







爬虫的场景
小许同学想做一个新闻网站,但新闻网站需要很多新闻素材,并且新闻对实时性要求比较高,从发现新闻热点,写稿,审核,排版、发稿、投放需要多人多个部门协同完成,当你这些资源都不具备的时候,而你恰恰又有强烈的需求时,如果此刻你会一些爬虫技术,那么这些问题都迎刃而解,因为想喝牛奶,不一定真的要养一头奶牛。
一、什么是爬虫
网络爬虫(又称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫。 - 百度百科
个人通俗的理解就是:模拟人的行为去各个网站溜达,点点按钮,查查数据,或者把看到的信息背回来。就像一只虫子在一幢楼里不知疲倦地爬来爬去
二、爬虫协议
路边的野花不要踩,如果你控制不住,你偏要踩,小心回家跪搓衣板。那么爬虫也是一样,很多系统是很讨厌爬虫的,它们希望自己的业务数据不被窃取,而爬虫违背了它们利益,所以一不小心容易爬进监狱,监狱送福利,包吃包住,一日三餐东南海(冬瓜,南瓜,海带)。
但并不是所有的网站都讨厌爬虫,因为很多网站做SEO,它们希望被搜索引擎收录,被爬虫主流搜索引擎的爬虫抓取。比如:www.hao123.com,我们观察它的爬虫协议(https://www.hao123.com/robots.txt)就能看出它允许部分(百度、谷歌、有道、搜狗、搜搜)等爬虫对他进行蹂躏。其他的爬虫它一律不允许。如果你要强上,弄的不爽,那就是要告你的。
User-agent: Baiduspider
Allow: /
User-agent: Baiduspider-image
Allow: /
User-agent: Baiduspider-video
Allow: /
User-agent: Baiduspider-news
Allow: /
User-agent: Googlebot
Allow: /
User-agent: MSNBot
Allow: /
User-agent: YoudaoBot
Allow: /
User-agent: Sogou web spider
Allow: /
User-agent: Sogou inst spider
Allow: /
User-agent: Sogou spider2
Allow: /
User-agent: Sogou blog
Allow: /
User-agent: Sogou News Spider
Allow: /
User-agent: Sogou Orion spider
Allow: /
User-agent: JikeSpider
Allow: /
User-agent: Sosospider
Allow: /
User-agent: *
Disallow: /如何查看爬虫协议:在网站根域名下,一般会放一个robots.txt文件,文件中会清楚的描述哪些允许,哪些不允许。如果没有放置这样的文件,那就不管啦,霸王硬上弓。
三、需要掌握的技能
| 1、 | 掌握一门基础语言,会基础的编码(本文例子以Java语言为例) |
| 2、 | 掌握HTML+CSS+JavaScript 及盒子模型 |
| 3、 | 数据库+熟悉反爬策略 |
只讲理论不实战,那都是耍流氓。来,举栗子
四、Jsoup 实现简单爬虫
Jsoup是一款Java 的HTML解析器,可直接解析某个URL地址、HTML文本内容。它提供了一套非常省力的API,可通过DOM,CSS以及类似于jQuery的操作方法来取出和操作数据。总之,如果对HTML页面很了解的话,是可以很容易的用Jsoup来抓取页面的信息的。

1、分析页面元素
通过浏览器打开 “开发者调试工具” 通过选择器审查页面元素,按照盒子模型思维分析页面元素信息,如下图所示:
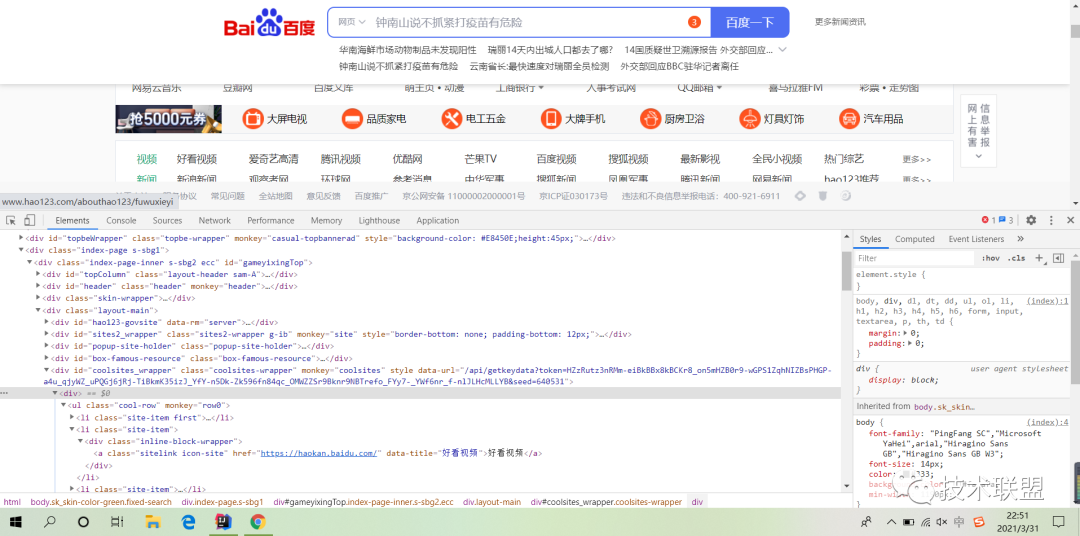
页面元素定位路径:coolsites_wrapper->cool-row-> href
Jsoup 实现简单爬虫源代码入下:
package com.it.union;
import org.jsoup.Connection;
import org.jsoup.Jsoup;
import org.jsoup.helper.StringUtil;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import java.io.IOException;
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
/**
* @author youyun.xu
* @ClassName: Spider
* @Description: Jsoup 实现简单爬虫
* @date 2021/3/15 20:39
*/
public class Spider {
static List<LinkEntity> stores = new ArrayList<>();
public static void main(String[] args) {
//1、与目标服务建立连接
Connection connection = Jsoup.connect("https://www.***.com/");
connection.header("user-agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.80 Safari/537.36");
try {
// 2、执行请求、解析结果
Document document = connection.get();
Element element = document.getElementById("coolsites_wrapper");
// 3、定位到->"酷站列表"
Elements elements = element.getElementsByClass("cool-row");
Iterator iterator = elements.iterator();
while (iterator.hasNext()) {
Element ulElement = (Element) iterator.next();
// 4、获取当前盒子模型下<a>标签列表
Elements links = ulElement.getElementsByTag("a");
Iterator iteratorLinks = links.iterator();
// 5、迭代遍历超链接列表
while (iteratorLinks.hasNext()) {
Element items = (Element) iteratorLinks.next();
String text = items.text();
String attribute = items.select("a").attr("href");
if (StringUtil.isBlank(attribute) || StringUtil.isBlank(text)) {
continue;
}
stores.add(new LinkEntity(text, attribute));
}
}
// 6、遍历爬取的结果(此处只做演示,不做任何存储操作)
stores.parallelStream().forEach(item -> {
System.out.println(item.getName() + " -> " + item.getUrl());
});
} catch (IOException e) {
e.printStackTrace();
}
}
}
class LinkEntity {
private String name;
private String url;
public LinkEntity(String name, String url) {
this.name = name;
this.url = url;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getUrl() {
return url;
}
public void setUrl(String url) {
this.url = url;
}
}Jsoup 爬虫技术实现思路:
1、得到自己想要爬取数据的url,与服务器建立链接
2、通过Jsoup的jar包中的方法将Html解析成Document
3、使用Document中的一些列get、first、children等方法获取自己想要的数据,如图片地址、名称、时间。
4、将得到的数据封装成自己的实体类。将实体中的数据在页面加载出来。
Jsoup 爬虫框架的不足:
只有html元素有的情况下,才能通过jsoup来爬虫,如果是这接口获得的数据,那么通过jsoup是无法获取到的。
五、Selenium 自动化测试+爬虫
Selenium 是一款自动化测试框架,支持多种主流的开发,对各种开发语言提供了丰富的API,通过API你可以快速定位页面元素,模拟用户点击,滑动,翻页,截屏等一系列操作。它可模拟用户真实操作行为,并且是基于真实浏览器运行环境,所以在自动化测试中受到了很多测试同学的青睐。当别人叫“WebDriver” 时你不要懵逼,不要换个马甲就不认识了,其实它也就是Selenium2,Selenium3

Selenium 实现简单爬虫+自动化测试 源代码入下:
package com.it.union;
import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.chrome.ChromeDriver;
import org.openqa.selenium.chrome.ChromeOptions;
import java.util.List;
import java.util.concurrent.TimeUnit;
/**
* @author youyun.xu
* @ClassName: SeleniumSpider
* @Description: 使用Java+Selenium 自动框架实现爬虫
* @date 2021/3/31 20:08
*/
public class SeleniumSpider {
private static ChromeOptions initChromeOptions(){
ChromeOptions options = new ChromeOptions();
/*
// 启动时自动最大化窗口
options.addArguments("--start-maximized");
// 禁用阻止弹出窗口
options.addArguments("--disable-popup-blocking");
// 启动无沙盒模式运行
options.addArguments("no-sandbox");
// 禁用扩展
options.addArguments("disable-extensions");
// 默认浏览器检查
options.addArguments("no-default-browser-check");
// 设置chrome 无头模式
options.setHeadless(Boolean.TRUE);
//不用打开图形界面。
options.addArguments("--headless");
*/
options.setBinary("C:\\Program Files\\Google\\Chrome\\Application\\chrome.exe");
return options;
}
private static WebDriver initWebDriver (ChromeOptions options){
WebDriver webDriver = new ChromeDriver(options);
webDriver.manage().window().maximize();
webDriver.manage().timeouts().implicitlyWait(10,TimeUnit.SECONDS);
return webDriver;
}
public static void main(String [] args){
// 1、设置chrome浏览器驱动
System.setProperty("webdriver.chrome.driver", "D:\\tools\\chromedriver_win32\\chromedriver.exe");
// 2、设置ChromeOptions
ChromeOptions chromeOptions= initChromeOptions();
// 3、初始化一个浏览器实例
WebDriver webDriver= initWebDriver(chromeOptions);
// 4、加载网页程序(某度)
webDriver.get("https://image.baidu.com");
// 5、通过ID选择器定位输入框,并设置搜索关键字”帅哥“
webDriver.findElement(By.id("kw")).sendKeys("帅哥");
// 6、通过Class类样式选择器定位,模拟点击事件并提交表单
webDriver.findElement(By.className("s_btn")).submit();
// 7、加载第二个页面:展示搜索页面元素信息
WebElement webElement = webDriver.findElement(By.id("imgid"));
// 8、定位搜索到所有图片元素
List<WebElement> imgs= webElement.findElements(By.className("imgbox"));
// 9、异步获取图片地址
syncThread(imgs);
// 10、模拟页面图片点击事件
imgs.forEach(images ->{
images.click();
});
}
public static void syncThread(List<WebElement> imgs){
Thread thrad = new Thread(new myThread(imgs));
thrad.start();
}
}
class myThread implements Runnable{
List<WebElement> imgs;
public myThread(List<WebElement> imgs) {
this.imgs = imgs;
}
@Override
public void run() {
imgs.forEach(images ->{
WebElement currentImages= images.findElement(By.className("main_img"));
String src=currentImages.getAttribute("src");
System.out.println("图片地址:->" + src);
//此处发挥自己想象(是杀是留,请君自便)
});
}
}Selenium 核心步骤如下:
1、下载对应版本驱动
2、安装浏览器产品,并定位至浏览器运行程序
# Chrome各版本驱动的下载地址http://chromedriver.storage.googleapis.com/index.html# Firefox浏览器对应各个版本驱动下载地址:https://github.com/mozilla/geckodriver/releases/
3、设置chrome浏览器驱动
4、设置ChromeOptions
5、初始化一个浏览器实例
6、加载网页程序(某度)
7、通过ID选择器定位输入框,并设置搜索关键字”帅哥“
8、通过Class类样式选择器定位,模拟点击事件并提交表单
9、加载第二个页面:展示搜索页面元素信息
10、定位搜索到所有图片元素
11、异步获取图片地址
12、模拟页面图片点击事件
今天太晚啦,反爬虫策略还有一个章节内容,各大厂商何有自己的自己反爬虫策略,本篇文章就不再做介绍了。
















 284
284











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











