






一、HTTP协议
HTTP协议是前后端的一个桥梁,想要完成一个网站光写完前端页面还不行,还得需要后端的加持,客户端和服务器之间,是基于网络来进行通信的,而他们两个通信就需要通过HTTP 协议来连接
HTTP (全称为 “超文本传输协议”) 是一种应用非常广泛的应用层协议。
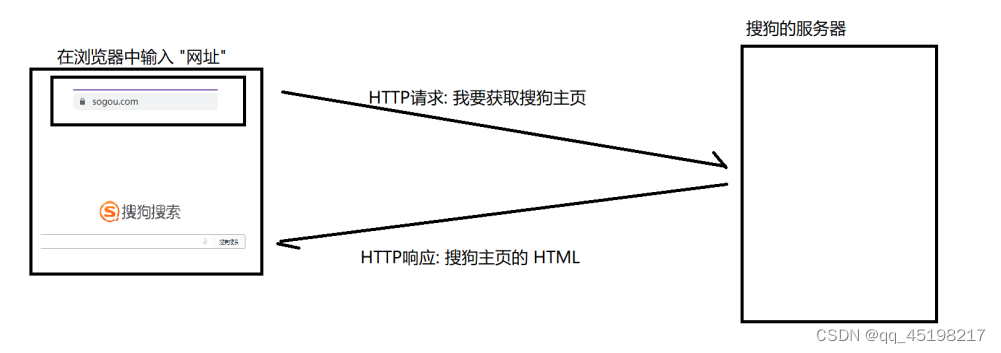
客户端:主动发起网络请求的一端;
服务器:被动接受网络请求的一端;
请求:客户端给服务器发的数据;
响应:服务器给客户端返回的数据;
二、HTTP请求
1.认识URL
(1)URL基本格式
我们再浏览器中地址栏,就是输入的URL,就是平常说的网址。URL是统一资源定位符,互联网上面每个文件都有一个唯一的URL,URL也表示文件的位置以及浏览器改怎么处理。
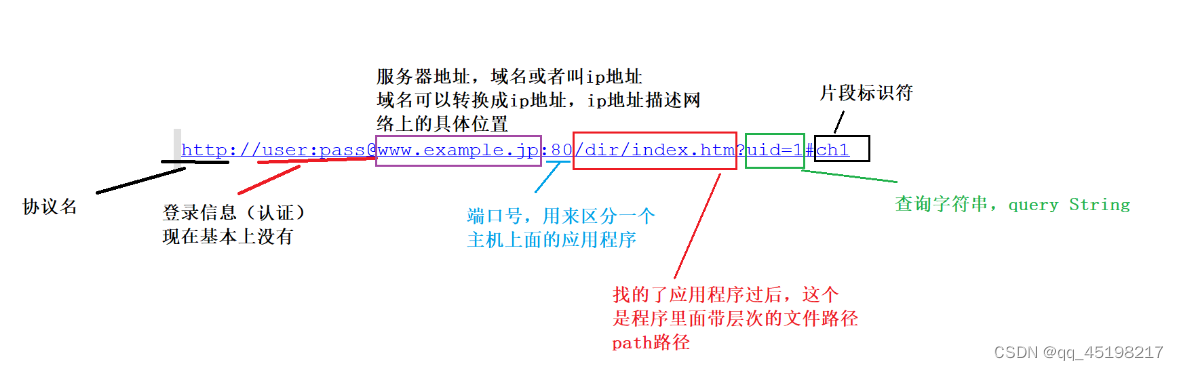
https :协议方案名。 常见的有 http 和 https, 也有其他的类型(例如访问 mysql 时用的jdbc:mysql )
user:pass :登陆信息。 现在的网站进行身份认证一般不通过 URL 进行了. 一般都会省略
www.example.jp: 服务器地址. 此处是一个 "域名", 域名会通过 DNS 解析成一个具体的 IP 地址.
80:端口号 当端口号省略的时候, 浏览器会根据协议类型自动决定使用哪个端口. 例如 http
协议默认使用 80 端口, https 协议默认使用 443 端口.
/dir/index.html: 带层次的文件路径.
uid=1: 查询字符串(query string). 一般从问号开始就是查询字符串query String,query String是客服端给服务器的参数,这个参数是一个键值对的结构, 以 & 作为键值对分隔符,以 = 作为键和值之间的分隔符;
ch1:片段标识
(2)URL encode
对于:、?/.…或者中文符号这些符号在URL中都当做特殊的意义理解,不只是单纯的?、/,或者中文符号 ,此时我们就要进行url encode 转义,这里的转义是直接取当前字符/字符串的内存的十六进制表示形式,然后在每个字节的前面加上%。
2.认识方法(method)
(1)GET方法
GET 是最常用的 HTTP 方法,常用于获取服务器上的某个资源。在浏览器中直接输入 URL, 此时浏览器就会发送出一个 GET 请求;另外, HTML 中的 link, img, script 等标签, 也会触发 GET 请求;使用 JavaScript 中的 ajax 也能构造 GET 请求。
GET https://www.sogou.com/ HTTP/1.1
Host: www.sogou.com
Connection: keep-alive
Cache-Control: max-age=0
sec-ch-ua: " Not;A Brand";v="99", "Google Chrome";v="91", "Chromium";v="91"
sec-ch-ua-mobile: ?0
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML,
like Gecko) Chrome/91.0.4472.77 Safari/537.36
Accept:text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,imag
e/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9
Sec-Fetch-Site: none
Sec-Fetch-Mode: navigate
Sec-Fetch-User: ?1
Sec-Fetch-Dest: document
Accept-Encoding: gzip, deflate, br
Accept-Language: zh-CN,zh;q=0.9,en;q=0.8
Cookie: SUID=19AA8B7B6E1CA00A000000005F9A2F76; SUV=1603940214073598;
GET请求的特点:
①首行的第一部分为 GET;
②URL 的 query string 可以为空, 也可以不为空;
③header 部分有若干个键值对结构;
④body 部分为空。
【注】:关于 GET 请求的 URL 长度问题,网上有些资料上描述: get请求长度最多1024kb 这样的说法是错误的. HTTP 协议由 RFC 2616 标准定义, 其中没有对 URL 的长度有任何的限制. 实际 URL 的长度取决于浏览器的实现和 HTTP 服务器端的实现. 在浏览器端, 不同的浏览器最大长度是不同的, 但是现代浏览器支持的长度一般都很长; 在服务器端, 一般这个长度是可以配置的.。(2)POST 方法
POST 方法也是一种常见的方法. 多用于提交用户输入的数据给服务器(例如登陆页面)。通过 HTML 中的 form 标签可以构造 POST 请求; 或者使用 JavaScript 的 ajax 也可以构造 POST 请求。
POST https://v.bitedu.vip/tms/login HTTP/1.1
Host: v.bitedu.vip
Connection: keep-alive
Content-Length: 105
sec-ch-ua: " Not;A Brand";v="99", "Google Chrome";v="91", "Chromium";v="91"
sec-ch-ua-mobile: ?0
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML,
like Gecko) Chrome/91.0.4472.77 Safari/537.36
Access-Control-Allow-Methods: PUT,POST,GET,DELETE,OPTIONS
Content-Type: application/json;charset=UTF-8
Access-Control-Allow-Origin: *
Accept: application/json, text/plain, */*
Access-Control-Allow-Headers: Content-Type, Content-Length, Authorization,
Accept, X-Requested-With , yourHeaderFeild
Origin: https://v.bitedu.vip
Sec-Fetch-Site: same-origin
Sec-Fetch-Mode: cors
Sec-Fetch-Dest: empty
Referer: https://v.bitedu.vip/login
Accept-Encoding: gzip, deflate, br
Accept-Language: zh-CN,zh;q=0.9,en;q=0.8
Cookie: username=123456789; rememberMe=true
{"username":"123456789","password":"xxxx","code":"jw7l","uuid":"d110a05ccde64b16
a861fa2bddfdcd15"}
POST 请求的特点:
①首行的第一部分为 POST
②URL 的 query string 一般为空 (也可以不为空)
③header 部分有若干个键值对结构.
④body 部分一般不为空. body 内的数据格式通过 header 中的 Content-Type 指定, body 的长度由header 中的 Content-Length 指定。
(3)经典面试题 GET 和 POST 的区别
答:GET 和 POST 是没有本质区别的,只是使用习惯上的区别。
①GET 习惯上,把客户端的数据通过query String来传输(body部分是空),POST 习惯上,把客户端的数据通过body来传输(query String是空的)②语义区别,GET 习惯上,用于从服务器获取数据;POST习惯上,是客户端给服务器提交数据。③一般情况下,程序员会把 GET 请求的处理,设计成“幂等”(“幂等"是指请求被重复的发送不会产生影响),POST 请求的处理,不要求实现“幂等”。④GET 可以被缓存, POST 不能被缓存. (这一点也是承接幂等性).
【注】:①POST 比 GET 更安全 :依据是如果使用GET请求进行登录,此时username和password通过query String来传递,就会出现在浏览器地址栏种,是不安全的;但是 POST就会把username和password放到body中,会比 GET 更安全。这种说法是错误的,POST已抓包也能抓到username和password,故安不安全取决于加密算法的强度;②传输的数据量:POST 传输的数据量比 GET 更多,原因 GET 的URL有上限 ,但RFC 标准明确说明,不对URL进行长度限制;③GET 只能传输文本数据: POST可以传输 文本和二进制数据,GET完全可以传输文本和二进制数据,GET 的 query string 虽然无法直接传输二进制数据, 但是可以针对二进制数据进行 url encode。
3.认识请求"报头”(header)
(1)Host:表示该请求对应的服务器地址,地址里面可以是ip可以是域名,也可以手动指定端口号。但是域名是可以在URL中显示的,有时候URL中显示的域名和Host的域名不太一样,这是因为网站存在一种程序叫做“代理”,“代理”需要翻外网,翻外网的域名就和Host 里面的域名就不一样了。
(2) Content-Length:表示的是 body 的长度,长度的单位是字节
(3) Content-Type:表示的是 body 的格式。如果请求有body(POST),此时就会在header中带上Content-Length和Content-Type这两个参数。
Content-Type 中的常见取值:
1|application/x-www-form-urlencoded:
此时body就会使用类似于query String的格式进行组织
1|multipart/form-data
使用HTML上传文件的时候的格式。
1|application/json
数据为 json 格式. body 格式形如:
{"username":"123456789","password":"xxxx","code":"jw7l","uuid":"d110a05ccde64b16
a861fa2bddfdcd15"}
(4) User-Agent(简称 UA)表示浏览器操作系统的属性,形如:
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.74 Safari/537.36 Edg/99.0.1150.55
其中 Windows NT 10.0; Win64; x64 表示操作系统信息;AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.77 Safari/537.36 表示浏览器信
息 表示浏览器信息.
(5) Referer:这个是表示页面是从哪里跳转来的。形如:
https://v.bitedu.vip/login
如果直接在浏览器中输入URL, 或者直接通过收藏夹访问页面时是没有Referer 的.
(6) Cookie : 本质上是浏览器给网页提供的本地存储数据的机制。
①Cookie是什么?
答:Cookie是浏览器提供的一种让程序员在本地存储数据的能力。
②Cookie里面存的是啥?
答:Cookie里面存的是键值对的格式数据,键值对用“;”分割,键和值之间用“=”分割。
③Cookie从哪里来?程序员如何在Cookie里面存东西?
答:在浏览器中的URL位置左边用一个锁,点击这个锁就可以看到浏览器中的Cookie,每个Cookie还不一样,百度有一组百度的Cookie,搜狗有一组搜狗的Cookie…;浏览器里面存的Cookie都是从服务器的响应“报头”里面的 set-cookie 字段中来的,每个 set-cookie 字段里面都包含一个Cookie 这样的键值对,浏览器拿到响应之后就会把 set-cookie中的内容保存到本地,而 set-cookie 就是程序员自己在服务器中构造填写的。
④Cookie要到哪里去?
答:同一时刻客户端有很多,客户端这边会通过Cookie来保存当前用户使用的中间状态,当客户端访问浏览器时,就会自动把Cookie的内容带到入请求中,服务器就能知道客户端是什么样子了。
三、HTTP响应
1.认识状态码
属于HTTP的响应内容,表示这次的请求结果是如何的,是访问成功, 还是失败, 还是其他的一些情况…
五大类别:
1、1XX Hold on 等会继续
2、2XX Here you are 成功访问
3、3XX Go away 重定向
4、4XX You fucked up 服务器崩了
5、5XX I fucked up 客服端的问题
(1)200 OK
HTTP/1.1 200 OK
这是一个最常见的状态码, 表示访问成功
(2)404
404 Not Found
客服端尝试请求的资源,在服务器上不存在
(3)403
403 Forbidden
表示访问被拒绝. 有的页面通常需要用户具有一定的权限才能访问(登陆后才能访问). 如果用户没有登陆直接访问, 就容易见到 403
(4)405
405 Method Not Allowed
当前http方法,服务器不支持
(5)500
500 Internal Server Error
服务器代码出现了崩溃/异常
(6)504
504 Gateway Timeout
当服务器负载比较大的时候, 服务器处理单条请求的时候消耗的时间就会很长, 就可能会导致出现超时的情况
(7)302
302 Move temporarily
重定向
2.认识响应 “报头” (header)
响应报头的基本格式和请求报头的格式基本一致,类似于 Content-Type , Content-Length 等属性的含义也和请求中的含义一致。
响应中的 Content-Type 常见取值有以下几种:
text/html : body 数据格式是 HTML
text/css : body 数据格式是 CSS
application/javascript : body 数据格式是 JavaScript
application/json : body 数据格式是 JSON
3.认识响应 “正文” (body)
正文的具体格式取决于 Content-Type。
四、HTTP请求的构造
1.通过 form 表单构造 HTTP 请求
form (表单) 是 HTML 中的一个常用标签. 可以用于给服务器发送 GET 或者 POST 请求.
form 的重要参数:
①action: 构造的 HTTP 请求的URL 是什么.
②method: 构造的 HTTP 请求的方法 是 GET 还是 POST (form 只支持 GET 和 POST).
input 的重要参数
①type: 表示输入框的类型. text 表示文本, password 表示密码, submit 表示提交按钮.
②name: 表示构造出的 HTTP 请求的 query string 的 key. query string 的 value 就是输入框的用户输入的内容.
③value: input 标签的值. 对于 type 为 submit 类型来说, value 就对应了按钮上显示的文本.
<body>
<!--表单标签,允许用户和服务器之间交互数据,用户把这个请求提交给搜狗服务器-->
<!--要求提交的数据以键值对的形式来组织-->
<form action="https://www.sogou.com" method="post">
<input type="text" name="studentName">
<!--input type=submit 构造了一个特殊的提交按钮,value属性描述了按钮中的文本-->
<!--点击这个按钮就会触发form表单的"提交操作",也就是构造http请求发送给服务器-->
<input type="submit" value="提交">
</form>
</body>

2.通过 ajax 构造 HTTP 请求
从前端角度, 除了浏览器地址栏能构造 GET 请求, form 表单能构造 GET 和 POST 之外, 还可以通过 ajax 的方式来构造 HTTP 请求. 并且功能更强大.
.
a
j
a
x
(
)
:
j
q
u
e
r
y
中,
.ajax(): jquery中,
.ajax():jquery中,是一个特殊的全局对象, jquery的api是以$的方法的形式引出来的,只有一个参数,是一个js对象。 在 JavaScript 中可以通过 ajax 的方式构造 HTTP 请求. 特点是可以不需要刷新页面/页面跳转 就能进行数据传输.
<body>
<!--引入jquery-->
<script src="https://code.jquery.com/jquery-3.6.3.min.js"></script>
<script>
$.ajax({
type:'get',
url:'https://www.sogou.com?studentName=zhangsan',
//次数success声明了一个回调函数,就会在服务器响应返回到浏览器的时候触发该回调
//此处的回调体现了"异步"
success:function(data){
//data是响应的正文部分
console.log("当服务器返回的响应到达浏览器之后,浏览器触发该回调,通知到咱们的代码中");
}
});
console.log("浏览器继续往下执行后续代码");
</script>
</body>
3.使用第三方工具构造HTTP请求(postman)
五、Fiddler使用
浏览器自带的功能数据并不是很完善,所以我们需要用到第三方工具 fiddler 这个工具来抓包, Fiddler的安装,官网选择经典模式,安装下载即可。
安装好之后先选择tools然后options点击HTTPS,然后找图中内容全选,再安装提示,安装一个证书。
(1)使用
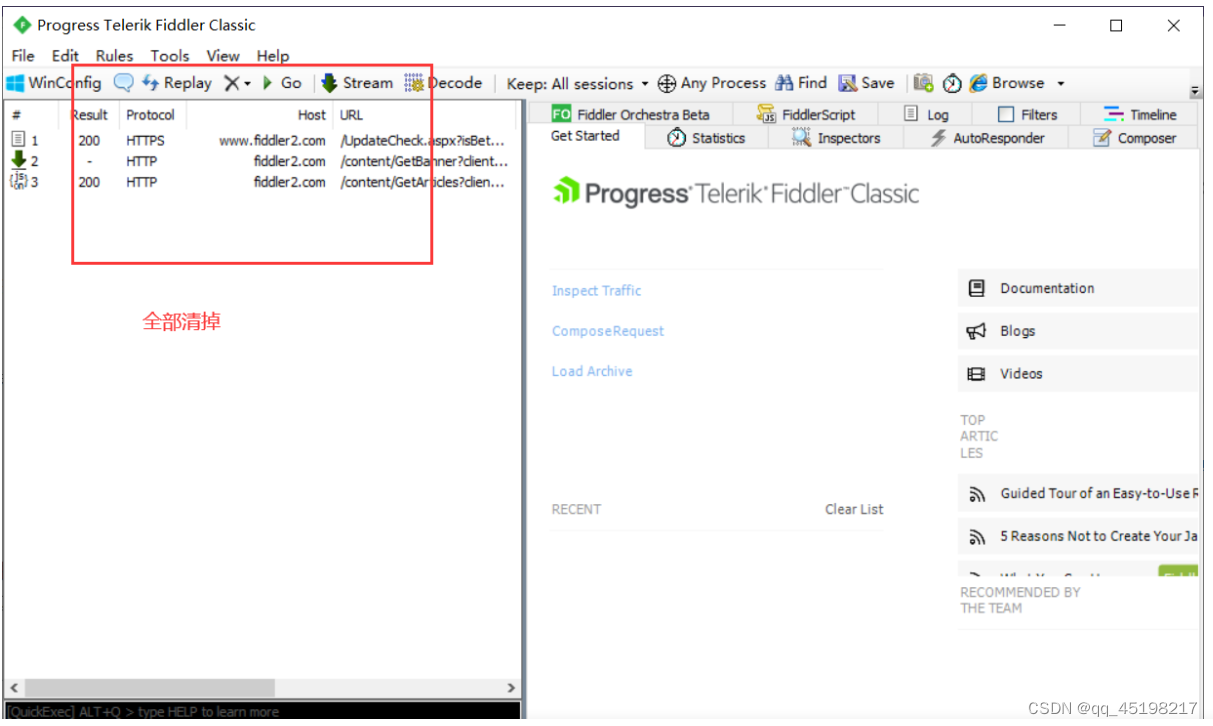
①首先刚进 Fiddler左侧会有东西,把他全部清除掉,再从浏览器地址栏搜索你想要的地址。
②此时左侧会有很多选项,选项中字体有一些为蓝色的可能就是我们要抓的包,抓包这种东西得多抓几次才会抓准确,
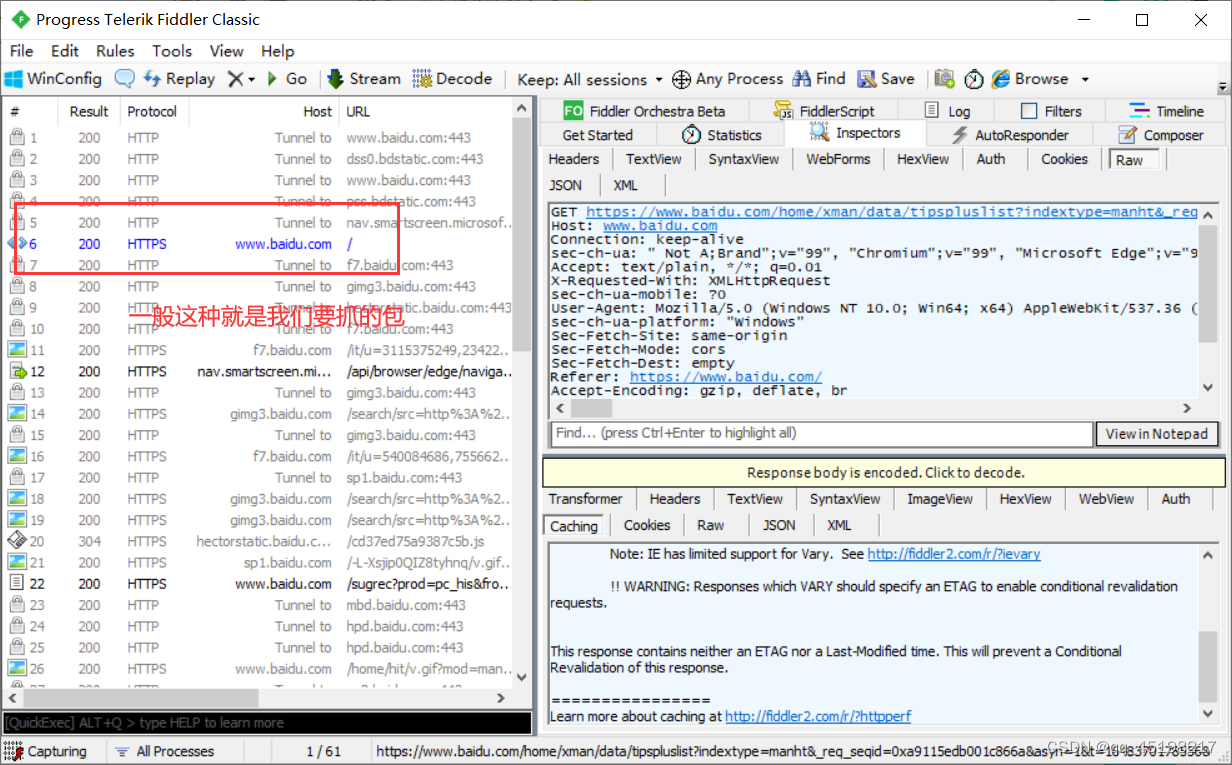
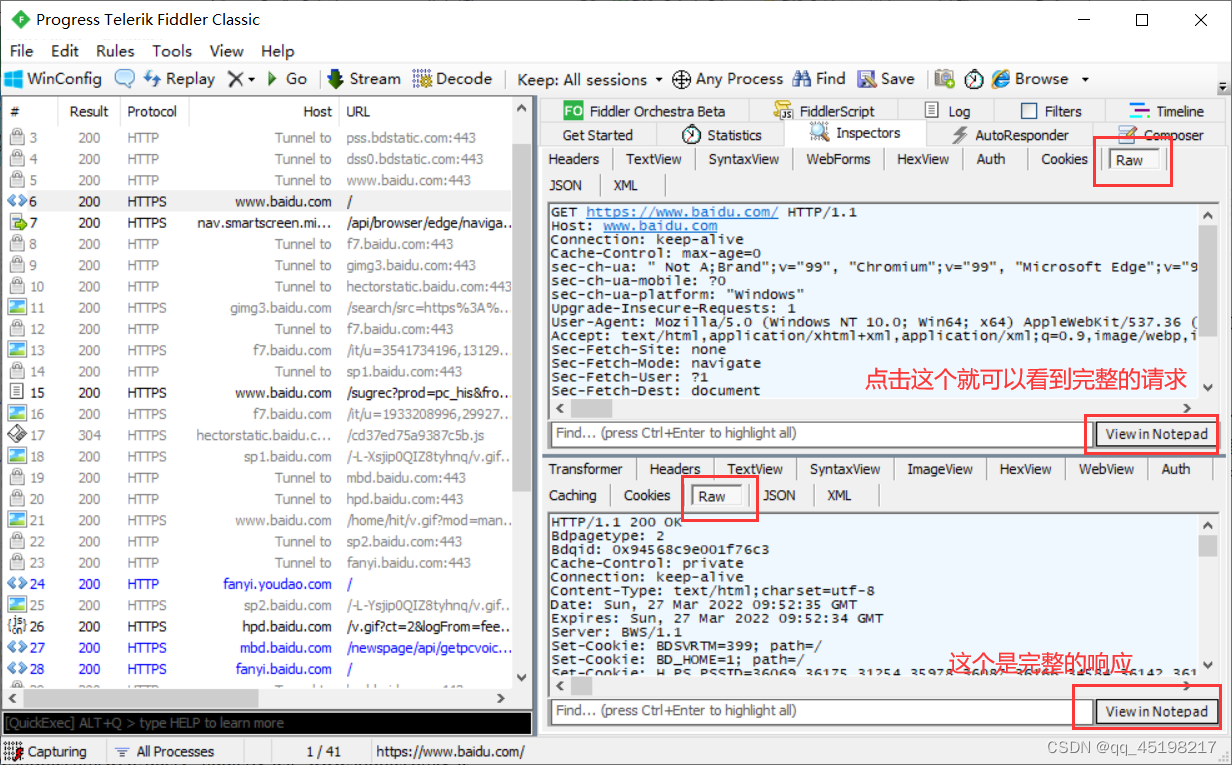
③请求与响应
2.2 抓包原理
Fiddler之所以能够获得到这些HTTP请求的详细情况,主要是因为Fiddler相当于一个“代理‘的作用。也可以想象成一个代购,例如人在中国但想买国外的东西,这就需要代购了,代购直接在国外买东西,然后给你寄过来。Fiddler的作用就相当于中间的代购,浏览器给服务器请求发送的数据以及服务器响应返回的数据,就会被Fiddler给都获取。
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









