






前言
本文主要记录[ACTF新生赛2020]usualCrypt和[MRCTF2020]Xor的做题过程和相关思路
[ACTF新生赛2020]usualCrypt
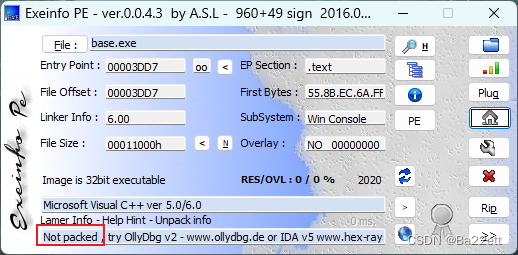
下载,解压,查壳,发现无壳
用IDA打开,查看字符串,发现有线索
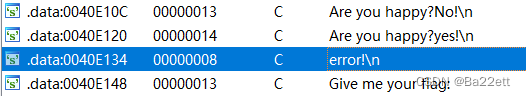
查找引用,找到main函数,发现调用了sub_401080函数
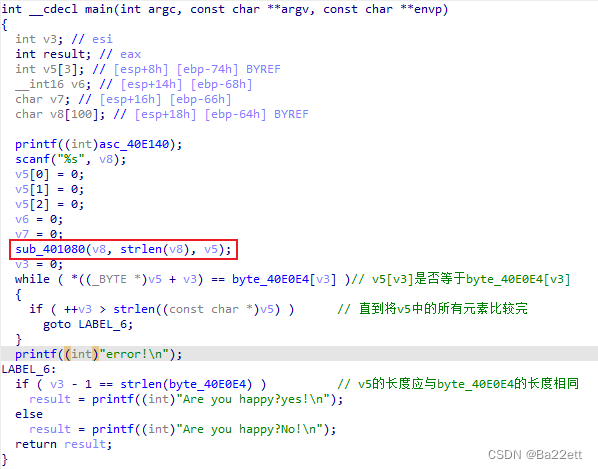
进入sub_401080函数

发现其主要用到的是byte_40E0A0数组,点击查看数组元素,像是base64的编码表,并且在函数中也能看到是以3为单位来进行计算,而base64根据三个以八位表示的字符构成的3 * 8bit = 24bit转为 24bit = 4 * 6bit 四个以六位表示的字符,再根据这 6bit 所表示的属于 [0,63] 的数字为下标查找编码表,从而将原本的三个字符编码成四个可见字符,所以猜测sub_401080函数的作用是进行base64编码,但该函数还调用了sub_401000函数和sub_401030函数
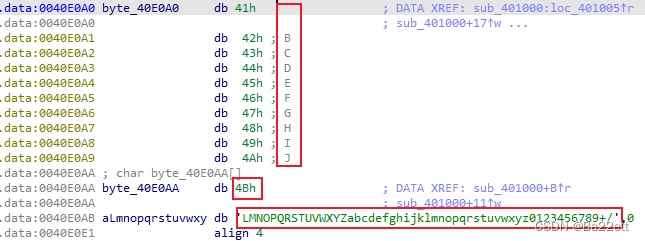
sub_401000函数
该函数以第六位开始,交换byte_40E0AA数组与byte_40E0A0数组的元素
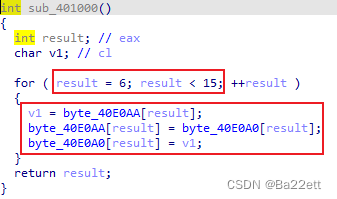
虽然看到byte_40E0A0数组的长度为10,但是这两个数组存放的地址是连续的,当取到byte_40E0A0[11]时,也就是取到了byte_40E0AA[1],也就是L
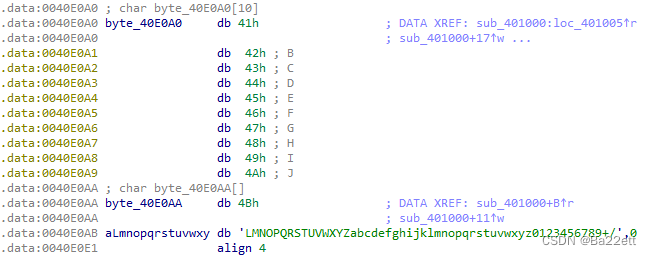
而当这个函数执行完后,base64的编码表就被修改为
ABCDEFQRSTUVWXYPGHIJKLMNOZabcdefghijklmnopqrstuvwxyz0123456789+/
sub_401030函数
该函数的作用是进行大小写转换

最后再将大小写转换后的结果与byte_40E0E4进行比较

所以,逆向的思路是先将上面这段字符串进行大小写转换,再使用修改后的base64编码表进行解码
import base64
byte_40E0E4 = [c for c in "zMXHz3TIgnxLxJhFAdtZn2fFk3lYCrtPC2l9"] # 开头别漏了 7Ah
for i in range(len(byte_40E0E4)): # 进行大小写转换
if 65 <= ord(byte_40E0E4[i]) <= 90:
byte_40E0E4[i] = chr(ord(byte_40E0E4[i]) + 32)
elif 97 <= ord(byte_40E0E4[i]) <= 122:
byte_40E0E4[i] = chr(ord(byte_40E0E4[i]) - 32)
data = "".join(byte_40E0E4)
STANDARD_ALPHABET = b'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/'
CUSTOM_ALPHABET = b'ABCDEFQRSTUVWXYPGHIJKLMNOZabcdefghijklmnopqrstuvwxyz0123456789+/'
DECODE_TRANS = bytes.maketrans(CUSTOM_ALPHABET, STANDARD_ALPHABET) # 使用修改的编码表
print(base64.b64decode(data.encode().translate(DECODE_TRANS)).decode()) # flag{bAse64_h2s_a_Surprise}
[MRCTF2020]Xor
下载解压,查壳,发现无壳
使用IDA打开,但是却不能反汇编出代码,只能看汇编代码,首先看要达到的目标是在左下角,即每次的判断指令都需要为False(走红线)
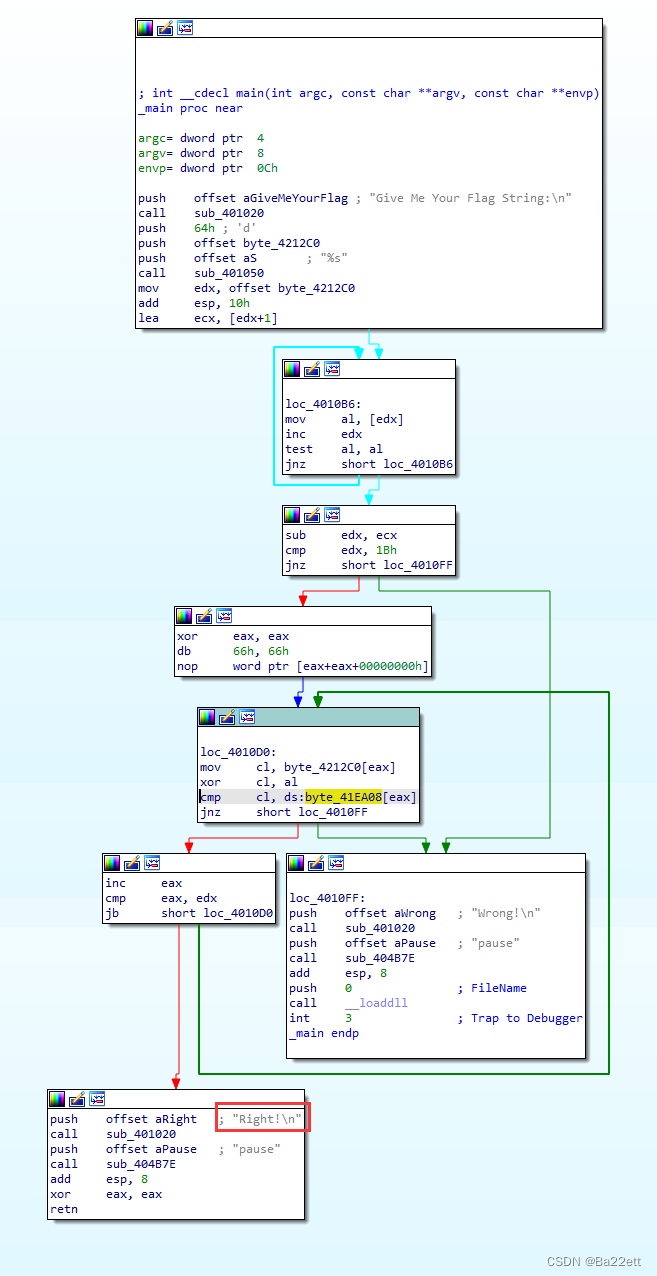
首先看上面的部分

再看下面的部分
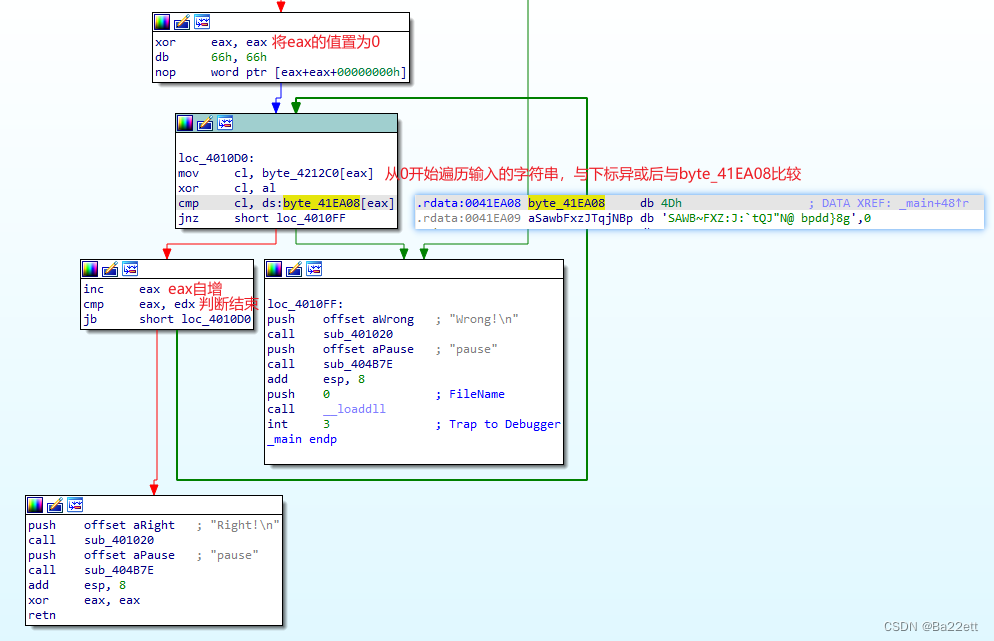
写脚本运算 别漏了4Dh
byte_41EA08 = "MSAWB~FXZ:J:`tQJ\"N@ bpdd}8g" # 注意要加转义符
tmp = []
for i in range(len(byte_41EA08)):
tmp.append(ord(byte_41EA08[i]))
flag = []
for i in range(len(tmp)):
flag.append(tmp[i] ^ i)
for i in flag:
print(chr(i), end="") # MRCTF{@_R3@1ly_E2_R3verse!}















 536
536











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









