









记录一下做网页抓取,jsoup和selenium
记得第一次了解jsoup是在几年前在哔哩哔哩网站上看到up主遇见狂神说的es教程上,挺久没有用了现在回顾一下。
jsoup是一款Java 的HTML解析器,可直接解析某个URL地址、HTML文本内容。它提供了一套非常省力的API,可通过DOM,CSS以及类似于jQuery的操作方法来取出和操作数据
先介绍一下jsoup的简单使用:
- 导入pom
- 编写java代码
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.8.3</version>
</dependency>
String url = "https://***";
Document document = Jsoup.parse(new URL(url), 5000);
Element el = document.getElementById("***");
//这里就和js中的元素获取一致,获取到指定的元素后可通过text()方法获取文本
仅仅依靠jsoup有些网页数据是获取不到的,所以可以借助Selenium
Selenium是一个用于Web应用程序测试的工具。Selenium测试直接运行在浏览器中,就像真正的用户在操作一样。
官网简单demo
Selenium安装请自行百度
还是分两步走
- 导入pom
- 编写java代码
<dependency>
<groupId>org.seleniumhq.selenium</groupId>
<artifactId>selenium-java</artifactId>
<version>3.141.59</version>
</dependency>
System.getProperties().setProperty("webdriver.chrome.driver", "D:\\Download\\Spring Could\\chromedriver\\chromedriver.exe");
WebDriver driver = new ChromeDriver();
//打开网页
driver.get("https://www.selenium.dev/selenium/web/web-form.html");
String title = driver.getTitle();
WebElement textBox = driver.findElement(By.name("my-text"));
WebElement submitButton = driver.findElement(By.cssSelector("button"));
textBox.sendKeys("Selenium"); //给input标签赋值
submitButton.click(); //模拟点击
WebElement message = driver.findElement(By.id("message"));
String value = message.getText();
//当然如果觉得Selenium解析网页获取节点元素没jsoup好用还可以借助jsoup来解析网页
//Document parse = Jsoup.parse(driver.getPageSource());
driver.quit(); //关闭浏览器
元素等待机制
在对元素进行定位时,有时候网页加载时间比较长,元素还没有加载出来,这个时候去查找这个元素的话程序中就会抛出异常,所以我们在编写代码时需要等待元素加载完,再操作。
- 硬性等待:强制等待,使用方法Thread.sleep(int sleeptime),使用该方法会让当前执行进程暂停一段时间(你设定的暂停时间)。弊端就是,你不能确定元素多久能加载完全,如果两秒元素加载出来了,你用了30秒,造成脚本执行时间上的浪费
try {
Thread.sleep(5);
}catch (InterruptedException e){
e.printStackTrace();
}
- 隐式等待:在设定时间内,特定元素没有加载完成,则抛出异常,如果元素加载完成,剩下的时间将不再等待。这种方法相对于硬性等待显的会灵活一点,但是隐式等待也有个弊端,因为这个设置是全局的,程序需要等待整个页面加载完成,直到超时,有时候我需要找的那个元素早就加载完成了,只是页面上有个别其他元素加载比较慢,程序还是会一直等待下去。直到所有的元素加载完成在执行下一步。
WebDriver 提供了三种隐性等待方法:
- implicitlyWait:识别对象时的超时时间。过了这个时间如果对象还没找到的话就会抛出NoSuchElement 异常。
- setScriptTimeout:异步脚本的超时时间。WebDriver 可以异步执行脚本,这个是设置异步执行脚本,脚本返回结果的超时时间。
- pageLoadTimeout:页面加载时的超时时间。因为 WebDriver 会等页面加载完毕再进行后面的操作,所以如果页面超过设置时间依然没有加载完成,那么 WebDriver 就会抛出异常。
driver.manage().timeouts().implicitlyWait(5,TimeUnit.SECONDS);
driver.manage().timeouts().setScriptTimeout(5,TimeUnit.SECONDS);
driver.manage().timeouts().pageLoadTimeout(5, TimeUnit.SECONDS);
- 显式等待: 显示等待是等待指定元素设置的等待时间,在设置时间内,默认每隔0.5s检测一次当前的页面这个元素是否存在,如果在规定的时间内找到了元素则执行相关操作,如果超过设置时间检测不到则抛出异常。默认抛出异常为:NoSuchElementException。推荐使用显示等待。
具体使用案例:
WebDriverWait wait = new WebDriverWait(driver, 5);
// 查找id为"kw"的元素是否可见
wait.until(ExpectedConditions.visibilityOfElementLocated(By.id("kw")));
WebDriver 常用 API
| 方法 | 描述 |
|---|---|
| get(String url) | 访问目标 url 地址,打开网页 |
| getCurrentUrl() | 获取当前页面 url 地址 |
| getTitle() | 获取页面标题 |
| getPageSource() | 获取页面源代码 |
| close() | 关闭浏览器当前打开的窗口 |
| quit() | 关闭浏览器所有的窗口 |
| findElement(by) | 查找单个元素 |
| findElements(by) | 查到元素列表 |
WebElement 常用 API
| 方法 | 描述 |
|---|---|
| click() | 对元素进行点击 |
| clear() | 清空内容(如文本框内容) |
| sendKeys(…) | 写入内容与模拟按键操作 |
| isDisplayed() | 元素是否可见(true:可见,false:不可见) |
| isEnabled() | 元素是否可见(true:可见,false:不可见) |
| isSelected() | 元素是否已选择 |
| getTagName() | 获取元素标签名 |
| getAttribute(attributeName) | 获取元素对应的属性值 |
| getText() | 获取元素文本值(元素可见状态下才能获取到) |
| submit() | 表单提交 |
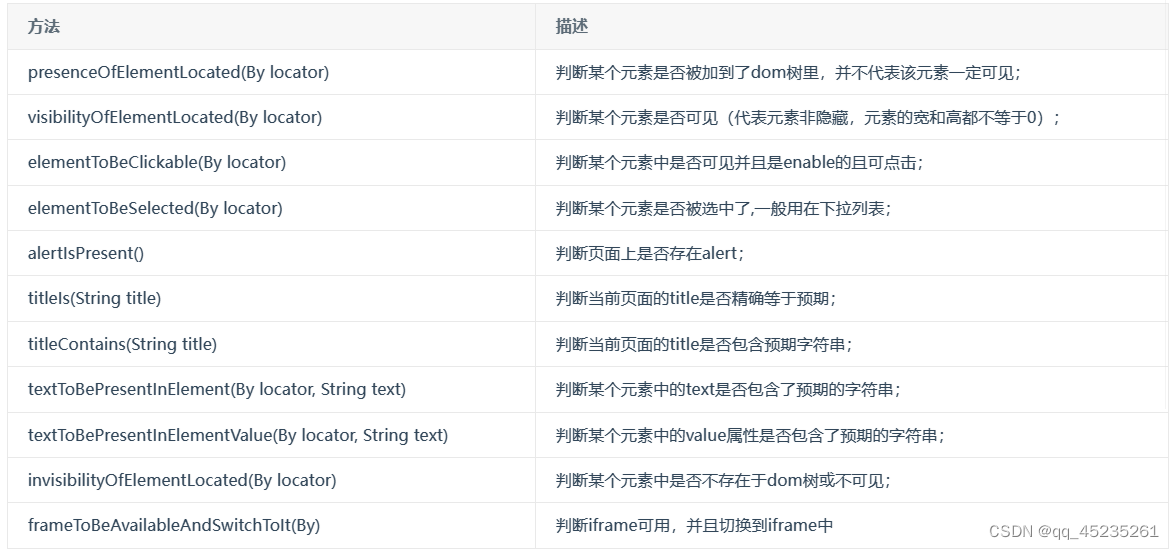
ExpectedConditions类中常用方法
参考文档:https://www.cnblogs.com/tester-ggf/p/12602211.html















 399
399











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









