






文章目录
前言
关于mongoDB在项目中的实际运用
提示:以下是本篇文章正文内容,下面案例可供参考
一、mongoDB是什么?
MongoDB是一个开源的、基于分布式文件存储的数据库,由C++语言编写。
它旨在为WEB应用提供可扩展的高性能数据存储解决方案。MongoDB定位在介于关系数据库和非关系数据库之间的产品,被认为是非关系数据库当中功能最丰富、最像关系数据库的系统。其支持的数据结构非常松散,基于类似JSON的BSON(Binary Serialized Document Format)格式,因此可以存储比较复杂的数据类型。MongoDB的一个显著特点是其支持的查询语言非常强大,语法类似于面向对象的查询语言,几乎可以实现类似关系数据库的单表查询功能,并且支持对数据建立索引。
此外,MongoDB具有高性能、易部署、易使用的特点,支持多种语言,包括Ruby、Python、Java、C++、PHP、C#
等,并且可以通过网络访问。它使用面向集合的存储方式,数据被分组存储在数据集中,这些集合类似于关系型数据库中的表,但不需要定义任何模式。
在此主要是针对Java中的一些运用
二、使用步骤
1.引入Maven
代码如下(示例):
 如需要再控制台打印语句
如需要再控制台打印语句
在配置文件中进行配置
 使用该插件
使用该插件

2.mongoDB的使用
2.1、构造查询条件
import com.mongodb.client.MongoClients;
import com.mongodb.client.MongoClient;
import com.mongodb.client.MongoDatabase;
import com.mongodb.client.MongoCollection;
import com.mongodb.client.model.Filters;
import org.bson.Document;
public class MongoDBQueryExample {
public static void main(String[] args) {
// 连接到MongoDB服务器
MongoClient mongoClient = MongoClients.create("mongodb://localhost:27017");
// 选择数据库和集合
MongoDatabase database = mongoClient.getDatabase("myDatabase");
MongoCollection<Document> collection = database.getCollection("myCollection");
// 构造查询条件
Document query = new Document("age", new Document("$gt", 30));
// 执行查询
for (Document document : collection.find(query)) {
System.out.println(document.toJson());
}
// 关闭连接
mongoClient.close();
}
}
在这个示例中,我们使用了Filters类来构造查询条件。Filters.gt(“age”, 30)表示查找年龄大于30的文档。然后,我们将查询条件传递给collection.find()方法来执行查询。
也可以使用query进行构造多个查询条件
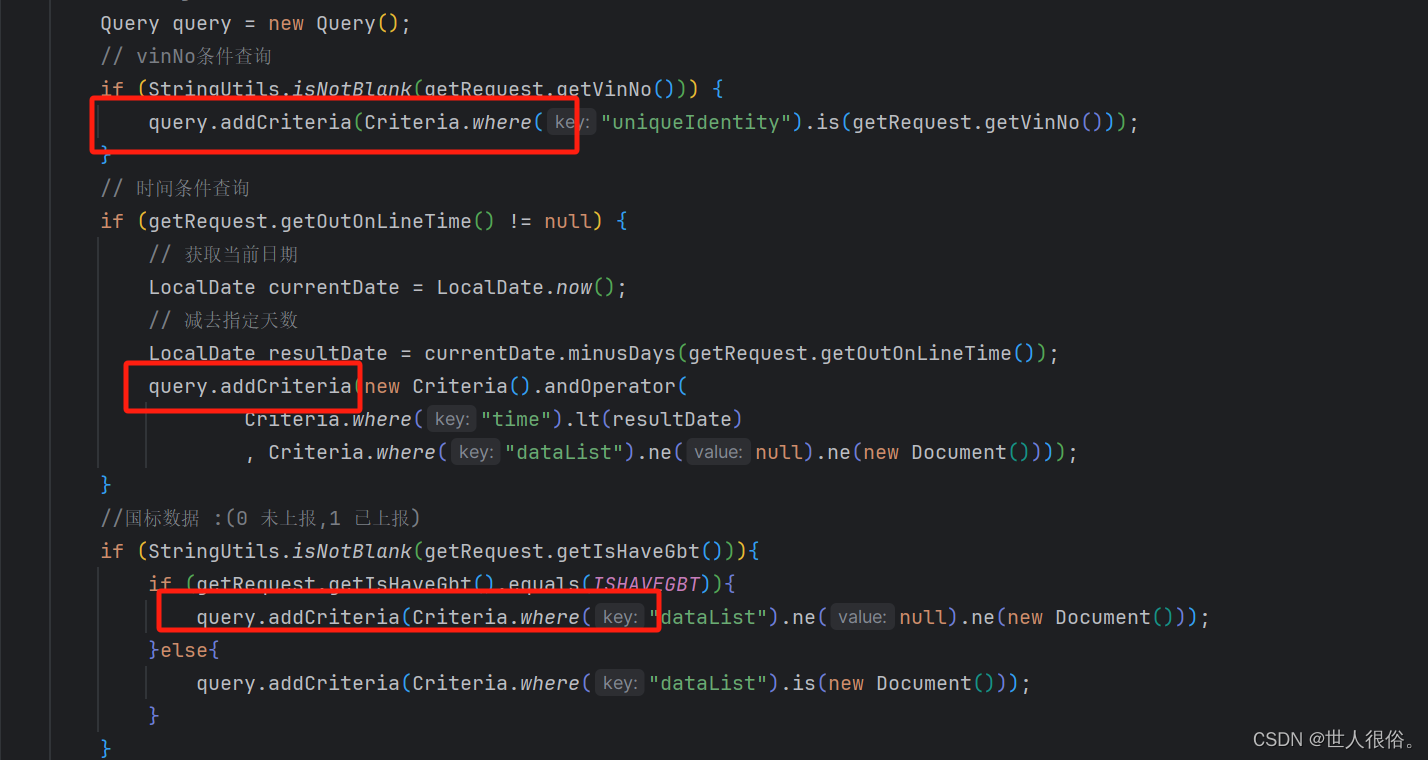 使用query,构造多个条件,调用mongo中的方法,可进行单个查询,或者多条数据查询的操作。
使用query,构造多个条件,调用mongo中的方法,可进行单个查询,或者多条数据查询的操作。
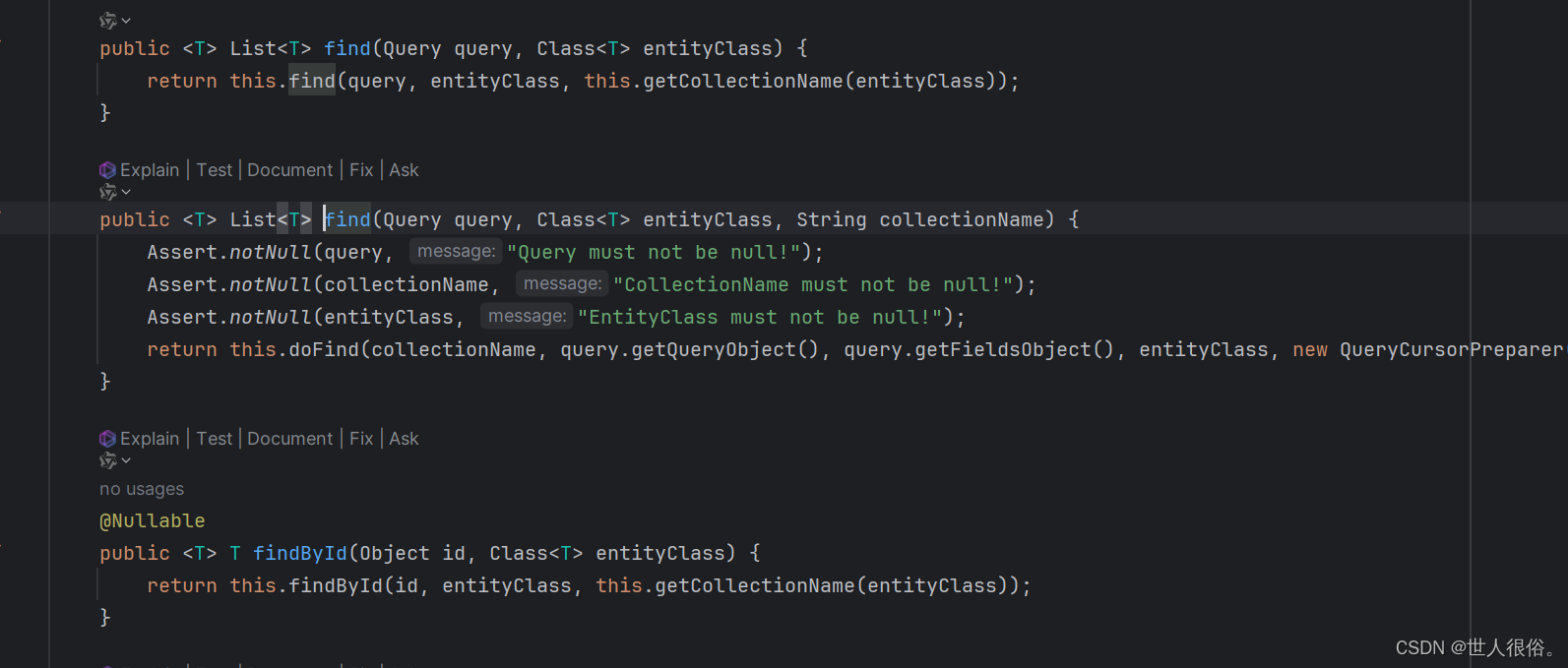
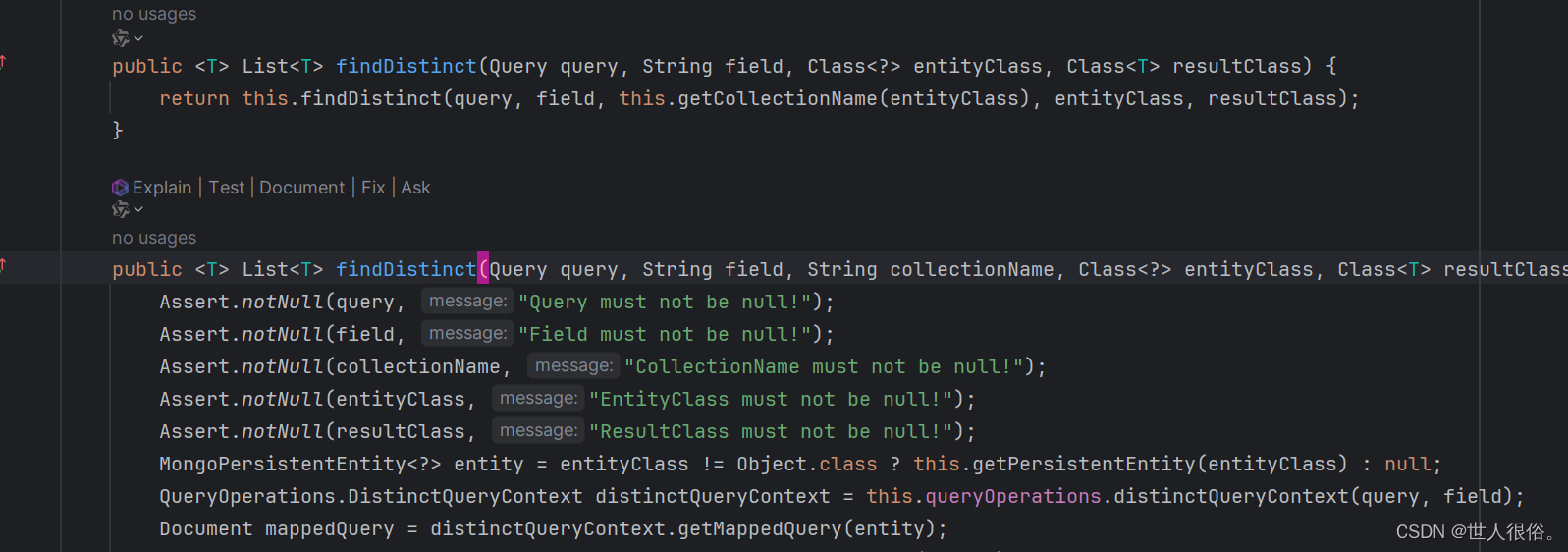
2.2、方法
mongoDB中封装了许多方法,这些方法可以让我们在开发的时候直接进行调用。如:
2.2.1、find()
该方法用于查询集合中的文档。它接受一个查询条件作为参数,并返回匹配的文档列表。例如
MongoCollection<Document> collection = database.getCollection("myCollection");
FindIterable<Document> documents = collection.find();
for (Document document : documents) {
System.out.println(document.toJson());
}
2.2.2、insertOne()
该方法用于向集合中插入单个文档。它接受一个文档对象作为参数,并返回插入操作的结果。例如:
Document document = new Document("name", "John")
.append("age", 30)
.append("city", "New York");
MongoInsertOneResult result = collection.insertOne(document);
System.out.println("Inserted document with id: " + result.getInsertedId());
2.2.3、updateOne()
该方法用于更新集合中的一个文档。它接受两个参数:第一个参数是查询条件,第二个参数是要更新的字段和值。例如:
Bson filter = Filters.eq("name", "John");
Bson update = Updates.set("age", 35);
UpdateResult result = collection.updateOne(filter, update);
System.out.println("Updated " + result.getModifiedCount() + " document(s).");
2.2.4、aggregate()
这个方法用于对集合中的文档进行聚合操作。它接受一个包含聚合管道阶段的列表作为参数。例如:
List<Bson> pipeline = Arrays.asList(
Aggregates.match(Filters.gte("age", 30)),
Aggregates.group("$city", Accumulators.sum("totalAge", "$age"))
);
AggregateIterable<Document> result = collection.aggregate(pipeline);
for (Document doc : result) {
System.out.println(doc.toJson());
}
2.2.5、distinct()
这个方法用于获取集合中某个字段的所有不同值。它接受一个字段名作为参数。例如:
List<String> distinctCities = collection.distinct("city", String.class).into(new ArrayList<>());
System.out.println("Distinct cities: " + distinctCities);
2.2.6、createIndex()
这个方法用于在集合上创建索引。它接受一个Bson类型的索引规范作为参数。例如:
collection.createIndex(Indexes.ascending("name"));
MongoDB Java驱动提供了许多其他有用的方法。以下是一些补充:
countDocuments():这个方法用于计算满足特定查询条件的文档数量。它接受一个Bson类型的查询条件作为参数。
findOneAndUpdate():这个方法用于查找并更新一个文档。它接受两个参数:一个是查询条件,另一个是要应用的更新操作。
bulkWrite():这个方法允许你执行批量写操作,包括插入、更新和删除。
createCollection():如果你想在数据库中创建一个新的集合,可以使用这个方法。
listCollections():这个方法会列出数据库中的所有集合。
drop():如果你想删除整个集合,可以使用这个方法。
indexInformation():这个方法返回集合的索引信息。
deleteMany():与deleteOne()类似,但这个方法可以删除多个匹配的文档。
这些方法只是MongoDB Java驱动提供的一部分功能。为了使用这些方法,你需要确保你的项目中包含了MongoDB Java驱动的依赖。在使用时,通常需要先创建一个MongoClient对象实例来访问数据库。然后,你可以使用这个客户端对象来执行各种数据库操作。
3、其他
3.1、排序
在项目中使用时,百万数据进行排序的时候遇到过因为排序数据量过大,导致mongoDB内存超出的情况。mongoDB内存一些版本在32MB,新版在100MB
org.springframework.data.mongodb.UncategorizedMongoDbException: Command failed with error 292 (QueryExceededMemoryLimitNoDiskUseAllowed): 'Error in $cursor stage :: caused by :: Sort exceeded memory limit of 104857600 bytes, but did not opt in to external sorting.' on server dev.api.benduoduo.com:27017. The full response is {"ok": 0.0, "errmsg": "Error in $cursor stage :: caused by :: Sort exceeded memory limit of 104857600 bytes, but did not opt in to external sorting.", "code": 292, "codeName": "QueryExceededMemoryLimitNoDiskUseAllowed"}; nested exception is com.mongodb.MongoCommandException: Command failed with error 292 (QueryExceededMemoryLimitNoDiskUseAllowed): 'Error in $cursor stage :: caused by :: Sort exceeded memory limit of 104857600 bytes, but did not opt in to external sorting.' on server dev.api.benduoduo.com:27017. The full response is {"ok": 0.0, "errmsg": "Error in $cursor stage :: caused by :: Sort exceeded memory limit of 104857600 bytes, but did not opt in to external sorting.", "code": 292, "codeName": "QueryExceededMemoryLimitNoDiskUseAllowed"}
at org.springframework.data.mongodb.core.MongoExceptionTranslator.translateExceptionIfPossible(MongoExceptionTranslator.java:133)
at org.springframework.data.mongodb.core.MongoTemplate.potentiallyConvertRuntimeException(MongoTemplate.java:2874)
at org.springframework.data.mongodb.core.MongoTemplate.execute(MongoTemplate.java:568)
at org.springframework.data.mongodb.core.MongoTemplate.doAggregate(MongoTemplate.java:2124)
at org.springframework.data.mongodb.core.MongoTemplate.aggregate(MongoTemplate.java:2093)
at org.springframework.data.mongodb.core.MongoTemplate.aggregate(MongoTemplate.java:1992)
 解决方案:
解决方案:
1. 添加索引
索引是提高查询效率的关键因素之一。在查询过程中添加适当的索引可以大大减少MongoDB内存的使用量。请确保索引覆盖了查询过程中使用的所有字段,以获得最佳的性能提升。
db.GBTerminalRealData.createIndex({
"time": -1}, {name: "time"})
2. 减小查询结果集
如果查询结果集过大,可能会导致内存限制错误。为了解决这个问题,可以考虑采取以下措施:
使用分页:通过使用skip和limit等方法,将查询结果进行分页处理,只返回需要的数据量。
限制结果集大小:在查询中使用projection操作符,只返回需要的字段,而不是全部字段。
int pageSize = 1000; // 每页数据量
int currentPage = 0; // 当前页数
long totalCount = collection.countDocuments(); // 总数据量
while (currentPage * pageSize < totalCount) {
List<Document> documents = collection.find()
.sort(Sorts.ascending("age"))
.skip(currentPage * pageSize)
.limit(pageSize)
.into(new ArrayList<>());
// 处理当前页的数据
for (Document document : documents) {
System.out.println(document.toJson());
}
currentPage++;
}
3. 增加服务器内存
如果数据量非常大,可以考虑增加服务器的内存,以便更好地处理大量数据。
3.2、分页
在项目中需要对百万数据进行分页操作,但是mongo自带的limit和skip的分页操作,对于百万数据查询过慢。对此针对此情况结合网上所说,就如方法下进行大数据量的分页操作。
原有方法:
//分页操作
query.skip((long) (getRequest.getPageNum() - 1) *getRequest.getPageSize()).limit(getRequest.getPageSize());
修改后:
Query query = Query.query(criteria).with(Sort.by(Sort.Direction.DESC, "_id"));
//计算总数
long count = mongoTemplate.count(query, RealTimeDataReportMongo.class, MONGO_NAME);
if (getRequest.getPageNum() != 1) {
// number参数是为了查上一页的最后一条数据
int number = (getRequest.getPageNum() - 1) * getRequest.getPageSize();
query.limit(number);
List<RealTimeDataReportMongo> realTimeDataReportMongos = mongoTemplate
.find(query, RealTimeDataReportMongo.class, MONGO_NAME);
// 获取最后一条数据
RealTimeDataReportMongo mongos = realTimeDataReportMongos.get(realTimeDataReportMongos.size() - 1);
// 取到上一页的最后一条数据id,当作条件查询接下来的数据
String id = mongos.getId();
query.addCriteria(Criteria.where("_id").lt(id));
}
// 页大小重新赋值,覆盖number参数
query.limit(getRequest.getPageSize());
List<CarStatusDataResponse> carStatusList = new ArrayList<CarStatusDataResponse>();
List<RealTimeDataReportMongo> realTimeDataReportMongos = mongoTemplate
.find(query, RealTimeDataReportMongo.class, MONGO_NAME);
总结
以上就是今天要讲的内容,本文仅仅简单介绍了mongoDB中一些方法的使用,和我在自身使用mongoDB的时候所遇到的两个问题和解决方法,当然网上对此相关的解决方法成百上千,期望各位在遇到相关情况下,可以分享一下更优的解决方法,毕竟学无止境,取长补短,共同交流,才能一起进步。















 1188
1188

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









