







期刊:ICLR
作者:Lukas Ruff * 1 Robert A. Vandermeulen * 2 Nico G ̈ornitz 3 Lucas Deecke 4 Shoaib A. Siddiqui 2 5 Alexander Binder 6 Emmanuel M ̈uller 1 Marius Kloft 2
框架:在introduction部分引出FCDD,再简述深度AD相关的工作,提出深度AD单类分类方法。后续便围绕解释深度单类分类展开,实验部分介绍内容还是蛮多。对不同数据集有不同的异常检测基准,解释了异常检测过程中的缺陷,还包含了”聪明的汉斯效应“。最后得出的结论分为七个部分:接受域的敏感度分析、高斯方差的影响、异常热图的可视化、网络架构中的细节、试验过程中针对不同数据集的训练和优化过程的一定解释、多个多种异常热图结果。
评价:重点在于其单类分类方法的可解释性
术语:explainability 可解释性、
目录
3 Explaining Deep One-class Classification 解释深度单类分类
摘要
本文提出的是完全卷积数据描述FCDD。在MVTec-AD制造业数据集上,在无监督的情况下创造了新的技术水平。
作者的方法:在训练过程中加入地面真实的异常解释,利用FCDD的解释,证明了深度单类分类模型对虚假图像特征的脆弱性。
1 Introduction
异常检测AD。人们通常使用异常得分注释像素来使异常检测得到解释。
- DSVDD深度支持向量数据描述:基于寻找一个神经网络,对数据进行转换,使名义数据集中到一个预定的中心,异常数据位于其他地方。
- FCDD:对DSVDD的修改。转换后的样本本身就是一个对应于下采样异常热图的图像。其中远离中心的像素对应于输入图像中的异常区域。只使用卷积层和池化层,限制了每个输出像素的接受域。
深度单类分类模型容易出现“聪明的汉斯”效应,即检测器固定在图像水印等虚假特征上。一般来说,生成的异常热图比基线的噪音更小,提供更多的结构,包括基于梯度的方法和自动编码器。
2 related work相关的工作
简述关于深度AD的相关工作,重点:解释方法。经典的深度AD使用自动编码器。在名义数据集上训练的自动编码器被认为重建异常样本的能力很差,得出重建误差可作为异常得分,像素级差异作为解释,进而自然地提供异常热图。最近的工作:将注意力纳入可以作为解释的重建模型。
重建方法的缺点:没有提供自然的方法来在训练期间纳入已知的异常情况。
深度AD单类分类方法:试图将名义数据集中在特征空间,将异常情况映射到遥远的位置,以无监督的方式将名义样本与异常情况分开。
- NLP领域,DSVDD已成功应用,产生了一种使用注意力机制的解释形式。
- 图像领域:使用深度泰勒分解得出相关性分数
表现较好的深度AD方法:基于自我监督的。即对名义样本进行转换,训练一个网络来预测在输入数据上使用了哪种转换方式,并通过预测的置信度提供一个异常得分。
大量的解释方法:模型诊断方法、基于梯度的技术。完全卷积架构已被用于监督分割任务
Q:什么是名义样本?A1:即正常数据样本
数据的转换方式有哪些?A2:
完全卷积架构?A3:后续已经回答
3 Explaining Deep One-class Classification 解释深度单类分类
深度单类分类。即通过学习神经网络来映射输出空间中心c附近的名义样本,让异常情况被映射掉,以此来进行异常检测。
对本文来说:使用超球体分类器HSC,是对Deep SAD的修改,是DSVDD的半监督版本
X1,……,Xn表示一个样本集合,y1,……,yn为标签,yi=1表示异常,yi=0表示名义样本。
HSC的目标:
c为中心,对应网络最后一层的偏置项,是包括在φ中的。φ是具有权重w的神经网络,h为伪Huber损失,
为稳健的损失
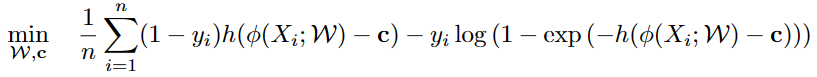
全卷积架构。使用全卷积网络FCN:将图像映射到一个特征矩阵,保留了空间信息。
- 只使用卷积层和池化层,不包含任何全连接层。此时:池化可被看作一种特殊的具有固定参数的卷积。
- 卷积层的核心属性:输出的每个像素只取决于输入的一个小区域,即输出像素的接收域。
- 每个输出像素的相对位置与输入中的相关感受区相同。
全卷积数据描述。FCDD的全卷积数据描述。
利用FCN、HSC的优势,提出了一种深度的单类方法,输出特征保留了空间信息,作为一个下采样的异常热图,
Q:全分辨率热图?
FCDD使用被标记为名义或异常的样本进行训练。其中异常样本可以是一个不属于名义样本的随机图像集合。
最近关于深度AD的工作中推荐使用这类似的辅助语料库,被称为Outlier Exposure。此外,在没有任何一种已知的异常现象的情况下,我们可以生成合成异常现象
Q:辅助语料库?
FCDD目标利用FCN输出矩阵![]() 的伪Huber损失,所有操作均是逐个元素应用。
的伪Huber损失,所有操作均是逐个元素应用。
FCDD目标的定义:
利用FCN域前面提出的HSC损失的新调整相结合。
会对异常情况下的||A(X)||1进行最大化,对名义样本最小化。选择使用||A(X)||1作为异常情况得分。
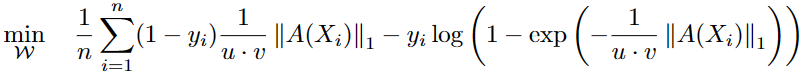
训练情况下,通常缺乏AD缓解下的地面真实异常地图,不可能以监督的方式来训练FCN对低分辨率热图A(X)进行上采样。于此:引入了一个基于感受野特性的上采样方案——热图升频。
Q:上采样?
热图升频。异常检测的寻来你过程中,一般无法获得真实的像素注释,无法学习如何使用卷积类型的结构进行升频。
推导出一种原则性的方法来取代低分辨率异常热图:对于A(X)中的每一个输出像素,都有一个独特的输入像素,位于其感受域的中心。
使用一个固定的高斯核的转置卷积对A(X)进行上采样。
感应场升频算法:

4 Experiments实验
对FCDD的性能进行定量和定性评估。
- 定量:使用ROC曲线
- 定性:将FCDD产生的热图与现有的深度AD解释方法进行比较。
使用像素级的重建误差作为解释热图。使用用于FCDD的高斯核对基线的热图进行了轻微的模糊处理,可减少噪音,更容易的解释热图。实验中:不考虑与模型无关的解释。
4.1 标准的异常检测基准
常见的AD基准是利用这些分类数据集的-VS-设置,“-”被用作名义类,其余类在测试时被用作异常类。
训练:只使用名义样本以及一些辅助的Outlier Exposure数据集的随机样本。会报告每个数据集的所有类别的平均AUC。在Fashion-MINIST、CIFAR-10核ImageNet数据集上进行FCDD的评估。
- Fashion-MINIST。使用EMNIST或灰度CIFAR-100作为OE训练Fashion-MINIST。使用了一个由3个卷积层组成的网络,进行了批量归一化,由2个下采样池化层隔开。
- CIFAR-10。每一个类放在vs-rest的设置中。使用与LeNet-5类似的模型,将核大小减少到3个,增加了批量归一化,将全连接层和最后的最大池层改为两个进一步的卷积。
- ImageNet。考虑了IMageNet1k中的30个类,用于-vs-设置,对于OE,使用ImageNet22k,使用VGG11的改编并进行批量归一化,适用于调整为224x224的输入。
Q:什么是OE?
最先进的方法,有结果并属于本文献作出的用*号标出

定量结果:FCDD使用了一个受限的FCN结构来提高可解释性,但性能接近于最先进的方法,超过了自动编码器。其中自动编码器在更复杂的数据集上产生的检测性能接近于随机。
 (c)中是按异常得分从左到右递增排序的,即左边是看起来最名义的异常到右边看起来最反常的异常。
(c)中是按异常得分从左到右递增排序的,即左边是看起来最名义的异常到右边看起来最反常的异常。
定性结果。
Q:没太懂这里的解释
基线解释。提议的FCDD异常热图产生了一个良好的、一致的视觉解释。
4.2 解释制造中的缺陷
使用给定的二进制异常分割图作为地面真实的像素标签,从热图像素得分计算AUC。解释AUC的所有样本的平均值,进行定量评估。对于FCDD,使用的网络是基于ImageNet上预先训练的VGG11网络,冻结了前10层,然后是我们训练的额外的完全卷积层。
- 合成异常点。使用一种“纸屑噪声”来生成合成异常,是一种简单的噪声模型,在图像中插入彩色的斑点,反映了异常的局部性质。
- 半监督FCDD。主要优点:很容易地用于半监督的AD设置。为看到只有少数标记的异常点和它们对应的地面真实异常图用于训练的效果,为每个MVTec-AD类随机挑选一个真实的异常样本,将其加入训练集。在像素层面上训练一个模型,利用地卖弄真实热图的优势。通过一下方式制定像素级目标
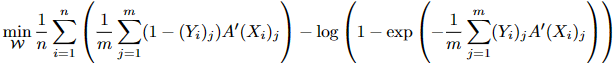
结果。FCDD在·无监督环境下的表现优于其竞争对手,创造了0.92的像素平均AUC的新技术水平。在半监督环境下--每个缺陷类别只使用一个异常样本和相应的异常图--解释性能进一步提高到0.96像素平均AUC。
4.3 聪明的汉斯效应

Q:何为汉斯效应?A:如果图片的水印被去除则表示失败
该图显示:单类模型确实很容易学习到基于虚假特征的特征:左下角的水印有高分,其他区域有低分。与传统的黑箱模型相比,像FCDD这样的透明检测器使从业者能够识别和补救。模型没办法知道假的特征在训练时是否提供了良好的判别能力。
5 Conclusion结论
FCDD表现良好,并且可以适应语义检测任务和更微妙的缺陷检测任务。直接将解释与异常得分联系起来应该使FCDD不容易受到攻击。
接收场的敏感性分析
检测性能只受到感受区较小的影响,较大的感受域会导致解释热图变得不那么集中。
CIFAR-10:创建了8个不同的网络结构来研究感受域的大小的影响,每个架构有4个卷积层、2个最大池层。为改变感受域,在3-17之间改变第一个卷积层的核大小。
- 内核大小为3:接受域包含大约1/4的图像
- 内核大小为17:接受域是整个图像
MVTec-AD。为其创建了6个不同的网络架构。有6个卷积层核3个最大池层。将所有卷积层的核大小在3-13中变化,分别对应于1/16核完整图像的接受域,
高斯方差的影响
使用前面提出的热图升采样,FCDD提供了全分辨率的异常热图。上升采样涉及到高斯核的σ的选择。本节展示了σ这个超参数对FCDD在MVTec-AD上的解释性能的影响。
对于一个输入为X = {X1, . . . , Xn} ,其对于的全分辨率异常热图为A = {A′(X1), . . . , A′(Xn)},对某个A‘(X)的归一化热图I(X)的计算方法:
j表示第j个像素,qη表示A中所有像素和样本的第η个百分位数
A的所有像素和所有样本中提取最小值,然后按元素方向进行减法。使用第η个百分位数可能会留下一些高于1的值,这就是为什么我们最终将像素钳制在1
η越低,热图中的红色(异常)区域就越多,因为有更多的值被留在1以上。
A′(X)只对其自身的分数进行归一化(突出图像中最异常的区域),到完整的数据集(突出哪些区域与整个数据集相比是异常的)
对于完整的数据集的可视化,我们重新平衡数据集,使X包含同等数量的名义图像和异常图像,以保持一致的比例。
η和X的选择在每个图中是一致的。
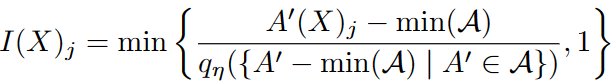
网络结构中的细节

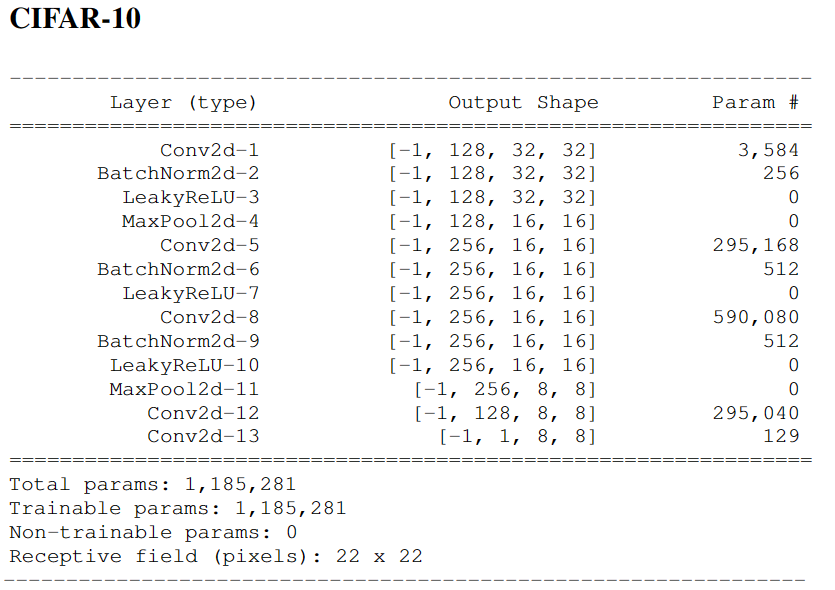
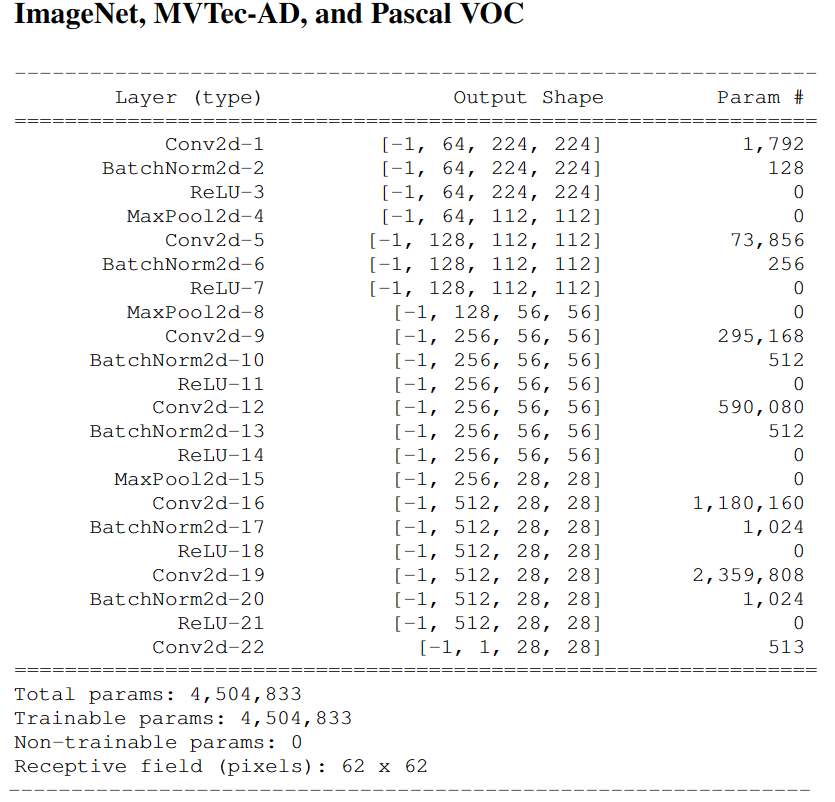
训练和优化
在数据加载管道中应用常见的预处理(如数据归一化等)和数据增强步骤。为了在训练期间以在线方式对辅助异常点进行采样,一个批次的每个名义样本有50%的机会被随机挑选的辅助异常点所取代。导致了足够大的批次规模的平衡训练批次。
实现中,一个epoch是指原始的名义数据训练集的大小。每个训练纪元大约有50%的名义样本被看到。
-
Fashion-MNIST。用128个样本的批量大小训练400个周期,使用SGD优化网络参数,使用Nesterov动量(μ=0.9),权重衰减为10-6,初始学习率为0.01。
-
预处理管道:1)随机裁剪大小为28,事先在所有的边上填充2个零像素(2)随机水平翻转,机会为50%(3)数据归一化。
-
Q:什么是Nesterov动量?
-
CIFAR-10。使用200个样本的批量大小训练了600个epochs。使用Adam(β=(0.9,0.999))对网络进行优化,权重衰减为10-6,初始学习率为0.001。历时400和500时降低10倍。
-
预处理管道是:(1)随机颜色抖动,所有参数设置为0.01(2)随机裁剪大小为32,事先在所有边上填充4个零像素(3)随机水平翻转,机会为50%(4)加高斯噪声,σ=0.001(5)数据归一化。
-
-
ImageNet。使用与CIFAR-10相同的设置,但在通过管道转发之前将所有图像的大小调整为256×256,并将随机裁剪改为224大小,没有填充。
-
Pascal VOC。使用与CIFAR-10相同的设置,但在通过管道转发之前将所有图像的大小调整为224×224,并删除随机裁剪步骤。
-
MVTec-AD。定义了一个epoch为完整数据集的10次迭代。提高了数据管道的计算性能。我们使用具有Nesterov动量(μ=0.9)、权重衰减10-4、初始学习率为0.001的SGD训练了200个周期,每个周期的下降系数为0.985。预处理管道是:(1)调整大小至240×240像素(2)随机裁剪至224大小,没有填充物(3)随机颜色抖动,所有参数设置为0.04或0.0005,随机选择(4)50%的机会应用加性高斯噪声(5)数据归一化。
进一步定性的异常热图结果
为了使不同类别的热图具有可比性,对一个图中的所有热图采用了统一的归一化处理。但是每个类别都有一个单独的异常检测器被训练,对某些类别产生了次优的可视化效果,如图18的MVTec-AD的 "牙刷 "图像。对这些类的归一化进行调整可以发现,热图实际上倾向于标记正确的异常区域。
图20:ImageNet中的异常测试样本的异常热图,其中22-30类显示。各栏按异常得分从左到右递增排序。小标题指的是每个模型所训练的名义类,其中一些例子也作为单独的一列显示在左边。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











