







import requests
import threading
from bs4 import BeautifulSoup
from queue import Queue
def task(queue_1:Queue):
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36",
}
while True:
if queue_1.empty():
break
url=queue_1.get()
content=requests.get(url=url,headers=headers)
content.encoding='utf-8'
content_1=content.text
soup=BeautifulSoup(content_1,'lxml')
ips = soup.select('tr.odd')
ips_1=[];adress_1=[];time_longth=[];time_1=[];ths=[]
for i in range(len(ips)):
ips_1.append(str(ips[i].select('td')[1].get_text())+':'+
str(ips[i].select('td')[2].get_text()))
# 代理ip
adress_1.append(str(ips[i].select('td a')[0].get_text()))
# 地址
time_longth.append(str(ips[i].select('td')[8].get_text()))
# 存活时间
time_1.append(str(ips[i].select('td')[9].get_text()))
# 验证时间
ths.append(str(ips[i].select('td')[5].get_text()))
# 类型 https 或http
for i in range(len(ips_1)):
with open('.\ips.text','a',encoding='utf-8') as f:
f.write(ips_1[i]+'\t'+adress_1[i]+'\t'
+time_longth[i]+'\t'+time_1[i]+'\t'+ths[i]+'\n')
print('-----线程%s爬取%s页上的信息'%(threading.current_thread().getName(),url[url.rfind('/')+1:]))
class Ip(object):
url='https://www.xicidaili.com/nn/%s'
def __init__(self,num):
self.num=num
self.queue_1=Queue(num+100)
def spider(self):
for i in range(1,self.num+1):
url_1=Ip.url%(i)
self.queue_1.put(url_1)
threads=[]
for i in range(self.num):
t=threading.Thread(target=task,args=(self.queue_1,))
t.start()
threads.append(t)
for i in threads:
i.join()
if __name__ == '__main__':
Ips=Ip(3) #当前只爬取西刺代理上三页的所有数据,改变数值,可以爬取多页
# 最大数值为4034
Ips.spider()
print('-----------子线程已完成',threading.current_thread().getName())
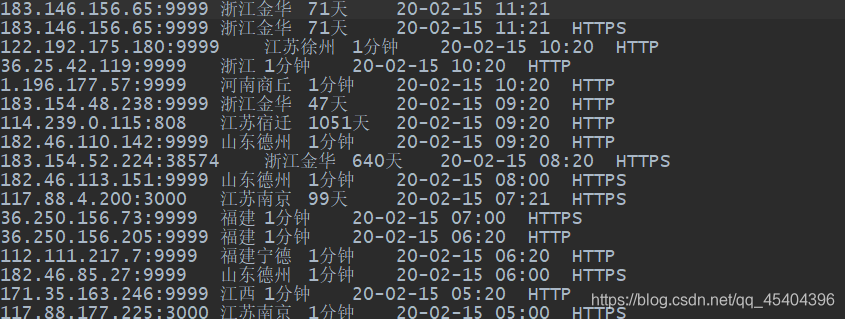
运行结果:

在同一个文件夹下面找到ips.text文件,所爬取的信息在这个文件里面。















 502
502











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











