







分析目标网站
- 目标网站的域名│www.dianyinggou.com/linkNav/
- 网站结构 | 静态
- 是否反爬虫 | 否
制定攻略
1.将分类页面的目录和名称写进列表里面,然后通过循环将列表里面的目录和名称依次导出,目的是为了组合成新的链接,方便访问下级链接
如:
list=['new','hot','free']
length=len(list)
for i in range(0,length):
link="http://www.baidu.com/"+list[i]
这样就得出了下级链接

2.得到连接后,需要requests对它进行访问
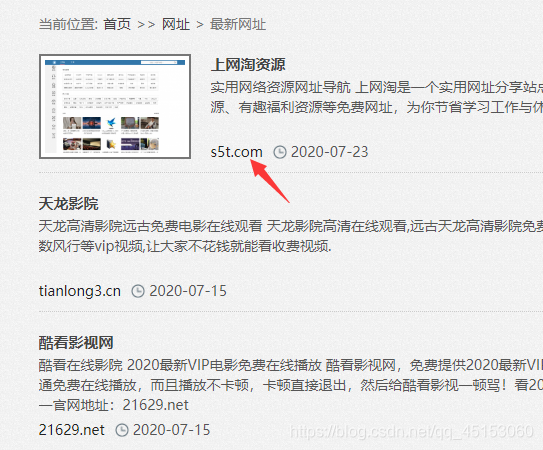
可以看到,我们想要的链接就在这个位置,只需要将这个地方进行标签定位就能获取到我们想要的值,但是在这之前我们需要看看这个页面有多少这样的网址
3.
可以看到有很多页,我们还要在代码中添加自动翻页的功能
4.首先我们要先知道一共有多少页面才好下手,这就要找末页的元素,打开开发者工具点击末页,可以看到,链接中刚好存在最大数,只需要提取最大数就可以利用for循环来进行翻页了,因为链接也是按照数字排序的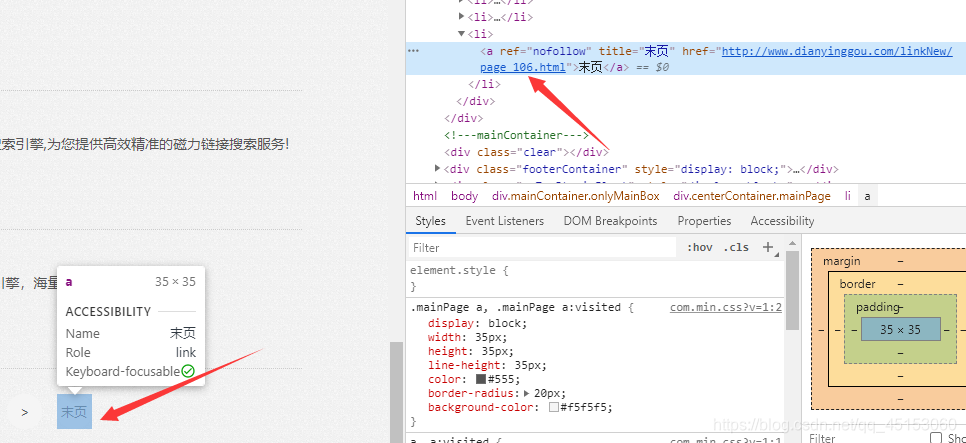

5.最后就简单了,直接上代码
使用到的工具
- pycharm
- Hbuilder
- 一台已经布置好的云服务器
代码
import requests
from bs4 import BeautifulSoup
# 网站根域名
root_url = "http://www.dianyinggou.com/"
# 定义分类页面的目录
page = ['linkNew/', 'linkHot/', 't/btcili/', 't/zaixianyingyuan/', 't/yingshixiazai/', 't/tiantianzhuiju/',
't/dongmanyingshi/', 't/jilupian/', 't/shipinjiexi/', 't/zimuxiazai/', 't/yingshizhoubian/', 't/shipinzhibo/',
't/zongyiyule/']
# 定义分类页面名
page_name = ['最新网址', '热门网址', 'BT磁力', '在线影院', '影视下载', '天天追剧', '动漫影视', '纪录片', '视频解析', '字幕下载', '影视周边', '视频直播', '综艺娱乐']
# 计算共有几个分类页面
length = len(page)
# 获取分类页面的地址
for i in range(0, length):
page_link = root_url + page[i]
print("<h3>" + page_name[i] + "</h3>")
# 直接访问分类页面地址
r = requests.get(page_link)
# 将得到的页面数据解析
soup = BeautifulSoup(r.text, "lxml")
# 定位到分类页面的末页链接
last_link = soup.find('div', class_='centerContainer mainPage').find_all('a')[-1]
# 判断链接是否为空链
if last_link is not None:
# 提取链接中的href元素
last_link = last_link['href']
# 提取分类页面连接中的最大数
max_page_num = last_link.replace(page_link + 'page_', '').replace('.html', '')
# 利用最大数制造循环,从小到大赋值给j,然后利用循环数来翻页
for j in range(0, int(max_page_num)):
# 目标链接
page_order_link = page_link + 'page_' + str(j) + '.html'
# 请求目标链接
r = requests.get(page_order_link)
# 解析页面
soup = BeautifulSoup(r.text, "lxml")
# 定位页面标签,将获得的值存储为列表
target_domains = soup.find_all('div', class_='rightInfo')
# 利用循环将表中的数据提取出来
for target_domain in target_domains:
# 网站名称
target_domain_name = target_domain.find('h4').find('a')['title']
# 网站链接
target_domain_link = target_domain.find('ul', class_='info').find('a').text
#打印出html代码
print("<a href=\"http://" + target_domain_link + "\" >" + target_domain_name +"</a>")
将打印出的代码拷贝进Hbuilder
将样式稍加修改,然后保存进html文件中,最后上传至服务器,最后做出来的效果

闲聊加群:695650348,群里有学习python的资料,还有各种资源或软件,有问题可以私聊管理员解决


















 1027
1027

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











