







一、Map集合的特点
1.Map是一个双列集合,一个元素包含两个值(一个key,一个value)
2.Map集合中的元素,key和value的数据类型可以相同,也可以不同
3.Map中的元素,key不允许重复,value可以重复
4.Map里的key和value是一一对应的。
二、Map中的方法
①.put(K key, V value) 将键(key)/值(value)映射存放到Map集合中
public class Test {
public static void main(String[] args) {
HashMap<String, Integer> map = new HashMap<String, Integer>();
map.put("Tom", 100);//向HashMap中添加元素
map.put("Tom1", 700);//向HashMap中添加元素
map.put("Tom", 100);//向HashMap中添加元素
System.out.println(map);
}
}运行结果:

②.get(Object key) 返回指定键所映射的值,没有该key对应的值则返回 null,即获取key对应的value。
public class Test {
public static void main(String[] args) {
HashMap<String, Integer> map = new HashMap<String, Integer>();
map.put("Tom", 100);
map.put("Tom", 0);
int score = map.get("Tom");// 获取key对应的value
System.out.println(score);// key不允许重复,若重复,则覆盖已有key的value
}
}运行结果:
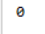
可知,之前加入的value已被覆盖,前面的观点得证
③. size() 返回Map集合中数据数量,准确说是返回key-value的组数。
public class Test {
public static void main(String[] args) {
HashMap<String, Integer> map = new HashMap<String, Integer>();
map.put("Tom", 100);
map.put("Jim", 90);
map.put("Sam", 91);
System.out.println(map);
System.out.println(map.size());
}
}运行结果:
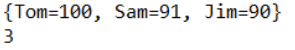
④:clear() 清空Map集合
public class Test {
public static void main(String[] args) {
HashMap<String, Integer> map = new HashMap<String, Integer>();
map.put("Tom", 100);
map.put("Jim", 90);
map.put("Sam", 91);
map.clear();// 清空map中的key-value
System.out.println(map.size());
}
}运行结果:
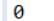
⑤:isEmpty () 判断Map集合中是否有数据,如果没有则返回true,否则返回false
public class Test {
public static void main(String[] args) {
HashMap<String, Integer> map = new HashMap<String, Integer>();
map.put("Tom", 100);
map.put("Jim", 90);
map.put("Sam", 91);
System.out.println(map.isEmpty());
map.clear();// 清空map中的key-value
System.out.println(map.isEmpty());
}
}运行结果:
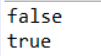
⑥:remove(Object key) 删除Map集合中键为key的数据并返回其所对应value值。
public class Test {
public static void main(String[] args) {
HashMap<String, Integer> map = new HashMap<String, Integer>();
map.put("Tom", 100);
map.put("Jim", 90);
map.put("Sam", 91);
map.remove("Tom");
System.out.println(map);
}
}运行结果:

⑦:containsKey(Object key) Hashmap判断是否含有key
public class Test {
public static void main(String[] args) {
HashMap<String, Integer> map=new HashMap<>();
/*boolean*///判断map中是否存在这个key
System.out.println(map.containsKey("DEMO"));//false
map.put("DEMO", 1);
System.out.println(map.containsKey("DEMO"));//true
}
}运行结果:
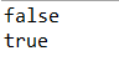
⑧:containsValue(Object value) Hashmap判断是否含有value:
public class Test {
public static void main(String[] args) {
HashMap<String, Integer> map=new HashMap<>();
/*boolean*///判断map中是否存在这个value
System.out.println(map.containsValue(1));//false
map.put("DEMO", 1);
System.out.println(map.containsValue(1));//true
}
}运行结果:

⑨:Hashmap添加另一个同一类型的map下的所有数据
public class Test {
public static void main(String[] args) {
HashMap<String, Integer> map=new HashMap<>();
HashMap<String, Integer> map1=new HashMap<>();
/*void*///将同一类型的map添加到另一个map中
map1.put("DEMO1", 1);
map.put("DEMO2", 2);
System.out.println(map);//{DEMO2=2}
map.putAll(map1);
System.out.println(map);//{DEMO1=1, DEMO2=2}
}
}运行结果:

⑩:Hashmap替换这个key的value
public class Test {
public static void main(String[] args) {
HashMap<String, Integer> map=new HashMap<>();
/*value*///判断map中是否存在这个key
map.put("DEMO1", 1);
map.put("DEMO2", 2);
System.out.println(map);//{DEMO1=1, DEMO2=2}
System.out.println(map.replace("DEMO2", 1));//2
System.out.println(map);//{DEMO1=1, DEMO2=1}
}
}运行结果:

三、Map常用实现类
(1)HashMap
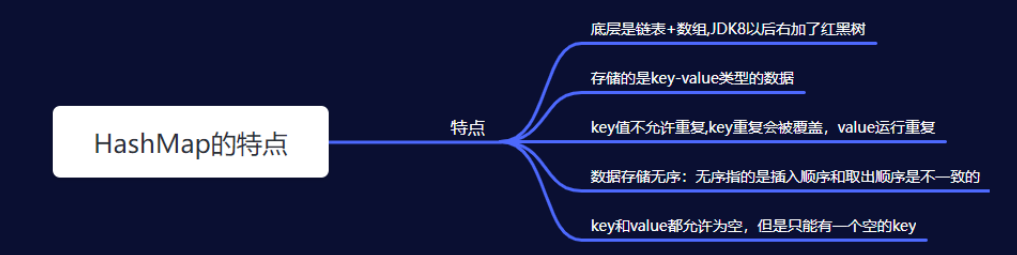
(2)TreeMap

四、HashMap
(1)什么是HashMap?
HashMap 数据结构为 数组+链表(JDk1.7),JDK1.8中增加了红黑树,其中:链表的节点存储的是一个 Entry 对象,每个Entry 对象存储四个属性(hash,key,value,next)
如图所示

(2)为什么要使用HashMap?
对于要求查询次数特别多,查询效率比较高同时插入和删除的次数比较少的情况下,通常会选择ArrayList,因为它的底层是通过数组实现的。对于插入和删除次数比较多同时在查询次数不多的情况下,通常会选择LinkedList,因为它的底层是通过链表实现的。
但现在同时要求插入,删除,查询效率都很高的情况下我们该如何选择容器呢?
那么就有一种新的容器叫HashMap,他里面既有数组结构,也有链表结构,所以可以弥补相互的缺点。而且HashMap主要用法是get()和put() 。
(3)HashMap工作原理
首先,初始化 HashMap,提供了有参构造和无参构造,无参构造中,容器默认的数组大小 initialCapacity 为 16,加载因子loadFactor 为0.75。容器的阈(yu)值为 initialCapacity * loadFactor,默认情况下阈值为 16 * 0.75 = 12; 后面会讲到阈值有啥用。
然后,这里我们拿 PUT 方法来做研究:
第一步:通过 HashMap 自己提供的hash 算法算出当前 key 的hash 值
第二步:通过计算出的hash 值去调用 indexFor 方法计算当前对象应该存储在数组的几号位置
第三步:判断size 是否已经达到了当前阈值,如果没有,继续;如果已经达到阈值,则先进行数组扩容,将数组长度扩容为原来的2倍。
> 请注意:size 是当前容器中已有 Entry 的数量,不是数组长度。
第四步:将当前对应的 hash,key,value封装成一个 Entry,去数组中查找当前位置有没有元素,如果没有,放在这个位置上;如果此位置上已经存在链表,那么遍历链表,如果链表上某个节点的 key 与当前key 进行 equals 比较后结果为 true,则把原来节点上的value 返回,将当前新的 value替换掉原来的value,如果遍历完链表,没有找到key 与当前 key equals为 true的,就把刚才封装的新的 Entry中next 指向当前链表的始节点,也就是说当前节点现在在链表的第一个位置,简单来说即,先来的往后退。
OK!现在,我们已经将当前的 key-value 存储到了容器中。
为什么我选择聊 PUT 方法?
因为 PUT 是操作HashMap的最基础操作,了解了 PUT 的机制后,再去看 API其他方法源码的时候你会有所眉目,你可以带着这种初知去探究 HashMap 的其他方法,你一定会豁然开朗。
(4)扩容机制
HashMap 使用 “懒扩容” ,只会在 PUT 的时候才进行判断,然后进行扩容。
将数组长度扩容为原来的2 倍
将原来数组中的元素进行重新放到新数组中
需要注意的是,每次扩容之后,都要重新计算原来的 Entry 在新数组中的位置,为什么数组扩容了,Entry 在数组中的位置发生变化了呢?所以我们会想到计算位置的 indexFor 方法,为什么呢,我摘出了该方法的源码如下:
static int indexFor(int h, int length) { // h 为key 的 hash值;length 是数组长度
return h & (length-1);
}由源码得知,元素所在位置是和数组长度是有关系的,既然扩容后数组长度发生了变化,那么元素位置肯定是要发生变化了。HashMap 计算元素位置采用的是 &运算,不了解此运算的我在这里给个简单的例子:
为什么 HashMap使用这种方式计算在数组中位置呢?
按照我们的潜意识,取模就可以了。hashMap 用与运算主要是提升计算性能。这又带来一个新问题,为什么与运算要用 length -1 呢,回看 hashmap初始化的时候,数组长度 length必须是2的整次幂(如果手动传参数组长度为奇数n,hashMap会自动转换长度为距离n最近的2的整次幂数), 只有这样, h & (length-1) 的值才会和 h % length 计算的结果是一样的。这就是它的原因所在。另外,当length是2的整次幂的时候,length-1的结果都是低位全部是1,为后面的扩容做了很好的准备,这里先不扯这个,先理解一下这个意思。
我们来写个单元测试验证下:
public static void main(String[] args) {
/**
* 定义数组长度为2的整次幂,2^4
*/
int length = 16;
/**
* 定义key,并计算k的hash值
*/
String k = "China";
int h = k.hashCode();
/**
* 分别使用两种方式计算在数组中的位置
*/
int index1 = h % length;
int index2 = h & (length - 1);
/**
* 验证结果
*/
System.out.println(index1 == index2);
/**
* 结果为 true
*/
}public static void main(String[] args) {
/**
* 假设数组长度不是2的整次幂,2^4-1
*/
int length = 15;
/**
* 定义key,并计算k的hash值
*/
String k = "China";
int h = k.hashCode();
/**
* 分别使用两种方式计算在数组中的位置
*/
int index1 = h % length;
int index2 = h & (length - 1);
/**
* 验证结果
*/
System.out.println(index1 == index2);
/**
* 打印结果:false
*/
}(5)如何优化 HashMap?
初始化 HashMap 的时候,我们可以自定义数组容量及加载因子的大小。所以,优化 HashMap 从这两个属性入手,但是,如果你不能准确的判别你的业务所需的大小,请使用默认值,否则,一旦手动配置的不合适,效果将适得其反。
threshold = (int)( capacity * loadFactor );
阈值 = 容量 X 负载因子;
初始容量默认为16,负载因子(loadFactor)默认是0.75; map扩容后,要重新计算阈值;当元素个数 大于新的阈值时,map再自动扩容;以默认值为例,阈值=16*0.75=12,当元素个数大于12时就要扩容;那剩下的4个数组位置还没有放置对象就要扩容,造成空间浪费,所以要进行时间和空间的折中考虑;
loadFactor过大时,map内的数组使用率高了,内部极有可能形成Entry链,影响查找速度;
loadFactor过小时,map内的数组使用率较低,不过内部不会生成Entry链,或者生成的Entry链很短,
由此提高了查找速度,不过会占用更多的内存;所以可以根据实际硬件环境和程序的运行状态来调节loadFactor;
所以,务必合理的初始化 HashMap
(6)HashMap和HashTable 的异同?
二者的存储结构和解决冲突的方法都是相同的。
HashTable在不指定容量的情况下的默认容量为11,而HashMap为16,Hashtable不要求底层数组的容量一定要为2的整数次幂,而HashMap则要求一定为2的整数次幂。
HashTable 中 key和 value都不允许为 null,而HashMap中key和value都允许为 null(key只能有一个为null,而value则可以有多个为 null)。但是如果在 Hashtable中有类似 put( null, null)的操作,编译同样可以通过,因为 key和 value都是Object类型,但运行时会抛出 NullPointerException异常。
Hashtable扩容时,将容量变为原来的2倍+1,而HashMap扩容时,将容量变为原来的2倍。
Hashtable计算hash值,直接用key的hashCode(),而HashMap重新计算了key的hash值,Hashtable在计算hash值对应的位置索引时,用 %运算,而 HashMap在求位置索引时,则用 &运算。
参考博客:https://blog.csdn.net/weixin_35586546/article/details/81153793















 1903
1903











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









