







1 面向对象的三大特征:封装,继承.多态
封装:彼此相关数据和操作包围起来,抽象成为一个对象,想要访问对象的数据只能通过已定义的接口。封装不仅仅实现了数据的保护,还把彼此相关联的变量和函数包围了起来。
继承:子类继承父类的字段属性方法,Java这支持单继承
多态:
多态存在的3个条件:1)继承;2)重写;3)父类引用指向子类对象。
对于同一个行为,不同的子类对象具有不同的表现形式
2 修饰符public,protected,不写(default),private的区别

3 = 与 =+的区别
@Test
public void a17(){
short a =1;
a = a + 1; // 报错 因为a为short类型, int = short + int 不兼容的类型: 从int转换到short可能会有损失
a +=1;// 相当于 a = (short) a + 1
a = (short) (a + 1);
}4 八大基本类型
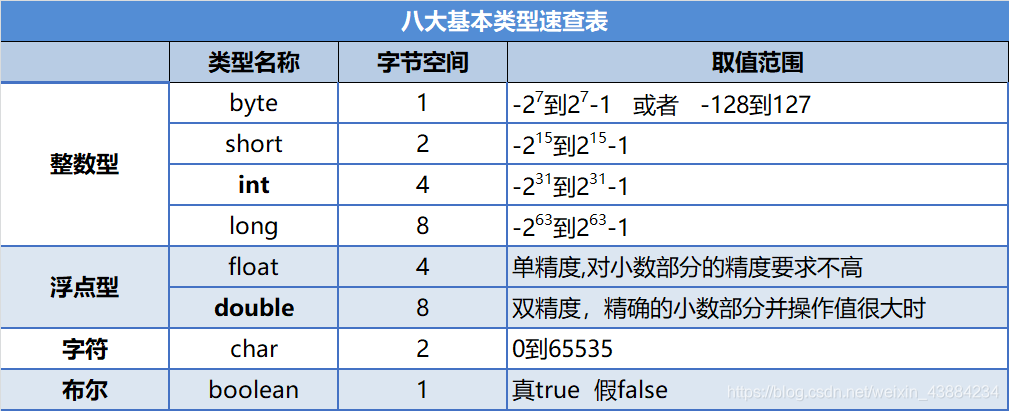
5 基本类型的字面值
整数的字面值为int :
@Test
public void a18(){
int a = 100;
int b = 9999999999999999999;//报错 右面的数据字面值是double,float是4字节存不下double类型的数据
}byte,short,char三种比int小的整数可以用范围内的值直接赋值
byte b1=127;//对,
byte b2=128;//错,超出byte范围
浮点数的字面值是double类型
double r =3.14;//对
float r =3.14;//错,右面的数据字面值是double,float是4字节存不下double类型的数据字面值后缀L D F
long x =99999999999L;//字面值是int类型,需转成long类型的数据,加字面值后缀L即可
float b = 3.0F;//3.0字面值是double类型,加后缀F会变成float类型
double d = 3D;//3字面值是int类型,加后缀D,会变成double类型进制前缀
0b - 标识这是2进制 ,如:0b0101
0 - 标识这是8进制, 8进制是三位,如: 023
0x - 标识这是16进制,如: 0x0001
\u -标识这是char类型,属于16进制6 基本类型的类型转换
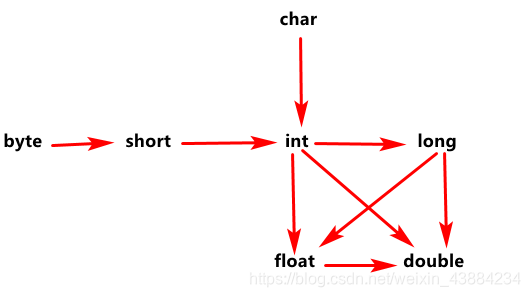
小到大(隐式转换)
byte m = 120;
int n = m;//小转大,右面的m是小类型,给左面的n大类型赋值,可以直接使用
float f = 3.2f; double d = f; -->可以执行大到小(强制类型转换)
int x = 999;
byte y =(byte)x;//大转小,右面x给左面的y小类型赋值,不可以,需要强制类型转换高到低
byte,short,char→ int→ long→float→double
7 运算规则
计算结果的数据类型,与最大数据类型一致
System.out.println(3/2);//1,int/int,得到的结果类型还是int
System.out.println(3/2d);//1.5,int/double。得到的结果是doublebyte,short,char三种比int小的整数,运算时会先自动转换成int
byte a = 1;
byte b = 2;
byte c = (byte)(a+b);
//a+b会自动提升成int类型,右面得运算结果就是int大类型
//给左面的byte小类型赋值,不可以,需要强转。浮点数运算不精确(bigdecimal解决)
8 用最有效率的方法计算2乘以8?
2<<3
9 &和&&的区别?
& 为逻辑与 当&的左右两边都为true才返回true 当&的左边已经为false,虽然说已经决定了当前的整个表达式为false 但是依旧需要判断右边的 表达式
&&为短路与 当&的左边表达式已经为false不需要判断右边的表达式,直接返回false,
|与|| 类似:
||:当左边的表达式已经为true时,不需要判断右边的表达式,直接返回true
|:即使左边的表达式以及为true,还需要判断右边的表达式
10 String 是 Java 基本数据类型吗?
不是,String为引用类型,默认值为null ,而8大基本数据类型(括号中为默认值),byte(0) short(0) int(0) long(0L) float(0.0f) double(0.0) char('/uoooo'(null)) boolean(flase) 并且Double 也为引用类型
基本数据类型:数据直接存储在栈上
引用数据类型区别:数据存储在堆上,栈上只存储引用地址
11 String 类可以被继承吗?
不行。String 类使用 final 修饰,无法被继承。
12、String和StringBuilder、StringBuffer的区别?
| String | StringBuffer | StringBuilder |
| String的值是不可变的,这就导致每次对String的操作都会生成新的String对象,不仅效率低下,而且浪费大量优先的内存空间 | StringBuffer是可变类,和线程安全的字符串操作类,任何对它指向的字符串的操作都不会产生新的对象。每个StringBuffer对象都有一定的缓冲区容量,当字符串大小没有超过容量时,不会分配新的容量,当字符串大小超过容量时,会自动增加容量 | 可变类,速度更快 |
| 不可变 | 可变 | 可变 |
| 线程安全 | 线程不安全 | |
| 多线程操作字符串 | 单线程操作字符串 |
13.初始化考察,请指出下面程序的运行结果。
public class InitialTest {
public static void main(String[] args) {
A ab = new B();
ab = new B();
}
}
class A {
static { // 父类静态代码块
System.out.print("A");
}
public A() { // 父类构造器
System.out.print("a");
}
}
class B extends A {
static { // 子类静态代码块
System.out.print("B");
}
public B() { // 子类构造器
System.out.print("b");
}
}执行结果:ABabab,两个考察点:
1)静态变量只会初始化(执行)一次。
2)当有父类时,完整的初始化顺序为:父类静态变量(静态代码块)->子类静态变量(静态代码块)->父类非静态变量(非静态代码块)->父类构造器(构造方法) ->子类非静态变量(非静态代码块)->子类构造器 。
14、重载(Overload)和重写(Override)的区别
1 Overload 重载 定义在用类中 方法名相同参数列表不同(顺序不同,类型不同)的方法,方法返回值与访问修饰符可以不同,发生在编译期
2 Override 重写 发生继承中,方法名相同,参数列表相同
子类的返回值类型与抛出的异常范围小于等于父类返回值类型
访问修饰符大于等于父类,子类不能重写父类的private方法
15、接口(abstract class)与抽象类(interface)的区别
抽象类只能单继承,接口可以多实现。
抽象类可以有构造方法,接口中不能有构造方法。
抽象类中可以有成员变量,接口中没有成员变量,只能有常量(默认就是 public static final)
抽象类中可以包含非抽象的方法(java 8 新特性),抽象类中的抽象方法类型可以是任意修饰符
16、Error 和 Exception 有什么区别?
Error 和 Exception 都是Throwable 的子类
Error 为系统错误,比如内存溢出,不可能指望程序能处理这样的情况。
Exception 表示需要捕捉或者需要程序进行处理的异常,是一种设计或实现问题,也就是说,它表示如果程序运行正常,从不会发生的情况。程序员自己解决
17、阐述 final、finally、finalize 的区别。
没有任何区别
final 修饰类,该类不能在派生子类,不能被当作父类继承,因此,一个类不能同时被声明为abstract 和 final。
修饰方法:不能被子类重写
修饰变量:该变量必须在声明时给定初值,而在以后只能读取,不可修改。 如果变量是对象,则指的是引用不可修改,但是对象的属性还是可以修改的。
finally finally 是对 Java 异常处理机制的最佳补充 配合try、catch使用,存放在finally中的内容,无论是否出现异常都一定会执行,通常用来释放锁 数据库连接等资源
finalize:Object 中的方法,在垃圾收集器将对象从内存中清除出去之前做必要的清理工作。finalize()方法仅作为了解即可,在 Java 9 中该方法已经被标记为废弃,并添加新的 java.lang.ref.Cleaner,提供了更灵活和有效的方法来释放资源。这也侧面说明了,这个方法的设计是失败的,因此更加不能去使用它。
18 JSON数组结构
JSON(JavaScript Object Notation) 是一种轻量级的数据交换格式
1:JSON 构建由两种结构
(1)键值对集合
(2)值的有序列表(An ordered list of values)。在大部分语言中,它被理解为数组(array)
值(value)可以是双引号括起来的字符串(string)、数值(number)、true、false、 null、对象(object)或者数组(array)。这些结构可以嵌套。
2:JSON具有以下这些形式:
(1) 对象格式
JSON对象是无序的:例子:{“id”:“1”,“name”:“飘香白咖”,“age”:“18”}
简单写法:key和数字可以不加""号,例子:{id:1,name:“飘香白咖”,age:18}
(2) array 格式
数组是值(value)的有序集合,例如:[1,“飘香白咖”,29]
(3)value格式(复杂格式):值(value)可以是双引号括起来的字符串(string)、数值(number)、true、false、 null、对象(object)或者数组(array)。这些结构可以嵌套。
例子:{id:1,name:“飘香白咖”,hobby:[[“水煮肉片”,“五香脆骨”],[“御姐”,“萝莉”,“筋肉美女”],{“1”:“前端”,“2”:“后端”}]}
[[“水煮肉片”,“五香脆骨”]为value嵌套,{“1”:“前端”,“2”:“后端”}为object嵌套
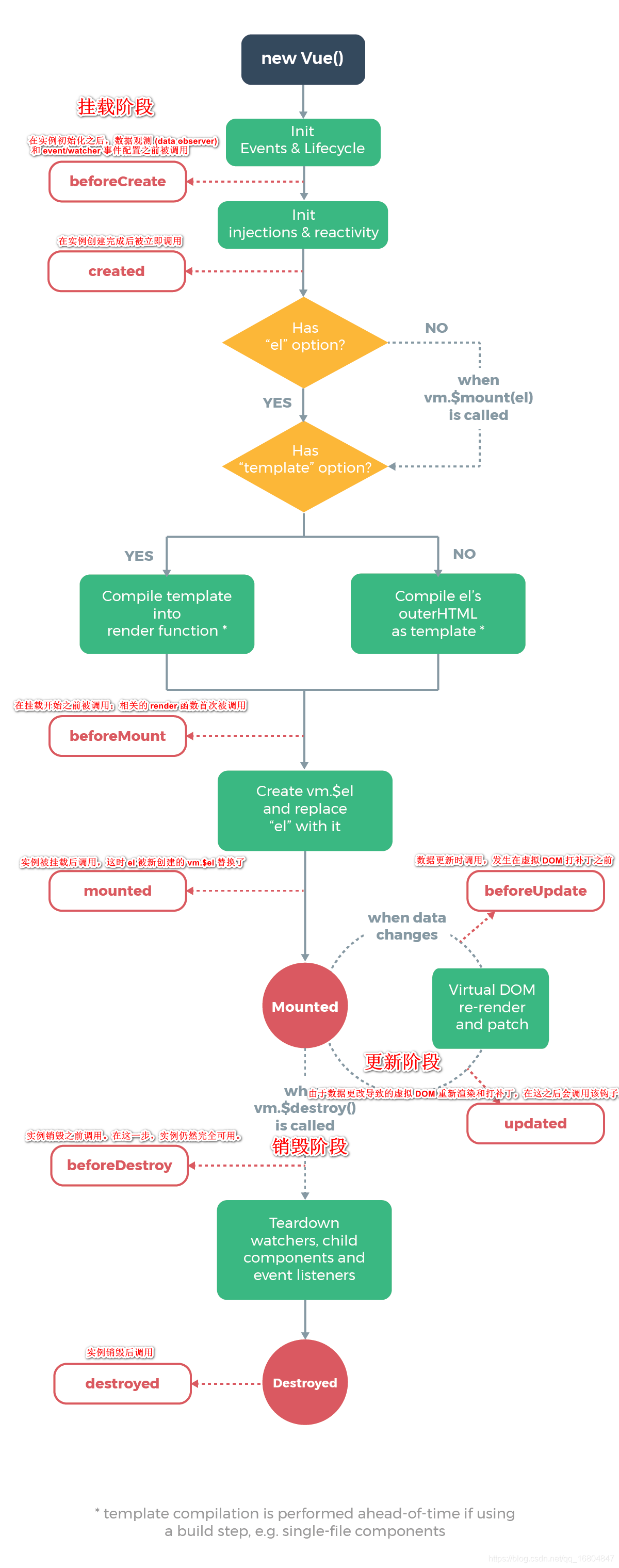
19 vue 的生命周期
20 Mybatis 是半自动的ORM映射框架 需要自己手写SQL语言
21 :线程的状态流转

1 : new: 对象初始化之后没有启动线程处于此状态
Thread.start与Thread.run的区别
start()方法是启动一个新的线程,新线程会执行相对应的run方法 start() 不能被重复调用
Run() 方法只是普通的方法调用,在调用线程中顺序执行而已
2 : Running 状态:包含了就绪和运行两种状态,线程调用start()方式时,程序进入就绪状态,等待获取cpu时间片,当成功获取时间片之后,进入运行状态,
线程中的sleep()方法与yieId()方法,wait()方法有什么区别
sleep()方法:是来个Thread类,wait();来自Object类
sleep()方法:使当前线程陷入睡眠状态,当当前线程持有同步锁时,线程不会释放同步锁,sleep()方法可以在任何地方都可以使用,sleep方法在时间到了之后自动恢复,继续执行,
wait()方法:使线程停止,并释放同步锁,让其他线程进入synchronized代码块执行,wait()方法只能在同步控制方法,或者同步代码块中使用,当当前线程被wait()时,必须替他线程调用同一对象的notify()或者notifyAll()才能够重新恢复
yieId()方法:线程执行sleep()方法后进入等待超时(timed_waiting)状态,而执行yidID方法后直接进入到就绪状态。 sleep()方法给其他线程运行机会时,不考虑线程的优先级,因此会给低优先级的线程运行的机会;yieId()方法只会给相同优先级或者更高优先级的线程运行的机会
3:Blacked:线程在进入同步方法或者同步代码块时被阻塞,等待同步锁的线程处于此状态
4:waiting:无期限等待另一个线程执行特定的操作处于此状态,需要被唤醒,负责会一直等待下去,例如执行Object.wait()方法时,必须等待另一个线程执行Object.notify()或Object.notifAll();而Thread.join():则需要等待指定的线程终止
线程的 join() 方法是干啥用的?
用于当前线程等待目标的终止在进行运行:如果一个线程A执行了threadB.join()语句,就是当前A线程等待B线程终止后,在从 threadB.join() 返回继续往下执行自己的代码。
5 timed_waiting:在指定的时间内等待另一个线程执行某项操作的线程处于此状态,与waiting不同,当超过自己设置的时间后,会自动唤醒,避免了无期限的等待
6 terminated:执行完毕已经退出的线程处于此状态
22 死锁的四个必要条件
1: 互斥条件:进程对所分配到的资源进行排他性控制,即在一个阶段内一个资源被一个进程所占用,若有其他进程请求此资源,不可访问,只能等待
2:请求和保持条件:进程已经获得了一个资源,但是有对其他资源发出请求,但是其他资源已经被其他进程所占用,当前进程等待其他进程释放资源,保持自己对当前资源的持有
3:不可剥夺条件:进程已经获得的资源在未使用完毕之前,不可以被其他资源强行剥夺,只能自己释放
4 环路等待:A保持a资源,想要吧b,c资源,而b,c资源分别被B,C进程所持有,但是B,C进程想要a资源,等待A进程释放a资源,但是A进程未获得b,c资源,由于不可剥夺性与请求保持条件,保持持有a资源,陷入私有
23 乐观锁与悲观锁
乐观锁 : 把事情都想好的地方想,认为每次处理业务时,在此时期都不会有人同时修改,所以不会上锁,但是提交事务时,会判断拿到的版本号与准备提交的版本号是否一样.或者和CAS算法实现.乐观锁适用于多读的应用类型,这样可以提高吞吐量,像数据库提供的类似于write_condition机制,其实都是提供的乐观锁
悲观锁:吧所以事情都往快的地方想,认为每次处理业务时,在此时期都会有人同时修改,所以给进程上锁,这样别人想拿这个数据就会阻塞直到它拿到锁(共享资源每次只给一个线程使用,其它线程阻塞,用完后再把资源转让给其它线程)。java中的同步锁就是悲观锁
24 Lock锁
因为同步锁有缺陷:当一个线程在执行带锁的方法时,其他需要使用这个方法的线程只能等待 ,等待获取锁的线程释放锁。当进行IO获取sleep时,会影响运行速率.。通过Lock可以知道线程有没有成功获取到锁。
Lock是一个类,通过这个类可以实现同步访问;不是java的内置语言
Lock和synchronized有一点非常大的不同,采用synchronized不需要用户去手动释放锁,当synchronized方法或者synchronized代码块执行完之后,系统会自动让线程释放对锁的占用;而Lock则必须要用户去手动释放锁,如果没有主动释放锁(unlock()),就有可能导致出现死锁现象。
25 为什么要使用线程池
每次创建线程都new的话,会消耗系统资源,还会降低系统的稳定性,
使用线程池的话:1 重复利用已创建的线程,降低线程创建和销毁造成的消耗。
2 提高响应速度,当任务到达时,任务可以不需要等到线程创建就能立即执行。
3 增加线程的可管理型。线程是稀缺资源,使用线程池可以进行统一分配,调优和监控。
26 线程池的运作流程
threadFactory(线程工厂):用于创建工作线程的工厂。
当任务到达时,判断是否达到核心线程数(corePoolSize),如果没有达到核心线程数,启动一个核心线程,去执行任务,如果 核心线程数(corePoolSize)<任务<最大线程数(maximumPoolSize) , 并且队列(workQueue)为满,则将保留任务并移交给工作线程的阻塞队列。当 核心线程数(corePoolSize)<任务<最大线程数(maximumPoolSize) 并且任务队列已满,则开启一个非核心线程来运行任务,当任务大于最大线程数(maxxinumPoolSize),则拒绝策略(handler),
保持存活时间(keepAliveTime):当线程池线程大于核心线程数,非核心线程池的空闲时间大于保持存货时间(keepAliveTime)会销毁

27 java自带的三个进程池

同步队列:SynchronousQueue:同步Queue,属于线程安全的BlockingQueue的一种,此队列设计的理念类似于"单工模式",对于每个put/offer操作,必须等待一个take/poll操作,类似于我们的现实生活中的"火把传递":一个火把传递地他人,需要2个人"触手可及"才行. 因为这种策略,最终导致队列中并没有一个真正的元素
newCachedThreadPool: 没有核心线程,非核心线程最大,队列为同步队列(SynchronousQueue),大小为1,有几个任务就有几个非核心线程,运行效率快
newFixedThreadPool : 没有非核心线程,核心线程数量(corePoolSize)等于最大线程数量(maximumPoolSize).队列为无界队列(LinkedBlockingQueue) 运行效率看核心线程数量
newsigleThreadPool : 没有非核心线程,,最大线程数量等于核心线程数量等于1:队列为无界队列
,线程安全,只有一个线程执行任务,运行效率慢
28 为什么不使用java自带的线程池
因为会产生OOM(内存溢出) : newCachedThreadPool虽然不会产生OOM,但是会内存100%,应为队列本质为数据结构,而数据结构的本质是用来存储的
29 提交优先级,与执行优先级
提交优先级 : 核心线程 --- 队列 --- 非核心线程
执行优先级 : 核心线程 --- 非核心线程 ---队列
30 线程池有哪些拒绝策略?
1 AbortPolicy : 中止策略 默认的中止策略,直接抛出 RejectedExecutionException 异常,调用者可以捕获这个异常,然后根据需求编写自己的处理代码。
2 DiscardPolicy:抛弃策略。什么都不做,直接抛弃被拒绝的任务。
3 DiscardOldestPolicy:抛弃最老策略。抛弃阻塞队列中最老的任务,相当于就是队列中下一个将要被执行的任务,然后重新提交被拒绝的任务。如果阻塞队列是一个优先队列,那么“抛弃最旧的”策略将导致抛弃优先级最高的任务,因此最好不要将该策略和优先级队列放在一起使用。
4 CallerRunsPolicy:调用者运行策略。在调用者线程中执行该任务。该策略实现了一种调节机制,该策略既不会抛弃任务,也不会抛出异常,而是将任务回退到调用者(调用线程池执行任务的主线程),由于执行任务需要一定时间,因此主线程至少在一段时间内不能提交任务,从而使得线程池有时间来处理完正在执行的任务。
31 集合
集合 : 集合的英文名称是Collection,是用来存放对象的数据结构,而且长度可变,可以存放不同类型的对象,并且还提供了一组操作成批对象的方法.Collection接口层次结构 中的根接口,接口不能直接使用,但是该接口提供了添加元素/删除元素/管理元素的父接口公共方法.
由于List接口与Set接口都继承了Collection接口,因此这些方法对于List集合和Set集合是通用的.

32 为什么要使用集合:
数组的长度是不可变的,插入,删除元素频繁,访问方法单一(数组下标),因为数组的长度不可变,所以数组的扩容(插入)与缩容(删除),所以不是直接操作原数组,而是创建新长度的数组,可用泛型约束
33 List、Set、Map三者的区别?
List接口 : 有序列表,有下标,可重复,可存null,有Arraylist,与Linklist 2个实现类,
Arraylist 底层为有序动态数组,查询快,增删慢,内部数组默认的初始容量是10,如果不够会以1.5倍的容量增长,
查找:ArrayList数组直接通过index直接定位到数组对应的节点。
增删:ArrayList需要移动目标节点后面的节点(System.arraycopy)

LinkList:底层为链表结构,查询慢,增添快,LinkList的内存地址是不联系的,是靠节点之间的地址连接起来的,头节点存储的是数据与下一个节点的地址,尾节点想法,中间阶段存储的是数据,上一个,以及下一个的节点地址
查找:LinkList需要从头节点或者从尾节点开始遍历,知道寻找到目标节点
增删:LinkList只需要修改目标节点前后的next或者prev属性即可

Set接口 : 无序列表,无下标,不可重复,有Hashset和TreeSet2个实现类
1 Set是一个不包含重复数据,无序的Collection
2 Set集合中的数据是无序的(因为Set集合没有下标)
3 Set集合中的元素不可以重复 – 常用来给数据去重
4 数据无序且数据不允许重复
5 HashSet : 底层是哈希表,包装了HashMap,相当于向HashSet中存入数据时,会把数据作为K,存入内部的HashMap中。当然K仍然不许重复。
6 TreeSet : 底层是TreeMap,也是红黑树的形式,便于查找数据
Map接口:键值对<k,v>: 有hashMap与treeMap2个实现类
1 Map可以根据键来提取对应的值
2 Map的键不允许重复,如果重复,对应的值会被覆盖
3 Map存放的都是无序的数据
4 Map的初始容量是16,默认的加载因子是0.75
34 HashMap
1 HashMap的结构是数组+链表 或者 数组+红黑树 的形式
2 HashMap底层的Entry[ ]数组,初始容量为16,加载因子是0.75f,扩容按约为2倍扩容
3 当存放数据时,会根据hash(key)%n算法来计算数据的存放位置,n就是数组的长度,其实也就是集合的容量
4 当计算到的位置之前没有存过数据的时候,会直接存放数据
5 当计算的位置,有数据时,会发生hash冲突/hash碰撞
6 解决的办法就是采用链表的结构,在数组中指定位置处以后元素之后插入新的元素
也就是说数组中的元素都是最早加入的节点
7 如果链表的长度>8时,链表会转为红黑树,当链表的长度<6时,会重新恢复成链表

35 hashmap和hashtable支持null值和null键么
hashmap允许多个null值和一个null键,hashtable不允许有任何null值和null键
1 List都可以添加null元素
2 HashMap可以有1个key为null的元素,TreeMap不能有key为null的元素
所以HashSet底层是HashMap,可以有1个null的元素,TreeSet底层是TreeMap,不能有key为null的元素。
36 Map集合的迭代方式

37 ArrayList 和 Vector 的区别。
ArrayList与Vector几乎一样,唯一的区别是Vector使用的 synchronized 来确保进程安全,,因此在性能上 ArrayList 具有更好的表现。
类似的有 Stringbuilder与 Stringbuffer hashMap与hashtable
38 介绍下 HashMap 的底层数据结构
底层是由“数组+链表+红黑树”组成

39 为什么改成数组 + 链表 + 红黑树结构
主要是为了在hash严重时(链表过长)的查找性能,使用链表的查询性能为O(n),使用红黑树是O(logn)。
40 那在什么时候用链表?什么时候用红黑树?
对于插入,如果一个同一个索引的链表长度达到8时,而且数组长度大于等于64时,会触发链表节点转化为红黑树,当数组长度小于64时,不会触发链表节点转化为红黑树,会数组扩容,因为此时数据量较小,
对于移除来说,当同一个索引的位置节点在移除后达到6个时,并该索引位置为红黑树节点,会触发红黑树节点转化为链表节点
41 HashMap 的插入流程是怎么样的?
头节点key和入参key是否相等:是判断是否是同一个key,不同的value,因为Map集合,不可以重复,使用后面的entry会覆盖前面的entry。

42 HashMap 的扩容(resize)流程是怎么样的?

43 HashMap 和Hashtable 的区别?
hashMap的允许key(只允许1个)与value为null。而hashtable不能为null
hashMap初始容量为15,hashtable初始容量为11,
hashMap的扩容是原来的2倍,hashtable为原来的2倍加1
hashMap是非线程安全的,hashtable是线程安全的
hashMap的hash是重新计算过的,hashtable直接使用hashCode
HashMap 去掉了 Hashtable 中的 contains 方法。
HashMap 继承自 AbstractMap 类,Hashtable 继承自 Dictionary 类。
44 equals方法和hashcode的关系?
1、如果两个对象equals相等,那么这两个对象的HashCode一定也相同
2、如果两个对象的HashCode相同,不代表两个对象就相同,只能说明这两个对象在散列存储结构中,存放于同一个位置















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









