









原来的那个github连接🔗死活进不去。。。没关系,还有一篇骨龄的代码是开源的~~~
前言
下面是找到的代码和文章的链接🔗,下面整个系列就是读一下代码,搞懂整个流程,小菜鸡的倔强~~~
文章链接🔗
data_utils.py
首先来看看这个.py文件。
github里的自述文件说的第一步就是运行data_utils.py生成*.npy数据,下面就看看
1.引入库
代码如下:
import numpy as np
import cv2 import os
import pandas as pd
from 6.moves import cPickle
2.标签输入
代码如下(示例):
import numpy as np
import cv2
import os
import pandas as pd
from six.moves import cPickle
# 针对这一问题,有关部门提供的验证和测试数据没有标签,因此将培训数据分为训练集、测试集和验证组
train_dir = '/home/rsna_bone_age/boneage-training-dataset/'
X_train = []
y_age = []
y_gender = []
df = pd.read_csv('/home/rsna_bone_age/boneage-training-dataset.csv')
a = df.values#表格转换为数组
m = a.shape[0]#取出的是img的ID
path = train_dir
k = 0
print ('Loading data set...')
for i in os.listdir(path):#用于返回一个由文件名和目录名组成的列表
y_age.append(df.boneage[df.id == int(i[:-4])].tolist()[0])
a = df.male[df.id == int(i[:-4])].tolist()[0]
if a:#加入性别标签
y_gender.append(1)
else:
y_gender.append(0)
首先使用pd.read_csv读.csv取文件。然后我打印info信息查看表头及是否有信息确实,结果如下。
| # | Column | Non-Null Count | Dtype |
|---|---|---|---|
| 0 | id | 12611 non-null | int64 |
| 1 | boneage | 12611 non-null | int64 |
| 2 | male | 12611 non-null | bool |
然后将表格转换为数组df.as_matrix()报错如下
AttributeError: 'DataFrame' object has no attribute 'as_matrix'
这是因为df.as_matrix()适用于老版本的pandas,官网上更新了,用df.values代替就可。
最后,将y_age、y_gender、x_train录入
df.id == int(i[:-4])
int(i[:-4]) i输出的是xxx.png
i[:-4] 就是输出不带.png
df.id输出如下,但是由于在for里所以循环输出i遍即12611遍
0 1377
1 1378
2 1379
3 1380
4 1381
...
12606 15605
12607 15606
12608 15608
12609 15609
12610 15610
Name: id, Length: 12611, dtype: int64
那么df.id == int(i[:-4])就是判断df.id的输出与int(i[:-4])是不是相等的,返回布尔型,如下
Name: id, Length: 12611, dtype: bool
0 False
1 False
2 False
3 False
4 False
...
12606 False
12607 False
12608 False
12609 False
12610 False
就相当于逐个录入图片的age, 下同
df.boneage[df.id == int(i[:-4])]
输出的就是索引等于True的那一行的boneage
输出如下(只截取了一条)
Name: boneage, dtype: int64
9279 168
df.boneage[df.id == int(i[:-4])].tolist()[0]
加入.tolist()[0]后输出入下。.tolist()[0]将数组或矩阵转化为列表(在矩阵为一维的时候,其余不用加[0])
96
168
168
同理df.male[df.id == int(i[:-4])].tolist()[0]如下
True
True
False
3.图像处理
img_path = path + i#图片的路径 i输出的是xxx.png
img = cv2.imread(img_path)#用于读取图片文件
print (img_path)
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)#将图片转化为RGB
img = cv2.resize(img,(300,300))#输出图片的尺寸
x = np.asarray(img, dtype=np.uint8)# image转换成array
X_train.append(x)
print ('100% completed loading data')
首先读取图像cv2.imread
函数有两个参数,第一个参数是图片路径,第二个参数表示读取图片的形式,有三种:
cv2.IMREAD_COLOR:加载彩色图片,这个是默认参数,可以直接写1。
cv2.IMREAD_GRAYSCALE:以灰度模式加载图片,可以直接写0。
cv2.IMREAD_UNCHANGED:包括alpha,可以直接写-1
cv2.imread()读取图片后已多维数组的形式保存图片信息,前两维表示图片的像素坐标,最后一维表示图片的通道索引,具体图像的通道数由图片的格式来决定
其次cv2.cvtColor(p1,p2)
是颜色空间转换函数,p1是需要转换的图片,p2是转换成何种格式。
cv2.COLOR_BGR2RGB 将BGR格式转换成RGB格式
cv2.COLOR_BGR2GRAY将BGR格式转换成灰度图片
然后cv2.resize()修改图片尺寸
最后np.asarray(img, dtype=np.uint8)# image转换成array
4.将数据存储为.pkl文件
# Save data
train_pkl = open('data.pkl','wb')
cPickle.dump(X_train, train_pkl, protocol=cPickle.HIGHEST_PROTOCOL)
train_pkl.close()
train_age_pkl = open('data_age.pkl','wb')
cPickle.dump(y_age, train_age_pkl, protocol=cPickle.HIGHEST_PROTOCOL)
train_age_pkl.close()
train_gender_pkl = open('data_gender.pkl','wb')
cPickle.dump(y_gender, train_gender_pkl, protocol=cPickle.HIGHEST_PROTOCOL)
train_gender_pkl.close()
python的pickle模块实现了基本的数据序列和反序列化。
通过pickle模块的序列化操作我们能够将程序中运行的对象信息保存到文件中去,永久存储。
通过pickle模块的反序列化操作,我们能够从文件中创建上一次程序保存的对象。
cPickle.dump作用
总结
这个程序就是图像的预处理
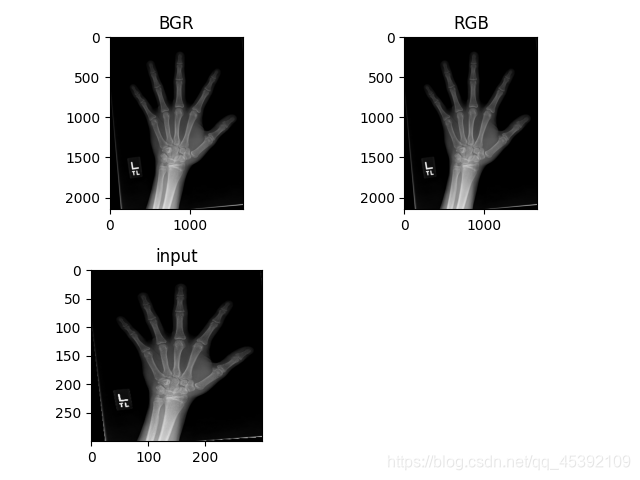
更新

前面可能有理解错误的地方,已经删除。

















 1655
1655

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









