







小罗碎碎念
今天分享的文章是前两天在公众号刷到的,我现在是看到AI病理相关的,就会保存下来,一有时间就去研究一下,哈哈。
好,说回正题,这篇文章是北航发表在IEEE上的一篇文章——Nucleus-Aware Self-Supervised Pretraining Using Unpaired Image-to-Image Translation for Histopathology Images 。

文章概述
标题翻译一下——利用组织病理学图像的**非配对图像到图像转换进行细胞核感知自监督预训练"——论文介绍了一种用于组织病理学图像自监督预训练的新型框架,该框架侧重于捕捉病理分析所必需的细胞核级信息**。
所提出的方法利用组织病理学图像和**伪掩膜图像之间无配对的图像到图像转换来提取核形态和分布信息**。通过使用条件和随机风格表示法调节生成过程,该框架可确保生成图像的真实性和多样性,以便进行预训练。
此外,还采用了**实例分割引导策略**来捕捉实例级信息。在 7 个数据集上的实验结果表明,所提出的预训练方法在各种任务中的表现优于有监督的方法,展示了它在提高模型性能方面的有效性。
文章要点
- 为组织病理学图像引入了一种新颖的细胞核感知自监督预训练框架
- 利用图像间的非配对转换捕捉核形态和分布信息
- 利用条件和随机风格表示法对生成过程进行调制,以生成逼真和多样化的图像
- 采用实例分割引导策略捕捉实例级信息
- 在 Kather 分类、多实例学习和密集预测任务上的表现优于监督方法
- 与其他自我监督方法相比,在迁移学习和半监督任务中取得了优异成绩
- 本文探讨了组织病理学图像中细胞核级信息的重要性,并提出了一种通过自我监督预训练显著提高模型性能的方法
源码&论文分享
下期推文预告

本文涉及的公开数据集汇总
一、引言
组织病理学在几乎所有癌症类型的诊断、预后和治疗反应分析中起着关键作用[1],[2]。在**计算机辅助病理诊断(CAPD)领域,全监督深度模型在各类病理学相关任务中占据主导地位,包括癌症分类[3]、细胞核分割[4]和分子亚型识别[5]。然而,这些模型依赖于大量的注释**,特别是对于需要实例级注释的密集预测任务。幸运的是,获取未标记的组织病理学图像相对容易,预计这些图像能被正确利用,以减轻专业注释者的负担。
一种最受欢迎的方法是**自监督预训练,它从无标签数据中学习到泛化的表示。它可以大致分为判别式和生成式。目前,判别式自监督预训练主要由对比学习方法主导,如SimCLR[6],MoCo v2[7]和SimSiam[8]。另一方面,生成式自监督预训练的最新发展基于去噪自编码器[9],它们使用编码器-解码器架构来重建被破坏的图像[10],[11],[12]。尽管破坏过程可能适用于通常包含大型前景对象且背景多变的自然图像,但它并不适用于组织病理学图像。简单地破坏组织病理学图像会导致核的丢失**,这对于癌症的识别、分级和预后至关重要[1]。对于CAPD相关任务,尤其是密集预测任务,核的重要性也无需过多强调[4],[13],[14],[15],[16],[17]。因此,在为组织病理学图像定制自监督预训练时,需要关注这些小实例。
作为生成式预训练的延伸,利用生成对抗网络(GAN)的对抗性预训练提供了核感知预训练的可能性。它不仅避免了破坏过程,还学习了下游任务的数据分布先验。大多数相关作品采用了**双向框架**,通过额外的编码器扩展GAN[18],[19],[20],如图1(a)所示。
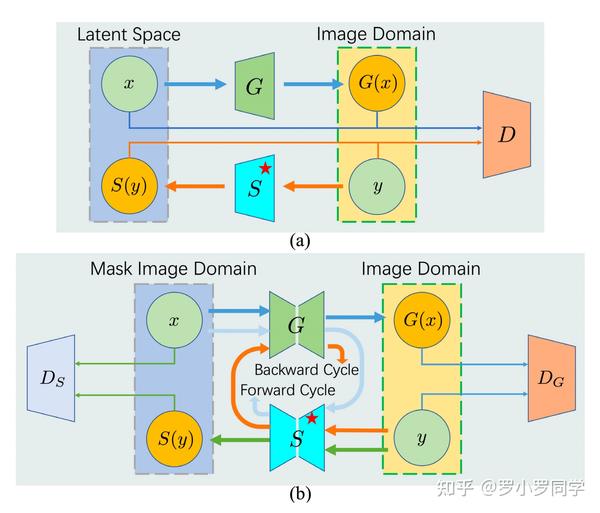
然而,GAN的潜在空间对于**细粒度表示学习来说过于抽象和冗余,这阻碍了它们在密集预测任务上的性能。鉴于GAN可以充当语义分段器[14],[21],其过程也可以被视为从图像到其对应掩模的图像到图像转换,原始的潜在空间可以替换为更具体的表示,即核掩模图像。这种设计对于组织病理学图像是可行的,因为合成掩模图像的成本较低[14]。这样,框架自然地转变为非配对图像到图像转换**(UNIT),并有望捕捉到核级信息。
如图1(b)所示,Cycle-GAN[22]作为一个简单而有效的UNIT框架,实现了该设计。它也由两个网络组成,这些网络以相反的方式学习,类似于双向框架。主要区别在于循环一致性,它调节转换并指导网络捕捉语义信息。此外,两个生成器都采用编码器-解码器架构,这允许为密集预测任务初始化解码器。
已经探索到,对抗性预训练的性能与生成图像的质量密切相关[20]。因此,如果我们只使用传统的Cycle-GAN进行预训练,其随机性非常有限,很难获得最佳性能。为了克服这个挑战,一个解决方案是用条件性和随机性风格表示共同调节合成过程,这确保了条件对应和内部条件多样性。这种共调节设计最初由CoModGAN[23]提出,这是最先进的大规模图像补全网络。通过将这种设计纳入对抗性预训练框架,由于生成图像质量的提高,性能有望显著提高。
值得注意的是,另一个生成器S作为预训练模型。尽管循环一致性用于强制执行条件约束,但它可能无法保证掩模图像和生成图像之间的完美匹配。类似于之前通过分割指导增强生成过程的工作[24],[25],[26],将分割任务纳入预训练框架是有利的。然而,仅依赖语义分割可能不足以提供有效信息,因为**从组织病理学图像到掩模图像的转换可以被视为一种语义分割**,如前所述。考虑到我们可以方便地从掩模图像中获得实例级地面真实情况,可以在预训练框架中增加实例分割,这可能导致对实例对象的更准确解释。此外,与许多现有工作只预训练编码器不同,实施预训练过程中的实例分割可以为下游密集预测任务提供更强的初始化。
基于分析,我们提出了一个新的核感知自监督预训练框架,用于组织病理学图像,使用**基于Cycle-GAN的UNIT在掩模域和组织病理学域之间进行。首先合成包含丰富语义信息的伪掩模图像作为掩模域。我们在框架中整合了共调节生成器**,以获得用于预训练的真实且多样的图像。我们还用实例分割任务指导框架,这使得约束更加严格,更加关注实例对象。
本文的新颖性和贡献总结如下
- 我们提出了一种新的对抗性自监督预训练方法,该方法在非配对图像到图像转换的框架内,对组织病理学图像中的核实例具有感知能力。
- 我们引入了条件性和随机性风格表示的共调节,用于在伪掩模图像的条件下生成高质量的组织病理学图像,确保为预训练网络提供的生成图像既真实又多样。
- 我们将框架与实例分割任务相结合,该任务提供实例级表示,与常见的语义分割指导相比,对核感知预训练更为有效。
- 通过7个迁移学习实验和8个半监督实验的结果表明,与其它预训练方法相比,我们的方法为5个不同的网络在7个数据集上提供了更有效和更稳健的初始化。
二、相关研究
我们的工作与四个类别相关:
- (1) 组织病理学图像的自监督预训练
- (2) 使用GAN的自监督预训练
- (3) 非配对图像到图像转换(UNIT)
- (4) 分割引导合成
A. 组织病理学图像的自监督预训练
自监督预训练在自然图像领域已经是一个成熟的课题,但对于组织病理学图像的研究仍然有限,特别是在生成式预训练方面。
- Koohbanani等人[13]基于数字病理学的多尺度特性和特殊染色性质设计了**三种病理学特定的预训练任务**。
- Yang等人[27]将对比学习定制到组织病理学中,通过染色向量扰动,并结合了跨染色预测任务。
- Luo等人[28]通过在MAE[10]的编码器中增强自蒸馏方案,使用可见组织病理学补丁的令牌,增强了编码器。
上述所有方法**都只为分类任务单独预训练了编码器**。适合特定病理学的密集预测任务的预训练方法仍然未被充分探索。
生成式预训练被认为提供了有利于密集预测任务的低级表示[29],[30]。然而,将生成式预训练直接应用于组织病理学图像的效果并不像应用于自然图像那样有效。
在本文中,我们将生成式自监督预训练定制到组织病理学。与之前忽略核形态和分布的工作不同,我们指导网络捕获带有伪掩模图像的细胞信息。此外,与大多数之前的研究不同,我们**同时为分类任务和密集预测任务初始化编码器和解码器**。
B. 自监督预训练与GAN
首先由Goodfellow等人[31]提出,生成对抗网络(GAN)是最流行的生成学习框架之一。近期的工作修改了GAN的架构以生成高质量图像[32][33][34][35],其中StyleGAN[33][35]在无条件图像生成方面取得了令人印象深刻的成果。此外,CoModGAN[23]将StyleGAN定制为图像到图像转换,在**图像补全**方面取得了领先成果。
由于对抗训练的无监督性质,GAN也提供了对抗预训练的可能性[29]。
- 以前的工作将生成器视为隐式自动编码器,通过结合一个额外的编码器,将图像映射到潜在表示[18][19][20]。
- DiRA[36]结合了对抗学习、判别学习和恢复学习,有效地指导编码器捕获医学图像更有信息量的方面。
- Tao等人[37]将对抗训练嵌入到魔方恢复中,采用了体素级的变换进行上下文置换。
在本工作中,我们也**预训练一个生成器,以提供强大的视觉表示,采用对抗自监督学习**。与以前的方法不同,我们不仅指导生成器从原始数据中学习表示,还帮助它从CoModGAN在UNIT框架内生成的高质量图像中捕获语义信息。
C. 非配对图像到图像转换
为了在没有配对图像的情况下学习两个域之间的映射,CycleGAN[22]提出了一个新的**循环一致性损失**,以保留域之间的结构信息。双向约束已被定制到多种任务中。例如,Mondal等人[38]通过学习CycleGAN中未标记图像和可用地面真实掩模之间的双向映射,提出了一种半监督分割方法。Hoffman等人[39]通过使用循环一致性损失和任务损失,提出了一个有效的域自适应方法,用于调整像素级和特征级表示。这些研究表明,循环一致性约束导致在应用域间样式转换时,生成器能够意识到语义有意义的结构。
在本论文中,我们同样**使用循环一致性约束来保留结构信息,同时使用CoModGAN和实例分割引导策略来增强生成质量。这些方法被纳入自监督预训练。据我们所知,尚未有研究进一步探索了UNIT在数字病理学自监督预训练领域的应用**。
D. 分割引导合成
研究表明,分割引导策略(SG)通过在生成图像上施加空间限制来提高GAN的性能[16][24][25][26]。Bazazian等人[24]使用基于部分的分割来引导双域图像合成。Aakerberg等人[25]利用辅助分割任务帮助生成准确的超级分辨率结果。Ardino等人[26]利用预测的分割图来促进修复过程,从而改善复杂场景中图像的生成质量。
大多数研究都使用了语义分割来提供指导。然而,由于**语义分割提供的信息与图像到掩模转换的信息相似**,这种策略在我们的框架中可能表现不佳。因此,我们整合了实例分割以提供更有效的指导。与我们目的最相关的方法是由Gong等人[16]提出的,他们以对抗方式将额外的实例分割模型融合到生成过程中。但是,这种方法需要一个内存消耗大的额外分割网络。
在本论文中,我们进一步改进了方法,通过与实例分割网络共享生成器的骨干,从而提高了预训练的效率。
三、实验
A. 数据集
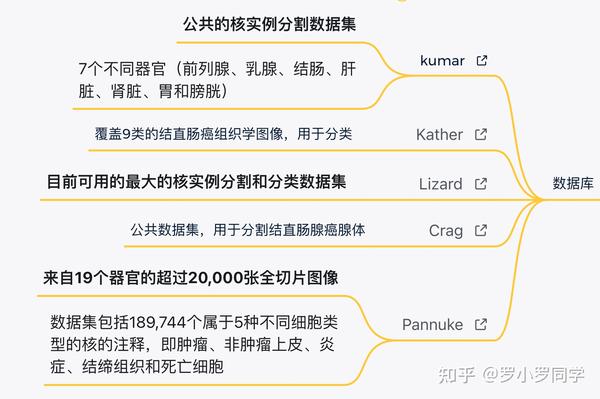
我们的实验中包含了各种数据集,用于预训练和下游任务。每个数据集的基本信息总结如下。
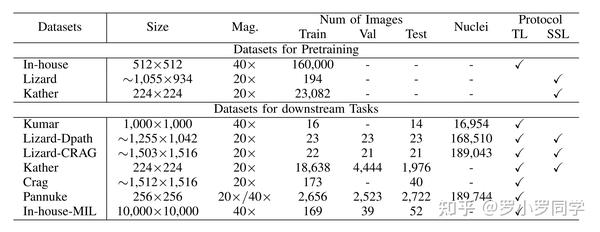
- In-House
我们从浙江大学第一附属医院收集了**1093张H&E染色的结直肠癌组织扫描的WSIs。包含正常和恶性切片,并裁剪成512×512像素的补丁。最终,准备了总共160,000张**未标记的组织病理学图像,放大倍数为40倍(0.25 µm/像素)。
- Kumar
Kumar [44]是一个**公共的核实例分割数据集**,包含从18个机构的30名患者中提取的30个注释瓦片。这些图像是从7个不同器官(前列腺、乳腺、结肠、肝脏、肾脏、胃和膀胱)的H&E染色组织中扫描和裁剪的,放大倍数为40倍(0.25 µm/像素),大小为1000 × 1000。根据原始工作,16张图像用于训练,14张用于测试。由于数据量极小,我们只将该数据集用于迁移学习协议的下游任务。

- Kather
该数据集包含**覆盖9类的结直肠癌组织学图像**,用于分类[45]。所有图像大小为224 × 224像素,放大倍数为20倍(0.5 µm/像素),来自国家肿瘤疾病中心(NCT)的组织库。

我们只使用两种类别,即结直肠腺癌上皮(TUM)和正常结肠粘膜(NORM),共23,082张图像用于训练,1,976张图像用于测试。类似于[13],我们**从训练数据中随机采样20%作为验证数据**。
- Lizard
Lizard [46]是**目前可用的最大的核实例分割和分类数据集**。它包括6个子集(GlaS、CRAG、CoNSeP、DPath、PanNuke和TCGA)的结直肠癌组织学图像,平均大小为1,016 × 917像素,放大倍数为20倍(约0.5µm/像素)。近50万个核被边界标注并分类为6个亚型(上皮、中性粒细胞、淋巴细胞、嗜酸性粒细胞、浆细胞和结缔组织细胞)。
由于子集TCGA目前不可用,我们将其排除在研究之外,总共得到238张图像。两个最大的子集(Dpath子集69张图像和CRAG子集64张图像)被用于下游任务。我们将这两个子集等分为训练、验证和测试三部分。
- Crag
Crag [47]是一个公共数据集,用于**分割结直肠腺癌腺体**。它由213张H&E图像组成,大小约为1,512 × 1,516像素,放大倍数为20倍(约0.5µm/像素)。

我们遵循官方设置,将数据集分为173张图像用于训练,40张图像用于测试。
- Pannuke
PanNuke数据集[48]包括7,901个瓦片,大小为256 × 256像素,放大倍数为20倍或40倍,来自19个器官的超过20,000张全切片图像(WSIs)。

数据集包括189,744个属于5种不同细胞类型的核的注释,即肿瘤、非肿瘤上皮、炎症、结缔组织和死亡细胞。遵循官方设置,数据集被分为训练集、验证集和测试集。
- In-House-MIL
我们还收集了来自In-house数据集相同来源的260张图像,大小为10,000 × 10,000像素,放大倍数为40倍。该数据集由130张恶性图像和130张正常图像组成,由一名专家病理学家进行注释。使用65%-15%-20%的分割将数据分为训练、验证和测试。
该数据集用于多实例学习。一个包表示从一张图像中提取的一组512 × 512大小的补丁。阳性包是包含癌细胞恶性图像,阴性包仅包含正常细胞图像。
B. 评估
- 评估协议
预训练质量通过迁移学习(TL)和半监督学习(SSL)协议进行评估。
- 对于TL,框架从零开始在In-House数据集上预训练,然后在各种下游任务上进行有监督训练并进行端到端微调。
- 对于SSL,模型在所有训练数据上预训练,然后在数据集的一部分上进行微调。
- 评估指标
- (1) 分类。准确性(Acc)和F1分数用于分类任务,包括补丁级分类和多实例学习。
- (2) 核分割和检测。报告**聚合Jaccard指数(AJI)[44]来评估分割质量**,并使用IoU阈值为0.5的F1分数来评估检测质量。
- (3) 多类核分割和检测。如果需要对核进行进一步分类,则使用在CoNIC挑战中提出的多类panoptic质量(mPQ+)[17]来评估分割质量。该指标是每个类别的PQ的平均值,其统计数据基于所有图像进行计算。报告所有类别的F1分数的平均值来量化检测质量。
- (4) 腺体分割。我们报告对象级Dice和Hausdorff距离,这在GlaS挑战[49]中用于评估实例级腺体分割质量。我们使用不同的随机种子运行每个下游任务五次,并报告平均值、标准差和基于独立两样本t检验的统计分析。
C. 迁移学习实验
我们针对自家的数据集进行了实验,并为预训练准备等量的掩模图像。我们将我们的方法与**医学图像中最新的两种自监督预训练方法**(DiRA [36] 和 Ciga-SimCLR [52])以及自然图像的两种方法(MoCo v2 [7] 和 SimSiam [8])进行了比较。
这些预训练方法的主要超参数参考了它们在Kumar数据集上的消融研究,例如MoCo v2的动量和softmax温度。我们还加入了ImageNet和Mormont等人的有监督预训练进行比较。请注意,我们只能将这些方法用于下游任务中的ResNet骨干网络的初始化。
- 多器官核检测和分割
如表II所示,尽管在我们的预训练框架中没有使用额外的注释,我们在Kumar数据集上的表现优于ImageNet(p<0.05)和Mormont等人(p<0.05)的有监督预训练。
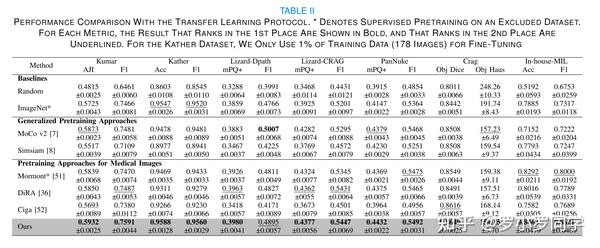
此外,我们的方法比以前的最先进预训练方法产生更好的结果(p<0.05,与MoCo v2相比),这表明我们的核感知方法对于密集预测任务更有效,并且对于各种器官的病理学图像的泛化更好。
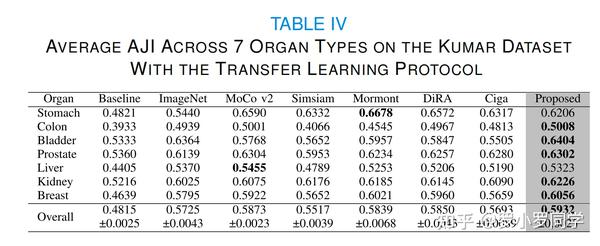
表IV中的每个器官的结果表明,我们的方法在各种器官的核分割中都有所改进。我们不仅提高了具有腺体结构的器官(如结肠、前列腺和乳腺)的性能,也提高了没有特殊结构的器官(如膀胱)的性能。我们还与Kumar上的核分割的最先进方法进行了比较。
为此,我们使用了HoVer-Net [4]作为分割器,并将Preact-ResNet-50骨干网络替换为预训练的ResNet-50,类似于之前的工作[61]。
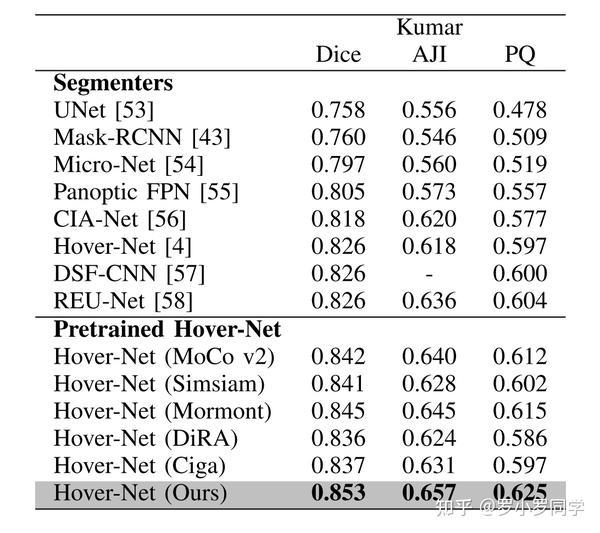
如表III所示,有趣的是,所有预训练方法都提高了Hover-Net的性能(Dice),其中我们的方法实现了Kumar上的新最先进结果。
- 结直肠癌分类
在Kather数据集上进行了癌症分类。我们只对1%的训练数据进行微调,以使任务更具挑战性,并加剧预训练方法之间的差异。
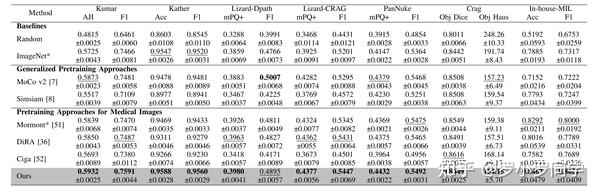
表II的结果表明,ImageNet提供了比大多数预训练方法更有效的初始化。这些结果与自监督方法并不总是优于ImageNet的发现一致[52]。尽管如此,我们的方法不仅显著优于其他自监督方法,提高了至少1.12%的准确性和1.08%的F1分数(与MoCo v2相比,p<0.05),而且略优于ImageNet。
这些结果的一个可能解释是,癌症分类任务高度依赖于核的特性,我们的预训练方法可以帮助更好地识别这些特性。
- 腺体分割
我们在Crag数据集上进行了腺体分割任务。值得注意的是,尽管我们的预训练方法是核感知的,但我们也为腺体分割提供了比监督对照组更强的初始化(ImageNet,p<0.05和Mormont,p<0.05,Obj Dice)。
我们与其他自监督方法相比也取得了优越的结果,尽管改进不显著(0.8649 vs. 0.8616,p=0.28,与Ciga相比)。这些改进可以归因于我们在掩模图像中核分布的特殊设计,这与腺体周围的上皮细胞相似。
- 多类核检测和分割
在Lizard的Dpath子集上,我们的方法优于其他预训练方法,但在mPQ+上的表现优于MoCo v2。然而,我们没有观察到与MoCo v2相比的F1分数的改进。我们将这些结果归因于在预训练期间我们没有在分割分支中对实例进行分类的权衡。当在Lizard的CRAG子集上进行实验时,我们在mPQ+和F1上都取得了最佳结果。
- 多器官和多类核检测和分割
我们还对一个更具多样性的数据集进行了实验,以进一步评估我们的预训练模型的迁移性,以防需要分割多种器官和多类核。在PanNuke数据集上进行的实验表明,我们的方法优于DiRA(p<0.05),这是之前的最先进预训练方法。
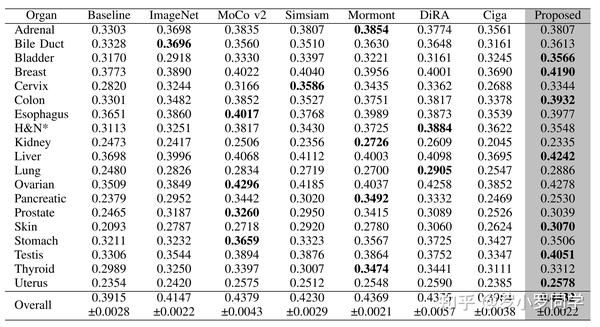
我们可以从表V中的每个器官的结果中学习到,无论是在上皮类结构(如乳腺、结肠和肝脏)还是非上皮类结构(如膀胱)中,我们的预训练方法都有所受益。这些结果表明了我们的预训练模型在各种下游情况下的鲁棒性。
- 多实例学习
我们在In-house-MIL数据集上进行了多实例学习的实验,以评估我们的方法是否有利于特殊的两阶段模型。原始工作[60]使用ImageNet预训练的骨干网络进行采样和聚合。我们也发现与随机初始化骨干网络相比,该策略更为有效,后者在采样后很难提供区分性特征。
此外,我们观察到泛化的自监督预训练方法无法提供更强的初始化,而针对医学图像的方法则比ImageNet受益更多。在这种特殊任务中,我们的方法仍然优于ImageNet(p<0.05),并且优于其他预训练方法。
综上所述,我们的方法在多个下游任务中表现出色,表明了其在医学图像预训练方面的有效性。我们的核感知自监督预训练方法特别适用于密集预测任务,并且在泛化到不同器官的病理学图像方面表现出色。
此外,我们的方法在癌症分类和腺体分割等任务中也取得了显著的改进,这进一步证明了其在医学图像分析中的广泛适用性。
D. 消融研究
为了证明我们设计的益处,我们对迁移学习和半监督学习协议(25%训练数据)进行了彻底的消融研究,逐步应用每个组件。我们将方法[14]修改为基线,该方法也使用基于CycleGAN的框架在掩模图像和组织病理学图像之间进行转换。
值得注意的是,他们的目的是通过核分割的训练数据增强,这不能直接用于比较。因此,我们将他们的掩模生成器替换为我们的基于ResNet的生成器,仅实现他们的CycleGAN阶段以进行公平比较。
- 掩模图像质量
我们检查合成掩模图像质量的影响。
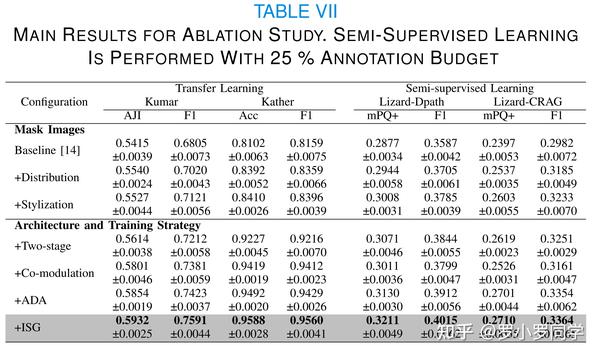
如表VII相应部分所示,引入了由核分布和样式化带来的额外信息。我们从随机的分布和二值核掩模设计开始,逐步添加腺体结构和样式化核。总的来说,我们可以观察到引入分布先验时,无论是迁移学习还是半监督学习,性能都有所提升(p<0.05)。样式化在大多数情况下都有益处,但在Kumar上的分割性能略有下降。
- 架构设计
为了分析网络设计的影响,我们研究了我们框架的不同架构。
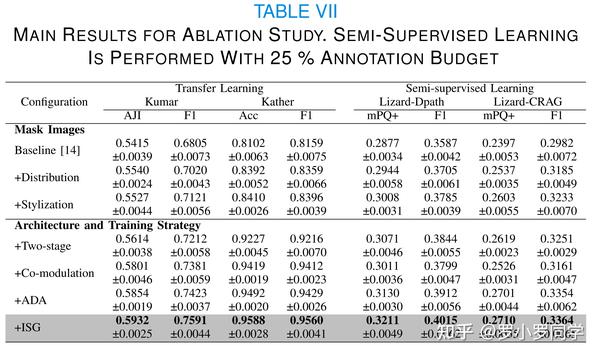
如表VII总结,我们将设计分为三个主要部分:病理生成器G的共调节设计、DG的适应性判别器增强策略(ADA)和分割引导策略。
对于第一部分,我们发现在我们的迁移学习协议中是有效的。然而,在预训练数据有限的半监督学习协议中,复杂的生成器设计由于过拟合问题而不利。我们通过**增强预训练数据中的ADA来缓解这个问题,这有效地提高了半监督学习的性能,同时也进一步提高了迁移学习的性能**。
此外,我们讨论了实例分割引导策略(ISG)的好处。
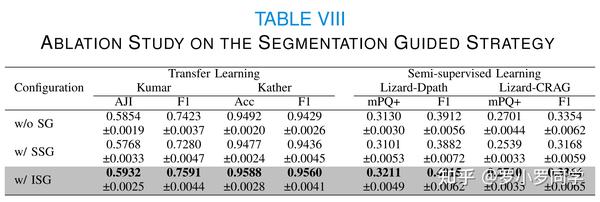
表VII和表VIII的结果表明,语义分割引导策略未能提供有用信息,支持我们在III-D的分析。相反,实例分割引导策略有效地提高了性能,特别是在迁移学习实验中,Kumar上的改进为1.68%(F1分数,p<0.05),Kather上的改进为1.31%(F1分数,p<0.05)。
- 预训练时间表
由于G和S的收敛率不一致,我们设计了两阶段预训练策略。表VII和表IX调查了额外训练阶段的效果。总的来说,与单阶段预训练相比,额外训练阶段的表现更优越(p<0.05对于迁移学习)。我们观察到更多的训练阶段并没有带来显著的性能提升。
- 用于密集预测任务的网络初始化
我们在表X中评估了初始化ResNet骨干、FPN以及我们能够初始化的所有结构(包括FPN和实例分割分支)的效果。初始化FPN的性能优于仅初始化编码器骨干。令人鼓舞的是,我们在Kumar上通过进一步初始化实例分割头发现性能有所提升。
然而,当进一步初始化更多的实例分割头时,我们在Kather上观察到轻微的改进,但在Lizard上性能有所下降。这可能是由于预训练和微调期间分割分支的不同角色所致。在下游任务中,当分割分支进一步对核进行分类时,初始化分割器的头可能会导致网络忽略核之间的差异。因此,我们为所有密集预测任务仅初始化FPN。
四、结论与讨论
本文介绍了一种**基于UNIT的核感知自监督框架,用于组织病理学图像。由于病理分析中核分布和形态的重要性,自监督学习框架需要包含这些先验知识。在我们的方法中,历史病理学图像和包含丰富核信息的伪掩模图像之间的循环一致性旨在使模型对核实例保持敏感。整个框架通过CoModGAN-ADA生成器得到增强**,该生成器确保生成组织病理学图像的质量与多样性。此外,实例分割引导策略的引入提高了模型提取实例级信息的能力。
所提出的自监督学习方法在**提取细粒度特征**方面是有效的,这些特征对于密集预测任务比其他预训练方法更有帮助。这在7个迁移学习实验和9个半监督学习实验中得到证实,其中我们的方法在大多数情况下显著优于最先进的方法。我们还研究了我们的方法是否为分类任务提供了区分性表示。
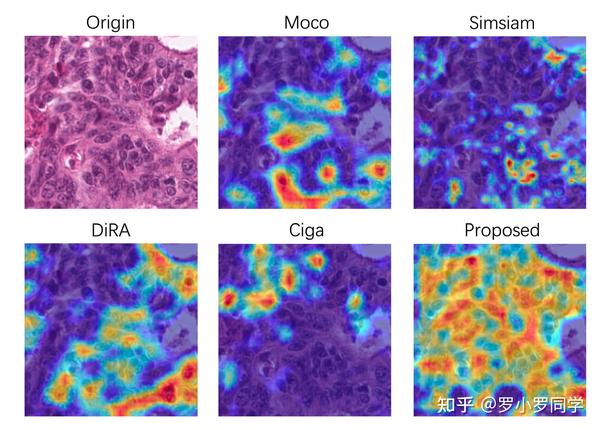
尽管图5中的热图可视化和表VI中的半监督(0.25%)结果表明,我们的方法可能偏向于核级特征,这些特征可能不如鉴别预训练获得的全局特征有效,但迁移学习结果表明,我们可以适应高质量的分类任务。
此外,我们在Kather上执行了线性评估协议[63]。如表XI所示,我们观察到我们的特征比随机初始化的特征更具线性可分性(p<0.05)。然而,论文中描述的Kather上的分类任务仅针对TUM和NORM类别进行。
为了对预训练方法进行更全面的分析,我们在Kather上进行了额外的多类别分类任务。值得注意的是,我们在这里排除了脂肪、背景、碎片和粘液,因为这些类别是无核的,很难从我们的核感知预训练方法中受益。我们在表XII中报告了Kather剩余5个类别的性能。
结果显示,除了TUM和NORM之外,我们的方法对不同类别的区分仍然更有效,这表明了最高的Acc,尽管宏观F1分数略低于之前的最先进方法。在未来的研究中,我们将关注扩展我们的方法,加入更多区分性特征,以补充其在分类任务边界的使用。
令人鼓舞的是,所提出的预训练方法对各种情况具有鲁棒性。首先,我们的方法对不同的组织类型具有鲁棒性。我们通过在不同的组织类型和不同的肿瘤类型上进行预训练来验证这一点。我们收集了除结直肠癌组织学图像之外的其他乳腺组织等量的组织病理学图像进行预训练。如表XIII所示,我们观察到在结肠或乳腺上预训练的模型之间没有显著差异(p=0.42,AJI)。
我们还预训练了结肠和乳腺组织,以评估利用更多样化的预训练源对方法的潜在益处。在这种情况下,我们增加了训练迭代次数,确保每次图像呈现给网络的次数保持不变。令人鼓舞的是,在引入这种多样化的数据集后,Kumar(AJI)和Kather的性能略有提高。观察到的改进可以在表XIV中解释,该表显示,利用更多样化的预训练源可以减轻对特定器官的偏差。
例如,仅使用结肠组织进行预训练时,与仅使用乳腺组织预训练相比,胃、肝脏和乳腺的性能略有下降。然而,当使用组合数据集时,这些器官的性能与仅使用乳腺组织预训练相当。在Pannuke数据集上报告的类似结果也可以在表XV中找到,其中在添加乳腺组织进行预训练后,肾上腺、乳腺、宫颈、肝脏、胰腺和子宫的指标有所下降。因此,收集更多样化的数据集进行预训练可能会获得更稳定的结果。
此外,我们收集了扫描自分化程度较低的结直肠癌肿瘤的组织病理学图像,这些肿瘤的腺体模式不明显。预计在这种情况下,伪掩模中的核分布表现最差,因为随机分布。
然而,如表XVI所示,我们观察到我们的方法与基线的结果相当(p=0.35),这表明我们的框架可以稳健地处理历史病理学图像和掩模图像之间的分布差距。其次,我们的方法对各种下游任务具有鲁棒性,这在表II中可以看到,其中我们的方法在分类、实例分割、语义分割和多实例学习任务中均有效。第三,我们的方法对各种下游任务架构有益。我们在Panoptic FPN、Mask-RCNN、Hover-Net、UperNet和C2C上进行各种任务的实验,并报告了在Kumar上使用Hover-Net的新最先进结果。
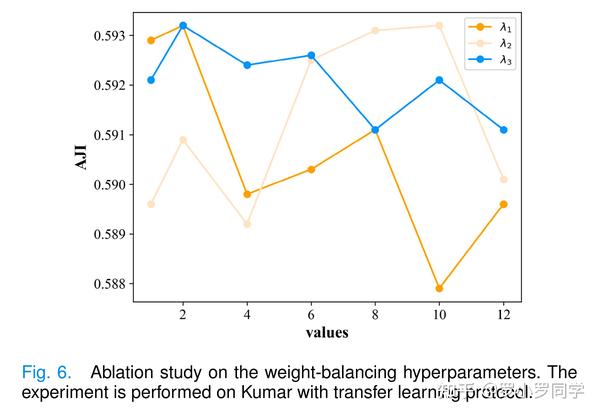
此外,我们的方法对超参数选择的鲁棒性。我们进行了额外的消融研究,以检查我们的方法对关键超参数选择的敏感性。具体来说,我们评估了改变一个权重平衡超参数(保持其他超参数固定不变)的影响。结果如图6所示,揭示在特定范围内,随着权重平衡超参数的改变,性能保持相对稳定。
尽管所提出的自监督预训练方法在各种任务中展示了有前景的结果,但仍有一些扩展需要进行。首先,掩模图像是固定和有限的,由手工设计,其中我们随机重新分配部分核以匹配腺体结构。然而,一个更好的解决方案是使核分布与不同的数据集相关,以便对特定任务进行对齐,从而采用更多样化的数据集进行预训练,这可能导致更好的性能。未来可能会探索如伪标签或使用预训练的核分割器等策略,这些策略将有助于生成更符合特定任务的数据分布。
此外,所提出的方法仅关注局部特征的提取,这与获得全局表示的预训练方法正交。研究结合这些方法的方法将是未来的一个研究方向。我们希望本文的方法能够作为核感知自监督预训练方法的基准。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









