






SQL教程跟学跟练
一、sql语法
练习网站:sqlzoo
地址:https://sqlzoo.net/wiki/SELECT_from_WORLD_Tutorial
sql语法结构
select–from–where–group by–having–order by–limit
运行顺序
from–where–group by–having–select–order by–limit
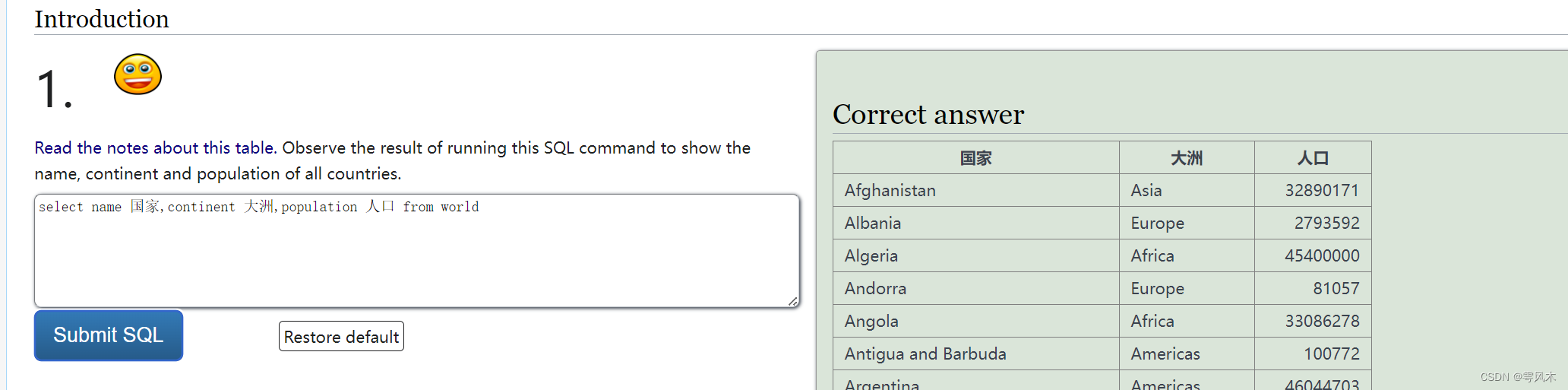
select——from
select 字段名
from 表名
查询语句必不可少
别名用as,可省略
去重
1、distinct

distinct效率较低,一般与count配合使用计算数据条数。distinct 使用中,放在 select 后边,对后面所有的字段的值统一进行去重。比如distinct后面有两个字段,那么 1,1 和 1,2 这两条记录不是重复值 。
2、group by

where——对数据进行筛选在from表名后
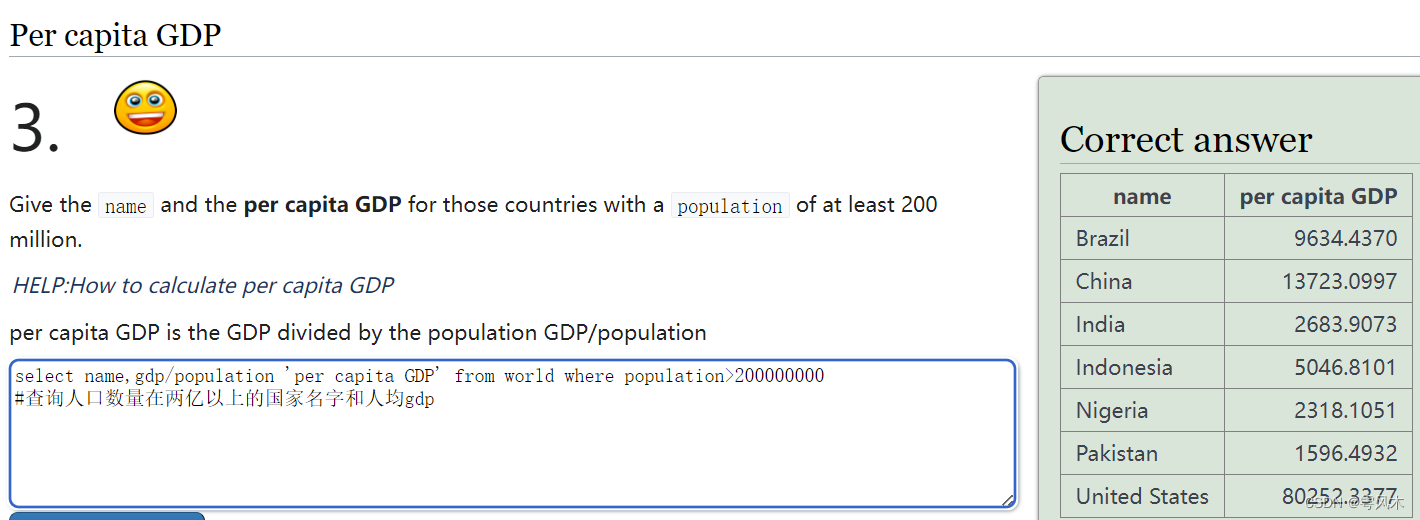
查询人口数量在两亿以上的国家名字和人均gdp
找到面积大于60万和名字中包含三个a或者人口大于13亿和面积大于30万的国家名称和面积
select
name,area
from
world
where
(area > 600000 and name like '%a%a%a%')
or
(population>1300000000 and area > 300000)
and的优先级大于or,所以上述代码中的括号(作用是标记优先级)可以去除。但为了阅读清晰,建议保留。
展示法国、意大利、德国三个国家的人口和国家名称.
select
name,population
from
world
where
name in('France','Germany','Italy')
其中in多条件的逻辑是or,between and多条件逻辑是and
order by排序
asc 升序 默认
desc 降序
ORDER BY subject in(‘physics’,‘chemistry’)
在为1不在为0,然后按照升序排序
图示为展示1984年的诺贝尔获奖者及学科,按照学科和获奖者姓名顺序排列,同时化学和物理需要放置在最后

SELECT winner, subject
FROM nobel
WHERE yr=1984
ORDER BY subject in('chemistry','physics'),subject,winner
limit[[位置偏移量],行数] 限制查询结果集显示的行数
行数必有,位置偏移量可选
limit n 返回前n行数据

select name,population
from world
order by population desc
limit 3
limit x,n 从x+1行返回n行

select name,population
from world
order by population desc
limit 3,4
#从第四行开始返回4行,也就是4,5,6,7行
group by&&聚合函数
聚合函数sum(总数),avg(平均),max(最大),min(最小),必须指定子u但进行聚合,不可使用通配符*,也会忽略空值行
count
表格行数count(*)最快的
某个字段行数count(字段名) 会忽略这个字段下的空值
group by
将group by后的字段进行去重分组
例题:查询每个大洲和大洲中人口数量超过10000000国家的数量
select
continent,count(name) num
from world
where population >= 10000000
group by continent
having 聚合后筛选
位置在group by之后,必须和group by一起使用
having表达式中可以使用聚合函数,where子句中不可以
where是对原表数据的行筛选,having是对group by分组后的数据筛选
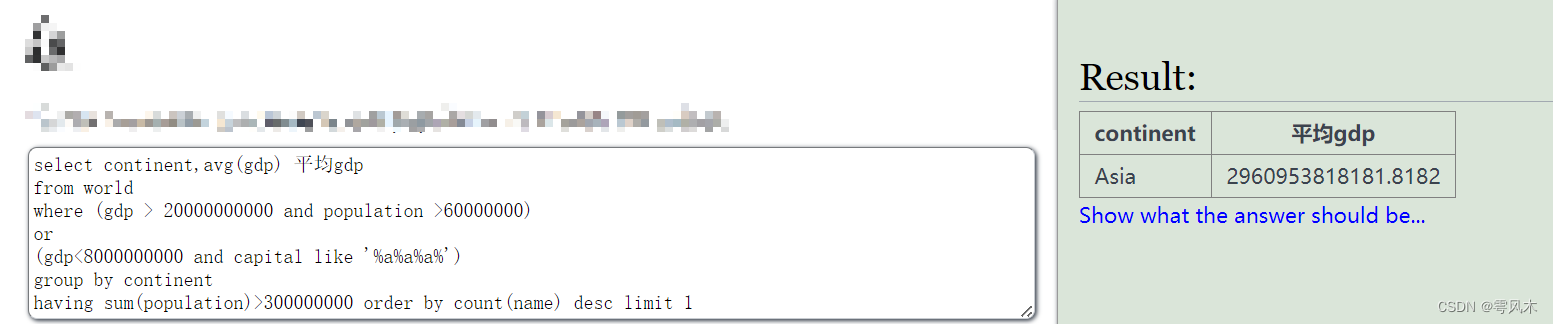
例题:
select continent,avg(gdp) 平均gdp
from world
where
(gdp > 20000000000 and population >60000000)
or
(gdp<8000000000 and capital like '%a%a%a%')
group by continent
having sum(population)>300000000
order by count(name) desc
limit 1
结果
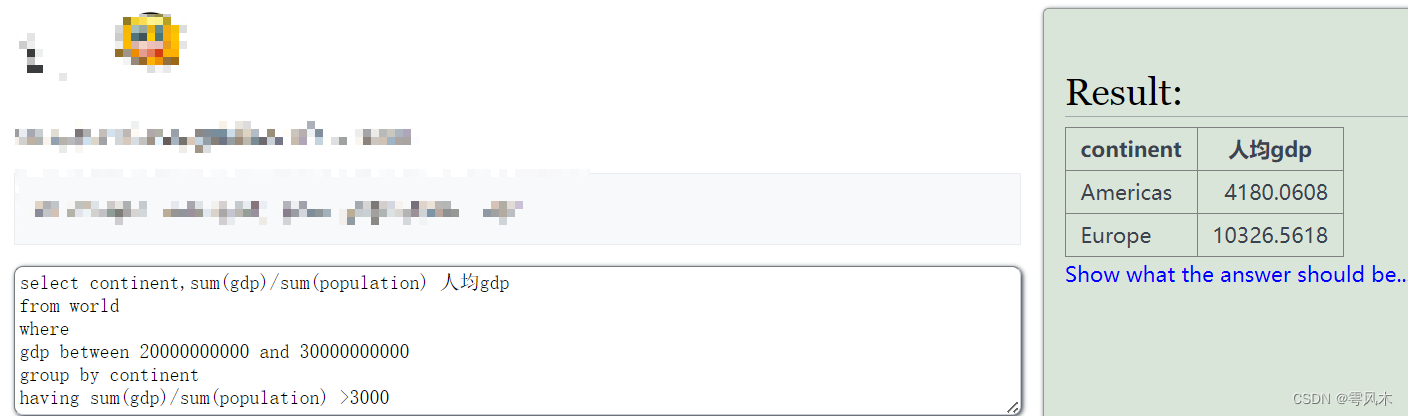
练习题

select continent,sum(gdp)/sum(population) 人均gdp
from world
where
gdp between 20000000000 and 30000000000
group by continent
having sum(gdp)/sum(population) >3000
部分常见函数
- round(x,y)四舍五入函数,对值x精确到小数点后y位
- 连接字符串函数concat(s1,s2,…)返回连接参数s1,s2…等等等产生的字符串
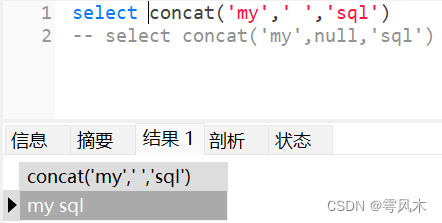

3. replace(s,s1,s2)替换函数。使用字符串s2替换s中所有的s1
4. left(s,n)&&right(s,n)&&substring(s,n,len)截取函数
left返回字符串s最左边n个字符
right返回字符串s最右边n个字符
substring返回字符串s从第n个位置开始的长度为len的字符串,n可为负数,从字符串倒数开始返回。n为0时返回为空。
5.数据类型转换函数cast(x as type)–转换数据类型的函数
6.日期时间函数
year(date)、month(date)、day(date)获取年月日的函数
date_add(date,interval exprtype)&date_sub(date,interval expr type)–对指定起始时间进行加减操作
datediff(date1,date2)–计算两个日期之间间隔的天数
date_format(date,format)—将日期和时间格式化
7.条件判断函数
if(expr,v1,v2)如果表达式expr是true返回值v1,否则返回v2
case when
case expr when v1 then r1
[when v2 then r2]...
[else rn] end
窗口函数
语法:over([partiyion by 字段名] [order by 字段名 asc|desc])
over中两个子句为可选的,partition by 为分区依据,order by为排序依据
排序窗口函数
rank()over()
dense_rank()over()
row_number()over()
窗口函数不受order by、limit影响
point
- 窗口函数只能写在select语句中
- partition by指定分区,只分区不去重。group by 去重分组
- 窗口函数中没有partition by子句的时候,即不对数据分区,直接整个表为分区
- 排序窗口函数中order by子句是必选项,窗口函数中order by 子句在分区内,依据指定字段和排序方法对数据进行排序
rank()\dense_rank()\row_number()指定排序赋值方法,排序窗口函数的区别
-
rank()
跳跃式窗口函数,如成绩为99、99、97、98,那么用rank()的排名为1、1、3、4 -
dense_rank()
并列连续型排序,如成绩为99、99、97、98,那么dense_rank()的排序结果为1、1、2、3 -
row_number()
连续型排序,如成绩为99、99、97、98,那么row_number()的排序结果为1、2、3、4
偏移分析函数
lag(字段名,偏移量,[默认值])over()
lead(字段名,偏移量,[默认值])over()
表连接
- inner join内连接 取并集
select * from A inner join B where A.id = B.id
select * from A join B where A.id = B.id
select * from A,B where A.id = B.id
例题地址
查询有球员名叫Mario进球的队伍1(team1)队伍2(team2)及球员姓名
select team1,team2,player
from game g1 join goal g2
where
g1.id = g2.matchid
and
player like '%Mario%'
查询team1的教练是“Fernando Santos”的teamname、mdate、赛事编号
select
teamname,mdate,g.id
from
eteam e
join game g
on e.id = g.team1
where
coach = 'Fernando Santos'
内连接会筛掉没有连上(连接键为null)的数据行
- 左连接left join(左表+交集)
- 右连接right join(右表+交集)
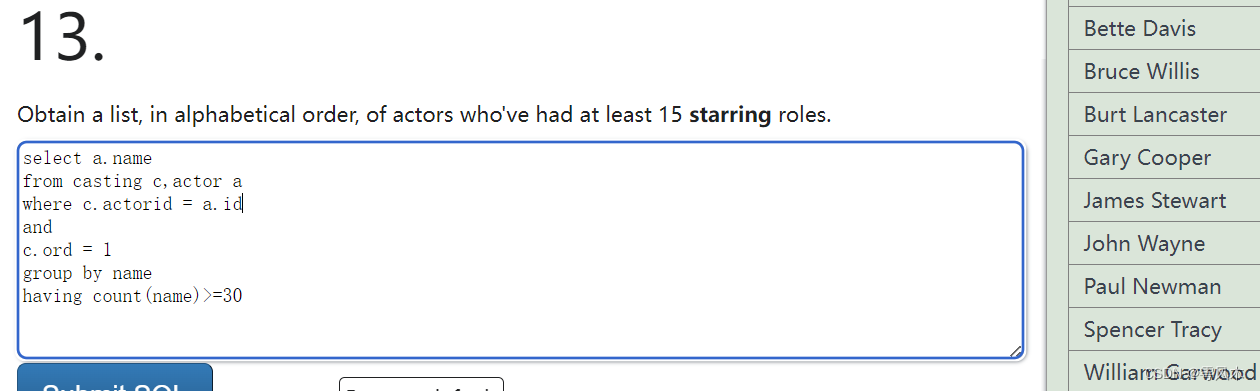
练习1
查询至少出演过第一主角30次的演员名
select a.name
from casting c,actor a
where c.actorid = a.id
and
c.ord = 1
group by name
having count(name)>=30
查询在比赛前十分钟有进球记录的球员,他的teamid,coach,进球时间(gtime,链接第五题)
select player,teamid,coach,gtime
from goal,eteam
where goal.teamid = eteam.id
and gtime<10

例题
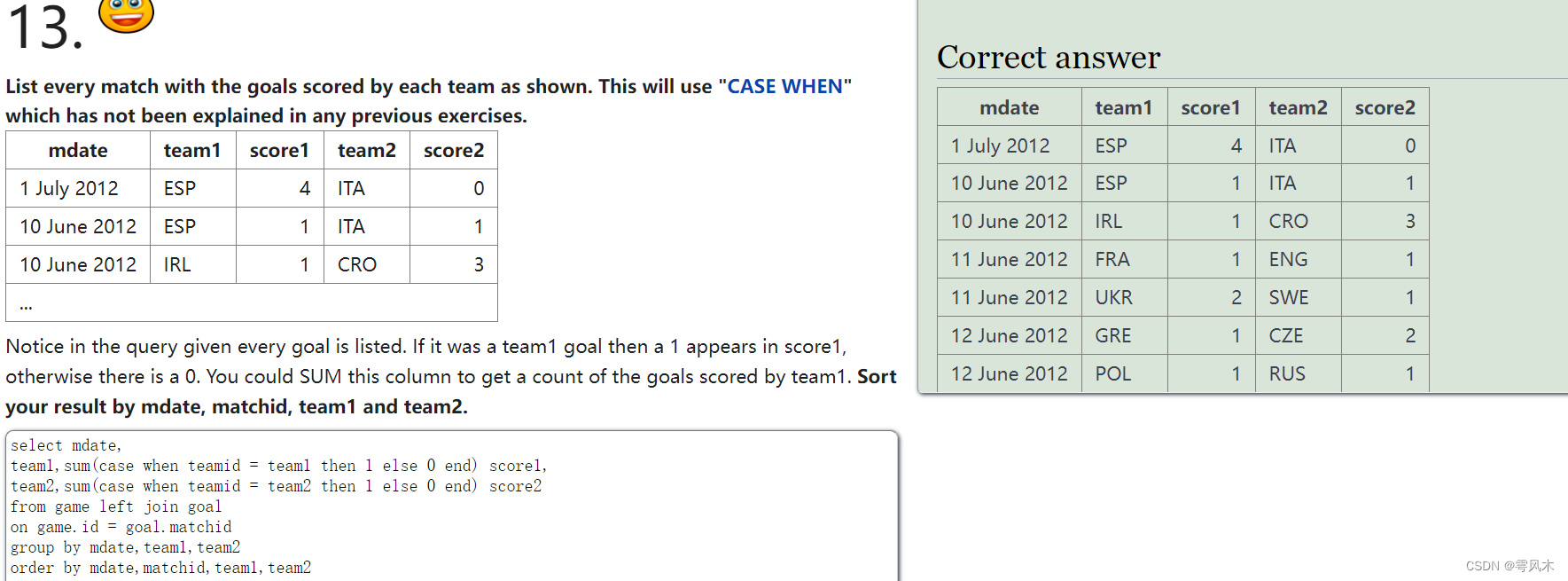
List every match with the goals scored by each team as shown. This will use “CASE WHEN” which has not been explained in any previous exercises.
mdate team1 score1 team2 score2
1 July 2012 ESP 4 ITA 0
10 June 2012 ESP 1 ITA 1
10 June 2012 IRL 1 CRO 3
…
Notice in the query given every goal is listed. If it was a team1 goal then a 1 appears in score1, otherwise there is a 0. You could SUM this column to get a count of the goals scored by team1. Sort your result by mdate, matchid, team1 and team2.
查询每场比赛每个球队的得分情况,将用到case when
select mdate,
team1,sum(case when teamid = team1 then 1 else 0 end) score1,
team2,sum(case when teamid = team2 then 1 else 0 end) score
from game left join goal
on game.id = goal.matchid
group by mdate,team1,team2
order by mdate,matchid,team1,team2
子查询
子查询本身就是一段完整的查询语句,然后用括号()包裹嵌套在主查询语句中,子查询可以多层嵌套。
最常用的子查询运用在from和where子句中。
例题
查询出gdp高于欧洲每个国家的所有国家名,有一些国家gdp值可能为null,请排除这些国家
select name
from world
where gdp is not null
and gdp > (
select max(gdp)
from world
where continent = 'Errope'
)

from基于子查询做为数据表















 382
382











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









