






原文链接
本文是基于下列博客整合的笔记,有需要的小伙伴可以看原文。
已整合
待整合
一、序言
目前,深度学习(Deep Learning,简称DL)在算法领域可谓是大红大紫,现在不只是互联网、人工智能,生活中的各大领域都能反映出深度学习引领的巨大变革。**要学习深度学习,那么首先要熟悉神经网络(Neural Networks,简称NN)的一些基本概念。**当然,这里所说的神经网络不是生物学的神经网络,我们将其称之为人工神经网络(Artificial Neural Networks,简称ANN)貌似更为合理。神经网络最早是人工智能领域的一种算法或者说是模型,目前神经网络已经发展成为一类多学科交叉的学科领域,它也随着深度学习取得的进展重新受到重视和推崇。
为什么说是“重新”呢?其实,神经网络最为一种算法模型很早就已经开始研究了,但是在取得一些进展后,神经网络的研究陷入了一段很长时间的低潮期,后来随着Hinton在深度学习上取得的进展,神经网络又再次受到人们的重视。本文就**以神经网络为主,着重总结一些相关的基础知识,然后在此基础上引出深度学习的概念**,如有书写不当的地方,还请大家评批指正。
二、神经元模型
神经元是神经网络中最基本的结构,也是神经网络的基本单元,它的设计灵感完全来源于生物学上神经元的信息传播机制。我们学过生物的同学都知道,神经元有两种状态:兴奋和抑制。一般情况下,大多数的神经元是处于抑制状态,但是一旦某个神经元收到刺激,导致它的电位超过一个阈值,那么这个神经元就会被激活,处于“兴奋”状态,进而向其他的神经元传播化学物质(其实就是信息)。
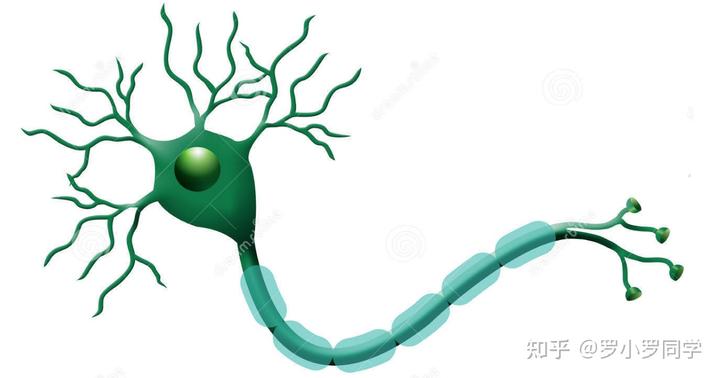
图1 生物学上的神经元结构示意图
1943年,McCulloch和Pitts将上图的神经元结构用一种简单的模型进行了表示,构成了一种人工神经元模型,也就是我们现在经常用到的“M-P神经元模型”,如下图所示:
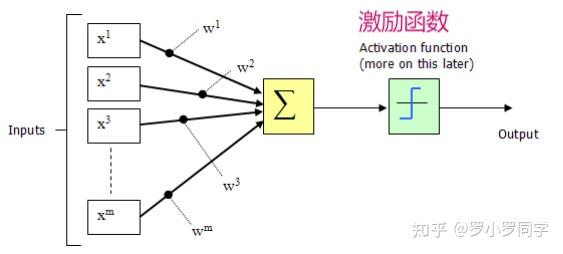
从上图M-P神经元模型可以看出,神经元的输出 y=f(∑i=1mωixi−θ) ,其中 θ 为我们之前提到的神经元的激活阈值,函数f(⋅)也被称为是激活函数。如上图所示,函数f(⋅)可以用一个阶跃方程表示,大于阈值激活;否则则抑制。但是这样有点太粗暴,因为阶跃函数不光滑,不连续,不可导,因此我们更常用的方法是用sigmoid函数来表示函数函数f(⋅)。
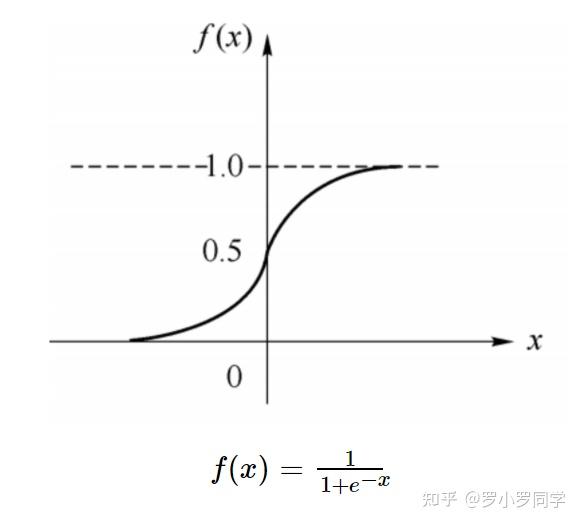
sigmoid函数
三、 感知机和神经网络
感知机(perceptron)是由两层神经元组成的结构,输入层用于接受外界输入信号,输出层(也被称为是感知机的功能层)就是M-P神经元。下图表示了一个输入层具有三个神经元(分别表示为 x0 、 x1 、 x2 )的感知机结构:
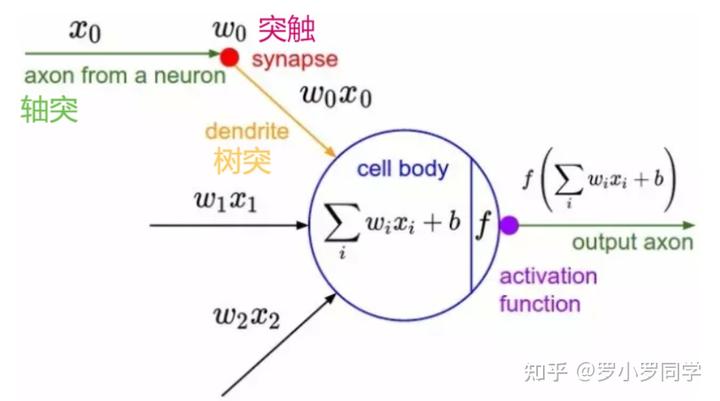
根据上图不难理解,感知机模型可以由如下公式表示:
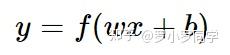
其中, ω 为感知机输入层到输出层连接的权重, b表示输出层的偏置。事实上,感知机是一种判别式的线性分类模型,可以解决与、或、非这样的简单的线性可分(linearly separable)问题,线性可分问题的示意图见下图:
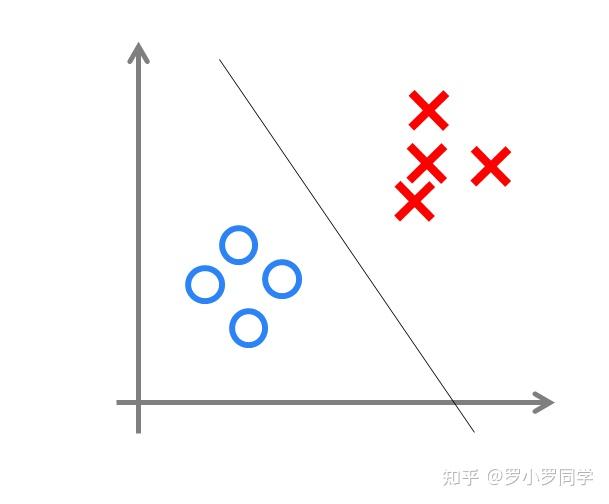
但是由于它只有一层功能神经元,所以学习能力非常有限。事实证明,单层感知机无法解决最简单的非线性可分问题——异或问题。
关于感知机解决异或问题还有一段历史值得我们简单去了解一下:感知器只能做简单的线性分类任务。但是当时的人们热情太过于高涨,并没有人清醒的认识到这点。于是,当人工智能领域的巨擘Minsky指出这点时,事态就发生了变化。Minsky在1969年出版了一本叫《Perceptron》的书,里面用详细的数学证明了感知器的弱点,尤其是感知器对XOR(异或)这样的简单分类任务都无法解决。**Minsky认为,如果将计算层增加到两层,计算量则过大,而且没有有效的学习算法。所以,他认为研究更深层的网络是没有价值的。**由于Minsky的巨大影响力以及书中呈现的悲观态度,让很多学者和实验室纷纷放弃了神经网络的研究。神经网络的研究陷入了冰河期。这个时期又被称为“AI winter”。接近10年以后,对于两层神经网络的研究才带来神经网络的复苏。
我们知道,我们日常生活中很多问题,甚至说大多数问题都不是线性可分问题,那我们要解决非线性可分问题该怎样处理呢?这就是这部分我们要引出的“多层”的概念。既然单层感知机解决不了非线性问题,那我们就采用多层感知机,下图就是一个两层感知机解决异或问题的示意图:

构建好上述网络以后,通过训练得到最后的分类面如下:
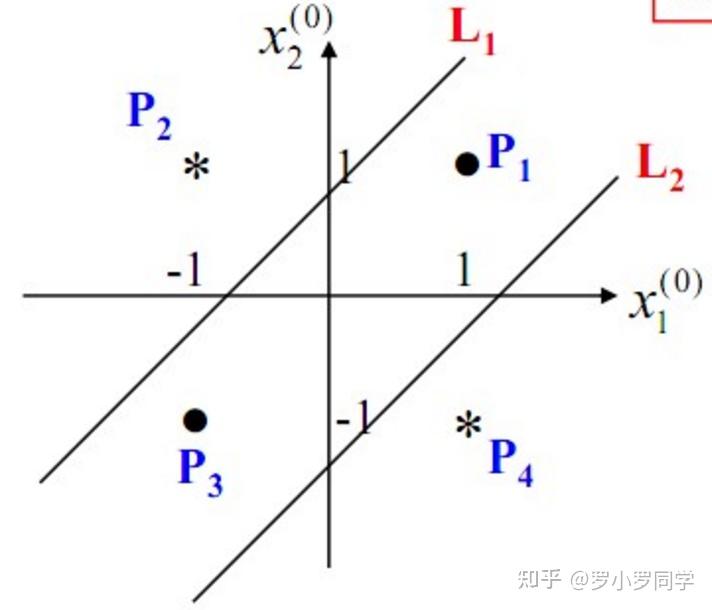
由此可见,多层感知机可以很好的解决非线性可分问题,我们**通常将多层感知机这样的多层结构称之为是神经网络。但是,正如Minsky之前所担心的,多层感知机虽然可以在理论上可以解决非线性问题,但是实际生活中问题的复杂性要远不止异或问题这么简单,所以我们往往要构建多层网络,而对于多层神经网络采用什么样的学习算法又是一项巨大的挑战**,如下图所示的具有4层隐含层的网络结构中至少有33个参数(不计偏置bias参数),我们应该如何去确定呢?
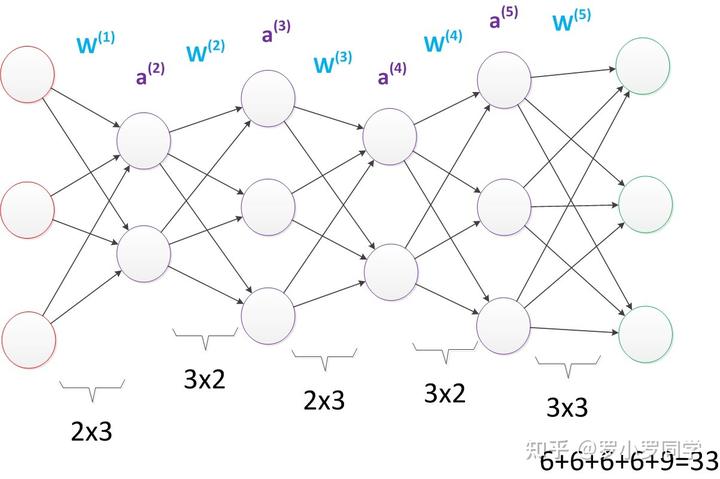
上述33个参数指的是“权重”
四、误差逆传播算法
所谓神经网络的训练或者是学习,其主要目的在于通过学习算法得到神经网络解决指定问题所需的参数,这里的参数包括各层神经元之间的连接权重以及偏置等。因为作为算法的设计者(我们),我们通常是根据实际问题来构造出网络结构,参数的确定则需要神经网络通过训练样本和学习算法来迭代找到最优参数组。
说起神经网络的学习算法,不得不提其中最杰出、最成功的代表——误差逆传播(error BackPropagation,简称BP)算法。BP学习算法通常用在最为广泛使用的多层前馈神经网络中。

前馈神经网络
前馈神经网络(feedforward neural network,FNN),简称前馈网络,是人工神经网络的一种。前馈神经网络采用一种单向多层结构。其中每一层包含若干个神经元。在此种神经网络中,各神经元可以接收前一层神经元的信号,并产生输出到下一层。第0层叫输入层,最后一层叫输出层,其他中间层叫做隐含层(或隐藏层、隐层)。隐层可以是一层。也可以是多层 。整个网络中无反馈,信号从输入层向输出层单向传播,可用一个有向无环图表示。
BP算法的主要流程可以总结如下:

本文直接举一个例子,代入数值演示反向传播法的过程
假设,你有这样一个网络层:

| 输入层 | 隐含层 | 输出层 | 权重 | 激活函数 |
|---|---|---|---|---|
| 包含两个神经元i1,i2,和截距项b1 | 包含两个神经元h1,h2和截距项b2 | 输出o1,o2 | 每条线上标的wi是层与层之间连接的权重 | 默认为sigmoid函数 |
现在对他们赋上初值,如下图:
注意:各层的权重总和并不为1
| 输入数据 | i1=0.05 | i2=0.10 | ||
|---|---|---|---|---|
| 输出数据 | o1=0.01 | o2=0.99 | ||
| 初始权重 | w1=0.15 w2=0.20 | w3=0.25 w4=0.30 | w5=0.40 w6=0.45 | w7=0.50 w8=0.55 |
目标:给出输入数据i1,i2(0.05和0.10),使输出尽可能与原始输出o1,o2(0.01和0.99)接近。
Step 1 前向传播
——1.输入层---->隐含层:
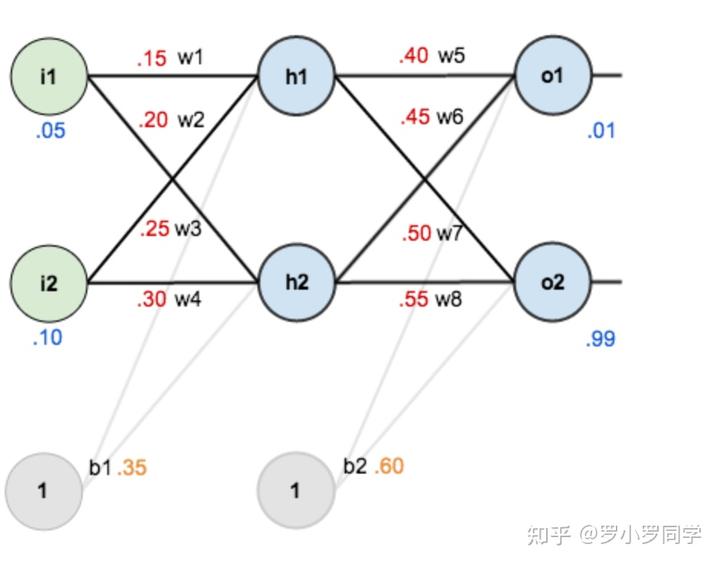
计算神经元h1的输入加权和:
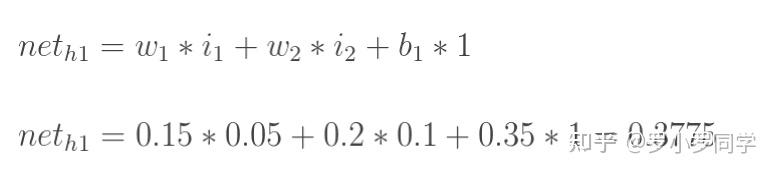
神经元h1的输出o1:(此处用到激活函数为sigmoid函数):
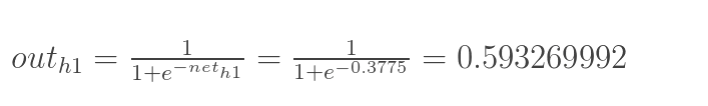
同理,可计算出神经元h2的输出o2:

计算过程
——2.隐含层---->输出层:
计算输出层神经元o1和o2的值:
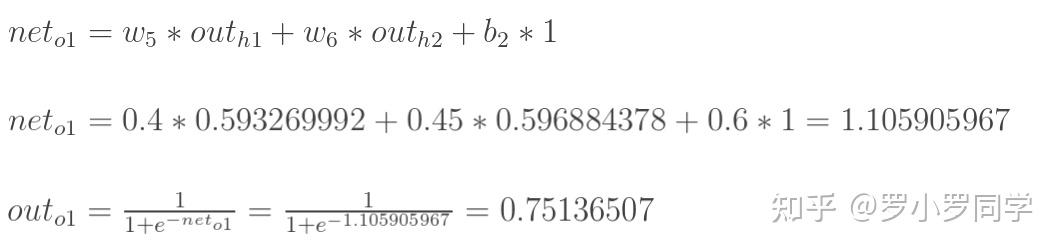

OUTo2的值(e没显示出来)
这样前向传播的过程就结束了,我们得到输出值为[0.75136079 , 0.772928465],与实际值[0.01 , 0.99]相差还很远,现在我们对误差进行反向传播,更新权值,重新计算输出。
Step 2 反向传播
——1.计算总误差
总误差:(square error)

但是有两个输出,所以分别计算o1和o2的误差,总误差为两者之和:
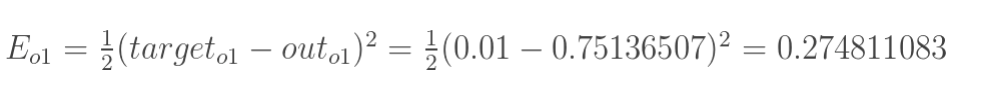

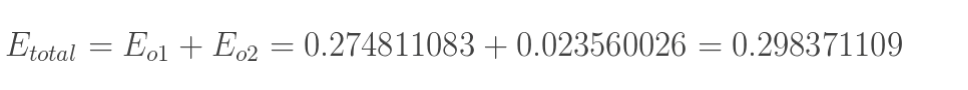
——2.隐含层---->输出层的权值更新:
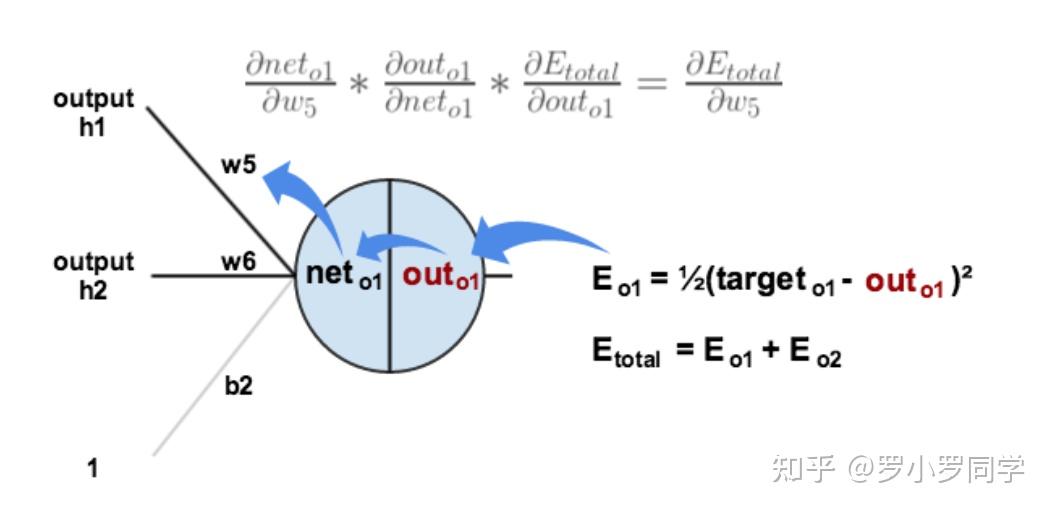
以权重参数 ω5 为例,如果我们想知道 ω5 对整体误差产生了多少影响,可以用整体误差对 ω5 求偏导求出:(链式法则)

下面的图可以更直观的看清楚误差是怎样反向传播的:
现在我们来分别计算每个式子的值:
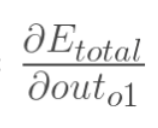
1
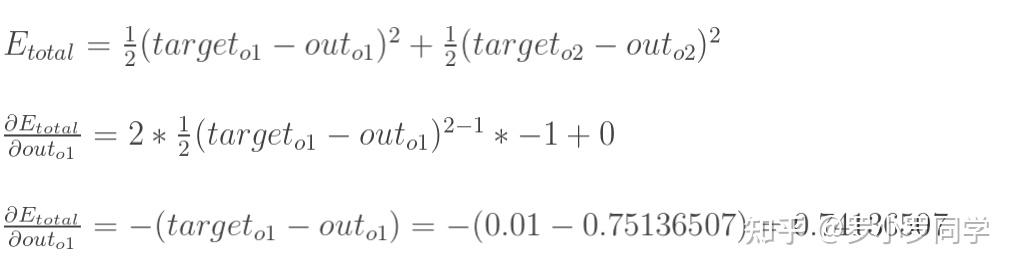
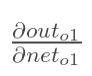
2

(这一步实际上就是对sigmoid函数求导,比较简单,可以自己推导一下)
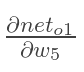
3
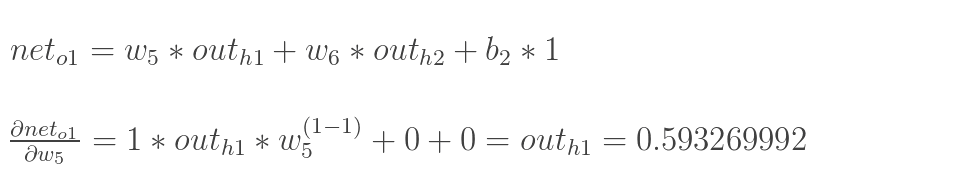
最后三者相乘:

这样我们就计算出整体误差E(total)对w5的偏导值。
回过头来再看看上面的公式,我们发现:
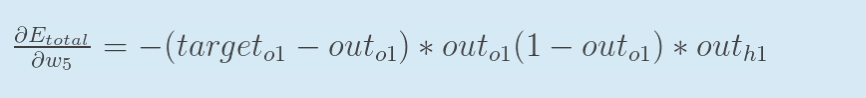
把求完偏导数之后的式子相乘即可
为了表达方便,用 δo1 来表示输出层的误差:
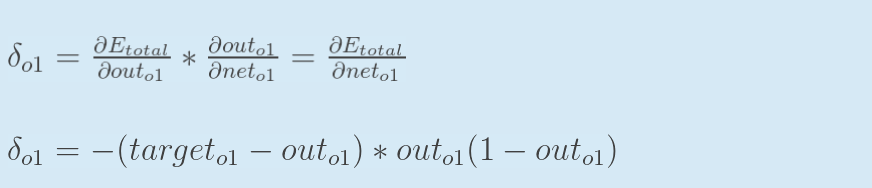
因此,整体误差E(total)对w5的偏导公式可以写成:

最后我们来更新w5的值:
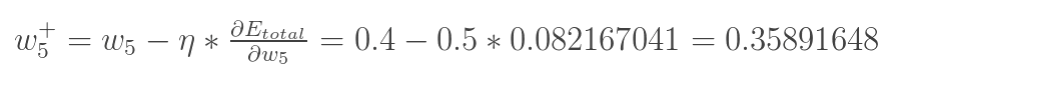
(其中, η 是学习速率,这里我们取0.5)
同理,可更新w6,w7,w8:

——3.隐含层---->隐含层的权值更新:
方法其实与上面说的差不多,但是有个地方需要变一下,在上文计算总误差对w5的偏导时,是从out(o1)---->net(o1)---->w5,但是在隐含层之间的权值更新时,是out(h1)---->net(h1)---->w1,而out(h1)会接受E(o1)和E(o2)两个地方传来的误差,所以这个地方两个都要计算。
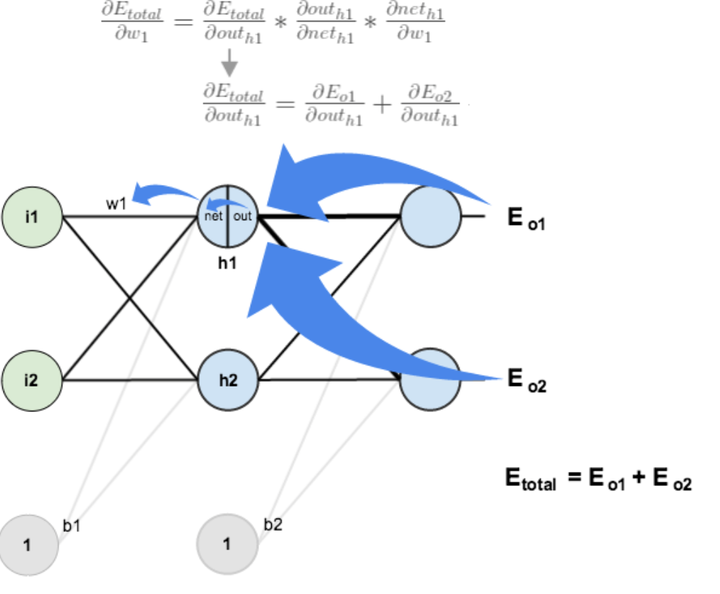
现在我们来分别计算每个式子的值:

1

计算
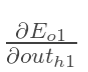
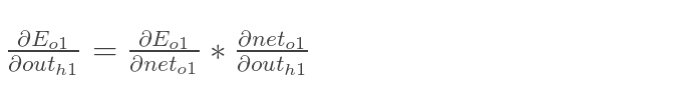

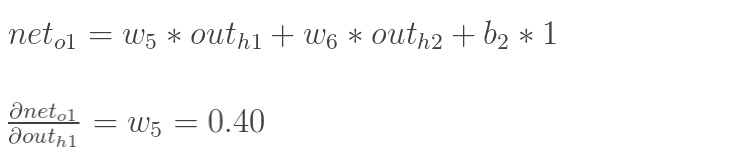

同理,计算出:
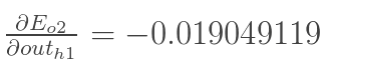
两者相加得到总值:
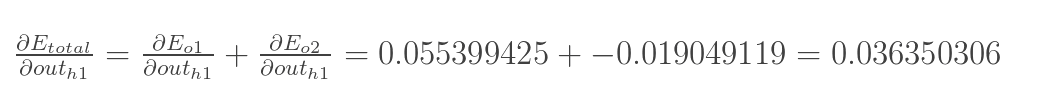
再计算
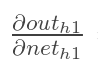
2

再计算
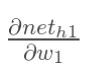
3
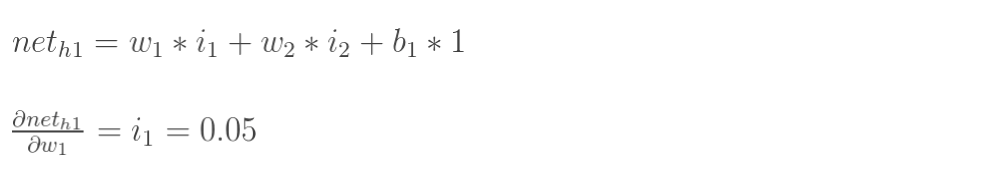
最后,三者相乘:

为了简化公式,用 δh1 表示隐含层单元h1的误差:

最后,更新w1的权值:

同理,可更新w2,w3,w4的权值:

这样误差反向传播法就完成了,最后我们再把更新的权值重新计算,不停地迭代,在这个例子中第一次迭代之后,总误差E(total)由0.298371109下降至0.291027924。迭代10000次后,总误差为0.000035085,输出为[0.015912196,0.984065734](原输入为[0.01,0.99]),证明效果还是不错的。
扩展1 代码实现
#coding:utf-8 import random import math # # 参数解释: # "pd_" :偏导的前缀 # "d_" :导数的前缀 # "w_ho" :隐含层到输出层的权重系数索引 # "w_ih" :输入层到隐含层的权重系数的索引 class NeuralNetwork: LEARNING_RATE = 0.5 def __init__(self, num_inputs, num_hidden, num_outputs, hidden_layer_weights = None, hidden_layer_bias = None, output_layer_weights = None, output_layer_bias = None): self.num_inputs = num_inputs self.hidden_layer = NeuronLayer(num_hidden, hidden_layer_bias) self.output_layer = NeuronLayer(num_outputs, output_layer_bias) self.init_weights_from_inputs_to_hidden_layer_neurons(hidden_layer_weights) self.init_weights_from_hidden_layer_neurons_to_output_layer_neurons(output_layer_weights) def init_weights_from_inputs_to_hidden_layer_neurons(self, hidden_layer_weights): weight_num = 0 for h in range(len(self.hidden_layer.neurons)): for i in range(self.num_inputs): if not hidden_layer_weights: self.hidden_layer.neurons[h].weights.append(random.random()) else: self.hidden_layer.neurons[h].weights.append(hidden_layer_weights[weight_num]) weight_num += 1 def init_weights_from_hidden_layer_neurons_to_output_layer_neurons(self, output_layer_weights): weight_num = 0 for o in range(len(self.output_layer.neurons)): for h in range(len(self.hidden_layer.neurons)): if not output_layer_weights: self.output_layer.neurons[o].weights.append(random.random()) else: self.output_layer.neurons[o].weights.append(output_layer_weights[weight_num]) weight_num += 1 def inspect(self): print('------') print('* Inputs: {}'.format(self.num_inputs)) print('------') print('Hidden Layer') self.hidden_layer.inspect() print('------') print('* Output Layer') self.output_layer.inspect() print('------') def feed_forward(self, inputs): hidden_layer_outputs = self.hidden_layer.feed_forward(inputs) return self.output_layer.feed_forward(hidden_layer_outputs) def train(self, training_inputs, training_outputs): self.feed_forward(training_inputs) # 1. 输出神经元的值 pd_errors_wrt_output_neuron_total_net_input = [0] * len(self.output_layer.neurons) for o in range(len(self.output_layer.neurons)): # ∂E/∂zⱼ pd_errors_wrt_output_neuron_total_net_input[o] = self.output_layer.neurons[o].calculate_pd_error_wrt_total_net_input(training_outputs[o]) # 2. 隐含层神经元的值 pd_errors_wrt_hidden_neuron_total_net_input = [0] * len(self.hidden_layer.neurons) for h in range(len(self.hidden_layer.neurons)): # dE/dyⱼ = Σ ∂E/∂zⱼ * ∂z/∂yⱼ = Σ ∂E/∂zⱼ * wᵢⱼ d_error_wrt_hidden_neuron_output = 0 for o in range(len(self.output_layer.neurons)): d_error_wrt_hidden_neuron_output += pd_errors_wrt_output_neuron_total_net_input[o] * self.output_layer.neurons[o].weights[h] # ∂E/∂zⱼ = dE/dyⱼ * ∂zⱼ/∂ pd_errors_wrt_hidden_neuron_total_net_input[h] = d_error_wrt_hidden_neuron_output * self.hidden_layer.neurons[h].calculate_pd_total_net_input_wrt_input() # 3. 更新输出层权重系数 for o in range(len(self.output_layer.neurons)): for w_ho in range(len(self.output_layer.neurons[o].weights)): # ∂Eⱼ/∂wᵢⱼ = ∂E/∂zⱼ * ∂zⱼ/∂wᵢⱼ pd_error_wrt_weight = pd_errors_wrt_output_neuron_total_net_input[o] * self.output_layer.neurons[o].calculate_pd_total_net_input_wrt_weight(w_ho) # Δw = α * ∂Eⱼ/∂wᵢ self.output_layer.neurons[o].weights[w_ho] -= self.LEARNING_RATE * pd_error_wrt_weight # 4. 更新隐含层的权重系数 for h in range(len(self.hidden_layer.neurons)): for w_ih in range(len(self.hidden_layer.neurons[h].weights)): # ∂Eⱼ/∂wᵢ = ∂E/∂zⱼ * ∂zⱼ/∂wᵢ pd_error_wrt_weight = pd_errors_wrt_hidden_neuron_total_net_input[h] * self.hidden_layer.neurons[h].calculate_pd_total_net_input_wrt_weight(w_ih) # Δw = α * ∂Eⱼ/∂wᵢ self.hidden_layer.neurons[h].weights[w_ih] -= self.LEARNING_RATE * pd_error_wrt_weight def calculate_total_error(self, training_sets): total_error = 0 for t in range(len(training_sets)): training_inputs, training_outputs = training_sets[t] self.feed_forward(training_inputs) for o in range(len(training_outputs)): total_error += self.output_layer.neurons[o].calculate_error(training_outputs[o]) return total_error class NeuronLayer: def __init__(self, num_neurons, bias): # 同一层的神经元共享一个截距项b self.bias = bias if bias else random.random() self.neurons = [] for i in range(num_neurons): self.neurons.append(Neuron(self.bias)) def inspect(self): print('Neurons:', len(self.neurons)) for n in range(len(self.neurons)): print(' Neuron', n) for w in range(len(self.neurons[n].weights)): print(' Weight:', self.neurons[n].weights[w]) print(' Bias:', self.bias) def feed_forward(self, inputs): outputs = [] for neuron in self.neurons: outputs.append(neuron.calculate_output(inputs)) return outputs def get_outputs(self): outputs = [] for neuron in self.neurons: outputs.append(neuron.output) return outputs class Neuron: def __init__(self, bias): self.bias = bias self.weights = [] def calculate_output(self, inputs): self.inputs = inputs self.output = self.squash(self.calculate_total_net_input()) return self.output def calculate_total_net_input(self): total = 0 for i in range(len(self.inputs)): total += self.inputs[i] * self.weights[i] return total + self.bias # 激活函数sigmoid def squash(self, total_net_input): return 1 / (1 + math.exp(-total_net_input)) def calculate_pd_error_wrt_total_net_input(self, target_output): return self.calculate_pd_error_wrt_output(target_output) * self.calculate_pd_total_net_input_wrt_input(); # 每一个神经元的误差是由平方差公式计算的 def calculate_error(self, target_output): return 0.5 * (target_output - self.output) ** 2 def calculate_pd_error_wrt_output(self, target_output): return -(target_output - self.output) def calculate_pd_total_net_input_wrt_input(self): return self.output * (1 - self.output) def calculate_pd_total_net_input_wrt_weight(self, index): return self.inputs[index] # 文中的例子: nn = NeuralNetwork(2, 2, 2, hidden_layer_weights=[0.15, 0.2, 0.25, 0.3], hidden_layer_bias=0.35, output_layer_weights=[0.4, 0.45, 0.5, 0.55], output_layer_bias=0.6) for i in range(10000): nn.train([0.05, 0.1], [0.01, 0.09]) print(i, round(nn.calculate_total_error([[[0.05, 0.1], [0.01, 0.09]]]), 9)) #另外一个例子,可以把上面的例子注释掉再运行一下: # training_sets = [ # [[0, 0], [0]], # [[0, 1], [1]], # [[1, 0], [1]], # [[1, 1], [0]] # ] # nn = NeuralNetwork(len(training_sets[0][0]), 5, len(training_sets[0][1])) # for i in range(10000): # training_inputs, training_outputs = random.choice(training_sets) # nn.train(training_inputs, training_outputs) # print(i, nn.calculate_total_error(training_sets))
扩展2 手推过程




五、常见的神经网络模型
5.1 Boltzmann机和受限Boltzmann机
神经网络中有一类模型是为网络状态定义一个“能量”,能量最小化时网络达到理想状态,而网络的训练就是在最小化这个能量函数。
Boltzmann(玻尔兹曼)机就是基于能量的模型,其神经元分为两层:
| 显层 | 隐层 |
|---|---|
| 用于表示数据的输入和输出 | 数据的内在表达 |
Boltzmann机的神经元都是布尔型的,即只能取0、1值。标准的Boltzmann机是全连接的,也就是说各层内的神经元都是相互连接的,因此计算复杂度很高,而且难以用来解决实际问题。因此,我们经常使用一种特殊的Boltzmann机——受限玻尔兹曼机(Restricted Boltzmann Mechine,简称RBM),它层内无连接,层间有连接,可以看做是一个二部图。下图为Boltzmann机和RBM的结构示意图:
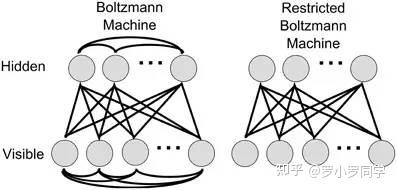
RBM常常用**对比散度(Constrastive Divergence,简称CD)**来进行训练。
对比散度的分析见下一篇笔记:
5.2 RBF网络
RBF(Radial Basis Function)径向基函数网络是一种单隐层前馈神经网络,它使用径向基函数作为隐层神经元激活函数,而输出层则是对隐层神经元输出的线性组合。下图为一个RBF神经网络示意图:

径向基函数网络
训练RBF网络通常采用两步:
1> 确定神经元中心,常用的方式包括随机采样,聚类等;
2> 确定神经网络参数,常用算法为BP算法。
5.3 ART网络
ART(Adaptive Resonance Theory)自适应谐振理论网络是竞争型学习的重要代表,该网络由**比较层、识别层、识别层阈值和重置模块**构成。ART比较好的缓解了竞争型学习中的“可塑性-稳定性窘境”(stability-plasticity dilemma),可塑性是指神经网络要有学习新知识的能力,而稳定性则指的是神经网络在学习新知识时要保持对旧知识的记忆。这就使得ART网络具有一个很重要的优点:可进行增量学习或在线学习。
5.4 SOM网络
SOM(Self-Organizing Map,自组织映射)网络是一种竞争学习型的无监督神经网络,它能将高维输入数据映射到低维空间(通常为二维),同时保持输入数据在高维空间的拓扑结构,即将高维空间中相似的样本点映射到网络输出层中的临近神经元。下图为SOM网络的结构示意图:
5.5 结构自适应网络
我们前面提到过,一般的神经网络都是先指定好网络结构,训练的目的是利用训练样本来确定合适的连接权、阈值等参数。与此不同的是,结构自适应网络则将网络结构也当做学习的目标之一,并希望在训练过程中找到最符合数据特点的网络结构。
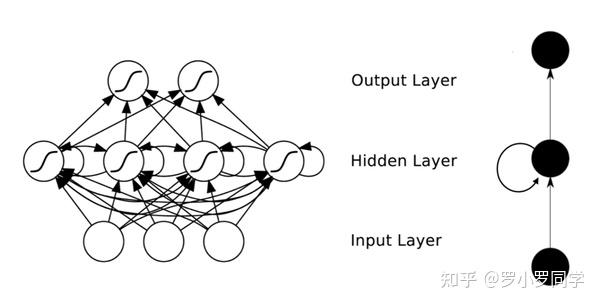
5.6 递归神经网络以及Elman网络
与前馈神经网络不同,递归神经网络(Recurrent Neural Networks,简称RNN)允许网络中出现环形结构,从而可以让一些神经元的输出反馈回来作为输入信号,这样的结构与信息反馈过程,使得网络在 t 时刻的输出状态不仅与 t 时刻的输入有关,还与 t−1 时刻的网络状态有关,从而能处理与时间有关的动态变化。
Elman网络是最常用的递归神经网络之一,其结构如下图所示:
RNN一般的训练算法采用推广的BP算法。值得一提的是,RNN在(t+1)时刻网络的结果O(t+1)是该时刻输入和所有历史共同作用的结果,这样就达到了对时间序列建模的目的。因此,从某种意义上来讲,RNN被视为是时间深度上的深度学习也未尝不对。
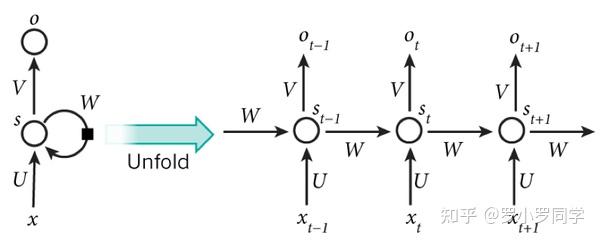
RNN在(t+1)时刻网络的结果O(t+1)是该时刻输入和所有历史共同作用的结果,这么讲其实也不是很准确,因为“梯度发散”同样也会发生在时间轴上,也就是说对于 t 时刻来说,它产生的梯度在时间轴上向历史传播几层之后就消失了,根本无法影响太遥远的过去。因此,“所有的历史”只是理想的情况。在实际中,这种影响也就只能维持若干个时间戳而已。换句话说,后面时间步的错误信号,往往并不能回到足够远的过去,像更早的时间步一样,去影响网络,这使它很难以学习远距离的影响。
为了解决上述时间轴上的梯度发散,机器学习领域发展出了长短时记忆单元(Long-Short Term Memory,简称LSTM),通过门的开关实现时间上的记忆功能,并防止梯度发散。其实除了学习历史信息,RNN和LSTM还可以被设计成为双向结构,即双向RNN、双向LSTM,同时利用历史和未来的信息。
六、从零开始实现一个简单的神经网络
6.0 参考资料
6.1 前言
七、深度学习
深度学习指的是深度神经网络模型,一般指网络层数在三层或者三层以上的神经网络结构。
理论上而言,参数越多的模型复杂度越高,“容量”也就越大,也就意味着它能完成更复杂的学习任务。就像前面多层感知机带给我们的启示一样,神经网络的层数直接决定了它对现实的刻画能力。但是在一般情况下,复杂模型的训练效率低,易陷入过拟合,因此难以受到人们的青睐。具体来讲就是,随着神经网络层数的加深,优化函数越来越容易陷入局部最优解(即过拟合,在训练样本上有很好的拟合效果,但是在测试集上效果很差)。同时,不可忽略的一个问题是随着网络层数增加,“梯度消失”(或者说是梯度发散diverge)现象更加严重。我们经常使用sigmoid函数作为隐含层的功能神经元,**对于幅度为1的信号,在BP反向传播梯度时,每传递一层,梯度衰减为原来的0.25。**层数一多,梯度指数衰减后低层基本接收不到有效的训练信号。
为了解决深层神经网络的训练问题,一种有效的手段是采取无监督逐层训练(unsupervised layer-wise training),其基本思想是每次训练一层隐节点,训练时将上一层隐节点的输出作为输入,而本层隐节点的输出作为下一层隐节点的输入,这被称之为**“预训练”**(pre-training);在预训练完成后,再对整个网络进行“微调”(fine-tunning)训练。比如Hinton在深度信念网络(Deep Belief Networks,简称DBN)中,每层都是一个RBM,即整个网络可以被视为是若干个RBM堆叠而成。
在使用无监督训练时,首先训练第一层,这是关于训练样本的RBM模型,可按标准的RBM进行训练;然后,将第一层预训练号的隐节点视为第二层的输入节点,对第二层进行预训练;… 各层预训练完成后,再利用BP算法对整个网络进行训练。
事实上,“预训练+微调”的训练方式可被视为是将大量参数分组,对每组先找到局部看起来较好的设置,然后再基于这些局部较优的结果联合起来进行全局寻优。这样就在利用了模型大量参数所提供的自由度的同时,有效地节省了训练开销。
另一种节省训练开销的做法是进行“权共享”(weight sharing),即让一组神经元使用相同的连接权,这个策略在卷积神经网络(Convolutional Neural Networks,简称CNN)中发挥了重要作用。下图为一个CNN网络示意图:
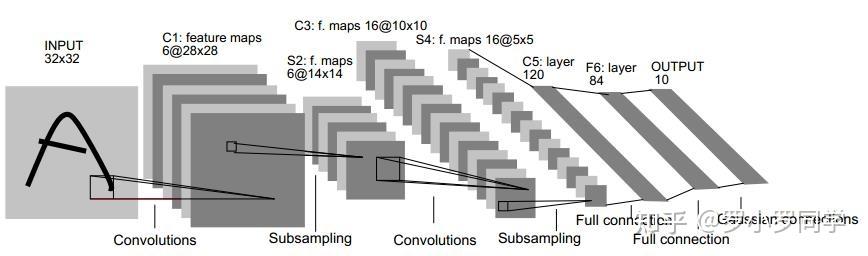
CNN可以用BP算法进行训练,但是在训练中,无论是卷积层还是采样层,其每组神经元(即上图中的每一个“平面”)都是用相同的连接权,从而大幅减少了需要训练的参数数目。

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









