







 本文详细介绍了一种高效的图存储方式——链式前向星,包括其定义、构造过程及应用示例。通过实例展示了如何利用链式前向星结构避免排序操作,提高图遍历效率。
本文详细介绍了一种高效的图存储方式——链式前向星,包括其定义、构造过程及应用示例。通过实例展示了如何利用链式前向星结构避免排序操作,提高图遍历效率。
前向星
存储一个n个顶点,m条边的图。
1<=n<=1e6
1<=m<=2e6
你该如处理,用矩阵?由于顶点数据太大 不合适
用邻接表? 链表太复杂了 搞不懂
那就看看链式前向星把--
-
什么是前向星?
前向星是一种特殊的边集数组,我们把边集数组中的每一条边按照起点从小到大排序,如果起点相同就按照终点从小到大排序,并记录下以某个点为起点的所有边在数组中的起始位置和存储长度,那么前向星就构造好了.
用len[i]来记录所有以i为起点的边在数组中的存储长度.,用head[i]记录以i为顶点的边集在数组中的第一个存储位置.
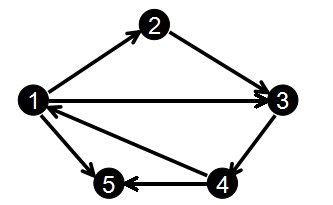
-
对于此图我们输入边的顺序为:
1 2 2 3 3 4 1 3 4 1 1 5 4 5经过排序处理,按照起点从小到大排序,如果起点相同就按照终点从小到大排序,得到的边集数组edge
-
首先我们要定义一个结构体来储存边
struct edge{ int from;//起点 int to;//终点 }edge[maxn]; -
按照规则排序后的边集数组edge
edge[0]---1 2 edge[1]---1 3 edge[2]---1 5 edge[3]---2 3 edge[4]---3 4 edge[5]---4 1 edge[6]---4 5 -
则head数组和len数组为,len[i]来记录所有以i为起点的边在数组中的存储长度,用head[i]记录以i为顶点的边集在数组中的第一个存储位置.
理解:如,以顶点4为起点的边数量有2条,(4,1)和(4,5),则len[4]=2; 以顶点4为起点的边在边集数组中第一次出现的小标位置是5,则head[4]=5;其它类推
head[1]=0; head[2]=3; head[3]=4; head[4]=5; head[5]=-1; len[1]=3; len[1]=3; len[3]=1; len[4]=2; len[5]=0;
弊端
利用前向星存储边会有排序操作,如果用快排时间至少为O(nlog(n)),因为要得到边集数组,就要排序
解决方法
如果用链式前向星,边结构体中加入next索引模拟指针指向下一条边的位置(事实上,从理解的角度来说,每条边的next,指向的是同一个顶点的边集中,刚好早于自己先出现的那一条边的边编号),就可以避免排序.
-
链式前向星
-
对比
如果说邻接表是不好写但效率好,邻接矩阵是好写但效率低的话,前向星就是一个相对中庸的数据结构。前向星固然好写,但效率并不高。而在优化为链式前向星后,效率也得到了较大的提升。
在不愿意写复杂的邻接表的情况下,链式前向星也是一个很优秀的数据结构。
-
同样链式前向星也可以定义一个结构体
struct edge{ int to;//边的终点 如(1,2)2就是这条边的终点,1就是起点 // int w; 表示边的权重 如果边有权重就加上,没有就不加 int next;//表示在前面已出现的边中与本条边同起点的边的最后出现的编号 或者 是同一个起点的边集中,刚好早于自己先出现的那一条边的边编号,简单的来看就是 同起点的上一条边的编号 }edge[maxn] edge[i].to //第i条边的终点 edge[i].next //与第i条边同起点的上一条边的边号,注意理解同起点的上一条边的边号,下面展开细说再次理解next,最难的理解的就是next,精髓也在这里
比如现在有几条边,(7,8)(7,9)(7,10)(7,11)(8,9),(8,11)依次添加到图中,编号从1开始
开始:
①添加1号边(7,8)
此时1号边的next=-1,结构体表示为edge[1].next=-1,因为在它之前顶点7没有任何边,②添加2号边(7,9)

此时2号边的next=1,结构体表示为edge[2].next=1,因为1号边刚好早于2号边先出现起点7上
③添加3号边(7,10)

此时3号边的next=2,结构体表示为edge[3].next=2,因为2号边刚好早于3号边先出现在起点7上,为什么不是1号边(注意理解刚好这个词,它是相对的)
④添加4号边(7,11)

此时4号边的next=3,结构体表示为edge[4].next=3,因为3号边刚好早于4号边先出现在起点7上
⑤在依次添加5号边(8,9),6号边(8,11)

那么5号边的next=-1(edge[5].next=-1),因为以顶点8为起点的边在5号添加之前没有; 6号边的next=5(edge[6].next=5),因为以顶点8为起点的边已经有5号边且刚好相对6号边来说是早于的
归纳一下
其实从宏观来看next是指向同起点前一条边的,将next换成front表示,我感觉更容易理解(一开始我就是这样理解的)。
通过每条边next就可以遍历出以本条边为起点的所有边,但是稍稍有不足。
比如通过4号边就可以遍历出以7为起点的所有边
4----next=3 4号边推出3号边 3----next=2 3号边推出2号边 2----next=1 2号边推出1号边 1----next=-1 1号边的next=-1,就说明以顶点7为起点的边就遍历完了,next=-1就是终止条件 你会发现这样从4寻找,就可以遍历所有以7为顶点的边,确实是这样的再来看一下从3号边开始,可以遍历出以7为起点点的所有边吗?
3----next=2 3号边推出2号边 2----next=1 2号边推出1号边 1----next=-1 1号边的next=-1,就说明以顶点7为起点的边就遍历完了 真的是遍历完了吗,我们会发现4号边也是以7为起点的边,但是并没有遍历到它; 同时我们通过3 2 1号边都无法遍历到4号边,这是因为边的next总是指向前一条边的, 当然无法通过3号直接找到4号边,而4号边却可以通过next找到3号边。 所有我们要想遍历完某起点的所有边,只能从这个起点上"最后"那条边开始遍历, 也就是最后出现起点上的那条边。 比如要想找到起点8的所有边,只能从6号边开始遍历那我们怎么找到最后出现起点上的那条边呢,
-
现在我们引出head[u]这个数组,用它来记录最后出现在起点u的那条边的边号,我们规定下head[u]初始化为-1,至于为什么,你要初始化为-2也可以,不讲究。
-
head[u]数组,在边依次输入的过程中是动态更新的,记住一点 head[u]始终记录的是当前已经输入的边中最后出现在起点u的那边的边号;而edge[i].next表示的是与第i条边同起点的上一条边的边号(当前起点最后出现的那条边),那么就可得出**edge[i].next=head[u],u是i边的起点,**随着边的输入head[i]可能就会更新
如:按照前面输入边的过程 (7,8)(7,9)(7,10)(7,11)(8,9),(8,11);我再把最后的图拿过来方便看

head[7]=-1 1号边(7,8)---edge[1].next= head[7]=-1 //head[u] u起点号,这里就是起点7即u=7;edge[j].next j是边号,这里就是1即j=1,二者是不一样的 此刻我们要做一个操作head[1]=7,更新head[1]的值, 2号边(7,9)---edge[2].next= head[7]=1 更新head[7]的值,head[7]=2 3号边(7,10)---edge[3].next= head[7]=2 更新head[7]的值,head[7]=3 4号边(7,11)---edge[4].next= head[7]=3 更新head[7]的值,head[7]=4 5号边(8,9)---edge[5].next= head[8]=-1 更新head[8]的值,head[8]=5 6号边(8,11)---edge[6].next= head[8]=1 更新head[8]的值,head[8]=6 说白了head[u]的作用就是 让我们定位到最后出现以u为起点的那条边上.是不是我们可以控制head[u]的值,就可以控制到边了,实现上也是如此,改变head[u]的值 从逻辑来说是就删除某些边的,让遍历的时候不在遍历到这些边
加边函数,这里就不考虑边的权值了
int cnt = 1 //边从1开始编号,有些题目说的从0开始,就cnt=0就行了,cnt最大值=边数+1 void add_edge(int u, int v)//加边,u起点,v终点 { edge[cnt].to = v; //第cnt边的终点 edge[cnt].next = head[u];//以u为起点最后出现的边号,也就是与这个边起点相同的上一条边的编号 head[u] = cnt++;//更新以u为起点最后出现的边号 }
再来推一次前面的过程
(7,8)(7,9)(7,10)(7,11)(8,9),(8,11) cnt=1; memset(head,-1,sizeof(head));//初始化 add_edge(7, 8) edge[1].to=8 edge[1].next=head[7]=-1 head[7]=cnt=1 cnt=cnt+1=2 add_edge(7, 9) edge[2].to=9 edge[2].next=head[7]=1 head[7]=cnt=2 cnt=cnt+1=3 add_edge(7, 10) edge[3].to=10 edge[3].next=head[7]=2 head[7]=cnt=3 cnt=cnt+1=4 add_edge(7, 11) edge[4].to=11 edge[4].next=head[7]=3 head[7]=cnt=4 cnt=cnt+1=5 add_edge(8, 9) edge[5].to=9 edge[5].next=head[8]=-1 head[8]=cnt=5 cnt=cnt+1=6 add_edge(8, 11) edge[6].to=11 edge[6].next=head[8]=5 head[8]=cnt=6 cnt=cnt+1=7我么就来通过head[u]来遍历完图的所有边
for(int u = 1; u <= n; u++)//n个起点 { cout << u << endl; //输出起点号 for(int j = head[u]; j != -1; j = edge[j].next)//遍历以i为起点的边 { cout << u << " " << edge[j].to<< endl; } cout << endl; } 这感觉就像是横向遍历,遍历完此起点的所有 在遍历下一个起点的所有边 依次类推 像不像横向遍历可不可以用纵向遍历所有的边呢,一条边走到“黑”,不难想到dfs
void dfs(u){ for(int j = head[u]; j != -1; j = edge[j].next){ dfs(edge[j].to);//从此条边的终点进入dfs } } 注意 如果图有环 就会陷入死循环 记得用数组标记边是否是使用过; 如果自环很多很多,就逻辑删除已经遍历过边 非常简单 head[u]=edge[head[u]].next, 就不会频繁判断边是否使用过,从而降低时间复杂度。保证时间复杂度是线性的如下图环很多,红色代表点,1为起点,在不改变head[1]的值的情况下,每次回到起点1,head[1]=x,都会去大量重复去判断前面已经遍历过边是否使用,然后找到一条未使用的边进行深度遍历, 这样判断会增加时间复杂度,环太多时间复杂度就会退化为 m*m

所以我们有时需要加上 head[u]=edge[head[u]].nextvoid dfs(u){ for(int j = head[u]; j != -1; j = edge[j].next){ head[u] = edge[j].next // == head[u]=edge[head[u]].next dfs(edge[j].to);//从此条边的终点进入dfs } } //优化下 void dfs(u){ while(head[u]!=-1){ head[u]=edge[head[u]].next dfs(edge[j].to);//从此条边的终点进入dfs } }完结
-

















 3295
3295

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









