





一、HashMap、HashTable、ConcurrentHashMap的区别: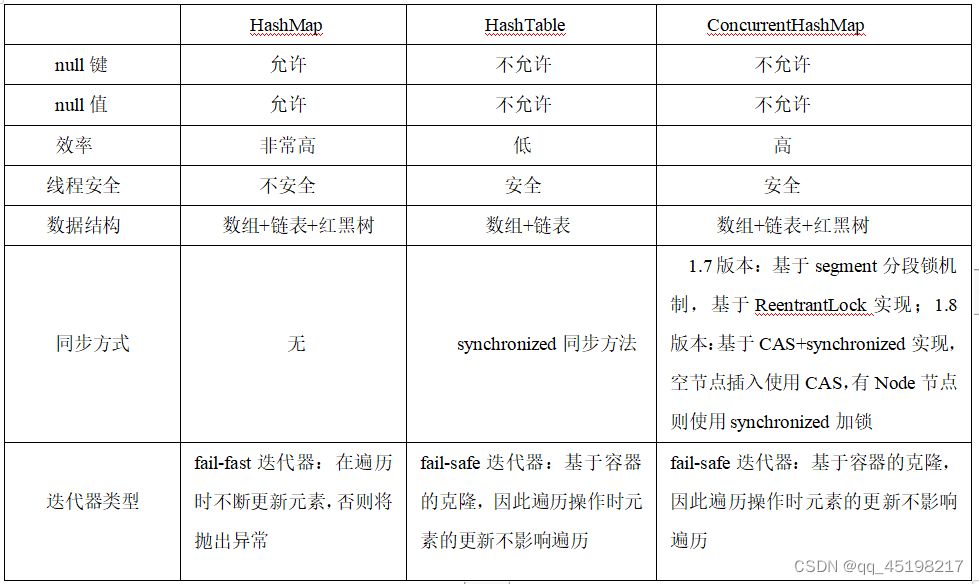 HashMap实现原理:
HashMap实现原理:
1.HashMap实现了Map接口,HashMap的默认初始容量是16,最大容量为2的30次方;
2.HashMap桶中放置的节点是一个单链表的结构:Entry单向链表,当准备添加一个key-value对时,首先使用key借助hash函数计算key的哈希地址,再将key-value键值对,结合计算出的hash地址插入到哈希桶中。
3.HashMap是基于哈希表实现的,存储的数据是key-value键值对,实现了Serializable接口,Cloneable接口,所以它也支持序列化,能被克隆。
HashTable实现原理:
1.HashTable同样是基于哈希表实现,存储的数据同样为key-value键值对,其内部也是通过单链表解决哈希冲突的,容量不足时,同样会自动扩容;
2.线程安全,可以用于多线程场景。它的线程安全实现方式是:所有的方法都使用synchronized加锁,像一些读操作不存在线程不安全问题,所以全部方法加锁导致了效率低下。
3.现在已经被丢了不再使用了。不涉及线程安全问题时使用HashMap,要保证线程安全时,使用ConcurrentHashMap。
ConcurrentHashMap实现原理:
(1)1.7版本:
1.底层数据结构还是数组+链表。HashEntry为链表的节点。
2.采用了segment分段锁技术,在多线程并发更新操作时,对同一个segment进行同步加锁,保证数据安全,这样就可以基于不同的segment进行并发写操作。
3.继承ReentrantLock实现同步锁机制。
4.和HashMap一样,都存在哈希冲突,链表查询效率低的问题。
(2)1.8版本:
1.底层数据结构和HashMap 1.8版本一样,都是数组+链表+红黑树;
2.支持多线程并发操作,实现原理:CAS+synchronized保证并发更新;
3.put方法放元素的时候:通过key对象的hashcode计算出数组的索引,如果没有Node,则使用CAS尝试插入元素,失败则无条件自旋,直到插入成功为止,如果存在Node,则使用synchronized锁住该Node元素(链表/红黑树的头节点),再执行插入操作。
【注】1.7和1.8版本共同有的特征:
1.读操作没有加锁,value是volatile修饰的,保证了可见性,所以是安全的;
2.读写分离可以提高效率:多线程对不同的Node/Segment的插入/删除是可以并发、并行执行的,对同一个Node/Segment的写操作是互斥的。读操作是无锁状态,可以并发、并行执行。
【无标题】
最新推荐文章于 2024-07-22 19:36:52 发布
















 1111
1111











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









