






条件概率
设 E 是随机试验,Ω 是样本空间,A,B 是随机试验E上的两个随机事件且 P(A)>0,称为在事件 A 发生的条件下事件B发生的概率,称为条件概率,记为 P(B|A)。
对定义1中的公式变换可得 P(AB) = P(A)P(B|A),同理可得P(AB)=P(B)P(A|B),进一步根据这个关系可推得条件概率公式:P(A)P(B/A)=P(B)P(A/B)
全概率
全概率公式是概率论中非常重要的一个公式,通常我们会遇到一些较为复杂的随机事件的概率计算问题,这时,如果将它分解成一些较容易计算的情况分别进行考虑,可以化繁为简。
全概率公式
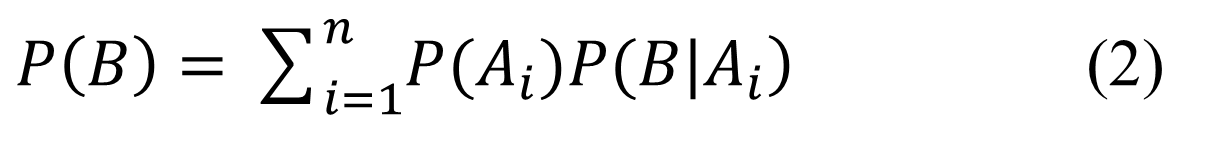
贝叶斯定理
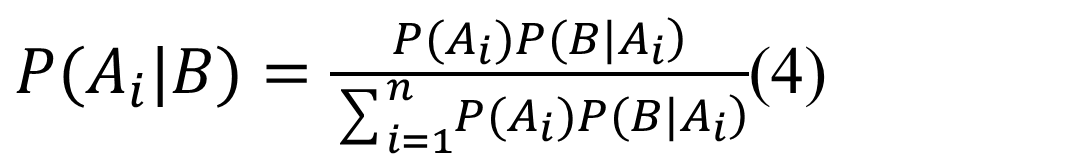
算法步骤



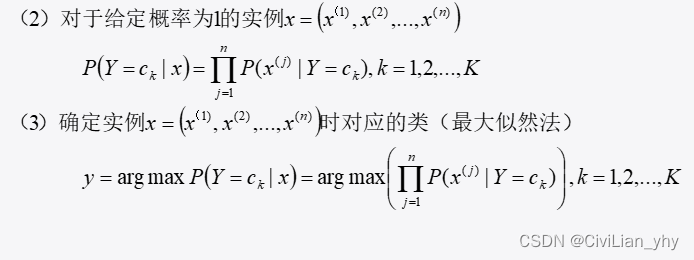
实例 判断是否患有糖尿病
准备数据集 : 皮马印第安人糖尿病数据集
数据内容:数据里包行了768行 X 9列数据。每一行表示一个超过21岁的皮马女性糖尿病患者的信息。前8列表示属性特征,第9列表示分类结果,如果患有糖尿病则为1,否则为0
前8列各个属性含义分别如下:
1.怀孕次数。
2.2小时口服葡萄糖耐量测试中得到的血糖浓度。
3.舒张期血压(mm Hg)。
4.三头肌皮脂厚度(mm)。
5.2小时血清胰岛素(mu U/ml)。
6.身体质量指数(体重kg/(身高in m)^2)。
7.糖尿病家族遗传作用值。
8.年龄。
# -*- coding: utf-8 -*-
"""
Created on Thu Dec 21 11:12:26 2023
@school: WYU
@author: haoyan
机器学习 -- 作业
"""
import numpy as np
import pandas as pd
class Naive_Bayesian :
def __init__(self):
self.useful_Mean = [] # ''' 有效数据均值 '''
self.useful_Var = [] # ''' 有效数据方差 '''
self.useless_Mean = [] # ''' 无效数据均值 '''
self.useless_Var = [] # ''' 无效数据方差 '''
#'''获取样本均值和方差'''
def data_Mean_Var(self,data_set_x,data_set_y):
self.data_set_x_samples, self.data_set_x_features = data_set_x.shape
self.data_set_y_samples, self.data_set_y_features = data_set_y.shape
for i in range(self.data_set_x_features): # 按特征来遍历
useful = [] # ''' 有效数据 '''
useless = [] # ''' 无效数据 '''
for j in range(self.data_set_y_features): # 按样本来便利
if data_set_y[0,j]==1:
useful.append(data_set_x[j,i])
else:
useless.append(data_set_x[j,i])
if len(useful) != 0 :
# useful =[0.697,0.774,0.634,0.608,0.556,0.403,0.481,0.437]
self.useful_Mean.append(np.mean(useful))
self.useful_Var.append(np.std(useful,ddof = 1))
if len(useless) != 0 :
# useless = [0.666,0.243,0.245,0.343,0.639,0.657,0.360,0.593,0.719]
self.useless_Mean.append(np.mean(useless))
self.useless_Var.append(np.std(useless,ddof = 1))
#''' 高斯分布 '''
def Gaussian(self,x, Mean, Var):
# x = 0.697
return np.exp(-(x - Mean) ** 2 / (2 * Var ** 2)) / (np.sqrt(2 * np.pi) * Var)
#'''
# 先验概率
# 返回 概率
#'''
def previous_Probaility(self,data_set_y):
times = 0
for i in range(self.data_set_y_features):
if data_set_y[0,i] == 1:
times += 1
self.useful_Porbaility = times/self.data_set_y_features
self.useless_Porbaility = 1 - times/self.data_set_y_features
#'''
#单个样本 好与坏的概率
#返回 好与坏的概率
#'''
def single_Sample_Probability(self,single_Samle,index,feature):
useful_Probability = 1
useless_Probability = 1
index = 0
for i in range(feature):
useful_Probability = useful_Probability * self.Gaussian(single_Samle[0,i],self.useful_Mean[index],self.useful_Var[index])
useless_Probability = useless_Probability * self.Gaussian(single_Samle[0,i],self.useless_Mean[index],self.useless_Var[index])
index +=1
return self.useful_Porbaility * useful_Probability , self.useless_Porbaility *useless_Probability
#'''
#整个样本
#返回 判断结果
#'''
def all_Sample_Probability(self,data_set_x,data_set_y):
index = 0
Probability = []
for i in range(self.data_set_x_samples):
useful,useless = self.single_Sample_Probability(data_set_x[i,:],index,self.data_set_x_features)
if useful > useless :
Probability.append(1)
# print("好")
else:
Probability.append(0)
# print("不好")
# 计算准确率
times = 0
for i in range(self.data_set_y_features):
if data_set_y[0,i] == Probability[i]:
times +=1
print("准确率:{0}%".format((times/self.data_set_y_features)*100))
return Probability
def data_Handle(data_set):
x_mat = np.mat(data_set.iloc[:,:-1].values)
y_mat = np.mat(data_set.iloc[:,-1].values)
regressor = Naive_Bayesian()
regressor.data_Mean_Var(x_mat,y_mat)
regressor.previous_Probaility(y_mat)
return regressor.all_Sample_Probability(x_mat,y_mat)
if __name__ == '__main__':
data = pd.read_csv('pima-indians-diabetes.data.csv', header = None)
Probability = data_Handle(data)
准确率:76.171875%
















 1285
1285











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









