行文件,运行速度快。即时编译器会将这些热点代码编译成与本平台关联的机器码,并进行各个层次的优化,保存到内存中
- 其实你可以理解为,就玩意就是一个“缓存”,将热点代码缓存了
C1、C2
- 在我们的JVM里面有2个JIT,C1和C2
- C1:Client Compiler,适合用于执行时间短或者对启动性能有要求的程序,编译速度快
- C2:Server Compiler,适合用于执行时间长或者对峰值性能有要求的程序,编译后的方法执行快
- jdk1.7以后,hotspot使用分层编译的方式
- 分层编译也就是会结合C1的启动性能优势和C2的峰值性能优势,热点方法会先被C1编译,然后热点方法中的热点会被C2再次编译
- -XX:+TieredCompilation开启参数
JVM分层编译5个阶段
- Java 虚拟机内置了 profiling。(profiling 是指在程序执行过程中,收集能够反映程序执行状态的数据。这里所收集的数据我们称之为程序的 profile)
- 解释执行
- 简单的C1编译:仅仅使用C1做一些简单的优化,不会开启profiling
- 受限的C1编译代码:只会执行方法调用次数以及回边次数多的Profiling的编译
- 完全的C1编译:将profiling里面的代码全部编译
- C2编译代码
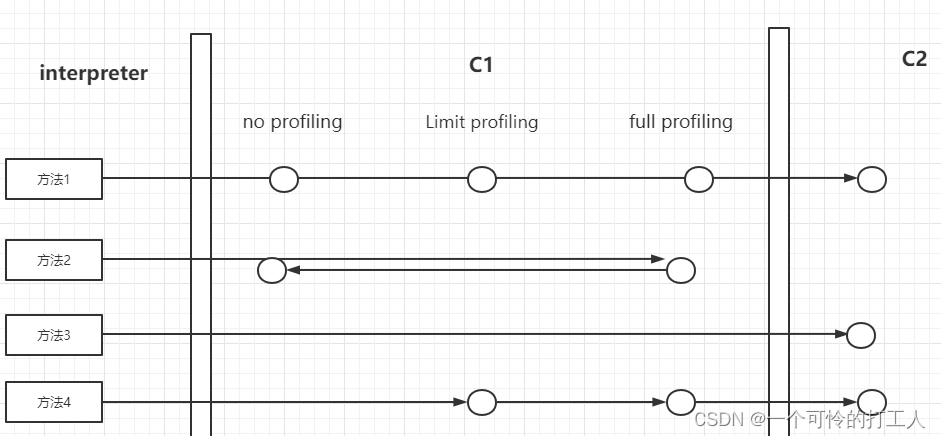
流程:- C1的no profiling和C2都是可终止状态
- “方法1”:正常情况下,热点代码的流程
- “方法2”:如果方法的字节数比较少(set,get方法),而且3层的profiling没有啥数据收集的,那么C1和C2效率差不多,那么就是C1的no profiling
- “方法3”:当C1很忙,那么就直接进入C2
- “方法4”:当C2很忙,那么就先进入C1,相当于一个缓冲
热点代码
- 频繁执行的方法:会将这个方法作为编译对象(方法计数器)
- 循环:会将这个循环所属的方法作为编译对象(回边计数器)
- 怎样判断热点代码?
- 基于采样的热点探测:虚拟机会周期性的对栈顶的方法进行检查,如果某个方法一直在栈顶就证明他是热点方法
- 缺点:死锁的话,岂不是判断失误?它会一直在栈顶
- 优点:简单,高效
- 基于计数器的热点探测:每个方法都有一个计数器,执行次数超过阈值了就是热点方法了。
- 缺点:麻烦,且不能获取这个方法在实际调用中的上下文环境
- 优点:精准
- hotspot用的是计数器:方法计数器和回调计数器
- 基于采样的热点探测:虚拟机会周期性的对栈顶的方法进行检查,如果某个方法一直在栈顶就证明他是热点方法
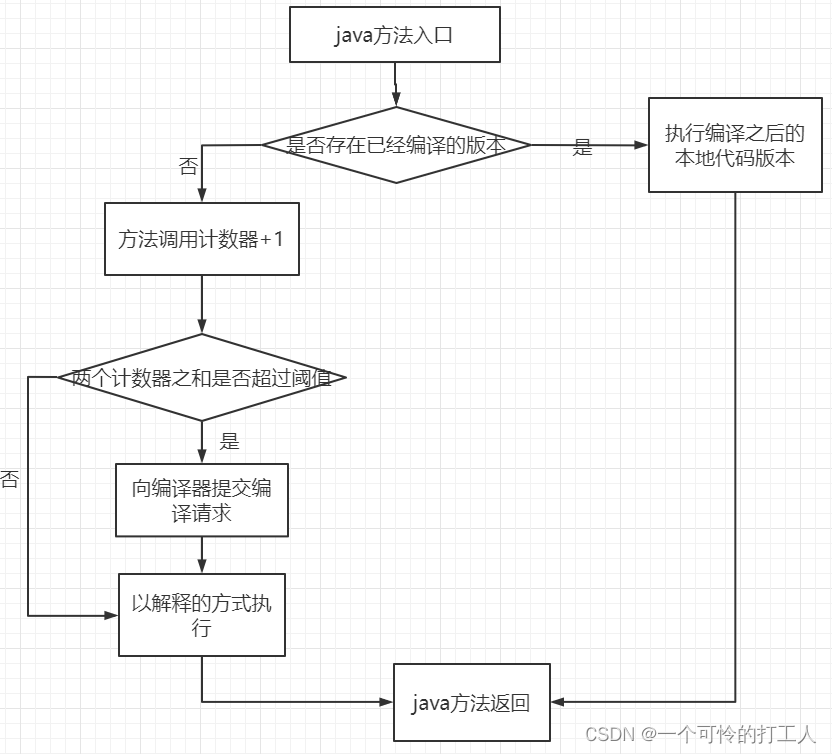
- 方法计数器:
- client下阈值默认1500,server下阈值默认10000,可以 -XX:CompileThreadhold 来人为设定。
- 计数并不是一个绝对的数字,他是存在周期的,即代码在一段时间内的调用次数。当超过某个时间后,如果方法的调用次数还不满足编译阈值,就会衰减一半,俗称”热度衰减“
举个例子:1年前你的方法执行了1000次,今天你的方法执行了500次,会被编译吗? - 进行热度衰减的动作是在虚拟机进行垃圾收集时顺便进行的,可以使用虚拟机参数
-XX:CounterHalfLifeTime 参数设置半衰周期的时间,单位是秒。整个 JIT 编译的交互过程如下图
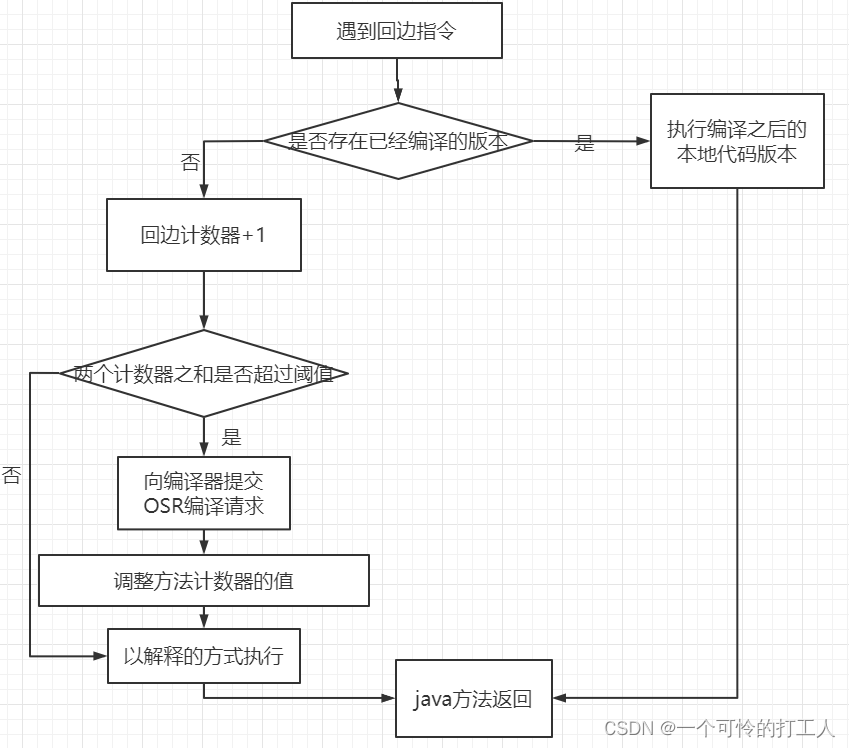
- 回边计数器
- 统计一个方法中循环体被调用的次数,在字节码中遇到控制流向后跳转的执行叫做“回边”,建立回边计数器就是为了OSR编译。
- -XX:OnStackReplacePercentage 来简介调整阈值,计算公式如下:
- 在 Client 模式下, 公式为 方法调用计数器阈值(CompileThreshold)X OSR 比率(OnStackReplacePercentage)/ 100 。其中 OSR 比率默认为 933,那么,回边计数器的阈值为 13995。
- 在 Server 模式下,公式为 方法调用计数器阈值(Compile Threashold)X (OSR 比率(OnStackReplacePercentage) - 解释器监控比率(InterpreterProfilePercent))/100。其中 onStackReplacePercentage 默认值为 140,InterpreterProfilePercentage 默认值为 33,如果都取默认值,那么 Server 模式虚拟机回边计数器阈值为 10700 。
- 回边计数器没有热度衰减
OSR编译
- JVM除了以方法为单位的编译,还存在以循环为单位的编译,叫做On-Stack-Replacement(OSR)编译
- 用循环的回边计数器来触发这种编译
- 就是动态的替换了栈帧上的方法,就是在非方法入口处进行解释执行和编译后的代码之间的切换。
- 在不启用分层编译的情况下,触发 OSR 编译的阈值是由参数 -XX:CompileThreshold 指定的阈值的倍数。
- 该倍数的计算方法为:(OnStackReplacePercentage - InterpreterProfilePercentage)/100
- 其中 -XX:InterpreterProfilePercentage 的默认值为 33,当使用 C1 时 -XX:OnStackReplacePercentage 为 933,当使用 C2 时为 140。
- 也就是说,默认情况下,C1 的 OSR 编译的阈值为 13500,而 C2 的为 10700。
- 在启用分层编译的情况下,触发 OSR 编译的阈值则是由参数 -XX:TierXBackEdgeThreshold 指定的阈值乘以系数。
Code Cache(方法区)
- 即时编译器编译后的数据存放Code Cache(方法区)
- JIT编译、JNI等都会编译代码到native code,其中JIT生成的native code占用了Code Cache的绝大部分空间,他是属于非堆内存的。
- 简而言之,JVM Code Cache (代码缓存)是JVM存储编译成本机代码的字节码的区域。我们将可执行本机代码的每个块称为 nmethod 。 nmethod 可能是一个完整的或内联的Java方法。
- 即时( JIT )编译器是代码缓存区的最大消费者。这就是为什么一些开发人员将此内存称为JIT代码缓存。
- 优化:
- 这个区域的大小是固定的。满了就不编译了,就摆烂了
- InitialCodeCacheSize –初始代码缓存大小,默认为160K
- ReservedCodeCacheSize –默认最大大小为48MB
- CodeCacheExpansionSize –代码缓存的扩展大小,32KB或64KB
增加ReservedCodeCacheSize可能是一个解决方案,但这通常只是一个临时解决办法。 - JVM提供了一个 UseCodeCache 刷新选项来控制代码缓存区域的刷新。其默认值为false。当我们启用它时,它会在满足以下条件时释放占用的区域:
- 代码缓存已满;如果该区域的大小超过某个阈值,则会刷新该区域
- 自上次清理以来已过了特定的时间间隔
- 预编译代码不够热。对于每个编译的方法,JVM都会跟踪一个特殊的热度计数器。如果此计数器的值小于计算的阈值,JVM将释放这段预编译代码
扩展
- 在Java9以后,Code Cache区被分成了3块
- -XX:nonNMethoddeHeapSize
- -XX:ProfiledCodeHeapSize
- -XX:nonprofiedCodeHeapSize
- 这种新结构以不同的方式处理各种类型的编译代码,从而提高了整体性能。
- 例如,将短命编译代码与长寿命代码分离可以提高方法清理器的性能——主要是因为它需要扫描更小的内存区域。类似于分代了啊
- 在Java9中,引入了AOT(Ahead-Of-Time)编译器
- 即时编译器是在程序运行过程中,将字节码翻译成机器码。而AOT是在程序运行之前,将字节码转换为机器码
- 优势:这样不需要在运行过程中消耗计算机资源来进行即时编译
- 劣势:AOT 编译无法得知程序运行时的信息,因此也无法进行基于类层次分析的完全虚方法内联,或者基于程序 profile 的投机性优化
- 在java10中,引入Graal编译器
- 它是一个以Java为主要编程语言,面向字节码的编译器
- Graal既可以作为动态编译器,在运行时编译热点方法;也可以作为静态编译器,实现AOT编译。














 546
546











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









