






继承的定义
现在有两个类,一个是学生类,一个老师类,对于这两个类来说,有很多的共同点,比如:他们都有姓名、性别等,但是对于这两个类来说,他们也有不同点,比如:工号,学号等,对于共同点来说,我们是不是可以帮归类成一个类叫做人,然后再去大类里面分出老师和学生,这样的关系就叫做学生类和老师类继承了人这个类。
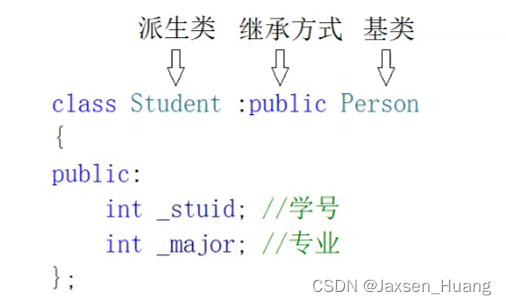
继承的关系和访问限定符
public:在类外,派生类内,自己本身的类域内可以访问
protected:在派生类内,自己本身的类域内可以访问
private:在自己本身的类域内可以访问
| 类成员/继承方式 | public继承 | protected继承 | private继承 |
|---|---|---|---|
| 基类的public成员 | 派生类的public成员 | 派生类的protected成员 | 派生类的private成员 |
| 基类的protected成员 | 派生类的protected成员 | 派生类的protected成员 | 派生类的private成员 |
| 基类的private成员 | 在派生类中不可见 | 在派生类中不可见 | 在派生类中不可见 |
PS:标红为常用的
总结:
- 基类private成员在派生类中无论以什么方式继承都是不可见的。这里的不可见是指基类的私有成员还是被继承到了派生类对象中,但是语法上限制派生类对象不管在类里面还是类外面都不能去访问它。
- 基类private成员在派生类中是不能被访问,如果基类成员不想在类外直接被访问,但需要在派生类中能访问,就定义为protected。可以看出保护成员限定符是因继承才出现的。
- 实际上面的表格我们进行一下总结会发现,基类的私有成员在子类都是不可见。基类的其他成员在子类的访问方式 == Min(成员在基类的访问限定符,继承方式),public > protected > private。
- 使用关键字class时默认的继承方式是private,使用struct时默认的继承方式是public,不过最好显示的写出继承方式。
- 在实际运用中一般使用都是public继承,几乎很少使用protetced/private继承,也不提倡使用protetced/private继承,因为protetced/private继承下来的成员都只能在派生类的类里面使用,实际中扩展维护性不强。
基类和派生类对象的赋值转换
派生类对象 可以赋值给 基类的对象 / 基类的指针 / 基类的引用。这里有个形象的说法叫切片或者切割。寓意把派生类中父类那部分切来赋值过去。基类对象不能赋值给派生类对象。
基类的指针或者引用可以通过强制类型转换赋值给派生类的指针或者引用。但是必须是基类的指针是指向派生类对象时才是安全的。这里基类如果是多态类型,可以使用RTTI(RunTime Type Information)的dynamic_cast 来进行识别后进行安全转换。(ps:这个我们后面再讲解,这里先了解一下)
class Person
{
protected :
string _name; // 姓名
string _sex; // 性别
int _age; // 年龄
};
class Student : public Person
{
public :
int _No ; // 学号
};
void Test ()
{
Student sobj ;
// 1.子类对象可以赋值给父类对象/指针/引用
Person pobj = sobj ;
Person* pp = &sobj;
Person& rp = sobj;
//2.基类对象不能赋值给派生类对象
sobj = pobj;
// 3.基类的指针可以通过强制类型转换赋值给派生类的指针
pp = &sobj
Student* ps1 = (Student*)pp; // 这种情况转换时可以的。
ps1->_No = 10;
pp = &pobj;
Student* ps2 = (Student*)pp; // 这种情况转换时虽然可以,但是会存在越界访问的问题
ps2->_No = 10;
}
继承中的作用域
- 在继承体系中基类和派生类都有**独立**的作用域。
- 子类和父类中有同名成员,子类成员将屏蔽父类对同名成员的直接访问,这种情况叫**隐藏**,也叫重定义。(在子类成员函数中,可以使用 基类::基类成员 显示访问)
- 需要注意的是如果是成员函数的隐藏,只需要函数名相同就构成隐藏。
- 注意在实际中在继承体系里面最好不要定义同名的成员。
派生类的默认成员函数
6个默认成员函数,“默认”的意思就是指我们不写,编译器会变我们自动生成一个,那么在派生类中,这几个成员函数是如何生成呢?
- 派生类的构造函数必须调用基类的构造函数初始化基类的那一部分成员。如果基类没有默认 的构造函数,则必须在派生类构造函数的初始化列表阶段显示调用。
- 派生类的拷贝构造函数必须调用基类的拷贝构造完成基类的拷贝初始化。
- 派生类的operator=必须要调用基类的operator=完成基类的复制。
- 派生类的析构函数会在被调用完成后自动调用基类的析构函数清理基类成员。因为这样才能 保证派生类对象先清理派生类成员再清理基类成员的顺序。
- 派生类对象初始化先调用基类构造再调派生类构造。
- 派生类对象析构清理先调用派生类析构再调基类的析构。
- 因为后续一些场景析构函数需要构成重写,重写的条件之一是函数名相同(这个我们后面会讲 解)。那么编译器会对析构函数名进行特殊处理,处理成destrutor(),所以父类析构函数不加virtual的情况下,子类析构函数和父类析构函数构成隐藏关系。
正确代码:
class Person
{
public :
Person(const char* name = "peter")
: _name(name )
{
cout<<"Person()" <<endl;
}
Person(const Person& p)
: _name(p._name)
{
cout<<"Person(const Person& p)" <<endl;
}
Person& operator=(const Person& p )
{
cout<<"Person operator=(const Person& p)"<< endl;
if (this != &p)
_name = p ._name;
return *this ;
}
~Person()
{
cout<<"~Person()" <<endl;
}
protected:
string _name ; // 姓名
};
class Student : public Person
{
public:
Student(const char* name, int num)
:Person(name )
,_num(num )
{
cout<<"Student()" <<endl;
}
Student(const Student& s)
: Person(s)
, _num(s ._num)
{
cout<<"Student(const Student& s)" <<endl ;
}
Student& operator=(const Student& s)
{
cout<<"Student& operator= (const Student& s)"<< endl;
if (this != &s)
{
Person::operator =(s);
_num = s ._num;
}
return *this ;
}
~Student()
{
/*由于多态的原因,析构函数统一会被处理成destructor,父子类的析构函数会被隐藏*/
//~Person();
//Person::~Person();
cout<<"~Student()" <<endl;
}
protected :
int _num ; //学号
};
void Test ()
{
Student s1 ("jack", 18);
Student s2 (s1);
Student s3 ("rose", 17);
s1 = s3 ;
}
错误案例:
疑问1:这里为什么要这样写? Person(name)
class Student : public Person
{
public:
Student(const char* name, int num)
:Person(name)
,_num(num )
{
cout<<"Student()" <<endl;
}
答:派生类的构造函数要分成两个部分来看到,要显示调用基类的构造函数和自己的成员变量初始化
疑问2:这里的拷贝构造的Person(s)的s为student类为什么可以用来给person类调用它的拷贝构造
Student(const Student& s)
: Person(s)
, _num(s ._num)
{
cout<<"Student(const Student& s)" <<endl ;
}
答:这里的s切片传入基类(派生类赋值给基类),所以只传入了派生类中基类的那一部分
疑问3:把注释处改成operator(s)会是怎么样的结果?如何解决,为什么这么解决?
Student& operator=(const Student& s)
{
cout<<"Student& operator= (const Student& s)"<< endl;
if (this != &s)
{
//Person::operator =(s);
operator=(s);
_num = s ._num;
}
return *this ;
}
答:因为这里的函数名字与父类相同,会发生隐藏这里只会重复调用operator=,不停地发生函数递归,直到stack溢出
疑问4:为什么下面这段代码会报错?
~Student()
{
~Person();//~Person(); == destructor() == ~Student
//Person::~Person();
cout << "~Student()" << endl;
}
答:由于多态的原因,析构函数统一会被处理成destructor()(同一个函数名),父子类的析构函数会被隐藏
疑问5:为什么这里会过多的调用析构函数呢?
~Student()
{
/*由于多态的原因,析构函数统一会被处理成destructor,父子类的析构函数会被隐藏*/
//~Person();
Person::~Person();
cout << "~Student()" << endl;
}
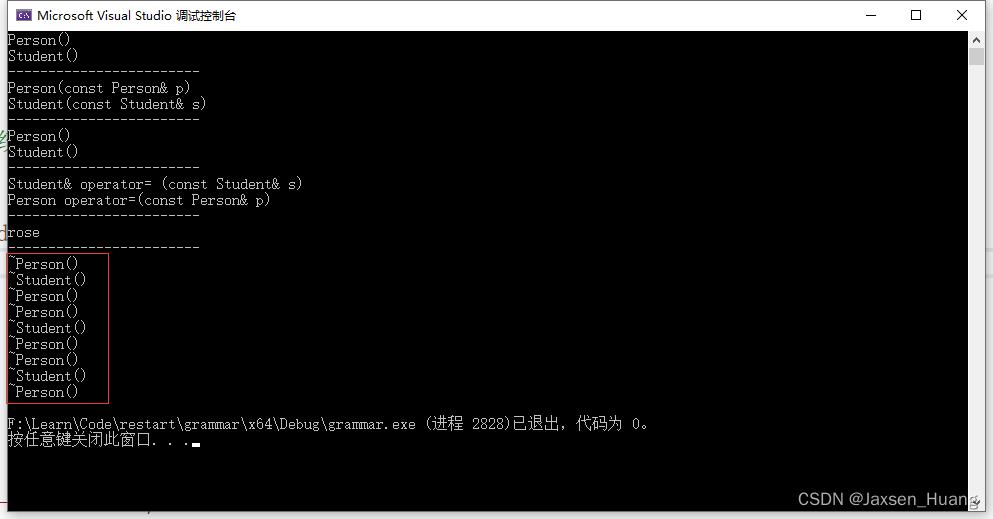
因为这里为保证安全,为了保证基类要在派生类之前先析构(因为如果基类析构先,那么派生类可以访问基类成员,会导致错误),所以要顺从先析构派生类后析构基类的顺序,如果在里面加入~person(),那么派生类进入析构函数的时候,析构了一次,又在派生类析构函数快结束的时候又析构了一次。所以这里会显示多次调用析构,所以不用在派生类中写基类的析构函数,编译器会在派生类析构的时候,按照先派生类后基类去析构。
如何写一个不被继承的类
将基类的构造函数写成私有的(C++98),用final关键字去修饰基类(C++11)。
继承和友元
基类的友元关系不能被继承到派生类里面
继承和静态成员
基类定义了static静态成员,则整个继承体系里面只有一个这样的成员。无论派生出多少个子类,都只有一个static成员实例 。
通俗的说就是,static静态成员的继承好比成员方法的继承,继承了使用权而不是像成员变量继承那样在派生类里面重新生成一份
复杂的菱形继承及菱形虚拟继承
单继承:一个子类只有一个直接父类时称这个继承关系为单继承
多继承:一个子类有两个或以上直接父类时称这个继承关系为多继承
菱形继承:菱形继承是多继承的一种特殊情况
菱形继承的问题:从下面的对象成员模型构造,可以看出菱形继承有数据冗余和二义性的问题。
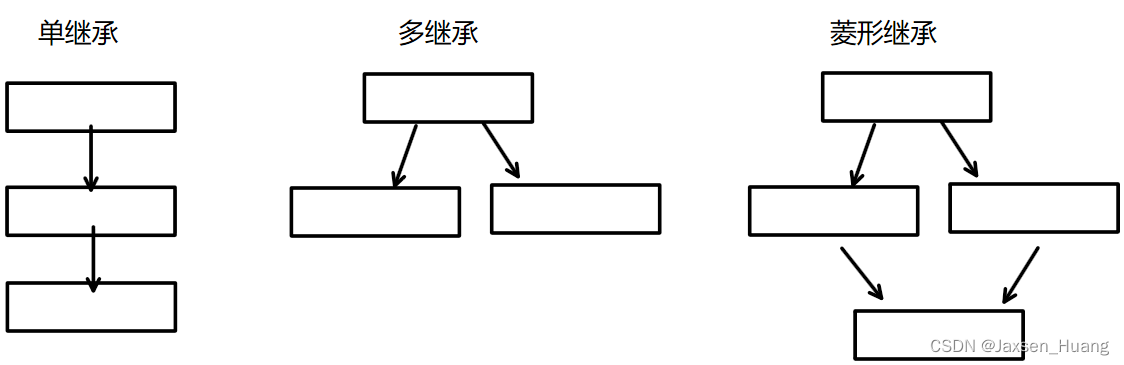
通俗的来说,在菱形继承的第二层中,两个派生类都有第一层基类的属性,是专属于他们两个独自的,就好比学校里面的助教,及时学生也是老师,所以助教类要继承学生类和助教类,但是学生类和老师类也继承了person类,这就会导致助教类有两份person类的信息导致了重复继承了personl类,这就是所谓的数据冗余和二义性
虚拟继承可以解决菱形继承的二义性和数据冗余的问题。如上面的继承关系,在Student和Teacher的继承Person时使用虚拟继承,即可解决问题。需要注意的是,虚拟继承不要在其他地方去使用。
示例代码:
class Person
{
public :
string _name ; // 姓名
};
class Student : virtual public Person
{
protected :
int _num ; //学号
};
class Teacher : virtual public Person
{
protected :
int _id ; // 职工编号
};
class Assistant : public Student, public Teacher
{
protected :
string _majorCourse ; // 主修课程
};
void Test ()
{
Assistant a ;
a._name = "peter";
}
virtual的作用解析:
ps:
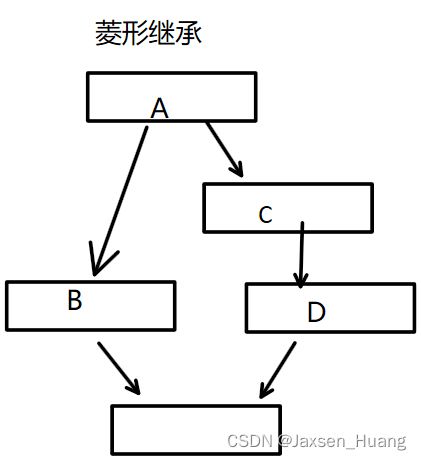
对于这样的菱形继承来说,我们要用virual修饰那个类呢?
答案是 B 和 C
因为virual要直接加在产生数据冗余的类
虚拟继承解决数据冗余和二义性的原理
示例:
class A
{
public:
int _a;
};
// class B : public A
class B : virtual public A
{
public:
int _b;
};
// class C : public A
class C : virtual public A
{
public:
int _c;
};
class D : public B, public C
{
public:
int _d;
};
int Test3()
{
D d;
d.B::_a = 1;
d.C::_a = 2;
d._b = 3;
d._c = 4;
d._d = 5;
return 0;
}
没有加virtual修饰的内存
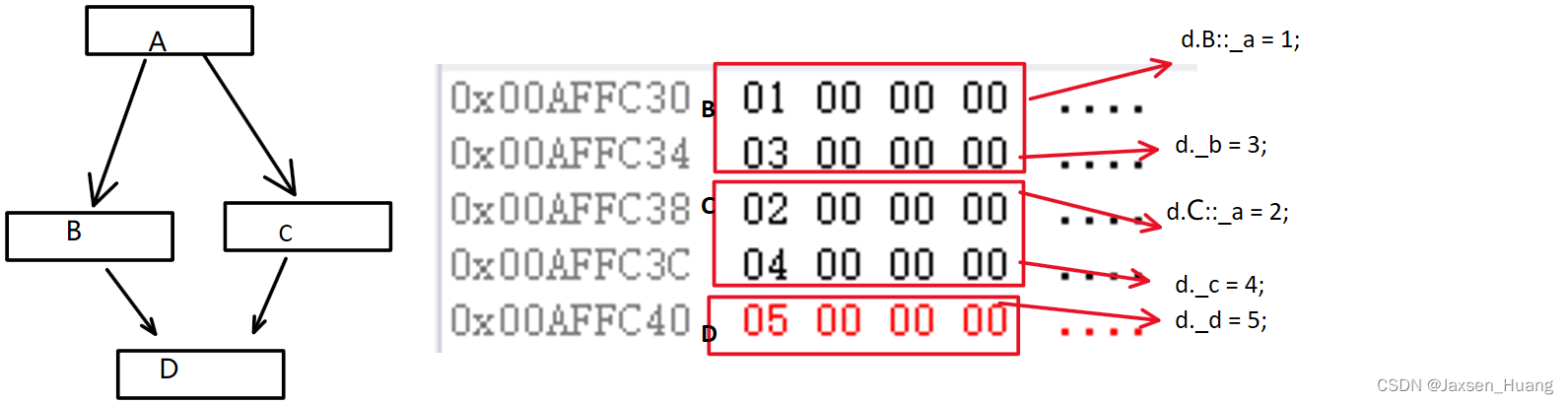
加了virtual修饰的内存
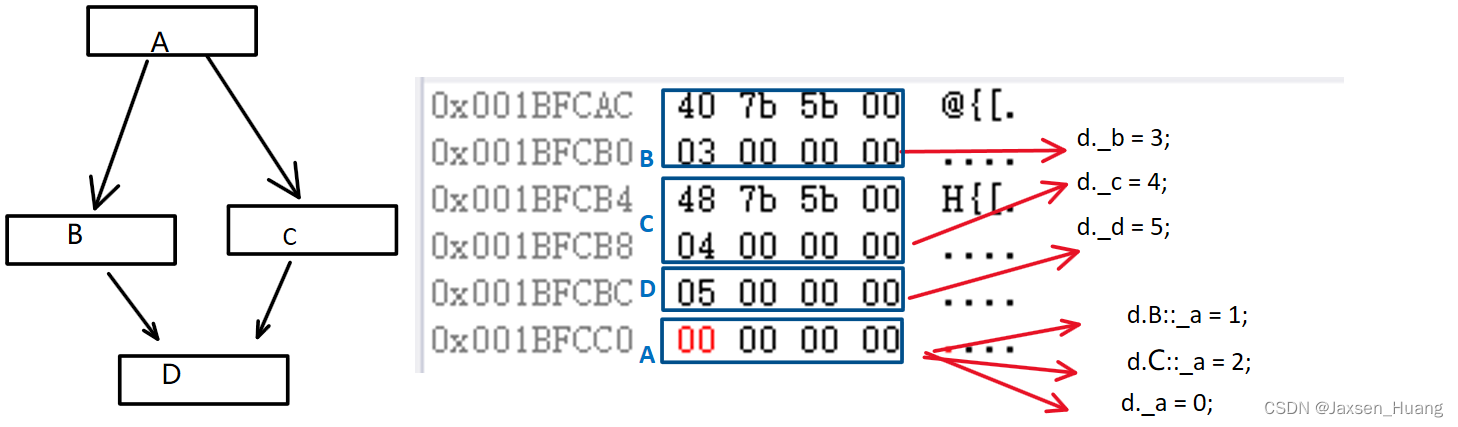
可以看到virtual修饰之后_a全都放q在了同一个内存,但是这里有另一点值得去考虑在被virtual修饰之后如何实现之前的切片功能
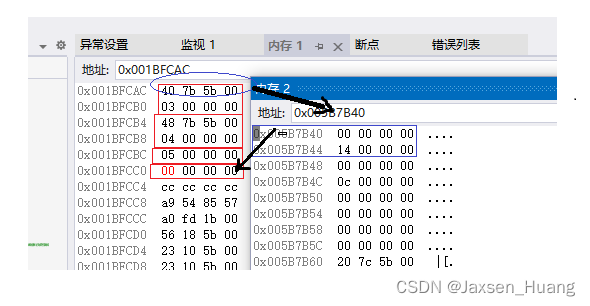
可以看到在加了virtual虚继承之后原本存放冗余数据的地方存放了一个地址,而这个地址表示的就是该冗余数据的值,并且是通过记录偏移量取寻找的这里的偏移量是0x00000014
组合和继承的对比
/*继承和组合的区别*/
//继承
class A
{
public:
void func()
{
}
protected:
int _a;
};
class B:public A
{
public:
void fun()
{
}
protected:
int _b;
};
//组合
class C
{
public:
void func()
{
}
protected:
int _c;
};
class D
{
protected:
C _c;
int _d;
};
void Test4()
{
B b;
D d;
cout << sizeof(b) << endl;
cout << sizeof(d) << endl;//大小一致
}
int main()
{
Test4();
return 0;
}
继承允许你根据基类的实现来定义派生类的实现。这种通过生成派生类的复用通常被称为白箱复用(white-box reuse)。术语“白箱”是相对可视性而言:在继承方式中,基类的内部细节对子类可见 。继承一定程度破坏了基类的封装,基类的改变,对派生类有很大的影响。派生类和基类间的依赖关系很强,耦合度高。
对象组合是类继承之外的另一种复用选择。新的更复杂的功能可以通过组装或组合对象来获得。对象组合要求被组合的对象具有良好定义的接口。这种复用风格被称为黑箱复用(black-box reuse),因为对象的内部细节是不可见的。对象只以“黑箱”的形式出现。
组合类之间没有很强的依赖关系,耦合度低。优先使用对象组合有助于你保持每个类被封装。实际尽量多去用组合。组合的耦合度低,代码维护性好。不过继承也有用武之地的,有些关系就适合继承那就用继承,另外要实现多态,也必须要继承。类之间的关系可以用继承,可以用组合,就用组合。
public继承是一种is-a的关系。也就是说每个派生类对象都是一个基类对象。
组合是一种has-a的关系。假设B组合了A,每个B对象中都有一个A对象。
对于继承和组合的选择,看是is-a的关系还是has-a的关系,但是尽量用组合















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









