







一些要点
1.在kronos数据字典中,VP开头的都是视图;
2.在kronos上能够看到的关于人员的id在数据库表中都是NUM后缀结尾的;
3.DELETEDSW:
这个字段在很多表中都存在,
例如:
SHIFTASSIGNMNT(班次分配表),TIMESHEETITEM(考勤明细表),PUNCHEVENT(打卡记录表)等等;
其意思代表了某个人员在某些表中的信息是否存在或者代表某些表中的信息是否还存在,其使用的值常为两个,一个是0表示还存在,没被删除,另一个是1表示不存在,已经被删除了。
例如在SHIFTASSIGNMNT(班次分配表)中,这个表示:
该班次是否已经被编辑或者被取代
但是只在下面8个视图中存在,如下:
VP_DAILYSCHEDULE(每日计划视图):
下面七个使用比较少:
RPTSP_CoverageWeeklyjo RPTSP_MonthlyLaborAcctSched
RPTSP_OnCall RPTSP_OpenShiftMonthlyJo
RPTSP_OpenShiftWeeklyJo RPTSP_WeeklyLaborAccountSched
RPTSP_WeeklyLocScheduleDetail
语句工具
1.查询对象名的类型
如何验证一个对象名是属于表还是视图或者存储过程?
1.查询存储所有对象的系统表sys.all_objects;
2.在系统表中有一个字段是type,这个列表明这个对象的类型。
3.查找出type值,然后查看其代表的类型。
type值对应的字母及其含义:
AF =聚合函数(CLR)
C =校验约束
D = DEFAULT(约束或独立)
外键约束
FN = SQL标量函数
FS = Assembly (CLR)标量函数
FT = Assembly (CLR)表值函数
IF = SQL内联表值函数
IT =内部表
P = SQL存储过程
PC =汇编(CLR)存储过程
PG =计划指南
PK =主键约束
R =规则(旧式,独立)
射频= Replication-filter-procedure
S =系统基表
SN =同义词
服务队列
TA = Assembly (CLR) DML触发器
TF = SQL表值函数
TR = SQL DML触发器
U =表(用户定义)
UQ =唯一约束
V =视图
X =扩展存储过程
语句如下:
SELECT * FROM sys.all_objects
WHERE name='表名';
--这个是查询带information_shcema的表或者视图
select TYPE from sys.all_objects where name = 'SCHEMATA' and schema_id = SCHEMA_ID('INFORMATION_SCHEMA')
2.查询某个表是否含有某个字段
方法一:
查询视图syscolumns
/*
1.查询的是系统视图syscolumns
2.条件是要查询的表名
*/
SELECT NAME
FROM
(
SELECT SYS.name FROM SYSCOLUMNS AS SYS WHERE ID=OBJECT_ID('要查询的表名')
) AS A
WHERE A.NAME='要查询的字段';
--使用with as
WITH COLUMNNAME AS
(
SELECT SYS.name AS NAME FROM SYSCOLUMNS AS SYS WHERE ID=OBJECT_ID('要查询的表名')
)SELECT NAME FROM COLUMNNAME WHERE NAME='要查询的字段';
方法二:
查询视图information_schema.columns
SELECT COLUMN_NAME
FROM
(
SELECT T.COLUMN_NAME FROM INFORMATION_SCHEMA.COLUMNS T WHERE T.TABLE_NAME='要查询的表名'
) AS B
WHERE B.COLUMN_NAME='要查询的字段名';
--使用with as
WITH COLUMNNAME AS
(
SELECT COLUMN_NAME FROM INFORMATION_SCHEMA.COLUMNS WHERE TABLE_NAME='要查询的表名'
)SELECT COLUMN_NAME FROM COLUMNNAME WHERE COLUMN_NAME='要查询的字段名';
3.查询两个视图或者表相同字段
SELECT A.NAME AS N'相同的字段' FROM
(SELECT SYS.NAME FROM SYSCOLUMNS AS SYS WHERE ID=OBJECT_ID('表1')) AS A,
(SELECT SYS.NAME FROM SYSCOLUMNS AS SYS WHERE ID=OBJECT_ID('表2')) AS B
WHERE A.NAME=B.NAME;
--使用with as
WITH TABLE1 AS
(
SELECT SYS.NAME FROM SYSCOLUMNS AS SYS WHERE ID=OBJECT_ID('表1')
),
TABLE2 AS
(
SELECT SYS.NAME FROM SYSCOLUMNS AS SYS WHERE ID=OBJECT_ID('表2')
)
SELECT T1.NAME FROM TABLE1 T1,TABLE2 T2 WHERE T1.NAME=T2.NAME;
参考:
sqlserver数据库中系统视图INFORMATION_SCHEMA.SCHEMATA在哪里?
4.根据列名查询表名
SELECT A.NAME AS N'列名',B.NAME AS N'表名'
FROM SYSCOLUMNS A,SYSOBJECTS B
WHERE A.ID=B.ID AND A.NAME='HOMEZIP';
--以上使用逗号就是相当于inner join连接。
5.根据某个值查询列名和所在表
这个方法,当数据库中的数据较多的时候,查询速度较慢,还有一点就是使用到了游标。。。。游标其实也会拖慢速度的。。。。。
太慢了,没啥用,等以后自己想办法写一个。。。
SQLSERVER查询整个数据库中某个特定值所在的表和字段的方法
该方法使用到了系统视图syscolumns,其中xtype字段值数字代表的含义为:
xtype 类型
34 image
35 text
36 uniqueidentifier
48 tinyint
52 smallint
56 int
58 smalldatetime
59 real
60 money
61 datetime
62 float
98 sql_variant
99 ntext
104 bit
106 decimal
108 numeric
122 smallmoney
127 bigint
165 varbinary
167 varchar
173 binary
175 char
189 timestamp
231 sysname
231 nvarchar
239 nchar
6.根据视图查询其创建的语句
sp_helptext '视图名'
字段和表意思
一些字段,选择在本地创建了一个库和两个表。来实现其查找每个字段和表意思的效果。
这里记录一下信息:
创建的库为:kronosDB
两个表:
一个是kronosTOrV:关于一些表或者视图的意思;
一个是kronosColumns:关于一些字段的意思。
创表语句以及意思:
create table kronosTOrV ---表或者视图
(
ktv_id int identity(1,1), ---索引
ktv_name varchar(100) not null, ---表或者视图的英文名字
ktv_desc text null, ---中文描述内容
ktv_type varchar(20) null ---是表还是视图
)
create table kronosColumns ---字段
(
kc_id int identity(1,1), ---索引
kc_name varchar(100) not null, ---字段英文名字
kc_desc text not null ---字段描述内容
)
注意:
在kronosTOrV表中,插入的数据如果是小写的说明是表,大写带VP的就是视图
sql语法
1.insert into 和select into
insert into和select into都是将某个表的字段数据copy在另一表中。
insert into from的语法形式为:
Insert into Table2(field1,field2,…) select value1,value2,… from Table1
将Table1的列数据插入到Table2中。
其实这个语句就是两个语句的组合体。。。。
首先是查询出一个表的数据:
select column1,column2,… from table1;
然后将table1的数据插入到table2中。
特点:
1.其中被插入数据的表必须要存在;
2.两个表中列的数据结构可以不一样,没有关系,只是将一个表的数据copy到另一个表中而已;但是,其两个表插入的时候列的个数必须要一样!
3.可以插入常量;
select into from的语法形式为:
SELECT vale1, value2 into Table2 from Table1
将一个表Table1的数据插入另一个表Table2 中;
特点
1.被插入数据的表必须不存在;要是存在还没运行就会报错;
2.除了数据一样之外,其数据结构是一样的,因为是将一个表的数据和结构全部都copy到另一个表中;
参考:
SELECT INTO 和 INSERT INTO SELECT 两种表复制语句
2.union和union all
union和union all都是合并两个或多个 SELECT 语句的结果集。union all允许重复值。
要注意的点:
合并表中的列的个数、数据类型必须相同或相兼容
参考:
https://www.cnblogs.com/ankeyliu/p/11340381.html
3.with as
什么是with as?
with as 也叫做子查询部分,可以定义为一个片段,该片段会被整个sql使用,也可以在union部分作为数据的不同部分,作为提供数据的部分。
如果作为片段被调用2次以上,优化器会自动将该WITH AS短语所获取的数据放入一个Temp表中。而提示meterialize则是强制将WITH AS短语的数据放入一个全局临时表中。很多查询通过该方式都可以提高速度。
以下为一个例子,其中表就是一个students,如下:
with ss as
(
select student_name from students where student_name like N'张%'
)select * from students where student_name in (select * from ss);
为什么要使用with as?
很多时候需要用到子查询,但是子查询会可能出现嵌套过多的情况,这样会导致难以维护和阅读;那么可以使用变量的方式来代替子查询。但是变量会损耗性能,所以当数据多的时候查询就会变慢。
这个时候with as就应运而生了,在SQL Server 2005中出来的公用表表达式(CTE)
语法如下:
[ WITH <common_table_expression> [ ,n ] ]
<common_table_expression>::=
expression_name [ ( column_name [ ,n ] ) ]
AS
( CTE_query_definition )
使用with as的注意点:
引用自:SqlServer_with_as的使用
- CTE后面必须直接跟使用CTE的SQL语句(如select、insert、update等),否则,CTE将失效。
- CTE后面也可以跟其他的CTE,但只能使用一个with,多个CTE中间用逗号(,)分隔
- 如果CTE的表达式名称与某个数据表或视图重名,则紧跟在该CTE后面的SQL语句使用的仍然是CTE,当然,后面的SQL语句使用的就是数据表或视图了
- CTE 可以引用自身,也可以引用在同一 WITH 子句中预先定义的 CTE。
其他详细参考:
SQL Server中With As的介绍与应用(一)–With As的介绍
4.over之聚合,排序函数
over函数,在实际的操作中,用于为查询出来的行数据集合添加一个列,以便进行特定的运算。
所谓特定的运算就是:
over函数能够为聚合和排序函数多出来一个列,这个列中是行数据的集合,这个集合又叫作函数据的窗口,因而又为开窗函数。
也就是给聚合和排序函数多出来了一个运算的窗口。
当然还是需要自己写个小例子才更好理解。
准备条件
创建一个表,并且插入数据,如下:
create table test_over_01(
a int,
b int,
c char
)
insert into test_over_01 values(1,3,'E')
insert into test_over_01 values(2,4,'A')
INSERT INTO test_over_01 VALUES(3,5,'B')
INSERT INTO test_over_01 VALUES(4,2,'C')
INSERT INTO test_over_01 VALUES(2,4,'B')
INSERT INTO test_over_01 VALUES(4,5,'F')
INSERT INTO test_over_01 VALUES(4,6,'G')
insert into test_over_01 values(3,2,'D')
insert into test_over_01 values(3,5,'G');
--查询所有
select * from test_over_01;
并且看是否插入成功,查询出来的数据如下:

使用聚合函数
1.求总记录数
select a,b,c,COUNT(*) over() as N'全部有的数量为'
from test_over_01;

2.求最小值
select a,b,c,min(b) over() as N'最小值为'
from test_over_01;
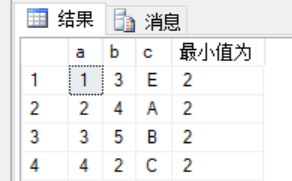
3.求最大值
select a,b,c,max(b) over() as N'最大值为'
from test_over_01;
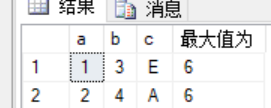
4.求平均值
select a,b,c,AVG(b) over() as N'平均值为'
from test_over_01;
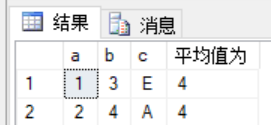
5.求和
select a,b,c,sum(b) over() as N'平均值为'
from test_over_01;
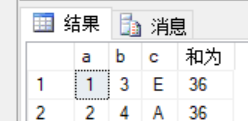
使用排序函数
在sqlserver2005中新添加了四个排序函数,其分别是:
rank(),desn_rank(),row_number(),ntile()
其中ntile()这个函数作用是分组的,但是不知道为啥网上我看到的博文里全都说是排序函数。。。。。
有一点倒是对的,那就是这个函数是跟着over函数一起使用的。
在over函数中,其格式一般为:
排序函数(),over(partition by [分组列] order by [排序列])
除此之外,使用over()函数,其括号里面必须要排序,也就是必须要使用到order by,如果不使用运行报如下错:

如果不指定其分组的列,也就是不使用partition by的时候,就会将整个查询出来的结果集作为一个分组
ntile函数
根据上面准备的条件,看一个小例子:
select a,b,c,NTILE(4) over(order by b desc) as N'ntile函数分组'
from test_over_01;
这个函数查询的是以b字段降序为排序
其查询出来的结果如下:
这个函数定义按照自己的理解如下:

从这个语句中中可以看出:
这是一个分组函数,根据括号中设置的数字,继而分为几组, 每一组中的每一行编号都是由其从1开始所属组的编号;这个分组的个数是自己设置括号中的数字,
但是分组中的数量是有两个约定确定的,如下:
ps:每一组又叫做桶,分组的个数又被叫做桶数
1.编号小的分组中的数量需要大于或者等于编号大的分组数量;
2.所有桶的数量要么都相同,要么从一个较小的桶开始桶数相同。
例如这里的9个数据,分为4桶,那么根据第一点的原因,我们不能分为2,2,2,3,
也不能分为3,2,2,1;而是只能分为3,2,2,2。
row_number函数
select a,b,c,ROW_NUMBER() over(order by b desc) as N'row_number()函数'
from test_over_01;
其查询结果为:

所以使用row_number函数当其列值相等的时候,并不会将相等的列并列为一个序号,而是正常排序
rank函数和dense_rank函数
这两个函数的例子一起使用,更加能够看出区别,如下:
--整个结果集是个分组,以b进行排名,rank函数返回每行的排名,
select a,b,c,RANK() over(order by b desc) as N'rank()函数'
from test_over_01;
--整个结果集是个分组,以b进行排名,dense_rank函数返回每行的排名,
select a,b,c,dense_rank() over(order by b desc) as N'dense_rank()函数'
from test_over_01;

所以根据这个小例子,得出的如下:
rank函数如果碰到列的大小相同的时候,其序号是并列为一样的序号。
当计算并列序列号后一位序号的时候,在其并列序号基础上根据并列的数量进行递增。
rank函数碰到列的大小相同的时候序号也是并列为一样的序号,
但是计算后一个序号并不会随着并列数量进行递增。而是按照并列值加一递增。
参考:
SQL2005四个排名函数(row_number、rank、dense_rank和ntile)的比较
Sql 四大排名函数(ROW_NUMBER、RANK、DENSE_RANK、NTILE)简介
https://q.cnblogs.com/q/69015/
分页
一般而言,在web程序中一般使用over加row_number函数实现分页。之所以使用row_number函数进行排序,而不是用rank和dense_rank函数,是因为row_number函数是忽略了列名的值是否相等的,为每一行都赋予一个并不会重复的序号,这一点在上面也很好的诠释了;
下面是一个小例子:
with testSection as
(
select ROW_NUMBER() over(order by b asc) as row_num,* from test_over_01
)
select * from testSection where row_num between 1 and 3 order by b asc;
查询出来,如下:
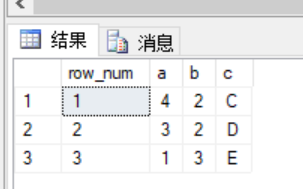
注意:
上面的语句中有两个地方进行了排序,一个是over函数中,另一个是对表的排序,其排序的字段需要保持一致,如果不一样的话,会导致over实现排序的序号显示出来混乱。
如下所示:

上面本来应该按照升序显示1,2,3的,但是实际显示的是3,2,1。所以应该让over中的排序和整个语句中某列的排序保持一致。
参考:
Sql 四大排名函数(ROW_NUMBER、RANK、DENSE_RANK、NTILE)简介
5.sqlserver没有自然连接
sqlserver是莫得自然连接的。。。。
我查找了好一会才发现是没有自然连接的。。。。。并且在sqlserver中其natural都不是关键字。。。。
下面这个博文是解决的一种方式:
SQL server 等值连接与自然连接,解决自然连接去掉重复列的问题
6.控制流语言
begin end
这是一个类似于Java中的大括号,也就是这个{ }的语句,其直译过来就是开始结束。。。。
BEGIN 和 END 语句用于下列情况:
WHILE 循环需要包含语句块。
CASE 表达式的元素需要包含语句块。
IF 或 ELSE 子句需要包含语句块。
注意:
1.在控制流语句必须执行包含两条或多条 Transact-SQL 语句的语句块的任何地方,都可以使用 BEGIN 和 END 语句。
2.BEGIN 语句单独出现在一行中,后跟 Transact-SQL 语句块。最后,END 语句单独出现在一行中,指示语句块的结束
还有一点:
没有begin end的时候,每一条update语句都需要写一次硬盘。有了begin end之后,数据库就不会自动commit了,只会当所有update完成之后,进行一次commit,也就是只写一次硬盘,速度肯定要比频繁写硬盘快很多。
https://www.zhihu.com/question/52126149
sql文档:
break
https://docs.microsoft.com/zh-cn/previous-versions/sql/sql-server-2008-r2/ms181271(v=sql.105)
跳出while或者if else语句最里面的循环。将执行出现在 END 关键字后面的任何语句,END 关键字为循环结束标记。
contiue
https://docs.microsoft.com/zh-cn/previous-versions/sql/sql-server-2008-r2/ms174366(v=sql.105)
重新开始 WHILE 循环。在 CONTINUE 关键字之后的任何语句都将被忽略。
goto
https://docs.microsoft.com/zh-cn/previous-versions/sql/sql-server-2008-r2/ms180188(v=sql.105)
如果 GOTO 语句指向该标签,则其为处理的起点。标签必须符合标识符规则。无论是否使用 GOTO 语句,标签均可作为注释方法使用。
GOTO 可出现在条件控制流语句、语句块或过程中,但它不能跳转到该批以外的标签。GOTO 分支可跳转到定义在 GOTO 之前或之后的标签。
if else
https://docs.microsoft.com/zh-cn/previous-versions/sql/sql-server-2008-r2/ms182717(v=sql.105)
任何 Transact-SQL 语句或用语句块定义的语句分组。除非使用语句块,否则 IF 或 ELSE 条件只能影响一个 Transact-SQL 语句的性能。
若要定义语句块,请使用控制流关键字 BEGIN 和 END。
return
https://docs.microsoft.com/zh-cn/previous-versions/sql/sql-server-2008-r2/ms174998(v=sql.105)
从查询或过程中无条件退出。RETURN 的执行是即时且完全的,可在任何时候用于从过程、批处理或语句块中退出。RETURN 之后的语句是不执行的。
返回类型:
可以选择返回int
但是有一点注意了:
除非另外说明,否则所有系统存储过程都将返回一个 0 值。此值表示成功,非 0 值表示失败
如果用于存储过程,RETURN 不能返回 null 值。
如果某个过程试图返回空值(例如,使用 RETURN @status,而 @status 为 NULL),则将生成警告消息并返回 0 值。
在执行了当前过程的批处理或过程中,可以在后续的 Transact-SQL 语句中包含返回状态值,但必须以下列格式输入:EXECUTE @return_status = <procedure_name>。
while
https://docs.microsoft.com/zh-cn/previous-versions/sql/sql-server-2008-r2/ms178642(v=sql.105)
设置重复执行 SQL 语句或语句块的条件。只要指定的条件为真,就重复执行语句。可以使用 BREAK 和 CONTINUE 关键字在循环内部控制 WHILE 循环中语句的执行。
注意点:
如果嵌套了两个或多个 WHILE 循环,则内层的 BREAK
将退出到下一个外层循环。将首先运行内层循环结束之后的所有语句,然后重新开始下一个外层循环。
7.[]方括号的意思
1.为了防止某些关键字在使用中引起歧义,如果加上中括号,则代表这是一个字段名,而不是关键字。
2.解决较长的中文名表名可能会被不识别的问题
8.case…when…then
https://docs.microsoft.com/zh-cn/previous-versions/sql/sql-server-2008/ms189074(v=sql.100)
CASE 表达式用于计算多个条件并为每个条件返回单个值。例如,它允许按列值显示可选值。数据中的更改是临时的,因此不存在对数据的永久更改。
https://docs.microsoft.com/zh-cn/previous-versions/sql/sql-server-2008/ms181765(v=sql.100)
有两种形式,一种是简单表达式,另一种是搜索表达式;
下面这个是简单表达式:
USE AdventureWorks;
GO
SELECT ProductNumber, Category =
CASE ProductLine
WHEN 'R' THEN 'Road'
WHEN 'M' THEN 'Mountain'
WHEN 'T' THEN 'Touring'
WHEN 'S' THEN 'Other sale items'
ELSE 'Not for sale'
END,
Name
FROM Production.Product
ORDER BY ProductNumber;
GO
这个是分类表达式
SELECT ProductNumber, Name, 'Price Range' =
CASE
WHEN ListPrice = 0 THEN 'Mfg item - not for resale'
WHEN ListPrice < 50 THEN 'Under $50'
WHEN ListPrice >= 50 and ListPrice < 250 THEN 'Under $250'
WHEN ListPrice >= 250 and ListPrice < 1000 THEN 'Under $1000'
ELSE 'Over $1000'
END
FROM Production.Product
ORDER BY ProductNumber ;
9.函数
参考:
w3cschool















 455
455











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









