



 这篇博客详细介绍了在Windows 2019和macOS 2019版Word中为日语文段注音的步骤,包括安装所需语言包,切换到日语环境,以及设置注音快捷键以提高效率。对于macOS,需要调整系统语言来实现日文注音。
这篇博客详细介绍了在Windows 2019和macOS 2019版Word中为日语文段注音的步骤,包括安装所需语言包,切换到日语环境,以及设置注音快捷键以提高效率。对于macOS,需要调整系统语言来实现日文注音。
Word日文文段注音方法(Win/Mac)
说明 此篇文章针对日语文段注音。如果仅仅是几个假名,手动挨个注音即可(win版Word有个文 wen的图标,mac版Word有个abc A的图标)。
文章目录
Windows 2019版Word 日文注音方法
下载安装Word2019版(我的是学校提供的版本)
打开Word
依次点击:左上角的文件,选项,语言,[编辑添加其他语言],日文,添加

然后你会发现日文后面有未安装的字样(我的已经安装了所以显示已安装),以西班牙语为例放个“未安装”的图

然后我们点击未安装这三个字,跳转到官网Office 语言配件包
你也可以直接点击这里跳转到官网Office 语言配件包
我们在步骤一中选择日语,按照你电脑是32位还是64位下载日语语言包
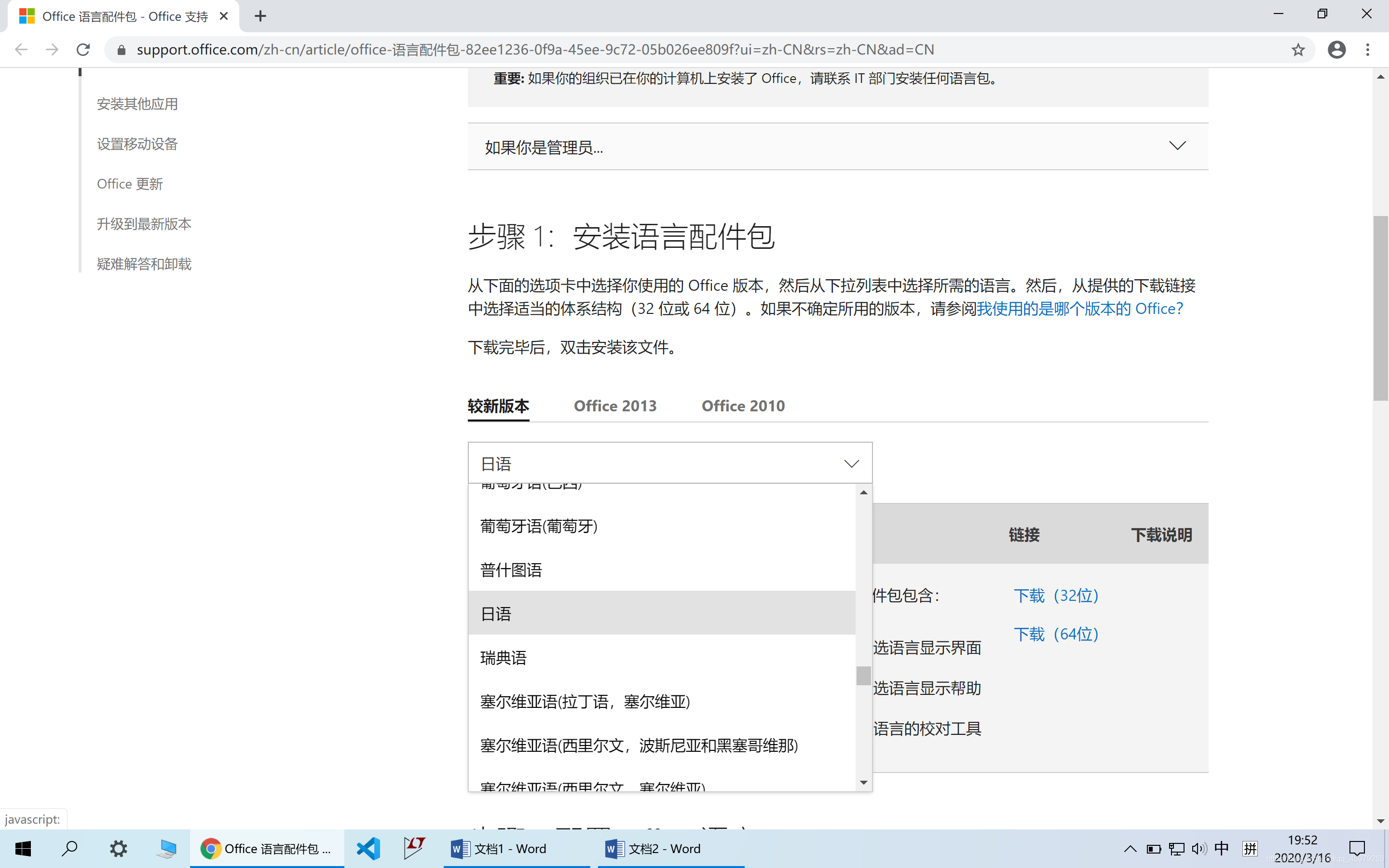

ps.这个过程可能比较漫长
下载好后我们双击打开,不出意外的话你再返回Word就会发现刚才的未安装变成了已安装

由于注音还需要windows系统中的语言包,我们还需要打开windows设置,时间和语言,首选语言,添加首选的语言,选择日本語
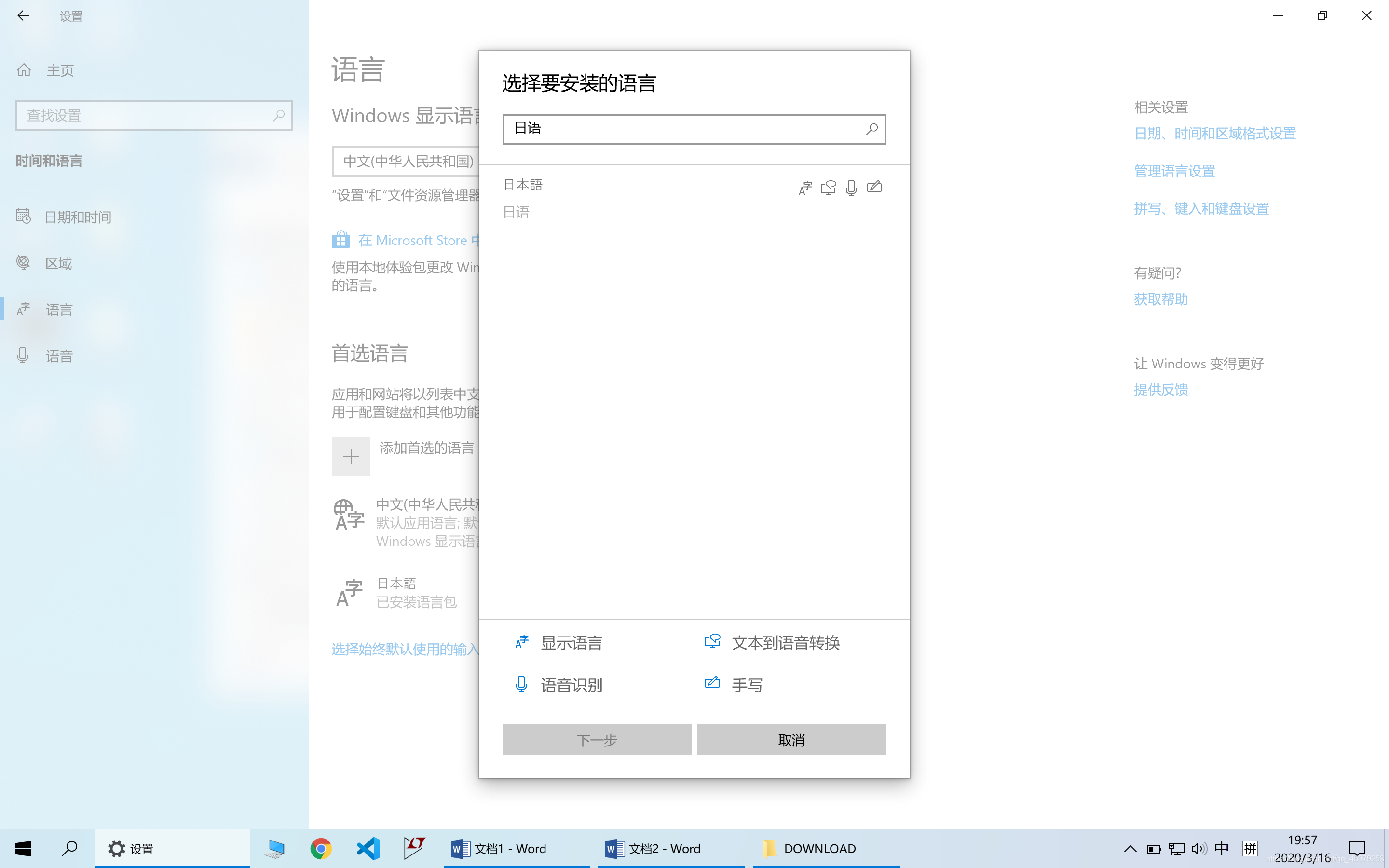
进行安装(可能也得下载好一会)(注:不需要使用日文输入法,只要安装了就行)
退出重开Word,键入一段日文,选中这段日文之后点击左下角的“中文”(或者“英语”)切换为“日语”。(我的已经切换好了,所以显示为“日语”)
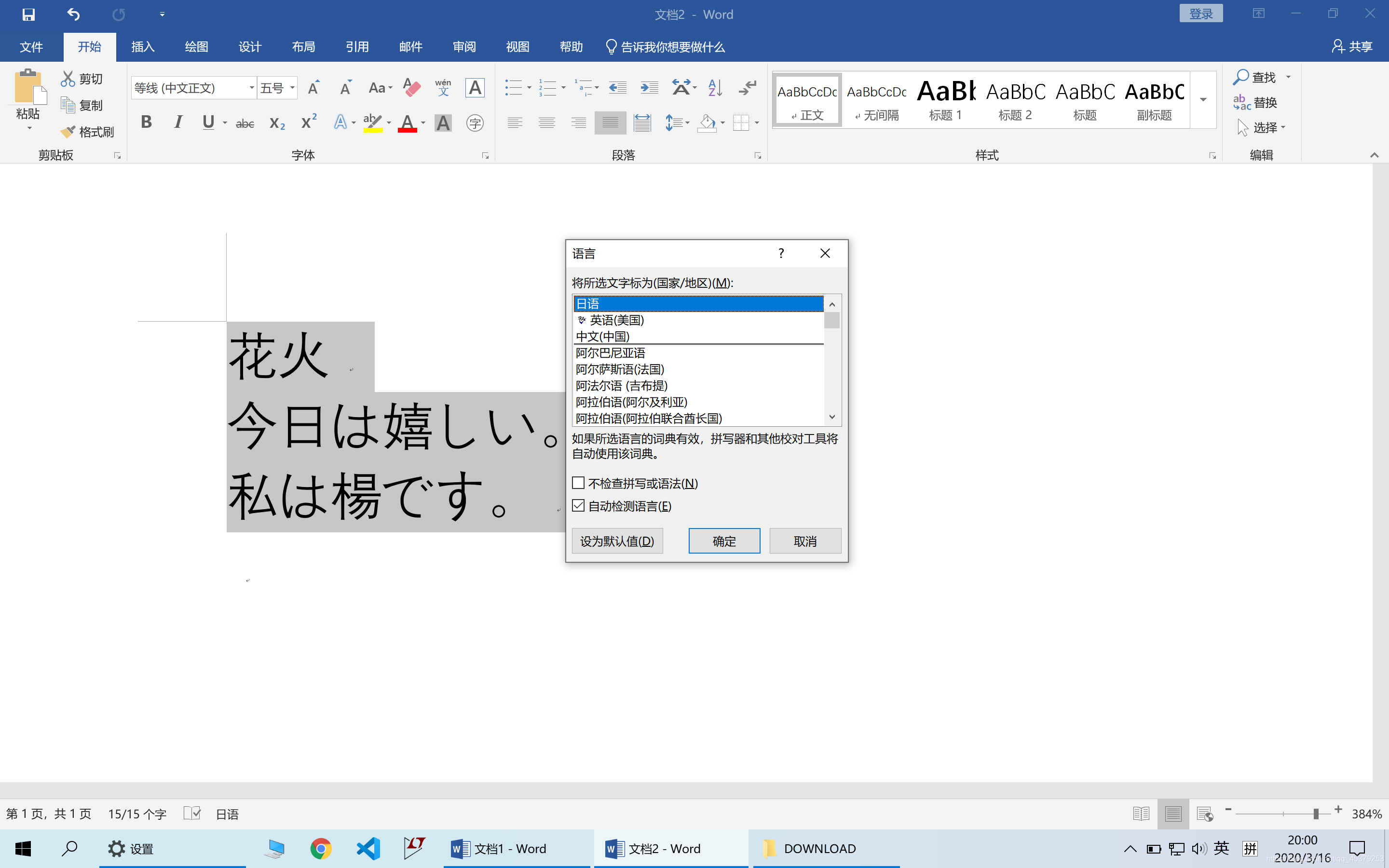
然后点击开始菜单里的文 wen图标,再点击确认,日文就注好音了!

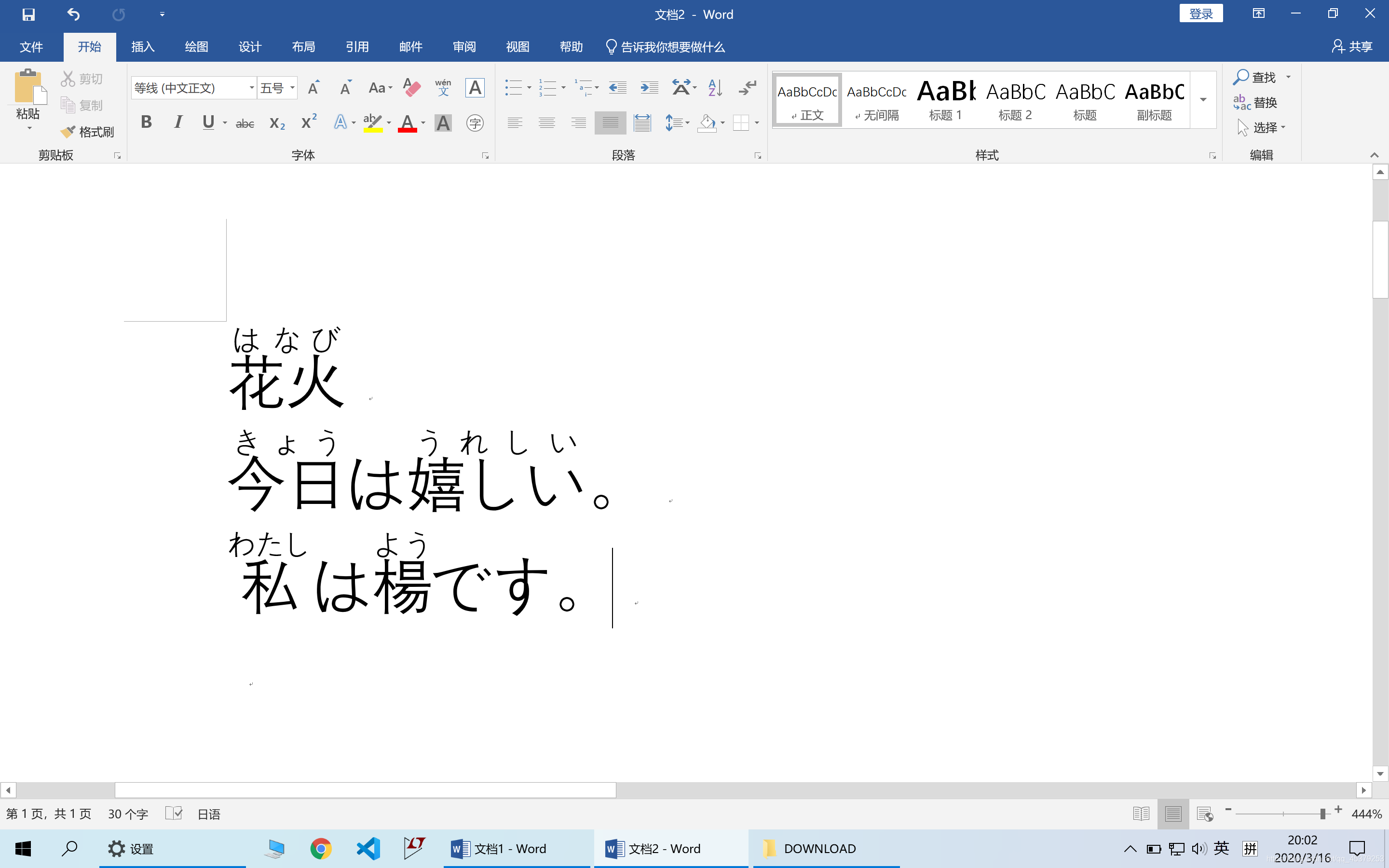
注:也可以选段落进行标注。但是Word一次只能处理一小段
最后,如果还没成功你可以把微软官网上下载的那个语言包多安装几次(至少我是安装了3、4次),然后应该就好了吧
macOS 2019版Word 日文注音方法
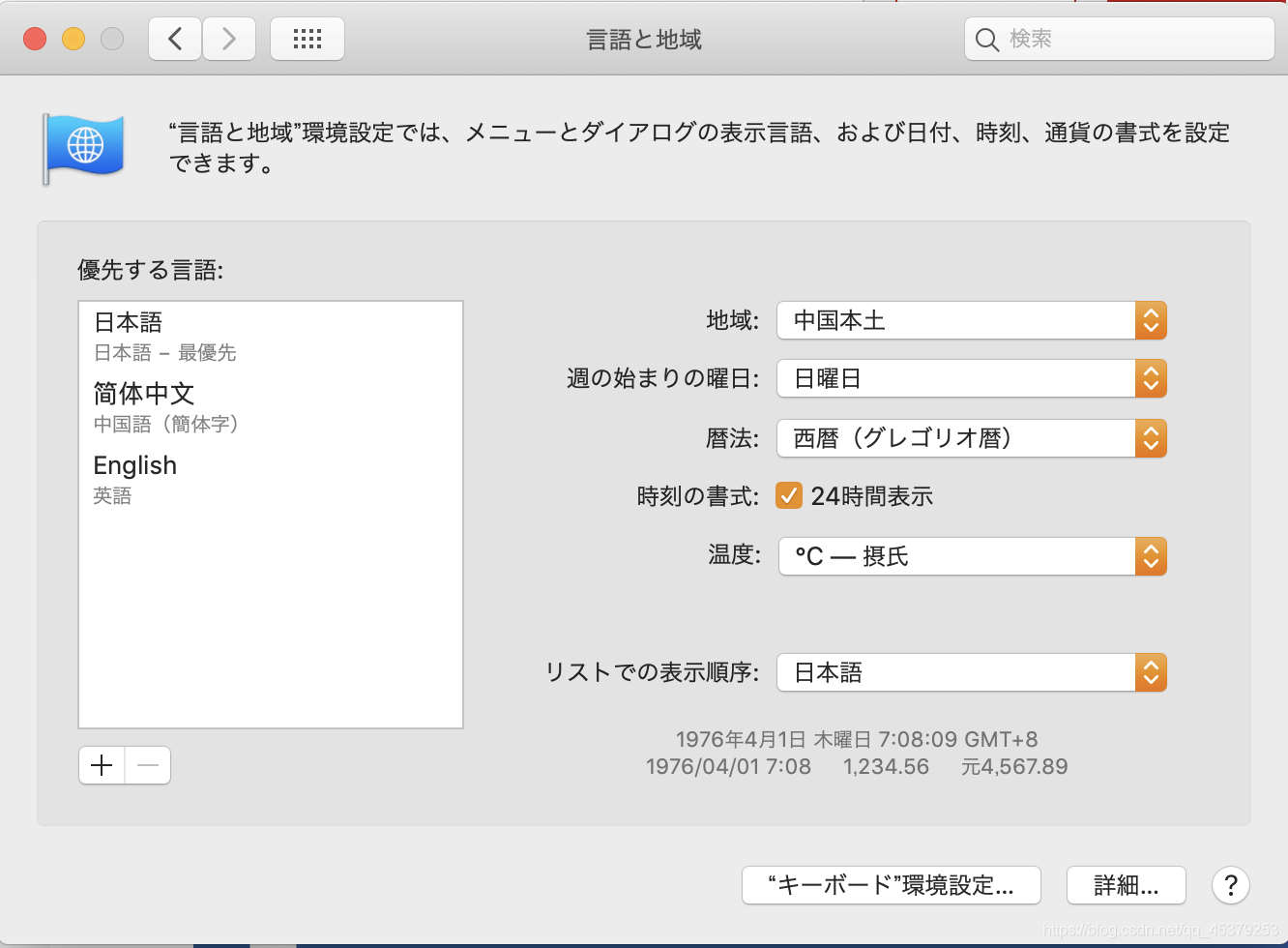
Mac 上的 Word2019 更改为日文版才能进行直接的段落日语注音, Word2019 没有日文版,Word的偏好设置中也没有可以直接调整语言的选项,因此我们采取的思路是调整系统语言。好在目前(2020年6月)最新的Catalina系统中,已经支持在系统偏好设置中为单个应用设置语言,如果你的Mac已经升级了Catalina系统,那么就不用看下面的步骤了。
首先打开 系统偏好设置 语言和地区 点击左下角的加号添加 日本語,然后把日本語拖拽到第一个(这一步是在修改电脑的系统语言)
点击 关闭 或点击 那个有12个小格子的东西 退出语言与地区界面,系统会提示重启,我们重启电脑。
重启之后你就会发现所有的东西都变成日文了(这不是废话么)
打开Word,跳出一个提示框,大意是“你已经改变首选语言”,点个确认进入Word
你惊喜的发现Word变成日文版了(对,mac版word本身没有直接能改变语言的选项,只有修改系统首选语言才会改变)
键入一段日文,选中,点击ホーム里的abc A按钮,回车,发现确实标注了
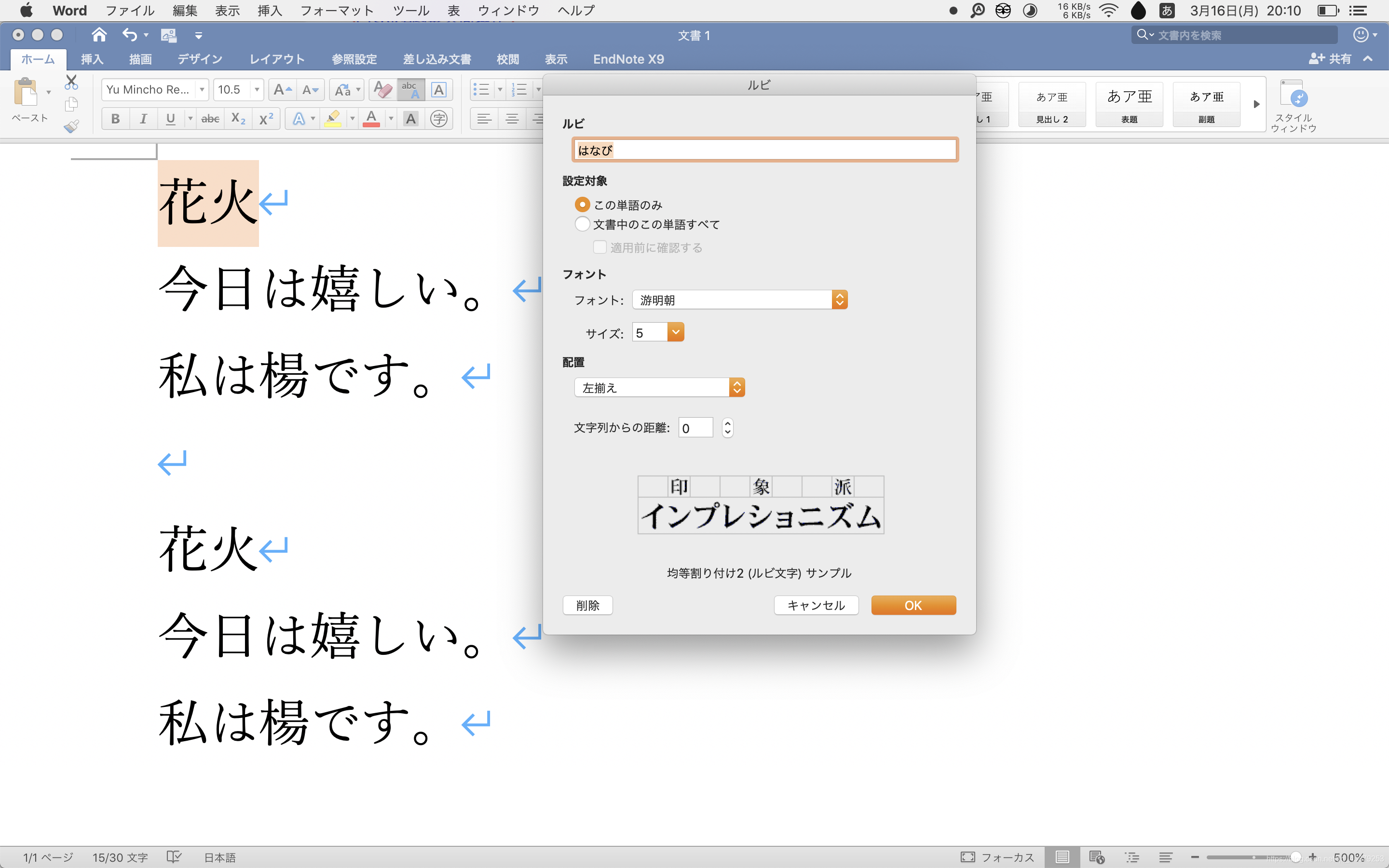

不过通过进一步的使用你会发现,如果选中几行日文,Word只能对其中第一行注音;如果是一句日文,Word连平假名也会注音;如果是一段日文,Word连。句号都不放过!(这也太过分了吧)
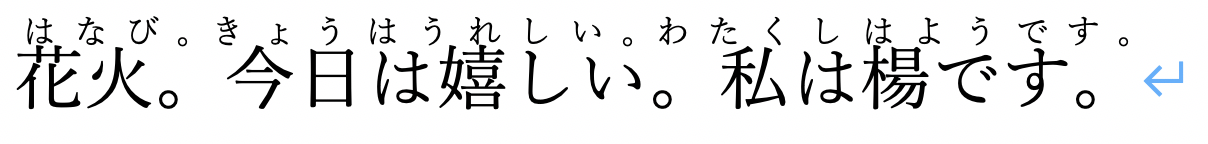
没事儿解决方法是有的,我们只要依次选中汉字点击那个abc A再回车进行挨个的注音不就行了么。
效果展示(有错的自己改吧)

这里感谢一下网易有道词典的拍照翻译,不然我个日语小白看着日文版的mac差不多要窒息了。
不过想了想初学者还是用windows的Word给日文文段注音吧,你看它兼容的那么好。毕竟初学者mac调成日文差不多就gg了
提高效率的方法——注音快捷键的设置
想法:我们设置一个快捷键来注音,这样至少不用不停去上面点那个abc A或是文 wen的图标。
Windows
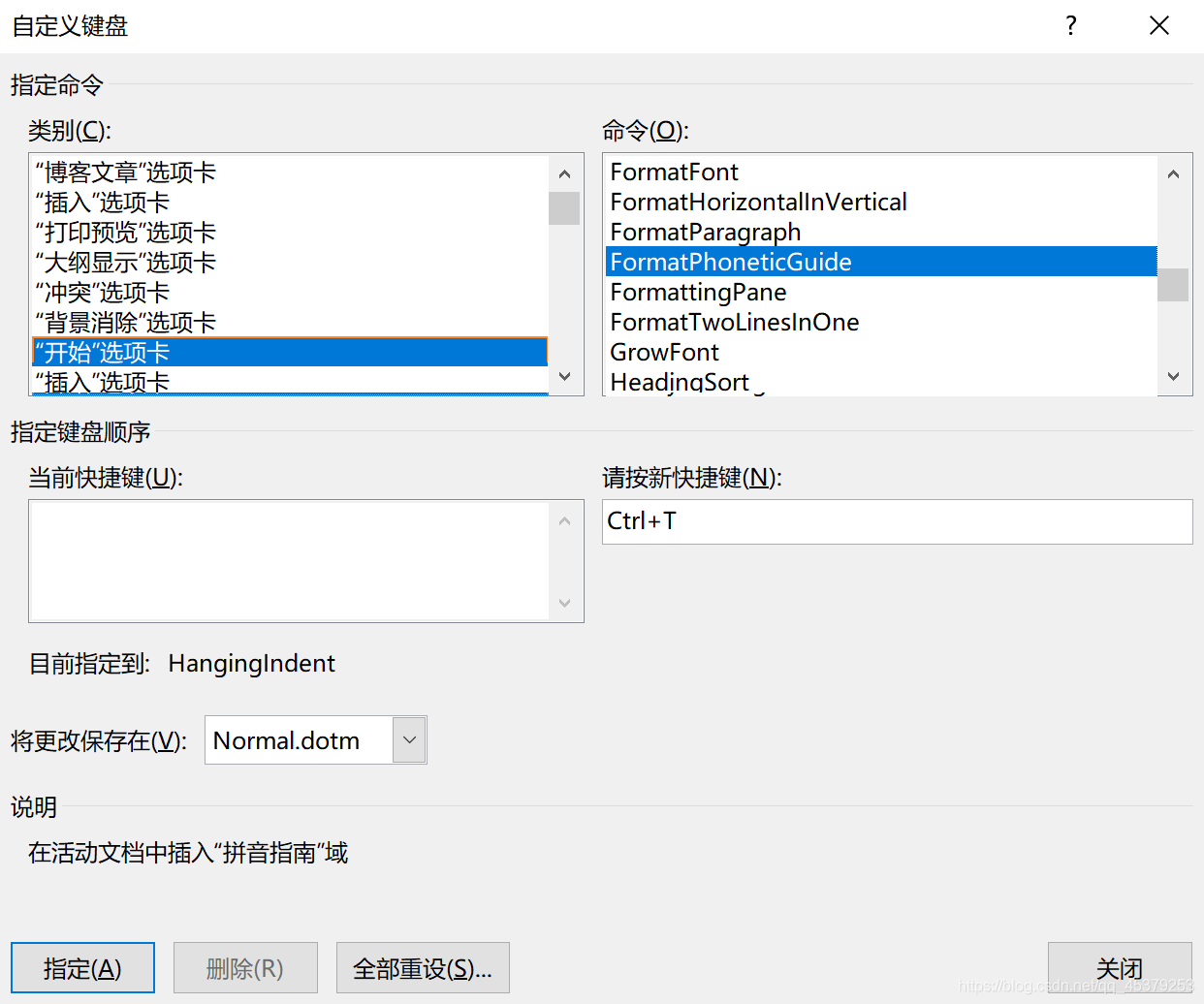
打开Word,点击左上角文件,点击左侧选项,自定义功能区,点击键盘快捷方式右侧的自定义(T)...,在左侧的类别中选择"开始"选项卡,在右侧的命令中选择FormatPhoneticGuide,点击请按新快捷键,敲一个你觉得顺手的快捷键(这里我选择Ctrl+T)。点击指定,关闭窗口回到Word界面,选中 日文文段 后直接按快捷键,就省去了鼠标移到上面点击的麻烦。
macOS
打开 系统偏好设置 キーボード,在下面的界面点击加号
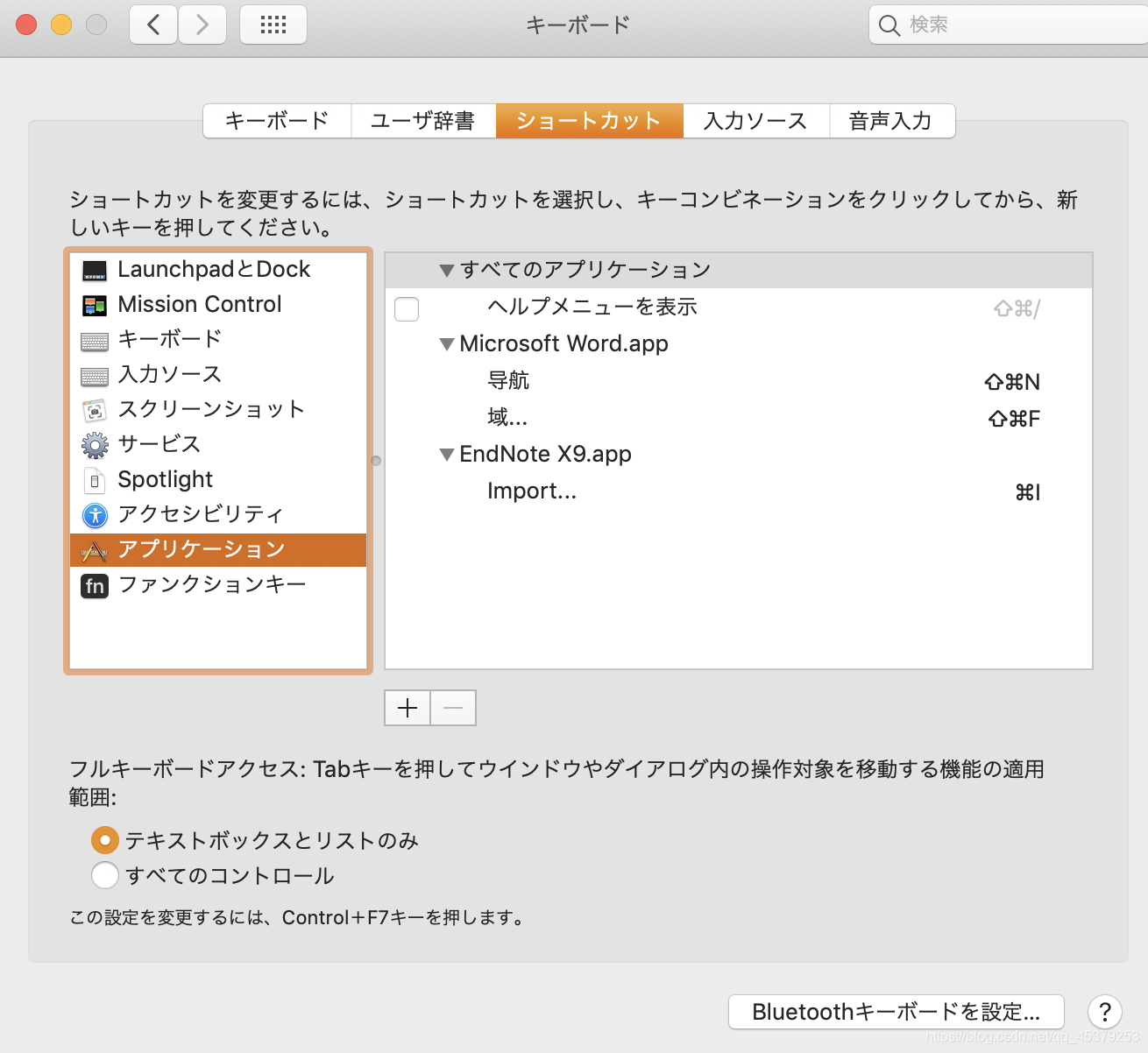
如下图所示,设置一个你觉得方便的快捷键,点击追加。
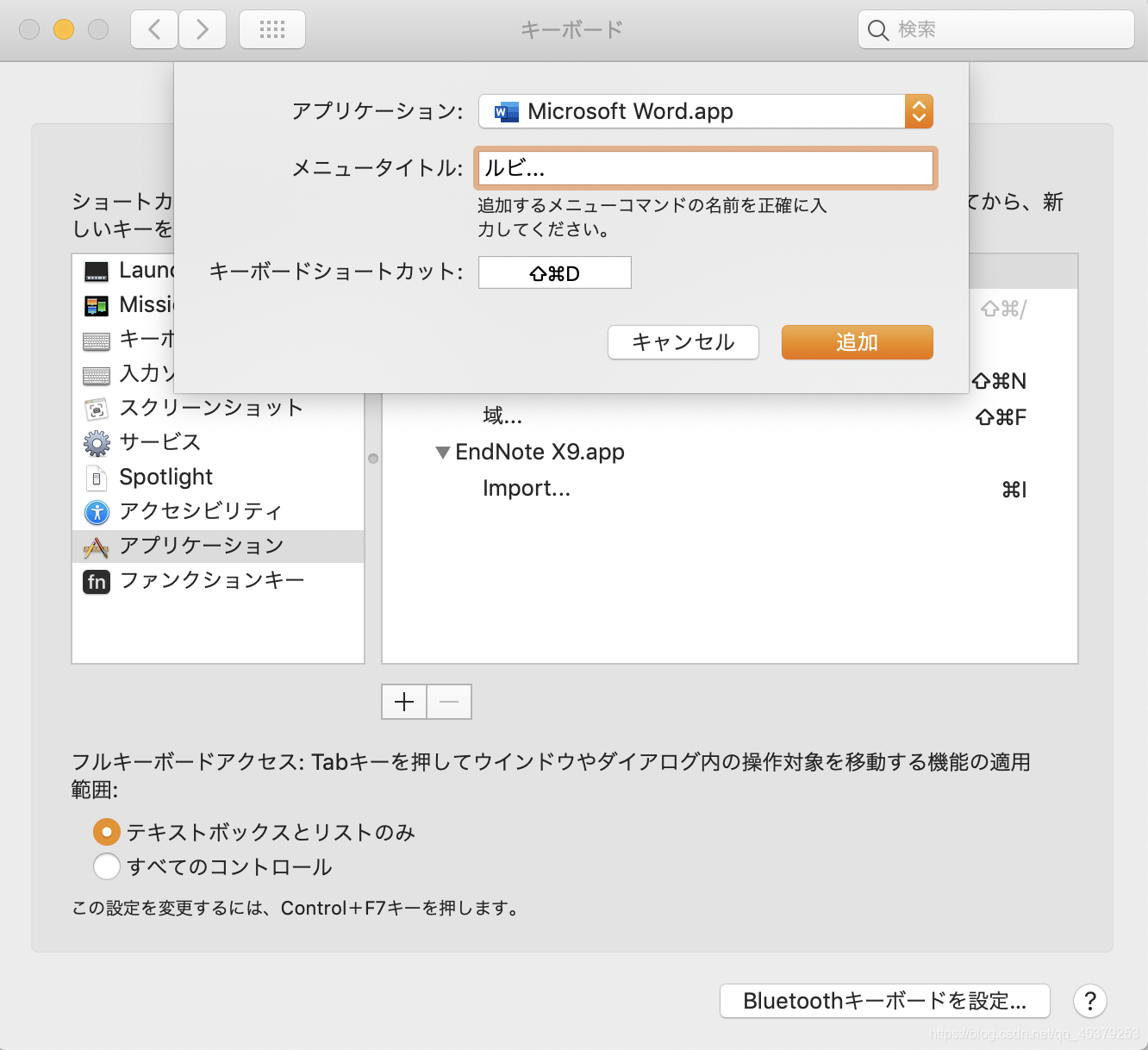
返回Word,选中 日文文段 后直接按快捷键,就省去了鼠标移到上面点击的麻烦。

















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









