






B站戴师兄课程笔记
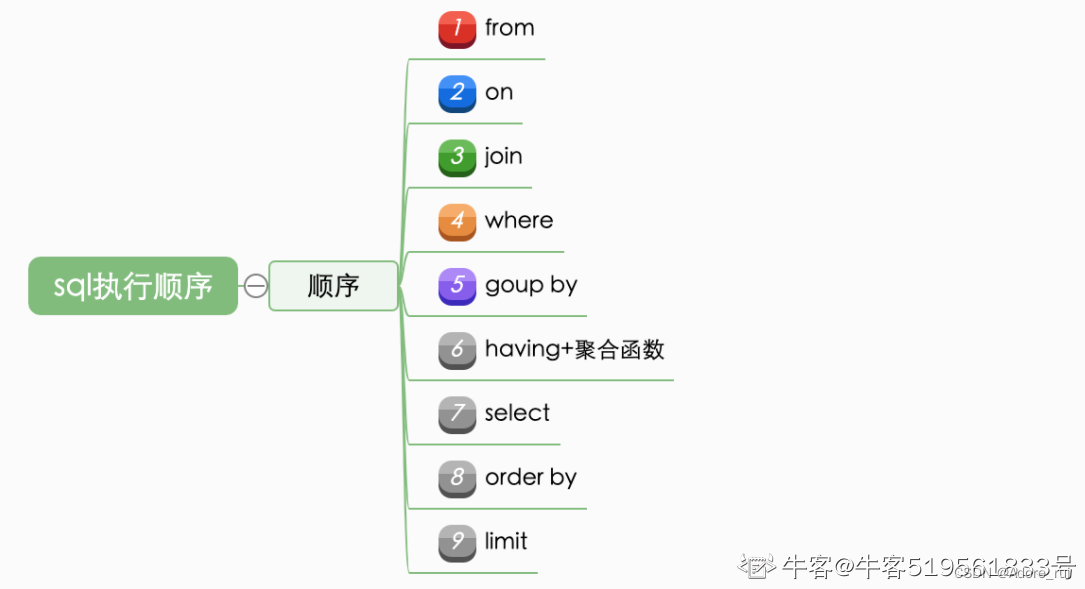
SQL查询语句语法结构和运行顺序
语法结构:select--from--where-group by--having--order by--limit
运行顺序:from--where--group by--having--order by--limit--select

- “;” 是多段代码需要添加
- * 表示选择所有列
访问在线数据库网站mysql:
选择
select 列明 别名,
from 表名称
SELECT
yr as 年,
winner 获胜者,
subject 科目
FROM nobel
去重
distinct放在select后面,可以对多个字段去重。但不能对多个字段中的一个字段单独去重。
SELECT
distinct continent
FROM world计算字段
直接敲计算公式到select后面
SELECT name,area,continent,population,gdp/population averageGDP
FROM world
WHERE
where表示筛选条件
SELECT name,gdp/population AverageGdp,population
FROM world
where population>=200000000

查询德国的人口
SELECT population
from world
where name='Germany'多条件查询:3个国家的人口——sql的两种写法
SELECT name,population
from world
where name='Germany' or name='Sweden' or name='Norway'
===============
SELECT name,population
from world
where name in ('Germany','Sweden','Norway')SELECT name,area
from world
where area between 250000 and 300000
通配符
| 通配符 | 含义 |
| % | 任意字符出现任意次数 |
| _ | 任意字符出现一次 |
C开头 ia结尾的name筛选
SELECT name,area
from world
where name like 'C%ia'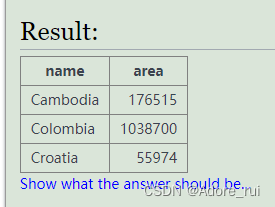
国家名称中第二个字符是t

name中间有2个o
SELECT name,area
from world
where name like '%o__o%'
1.指定几个字符时就使用几个通配符_来代替要求的字符数,没有指定字符数时使用通配符%
2.like后的字符和通配符的组合表达式需要用英文单引号(")包裹
SELECT name,area,population,area
from world
where (name like '%a%a%a%' and area>=600000)
or(population>1300000000 and area>5000000)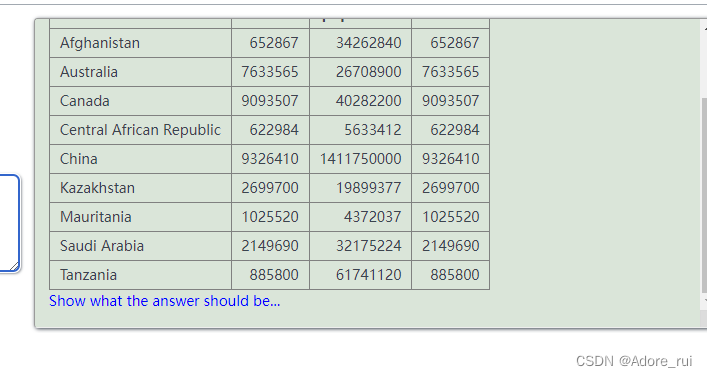
SELECT name,area,population,area
from world
where area between 25000 and 28000 and area !=27398SELECT name,continent,population/10000000
from world
where continent='South America'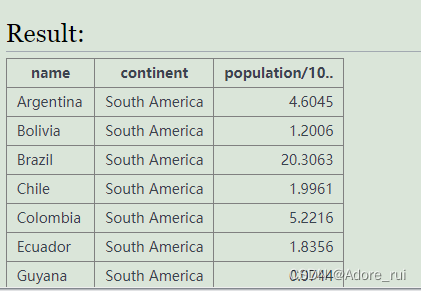
SELECT *
from nobel
where yr=1980
and subject not in('chemistry','medicine') 
查询既包含有所有元音字母(a,eio,u),同时国家名中没有空格的国家,最后显示他们的名字
SELECT *
from world
where name like'%a%'and
name like '%e%' and
name like '%i%' and
name like '%o%' and
name like '%u%' and
name not like'% %'查询1910年以前(不含1910)诺贝尔医学奖获得者和2004年及以后诺贝尔文学奖获得者的所有信息
SELECT *
from nobel
where yr<1910 and subject='medicine'
or yr>=2004 and subject='literature'ORDER BY
默认A--Z是升序,升序是asc,降序是desc
【例题17】查询姓名以Sir开头的获奖者(winner)按照年份从近到远排序,再按照姓名顺序升序排序
获奖年份(yr)和科目(subject),查询结果
SELECT *
FROM nobel
where winner like 'Sir%'
order by yr desc,winner asc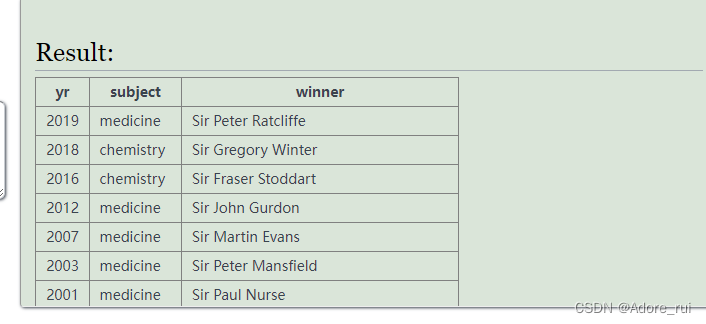
subject in(1,1,1),0,0,0 在括号里就是1,不在括号里是0,最后按照0001111排序

limit
limi他(x,n),从x+1行返回n行
limit 语句放在最后一行
SELECT *
FROM nobel
where yr=1984
order by subject in('Medicine','Chemistry'),subject,winner
limit 3,4聚合函数GROUP BY
聚合函数
 GROUP BY
GROUP BY
相当于使用了数据透视表,group by的内容是透视表的行
例题:查询每个大洲的国家数量
SELECT continent,count(name)
FROM world
group by continent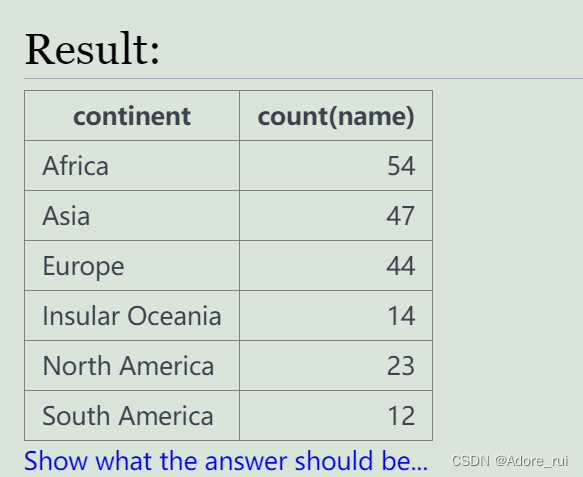
【例题25】查询2013至2015年每年每个科目的获奖人数,结果按年份从大到小,人数
从大到小排序
SELECT yr,subject,count(winner)
FROM nobel
where yr >=2013 and yr <=2015
group by yr,subject
order by yr desc,count(winner) desc
select 是最后一步运行的,所以order by yr desc,count(winner) desc这一步已经将用count的计算结果把表格的行排序确定好了,最后返回select这一步在取回value展示。
在select里面不能添加非聚合数值,因为group by 已经确定好表格的行了
select就相当于复制粘贴
练习题1:人口数量大于1000万的大洲内国家数量
select continent,
count(name)
from world
where population>10000000
group by continentHAVING
having放在group by后面
where在数据透视表创建之前进行筛选
having在数据透视表创建之后进行筛选
习题1:查询总人口数至少为3亿的大洲和其平均gdp,其中只有gdp高于200亿且人口数大于6000万或者gdp低于80亿且首都中含有三个a的国家的计入计算,最后按国家数从大到小排序,只显示第一行
select continent,
avg(gdp)
from world
where gdp >20000000000 and population>60000000 or capital like '%a%a%a%'
group by continent
having sum(population)>3000000000
order by count(name) desc
limit 1
练习题2:查询人均gdp大于3000的大洲及其人口数,仅gdp在200亿和300亿之间的国家计入计算
select continent,sum(population),sum(gdp)/sum(population)
from world
where gdp between 20000000000 and 30000000000
group by continent
having sum(gdp)/sum(population)>3000常见函数

case when 函数的应用
SELECT recovered 累计治愈人数,
case when recovered =1 then 'one' when recovered>1 then 'more' else '0'
end
FROM covid
where recovered>0
时间函数
select
whn 更新时间,
year(whn)年,
month(whn)月,
day(whn)日
from covid
where recovered >0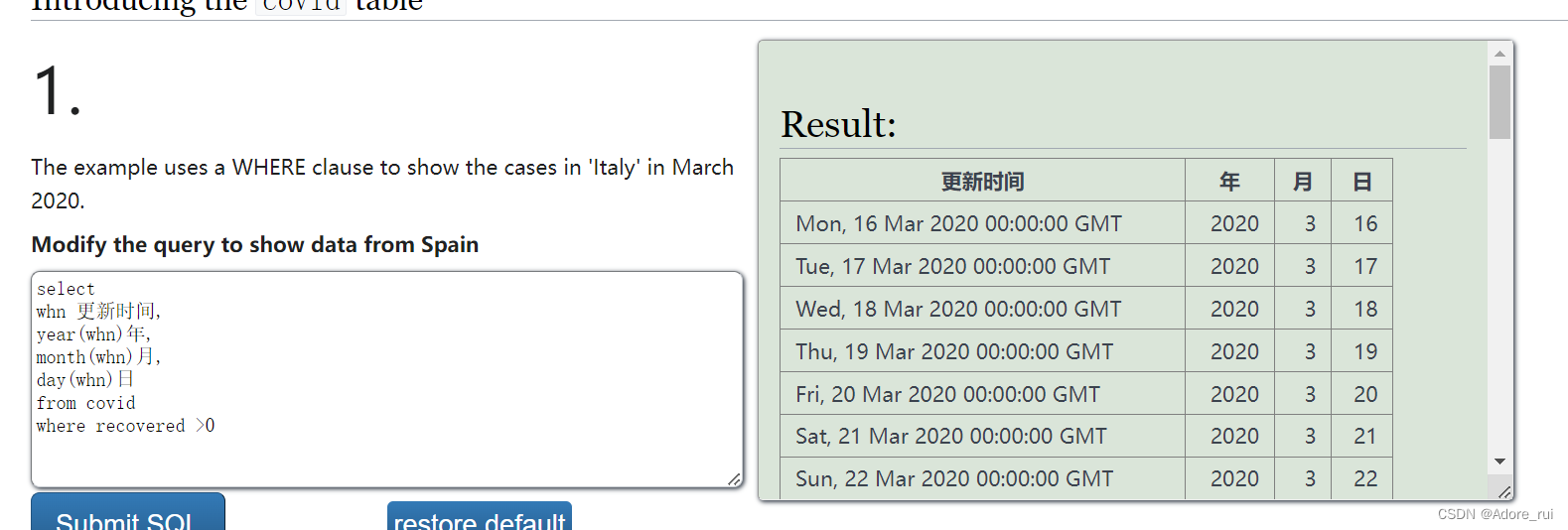
dataADD
select
whn 更新时间
,date_add(whn,interval 2 day)加2天
from covid
where recovered>0round/concat
SELECT
confirmed,
deaths,
recovered,
recovered / confirmed AS recovery_rate,
concat(ROUND((recovered / confirmed) * 100, 2),'%' )AS 治愈率
FROM
covid
WHERE
recovered / confirmed > 0.3;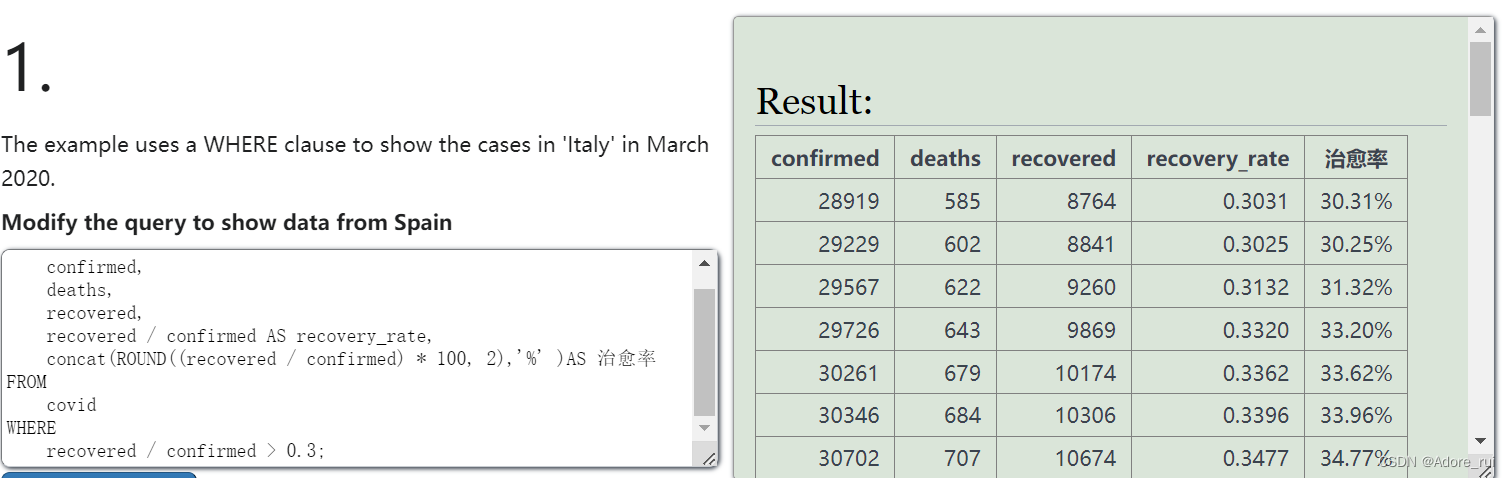
练习题1: 查询国家名称及其首都名称都以相同的字母开头的国家名及其首都,且不能包括国家名称和首都名称完全相同的情况
SELECT name,capital
FROM world
where left(name,1)=left(capital,1) and name<>capital 练习题2:查询首都和名称,其中首都需是国家名称的扩展
练习题2:查询首都和名称,其中首都需是国家名称的扩展
SELECT name,
capital
FROM world
where capital like concat('%',name,'%') and capital<>name字段的模糊查询
窗口函数
<窗口函数> over (partition by <用于分组的列名> order by <用于排序的列名>)
窗口函数over([partition by 字段名][order by 字段名 asc l desc])
1.窗口函数语法
<窗口函数> over (partition by <用于分组的列名>
order by <用于排序的列名>)<窗口函数>的位置,可以放以下两种函数:
1) 专用窗口函数,比如rank, dense_rank, row_number等
2) 聚合函数,如sum. avg, count, max, min等
2.窗口函数有以下功能:
1)同时具有分组(partition by)和排序(order by)的功能
2)不减少原表的行数,所以经常用来在每组内排名
3.注意事项
- 窗口函数原则上只能写在select子句中
- 窗口函数中的partition by 子句中可以指定数据的分区,和group by要去重的分组不同的是,partition by只分区不去重
- 窗口函数中没有partition by子句时,即不对数据分区,直接整个表为一个区
- 排序窗口函数中的order by子句时必选项,窗口函数中的order by子句在分区内,一句指定字段和排序方法对数据排序
- rank(),dense_rank(),row_number()指定排序赋值方法,对比三个排序窗口函数的异同
- rank():1,1,3,4
- dense_rank():1,1,2,3
- row_number():1,2,3,4

【例题29】查询每一年S14000021选区中所有候选人所在的团体(party)和得票数(votes),并对每一年中的所有候选人根据选票数的高低赋予名次,选票数最高则为1,第二名则为2,后续以此类推,最后根据团体(party)和年份(yr)排序
SELECT *,
rank()over (partition by yr order by votes)
FROM ge
WHERE constituency = 'S14000024'
order by party,yr
- lag :用于统计窗口内往上第n行值
- lead :用于统计窗口内往下第n行值
lag 和lead 有三个参数,第一个参数是列名,第二个参数是偏移的offset,第三个参数是 超出记录窗口时的默认值。
lag(列名,1,0) over (partition by 分组列 order by 排序列 rows between 开始位置 preceding and 结束位置 following)包括2个函数:
lag(exp_str,offset,defval) over(partion by ......order by ......)
lead(exp_str,offset,defval) over(partion by ......order by ......)
说明:
exp_str是字段名称。 offset是偏移量,即是上1个或上N个的值,假设当前行在表中排在第5
行,则offset 为3,则表示我 们所要找的数据行就是表中的第2行(即5-3=2)。offset默认值为1。
defval默认值,当两个函数取上N/下N个值,当在表中从当前行位置向前数N行已经超出了表的
范 围时,lag()函数将defval这个参数值作为函数的返回值,若没有指定默认值,则返回NULL,
那么 在数学运算中,总要给一个默认值才不会出错。
【例题30】查询法国和德国1月每天新增确诊人数,最后显示国家名、标准日期(2020-01-27)、当天截至时间累计确诊人数、昨天截至时间累计确诊人数、每天新增确诊人数,按照截至时间排序
当天截至时间累计确诊人数:cofirmed
昨天截至时间累计确诊人数:lag(confirmed,1,null)over(partion by name order by whn)
每天新增确诊人数:cofirmed-lag(confirmed,1,null)over(partion by name order by whn)
SELECT name,
DATE_FORMAT(whn,'%Y-%m-%d'),
LAG(confirmed,1) OVER(PARTITION BY name ORDER BY whn) AS prev_confirmed,
confirmed - LAG(confirmed,1) OVER(PARTITION BY name ORDER BY whn) AS new_confirmed
FROM covid
WHERE name IN ('germany', 'france') AND MONTH(whn) = 1
例题: 查询2017年选区为'S14000024'的所有候选人所在团体(party)和其选票数(votes)、还有候选人得票数在选区内对应的的排名
SELECT yr,firstName,lastName,party,
rank()over (partition by constituency order by votes desc) as rank
FROM ge
where yr=2017 and constituency='S14000024'
order by party

例题:查询截至时间为2020年4月20日的国家名,确诊人数,确诊人数排名,死亡人数,死亡人数排名,按照确诊人数降序排名
SELECT
name,confirmed,
rank()over (order by confirmed desc),
deaths,
rank()over (order by deaths desc)
FROM covid
where whn='2020-04-20'
order by confirmed desc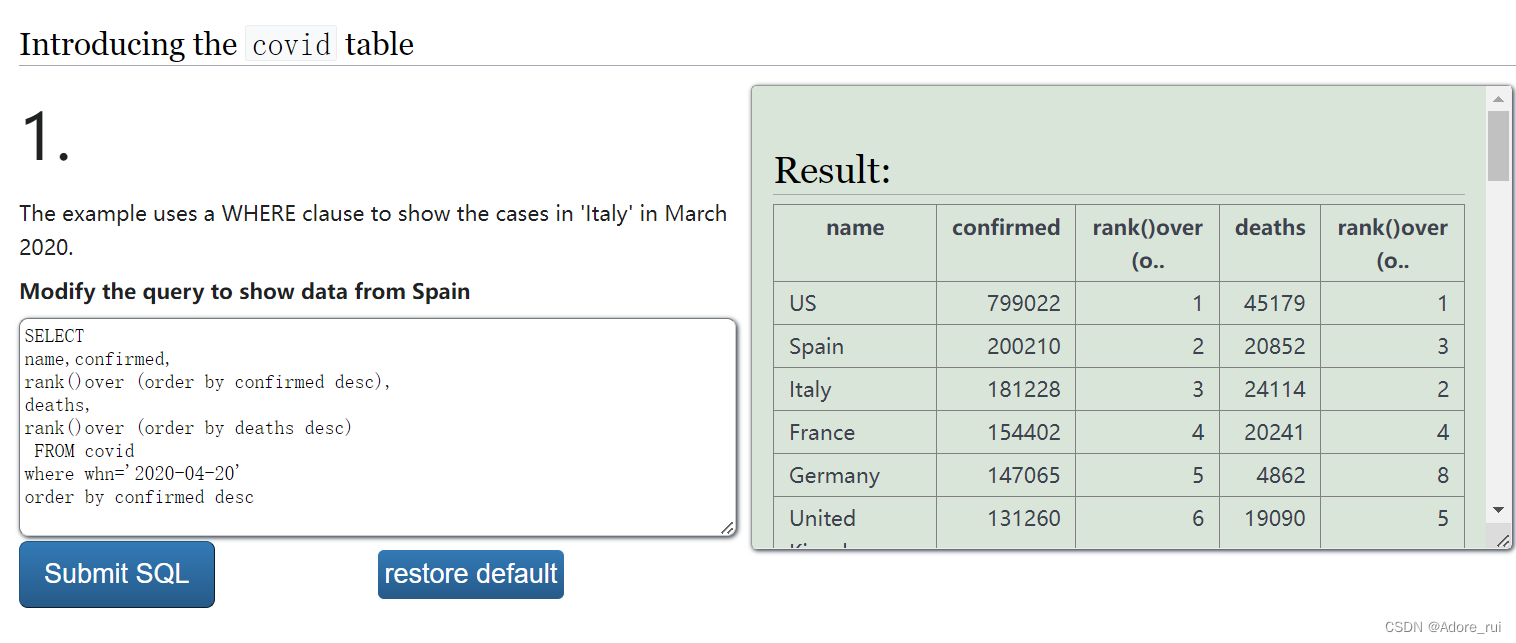
例题: 查询意大利每周新增确诊数(显示每周一的数值 weekday(whn)=0)最后显示国家名,标准日期(2020-01-27),每周新增人数按照截至时间排序
SELECT
name,
date_format(whn,'%Y-%m-%d') DATE,
(confirmed-LAG(confirmed,1) OVER(ORDER BY whn)) AS 每周新增
FROM covid
where name='Italy'
and weekday(whn)=0
ORDER BY whn表连接
-
内连接
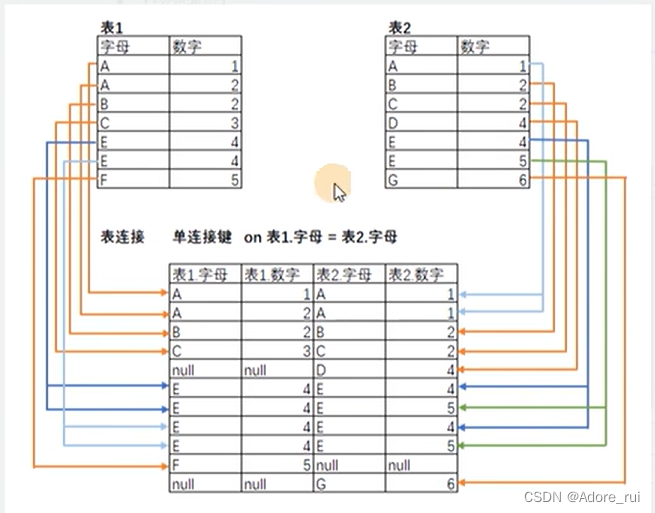
-
左连接
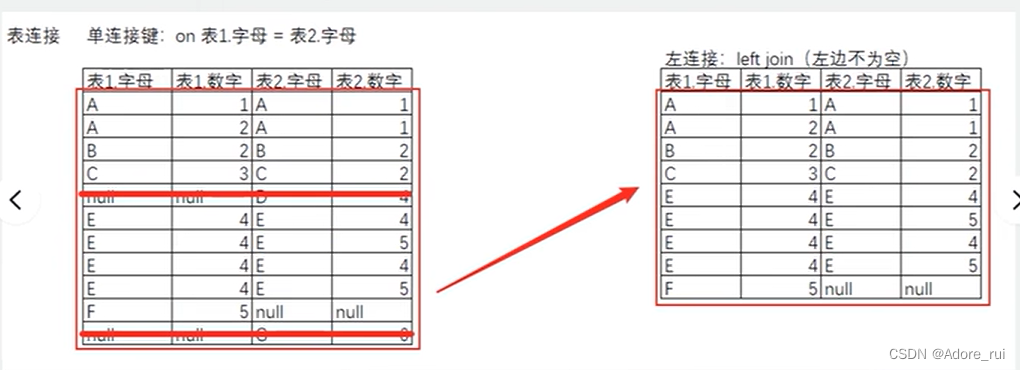
-
右连接


例题
例题31: 查询有球员名叫Mario进球的队伍1(team1),队伍2(team2)及球员姓名
SELECT team1,team2,player
FROM game
join goal on game.id=goal.matchid
where player like '%Mario%'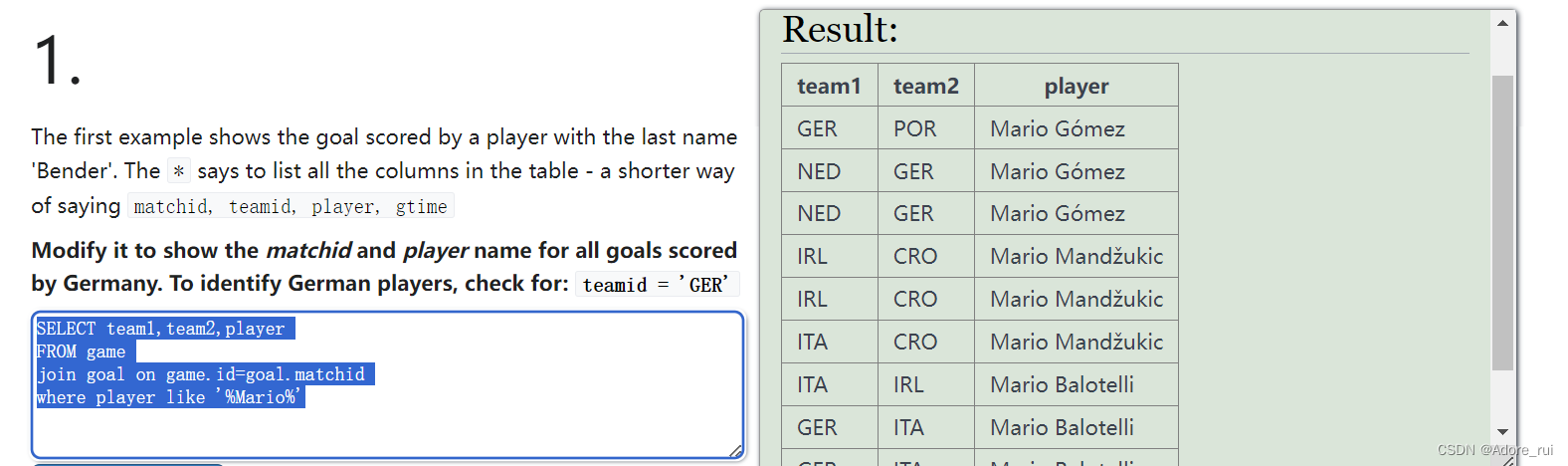
【例题32】查询队伍1(team1)的教练是"Fernando Santos”的球队名称(teamname)比赛日期(mdate)和赛事编号(id)
 报错:id列是模糊不清的
报错:id列是模糊不清的
修改:明确id的表明,game.id
SELECT game.id,teamname,mdate
FROM game join eteam on game.team1=eteam.id
where coach='Fernando Santos'
多表连接时,字段名唯一可以不指定表名,但是字段名不唯一时一定要指定表名
【例题33】使用合适的连接显示所有教师及其所教授的科目名
select
teacher.name,
dept.name
from teacher
join dept on teacher.dept=dept.id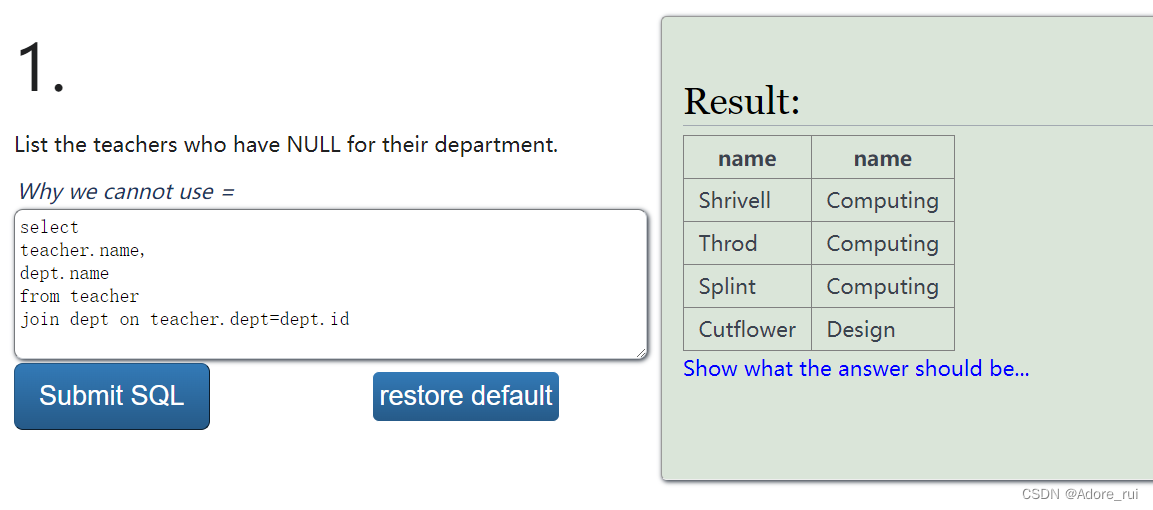
左连接
select
teacher.name,
dept.name
from teacher
left join dept on teacher.dept=dept.id
练习题1:查询至少出演过第1主角30次的演员名
SELECT actor.name,count(name) as 主演次数
FROM actor
join casting on actor.id=casting.movieid
group by actor.name
having count(name)>=30
order by count(name)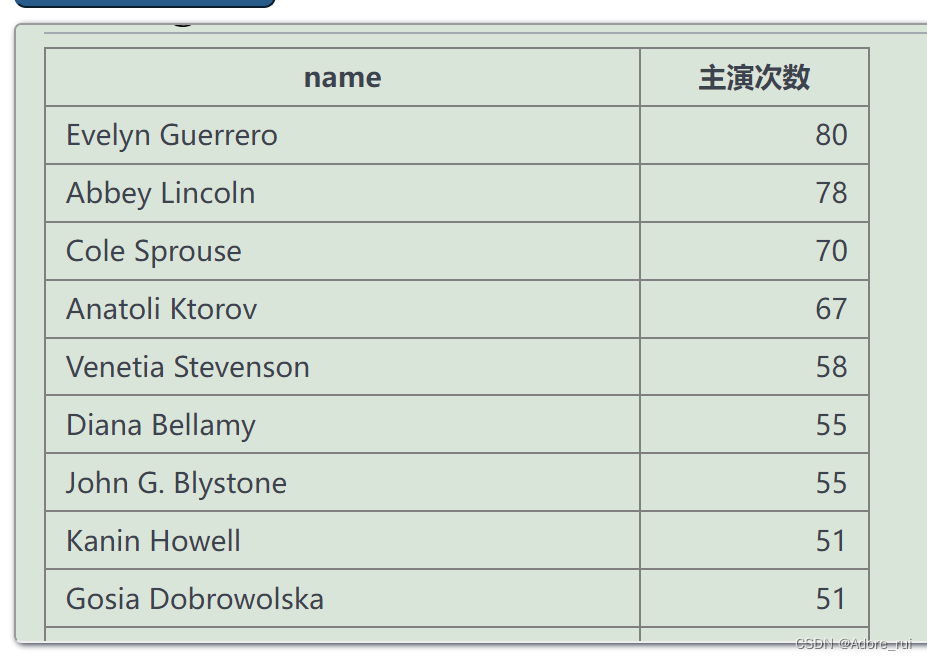
练习题2:查询在比赛前十分钟有进球记录的球员,他的队伍编号(teamid),教练(coach),进球时间(gtime)
select teamid,coach,gtime
from goal
left join eteam on goal.teamid= eteam.id
where gtime<=10
order by gtime desc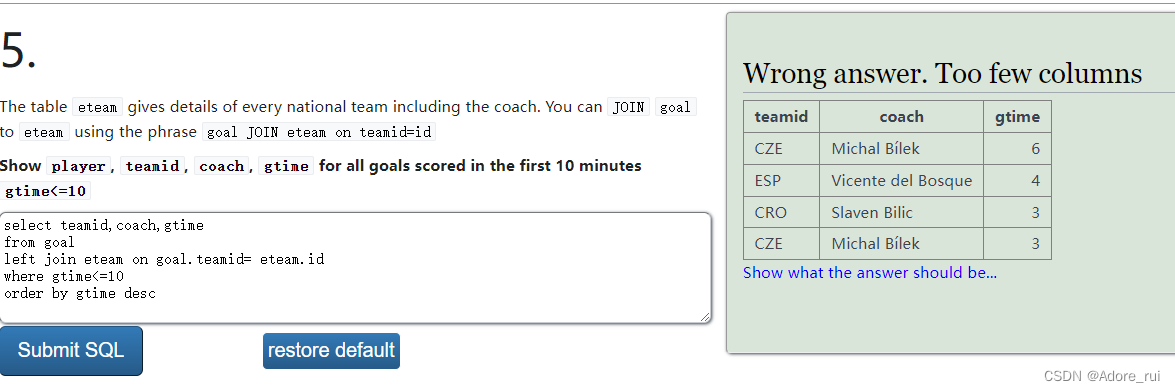
练习题3:查询每场比赛,每个球队的得分情况,按照以下格式显示。最后按照举办时间(mdate)、赛事编号(matchid)、队伍1(team1)和队伍2(team2)排序

select mdate,team1,
sum(case when team1=teamid then 1 else 0 end) score1,
team2,
sum(case when team2=teamid then 1 else 0 end) score2
from game
left join goal on game.id=goal.matchid
group by mdate,team1,team2
order by mdate,matchid,team1,team2
子查询
子查询本身就是一段完整的查询语句,然后用括号英文括号()包裹嵌套在主查询语句中,子查询可以多层嵌套
最常用的子查询运用在from和where子句中
【where基于子查询条件筛选(比较运算符&in关键字)】
【例题34】查询出gdp高于欧洲每个国家的所有国家名,有一些国家gdp值可能为NULL,请排除这些国家
SELECT name,gdp
FROM world
where gdp is not NULL
and gdp>(
select max(gdp)
FROM world
where continent='Europe')
【例题35】查询跟阿尔及尼亚(Argentina)和澳大利亚(Australia)在同一大洲的所有国家名及其所属大洲, 并按照国家名进行排序
SELECT name,continent
FROM world
where continent in(
select continent
from world
where name in('Argentina','Australia'))
order by name 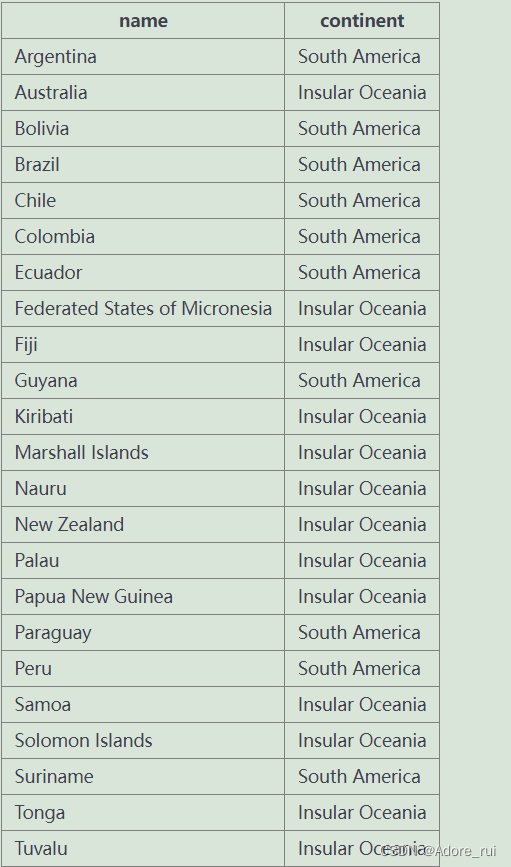
总结
1.子查询是可以自己正常独立运行的一段完整的查询语句,然后将子查询的查询结果作为主查询的一部分,因此子查询优先于主查询运行
2.例题34是带比较运算符的子查询,要求子查询为标量子查询,即子查询结果为一行一列(相当于一个单元格)
3.例题35是带in关键字的子查询,要求子查询为列子查询,即子查询结果为多行一列(单列)
4.where子句中的子查询适用于查询条件无法一步到位,需要先进行一步查询得到结果,基于这个查询结果再进行条件判断的情况,相当于我们无法直达时需要进行换乘
【from基于子查询作为数据表)
【例题36】查询2017年所有在爱丁堡的选区当选议员所在选区(constituency)及其团队(party),已知爱丁堡选区编号为S14000021至S14000026,当选议员即各选区得票数最高的候选人
SELECT constituency,party,votes,
rank()over (partition by constituency order by votes desc) as rank
from ge
where constituency in('S14000021','S14000026')and yr=2017 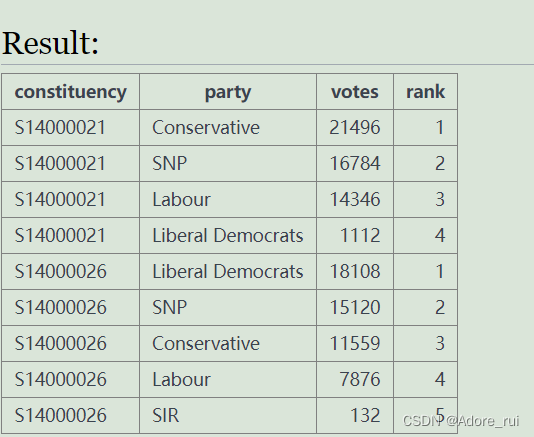
SELECT constituency,party
FROM (SELECT constituency,party,votes,
rank()over (partition by constituency order by votes desc) as rank
from ge
where constituency in('S14000021','S14000026')and yr=2017 ) as subtable
where subtable.rank=1 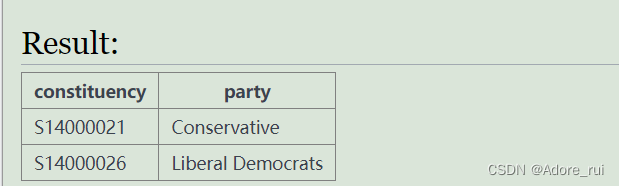
总结
- 子查询本身是一个完整的查询,由括号包裹嵌套在主查询中
- 子查询最后返回查询出的结果给主查询
- 子查询可以在select,from,where,having子句(同where)中使用,但要注意不同子句能接受的子查询种类有差别
- from的子查询必须有别名
- 子查询可以多重嵌套(子查询可以作为主查询再嵌套子查询)
练习题
练习题1:查询在欧洲(Europe)人均gdp大于英国(United Kingdom)的国家名人均国内生产总值(人均GDP)=国内生产总值(GDP)/人口(populaiton)
select name,continent,gdp/population as averageGDP
FROM world
where continent='Europe'
and gdp/population>(SELECT gdp/population
FROM world
where name ='United Kingdom')
练习题2:查询人口数(population)超过加拿大(Canada)但是少于波兰(Poland)的国家,结果显示这些国家名(name)和人口数(population)
select name,population
from world
where population >(SELECT population
FROM world
where name='Poland')and
population <(SELECT population
FROM world
where name ='Canada')
练习题3: 查询所有国家人口均≤25000000的大洲,及其国家名(name)和人口(population)
select name,population,continent
from world
where continent not in(
select distinct continent
from world
where population>25000000
)练习题4:查找每个大陆(continent)中最大的国家(按区域area),显示该大洲国家名(name),(area)(continent),
select name,population,continent
from world
where (continent,area) in (
select continent,max(area)
from world
group by continent
)select name,population,continent
from (select name,population,continent,
rank()over(partition by continent order by area desc) as areaRank
from world) as tempt
WHERE areaRank = 1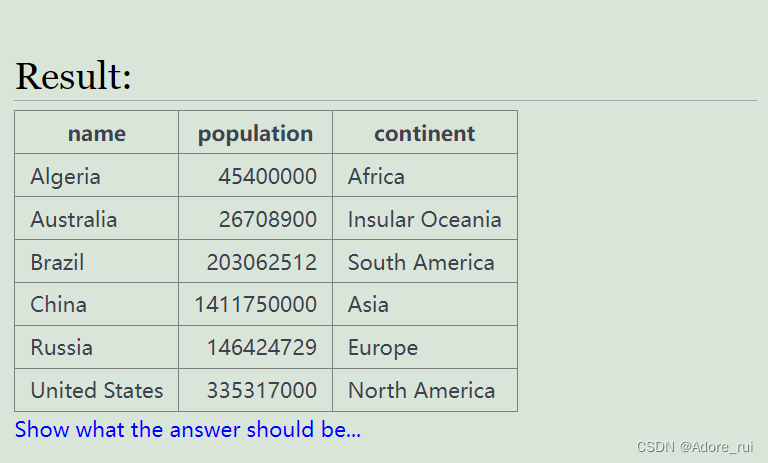
练习题5: 查询德国和意大利每天新增治愈人数并从高到低排名,查询结果按国家名,截至日期(输出格式为'xxxx年xx月xx日'),新增治愈人数,按排名排序
SELECT name,formatted_date,DAY_confirmed,
rank()over(partition by name order by DAY_confirmed desc) as rank
from(SELECT name,
DATE_FORMAT(whn,'%Y年%m月%d日') AS formatted_date,
(confirmed - LAG(confirmed) OVER (PARTITION BY name ORDER BY whn)) AS DAY_confirmed
FROM covid
WHERE name IN ('Germany', 'Italy')) as temp
order by rank















 4753
4753











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









