







判断文件属性
查看文件位数,以及是否有壳
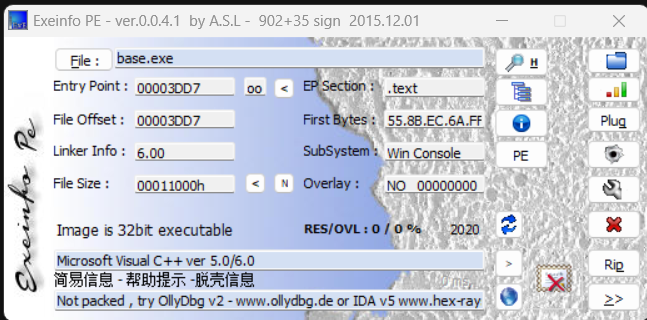
无壳,32位,用32位ida打开
分析main函数
分析main函数代码如下
int __cdecl main(int argc, const char **argv, const char **envp)
{
int v3; // esi
int v5[3]; // [esp+8h] [ebp-74h] BYREF
__int16 v6; // [esp+14h] [ebp-68h]
char v7; // [esp+16h] [ebp-66h]
char v8[100]; // [esp+18h] [ebp-64h] BYREF
sub_403CF8(&unk_40E140);
scanf("%s", v8);
memset(v5, 0, sizeof(v5));
v6 = 0;
v7 = 0;
sub_401080(v8, strlen(v8), v5); // v8通过sub_401080函数加密并赋值到v5
v3 = 0;
while ( *(v5 + v3) == aZmxhz3tignxlxj[v3] ) // v5+v3与aZmxhz3tignxlxj的第v3位进行比较
{
if ( ++v3 > strlen(v5) )
goto LABEL_6; // 要跳转到label_6否则会按顺序执行sub_403cf8函数,该函数会输出error
}
sub_403CF8(aError); // 输出error!
LABEL_6:
if ( v3 - 1 == strlen(aZmxhz3tignxlxj) )
return sub_403CF8(aAreYouHappyYes); // 输出Are you happy?yes!,表示输入的flag正确
else
return sub_403CF8(aAreYouHappyNo); // 输出Are you happy?No!,表示输出的flag错误
}main函数中一个关键点是sub_401080函数将输入的v8进行加密,并且赋值到v5,然后将v5进行运算其结果要等于aZmxhz3tignxlxj,只需要分析sub_401080是如何加密输入值的,写出解密代码,将aZmxhz3tignxlxj解密即可。
查看sub_401080函数
sub_401080函数调用了两个函数,一个是sub_401000函数,一个是sub_401030函数,中间的那一部分代码又长又难看,先不看,看看两个函数再说
分析sub_401000函数
void sub_401000()
{
int i; // eax
char v1; // cl
for ( i = 6; i < 15; ++i )
{
v1 = aAbcdefghijklmn[i + 10];
aAbcdefghijklmn[i + 10] = aAbcdefghijklmn[i];
aAbcdefghijklmn[i] = v1;
}
}该函数主要是将aAbcdefghijklmn变量的字符进行一种变化,aAbcdefghijklmn的值是 ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/
这个其实是base64的编码表
写出python相应的脚本
outside=list("ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/")
for i in range(6,15):
v1=outside[i+10]
outside[i+10]=outside[i]
outside[i]=v1
print("".join(outside))分析sub_401030函数
int __cdecl sub_401030(const char *a1)
{
__int64 v1; // rax
char v2; // al
v1 = 0i64;
if ( strlen(a1) )
{
do
{
v2 = a1[HIDWORD(v1)];
if ( v2 < 97 || v2 > 122 )
{
if ( v2 < 65 || v2 > 90 )
goto LABEL_9;
LOBYTE(v1) = v2 + 32;
}
else
{
LOBYTE(v1) = v2 - 32;
}
a1[HIDWORD(v1)] = v1;
LABEL_9:
LODWORD(v1) = 0;
++HIDWORD(v1);
}
while ( HIDWORD(v1) < strlen(a1) );
}
return v1;
}这个内容没啥好说的,学c语言的时候,应该都写过大小写转换的程序,一步步跟进参数,就可以看出来是对输入值的base编码之后的内容进行小写转换
关于中间的那一部分又长又丑的代码,看不懂,但是可以猜出来是进行base编码的程序,大胆尝试
总结
正向:输入->base64转换->大小写转换=zMXHz3TIgnxLxJhFAdtZn2fFk3lYCrtPC2l9=flag
逆向:zMXHz3TIgnxLxJhFAdtZn2fFk3lYCrtPC2l9->大小写转换->base转换=flag
其中base64需要换表,并且这个表在sub_401000进行了一些变换,需要拿到sub_401000变换后的编码表,也就是说先逆向sub_401000程序
总体解密代码
import base64
import string
aZmxhz3tignxlxj="zMXHz3TIgnxLxJhFAdtZn2fFk3lYCrtPC2l9".swapcase() #大小写转换
print(aZmxhz3tignxlxj)
#base表变换
outside=list("ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/")
for i in range(6,15):
v1=outside[i+10]
outside[i+10]=outside[i]
outside[i]=v1
print("".join(outside))
str1="".join(outside)
# base解码
string2 = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/"
print(base64.b64decode(aZmxhz3tignxlxj.translate(str.maketrans(str1, string2))))














 536
536











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









