







Python学习笔记05#文件操作
目录
一、文件内建函数(open()和file())
open(file,mode=‘r’):打开\创建文件
file是路径,如:'E:\\文件夹\\文档.txt'
mode是读写模式,如:'r'
注意这里要加引号
open()和file()具有相同的功能,可以任意替换
| 访问模式 | 说明 |
|---|---|
| r | 以只读方式打开文件。文件的指针将会放在文件的开头。这是默认模式。 |
| w | 打开一个文件只用于写入。如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件。 |
| a | 打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
| r+ | 打开一个文件用于读写。文件指针将会放在文件的开头。 |
| w+ | 打开一个文件用于读写。如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件。 |
| a+ | 打开一个文件用于读写,如果该文件已存在,文件指针将会放在文件的结尾。文件打开时会是追加模式。如果改文件不存在,创建新文件用于读写。 |
| rb | 以二进制格式打开一个文件用于只读。文件指针将会放在文件的开头。这是默认模式。 |
| wb | 以二进制格式打开一个文件只用于写入。如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件。 |
| ab | 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
| rb+ | 以二进制格式打开一个文件用于读写。文件指针将会放在文件的开头 |
| wb+ | 以二进制格式打开一个文件用于读写。如果改文件已存在则会覆盖。如果改文件不存在,创建新文件。 |
| ab+ | 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。如果改文件不存在,创建新文件用于读写。 |
简单使用示例:
fp = open('test','w')
二、文件内建方法(f.xxx之类的)(详见python核心编程P219)
注意这里的输入输出和open里的读和写的对应关系,我们常识中的输入似乎和写有关,但其实是输入对应读,输出对应写。我是这么理解的:读和写的访问模式是相对于操作者来说的,即我们在读和写,而输入输出是文件的方法,是对于文件这个对象来说的,文件输入进来就是读取,文件输出出去就是写出
- 输入
f.read():读取整个文件,以字符串显示
f.readline():一次读一行。运行后指针在该行末尾
f.readlines():一行一行读取,读取整个文件,以列表显示
f.strip():用于移除字符串头尾指定字符,默认空格或换行符
f.seek(0,0):挪动指针。第一个参数是偏移量,第二个参数0表示指针在文件开始处(默认值),1表示当前位置,2表示文件结尾 - 输出
f.write()
三、文件内建属性
四、pandas模块
pandas有个重要的数据结构:数据框(每列表示一个变量,每行表示一条记录),相当于一个二维列表
4.1 pandas读取txt文件(想把列表形式的txt以列表形式读取出来)
pandas.read_table()
data = pandas.read_table(file,sep='\t',head=None,encoding='utf-8',names=['col1','col2'])
file:路径
sep:分隔符
head:表头,默认=0(以第一行作为表头)。取None无表头
encoding:编码模式
names:每列的变量名
4.2 pandas读取csv文件
pandas.read_csv()
data = pandas.read_table(file,sep=',',head=None,encoding='utf-8',names=['col1','col2'])
4.3 pandas读取excel文件
pandas.read_execel()
data = pandas.read_execel(file,sep=',',head=None,encoding='utf-8',names=['col1','col2'])
不难发现,这几个读取语句的内置参数其实只有sep存在区别,依据这个规律,我们可以得到pandas写出的一般形式
4.4 pandas数据写出
data.to_csv(file,sep=',',header =None,encoding='utf-8',index =False)
以上是将csv文件输出,类比将csv和sep=?进行相应的替换就能得到excel和txt的写出方法。注意这里index是索引,默认为True,会导致输出的结果含索引值,这往往是我们不需要的。
4.5 pandas常用数据处理技巧
(1)构造数据框
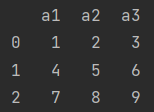
a. 字典强转a =pandas.DataFrame({'a1':[1,2,3],'a2':[4,5,6],'a3':[7,8,9]})
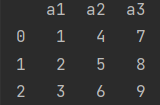
b. 列表\元组转换a =pandas.DataFrame([[1,2,3],[4,5,6],[7,8,9]],columns=['a1','a2','a3'])
(区别就是一个表内元素可变,一个不可变)
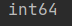
(2)查看指定列的数据类型
:a.a1.dtypes
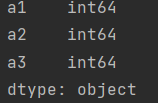
如果不指定某列,会显示所有列的数据类型
(3)数据框列属性转换
:a.a1 =a.a1.astype(float)
(4)列重命名
将列a1的名字改为b1:a =a.rename(columns={'a1':'b1'})
(5)数据选取
a. 选取数据前n行
取前2行 :a.head(2)
b. 通过索引
取前2行:a[0:2]
c. 通过列名选取
选择a1,a2列:a[['a1','a2']]
d.
五、os模块
5.1 为什么选择os模块
os模块提供了多数操作系统的功能接口函数。当os模块被导入后,它会自适应于不同的操作系统平台,根据不同的平台进行相应的操作
5.2 常用命令(path只有一个名字没有路径,默认在当前目录操作)
os.mkdir(path)——创建path指定的文件夹os.rmdir(path)——删除path指定的空文件夹
想要删除非空文件夹要用到shutil库
import shutil
shutil.rmtree('path')
os.remove(path)——删除path指定的文件os.chdir(path)——改变当前工作目录到指定目录















 2521
2521











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









