






python爬虫requests和bs4引入
python:网络爬虫:利用优秀的第三方库,如requests,beautifulsoup
1.前提基础:
Python3安装&Python3环境配置
Pycharm安装
备注:电脑没有pycharm也可以:
(建议安装:PyCharm 可以为我们节省大量时间,它能够管理代码,并完成大量其他任务,如 debug 和可视化等):
2、对于没有pycharm的伙伴们:requests和bs4引入
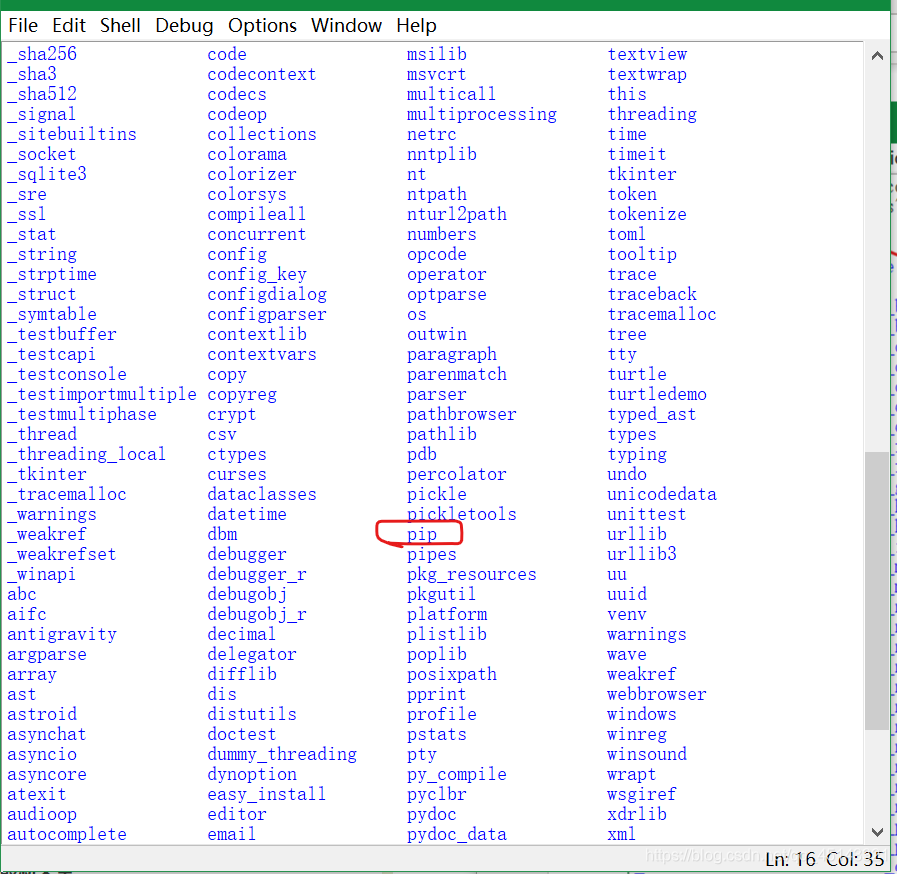
2.1 pip的检查
现在都会自带pip,不确定的可以自己按下图检查一下:
查看python已有的库:首先进入IDLE面板,输入
help('modules')

2.2 requests和bs4引入
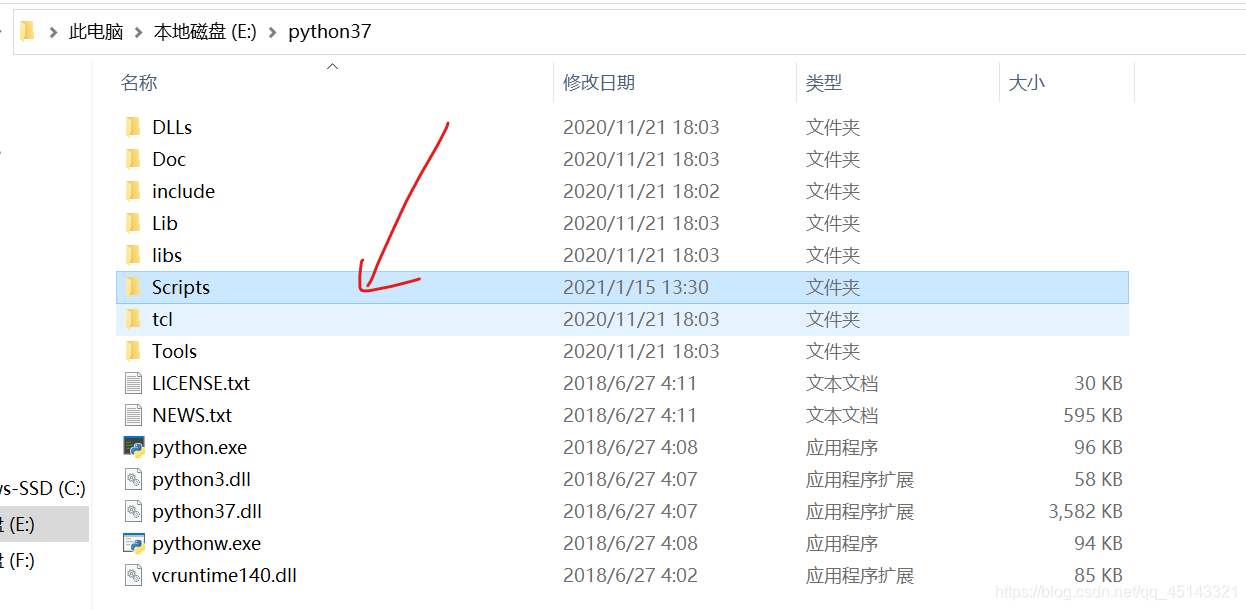
- 找到自己电脑安装python的文件夹,找到子文件夹Scripts
- 进入Scripts文件夹
点击最前面的文件夹符号
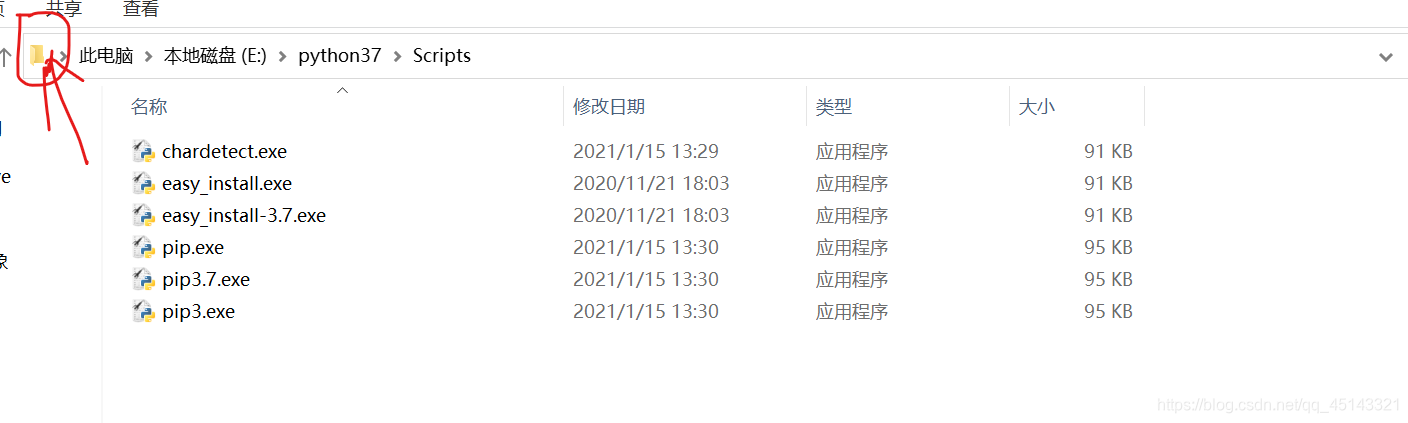
出现如下现象:
点击输入cmd:进入窗口
此时输入:pip install requests,按下回车,等待引入。
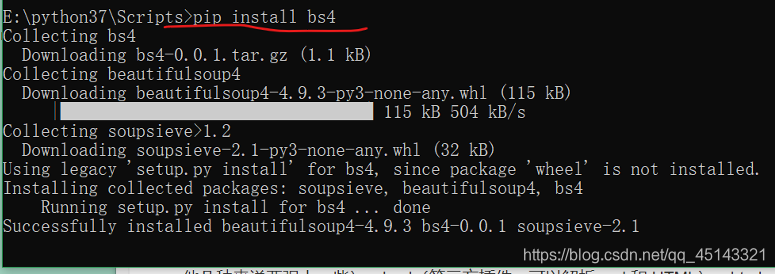
之后再输入 pip install bs4,按下回车,等待引入。
2.3 检查是否成功引入
IDLE面板输入import requests,如果没有出现任何代码提示,证明引入成功。
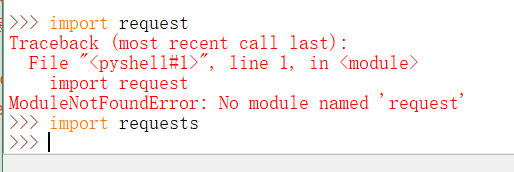
3.有pycharm的小伙伴:
- 点击File-----settings-------Project untitled-------project Interpreter
- 参考链接
点击”+“
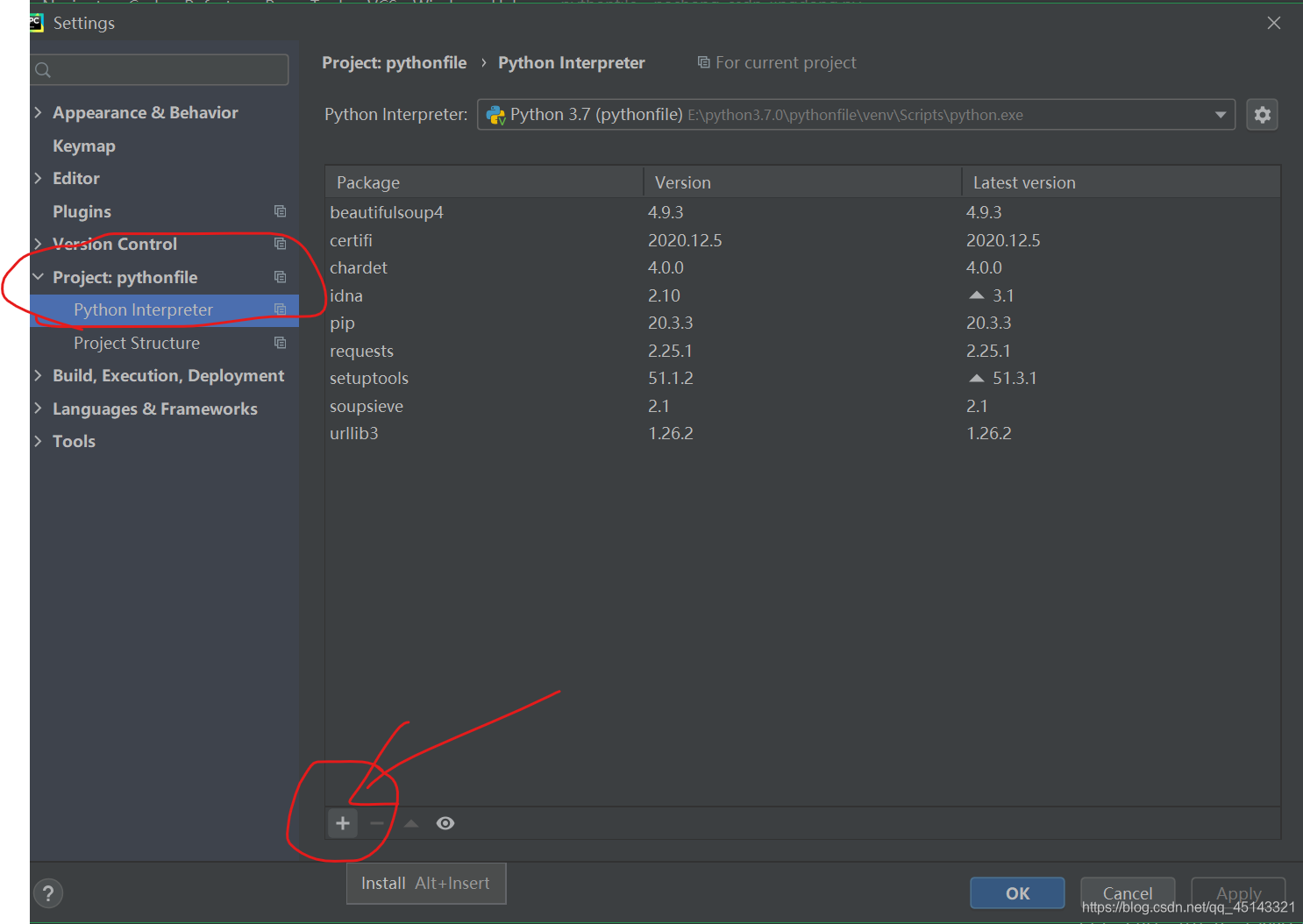
搜索”Beautifulsoup4“,紧接着点击底部”install“
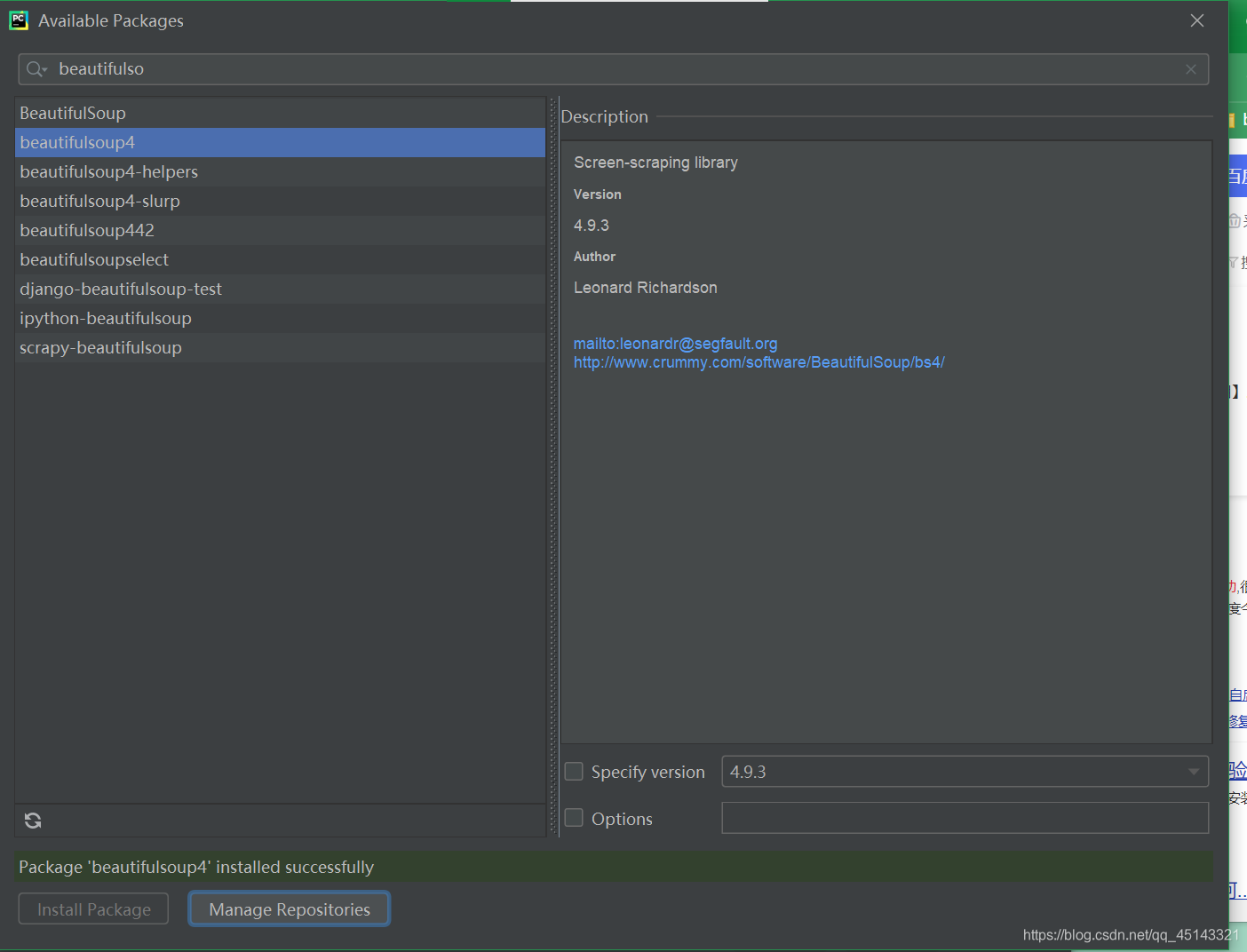
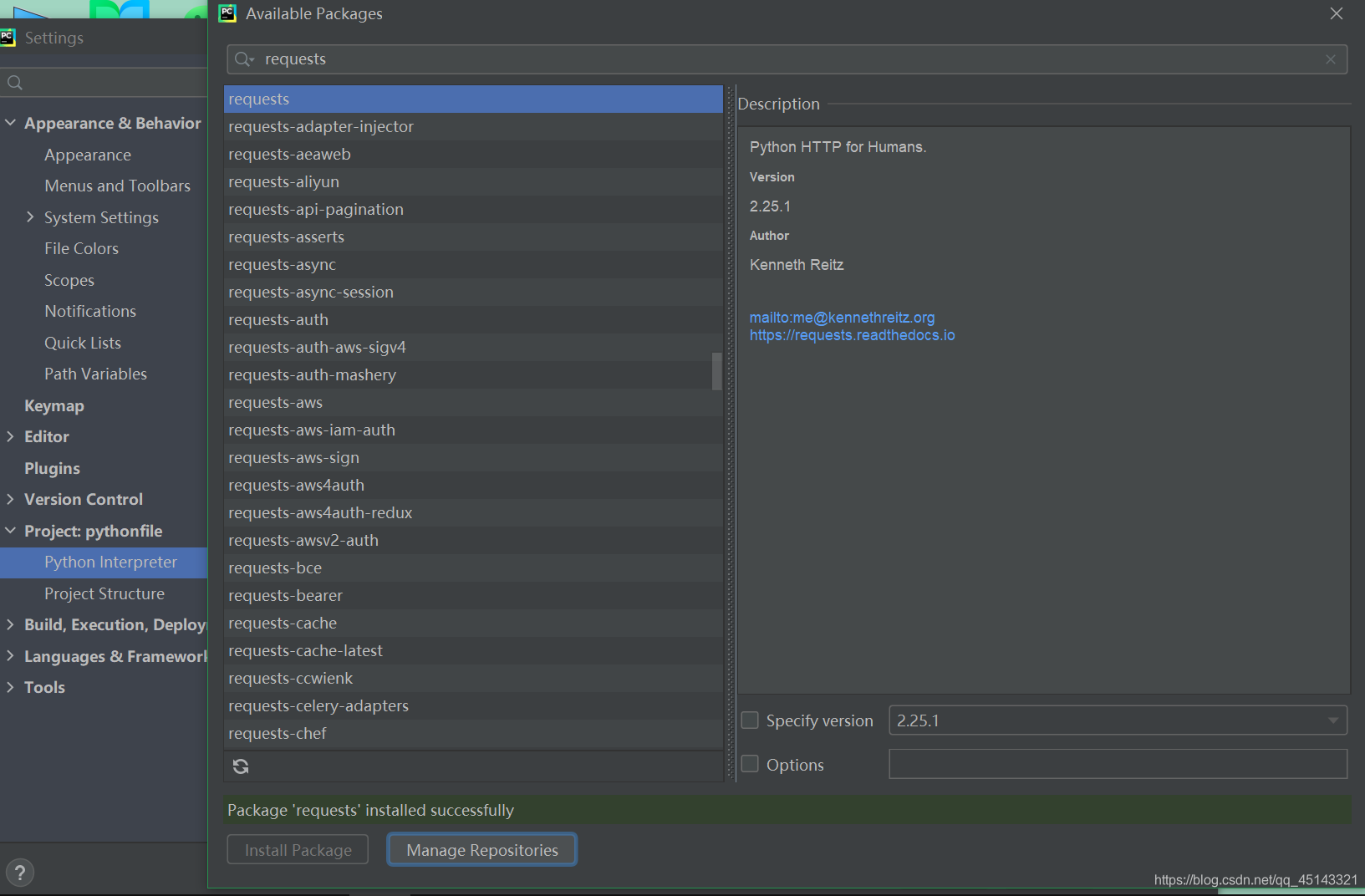
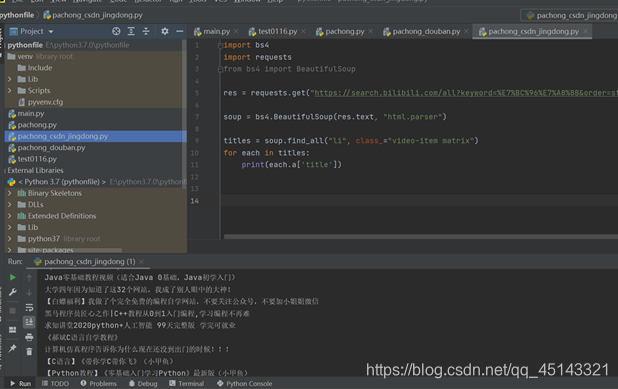
4.爬虫代码
import bs4
import requests
from bs4 import BeautifulSoup
res = requests.get("https://search.bilibili.com/all?keyword=%E7%BC%96%E7%A8%8B&order=stow&duration=0&tids_1=0")
soup = bs4.BeautifulSoup(res.text, "html.parser")
titles = soup.find_all("li", class_="video-item matrix")
for each in titles:
print(each.a['title'])
要格外注意空格和隔行,过多过少都会出现失误
运行结果















 2596
2596











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









