







小罗碎碎念
本期推文的主题——人工智能在肿瘤复发/转移预测领域的最新研究进展。

小罗观点
- 第一篇文献没记错的话,已经出现在文献速递中三次了,不是小罗偷懒哈,是因为这篇文献真的很重要,非常具有参考价值;
- 第二篇文献提出的技术挺有意思的,关注我的老师/同学里有不少是研究肺癌的,你们或许可以尝试一下;
- 第三篇文献就是常见的目标检测,这里是用在结直肠息肉检测,是为了结直肠癌的治疗和诊断服务的,那么我们很自然的就能想到,能不能可以迁移到你研究的癌种上呢?答案是肯定的,但是能否实现要看你的能力,以及实验室的硬件实力;
- 第四篇文献涉及的面很广,包括细胞分割、自动注释以及可解释性空间分析,如果最近看过我写的hover net相关的推文,你是不是觉得这期推送来的太是时候了,因为你可以看看两种模型在细胞分割方面的优缺点,SCI这不就来了?
- 第五篇文献的研究内容我之前从未接触过,就当开拓视野了;
- 第六篇文献很有意思,可以识别恶性肿瘤并预测肿瘤起源,但是训练数据不是病理组学中常见的放大20/40倍,而是200/400倍,所以在训练数据的准备上可能存在一定难度。
我是罗小罗同学,明天见!!
一、HECTOR|用于预测子宫内膜癌患者远处复发风险的多模态模型

文献概述
这篇文章是发表在《Nature Medicine》上的一项研究,我前两天的推文也推荐过这篇文章,为什么要再次拿出来说呢?因为……我明天有一篇推文就是关于这篇文献的精析。
研究团队开发了一个名为HECTOR(histopathology-based endometrial cancer tailored outcome risk)的多模态深度学习预测模型,用于预测子宫内膜癌患者的远处复发风险。
HECTOR模型利用苏木精-伊红染色的全切片图像(whole-slide images, WSIs)和肿瘤分期作为输入,对来自八个子宫内膜癌队列的2072名患者进行了训练和测试,包括PORTEC-1/-2/-3随机试验。
HECTOR模型在内部测试集(353名患者)和两个外部测试集(分别为160名和151名患者)上展示了出色的预测性能,C指数(concordance index, C-index)分别为0.789、0.828和0.815,超过了当前的金标准。此外,HECTOR模型还能更好地预测辅助化疗的效果。通过对形态学和基因组特征的提取,研究团队发现了与HECTOR风险组相关的因素,其中一些具有治疗潜力。
HECTOR模型的开发为个性化治疗提供了新的工具,有助于改善子宫内膜癌患者的治疗决策。研究还探讨了HECTOR模型的解释性,通过分析模型风险评分与已知预后因素的关联,以及输入数据对预测的贡献,为理解HECTOR模型提供了更深入的生物学见解。
研究结果表明,HECTOR模型在预测远处复发风险方面具有潜力,并且可能成为未来临床实践中的一个有效工具。
重点关注
HECTOR模型的概览
a部分:
- 描述了从
子宫内膜癌(EC)的苏木精-伊红染色全切片图像(H&E WSI)中分割组织,并将其划分为180微米大小的区域(称为patches)的过程。 - 使用
多阶段视觉变换器(multistage vision transformer),通过自监督学习的方法,从1862名患者的WSIs中随机抽取图像块进行训练,这些患者不包括在内部和外部测试集中。 - 从变换器的最后八个块中提取图像块级别的特征。

b部分:
- 展示了HECTOR模型如何接受H&E WSI和根据FIGO 2009标准分类的解剖学分期(I-III期)作为输入。
- 提取的图像块级特征在空间和语义上进行了平均处理。
- 这些特征被输入到一个
基于注意力机制的多重实例学习模型(attention-based multiple instance learning model)和im4MEC深度学习模型中(所有层都是冻结的),后者能够从H&E WSI预测分子类别,如imPOLEmut、imMMRd、imNSMP或imp53abn。 - 解剖学分期和基于图像的分子类别都通过嵌入层(Embedding layers)进行处理。
- 使用
基于门控的注意力机制(gating-based attention)对这三个嵌入结果进行加权,然后通过Kronecker积进行融合。 - 使用
负对数似然损失函数(−log(likelihood loss))来预测在离散时间上的无远处复发概率函数。 - 风险评分定义为综合预测概率。
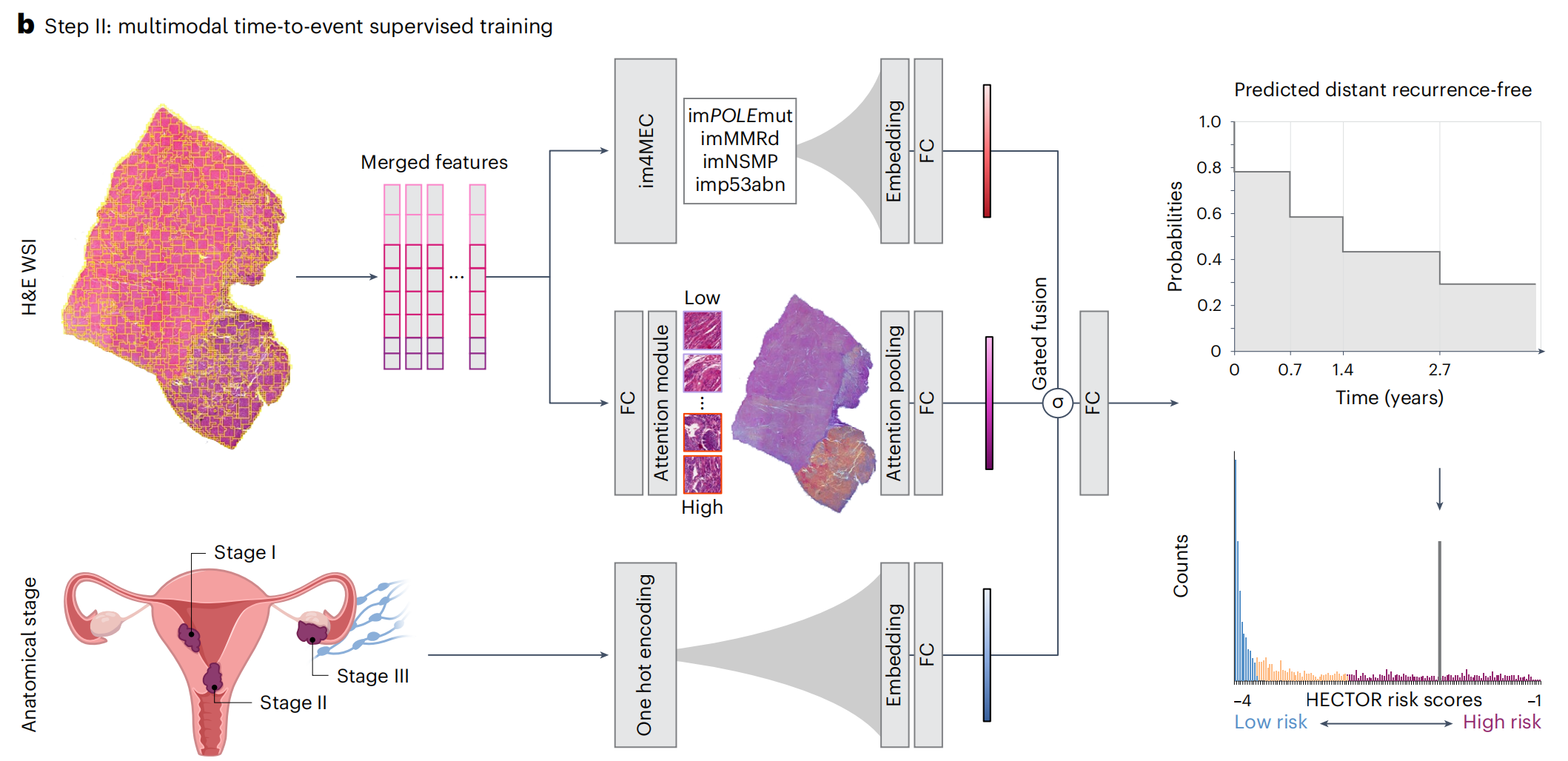
此外,图1还提到了多层面感知器(MLP, multilayer perceptron)和全连接层(FC, Fully Connected layer),这些是深度学习中常见的网络结构,用于处理和学习数据特征。
总体而言,HECTOR模型通过结合组织形态学特征、分子类别和解剖学分期信息,使用深度学习技术来预测子宫内膜癌患者的远处复发风险。
二、用于治疗肺癌转移的微型机器人技术

文献概述
这篇文章讨论了一种创新的微型机器人技术,用于治疗肺癌转移。
研究者们开发了一种生物混合型微机器人(biohybrid microrobots),利用能够自主运动的绿藻与涂有红细胞膜的纳米粒子结合,这些纳米粒子装载了化疗药物多柔比星(doxorubicin,DOX)。这种微机器人能够在肺部自主推进,实现药物的控制释放和增强药物分散,从而产生抗转移效果。
文章首先介绍了肺癌转移治疗的挑战,指出常规化疗效果不佳,主要是因为药物在肺部的靶向性和积累有限。接着,文章详细介绍了微机器人的设计和制备过程,包括使用纳米沉淀法制备DOX装载的PLGA纳米粒子,以及通过声波法将红细胞膜涂覆在纳米粒子上,形成具有核心-壳结构的NP(DOX)。研究者们还使用了点击化学方法将NP(DOX)结合到绿藻表面,制备出藻类-NP(DOX)-机器人。
研究结果显示,这种微机器人在模拟的肺液中保持了良好的运动能力,并且在体外实验中显示出较低的细胞毒性和有效的药物释放特性。在体内实验中,通过气管内给药,微机器人能够有效地将药物输送到小鼠肺部深处,并显示出比被动药物装载纳米粒子和游离药物对照组更快的药物分布、更好的组织积累和更持久的保留。在黑色素瘤肺转移模型中,藻类-NP(DOX)-机器人显著提高了治疗效果,减少了转移负担,并延长了生存时间。
文章还讨论了微机器人的安全性评估,包括在健康小鼠中进行的毒性测试,结果表明微机器人在治疗剂量下未引起明显的毒性反应。最后,文章总结了这种生物混合微机器人在肺部药物递送和肺癌转移治疗中的潜力,并提出了未来研究的方向,如集成额外的运动控制策略。
整体来看,这篇文章提出了一种新的治疗肺癌转移的方法,通过使用生物混合微机器人进行局部药物递送,以提高药物疗效并减少对正常组织的影响。
重点关注
图1详细展示了藻类-NP(DOX)-机器人的制备和特性分析,具体内容如下:

(A) 展示了一个示意图,描述了使用藻类-NP(DOX)-机器人治疗黑色素瘤肺转移的过程。
(B) 通过透射电子显微镜(TEM)图像展示了红细胞膜包覆的DOX载药纳米粒子(标记为NP(DOX)),比例尺为100纳米。
© 展示了NP(DOX)和未包覆的PLGA载药纳米粒子(标记为PLGA(DOX))的尺寸分布,数据为三次实验的平均值加上标准差(mean + SD)。
(D) 展示了NP(DOX)和PLGA(DOX)的表面zeta电位,这反映了纳米粒子在溶液中的稳定性。
(E) 展示了NP(DOX)和PLGA(DOX)的药物载药量,即DOX与PLGA重量的比值。
(F) 展示了NP(DOX)和PLGA(DOX)的包封效率,即载药量与输入DOX量的比值。
(G) 提供了藻类-NP(DOX)-机器人的示意图,显示了通过点击化学方法将NP(DOX)共价结合到藻类上。
(H) 展示了藻类-NP(DOX)-机器人的明场(BF)和荧光图像。藻类中的叶绿体在Cy5通道中显示自荧光;NP(DOX)在RFP通道中显示荧光。比例尺为10微米。
(I) 展示了藻类-NP(DOX)-机器人的伪彩色扫描电子显微镜(SEM)图像,其中藻类以绿色显示,NP(DOX)以橙色显示。比例尺为2微米。
(J) 展示了藻类-NP(DOX)-机器人与纯藻类和NP(DOX)的光学吸收光谱比较,单位为任意单位(a.u.)。
(K) 展示了在不同初始药物输入量下,每1×10^6个藻类上的DOX载药量的量化,数据为三次实验的平均值加减标准差。
(L) 展示了流式细胞仪直方图,比较了藻类在25微克药物输入量下,功能化前后NP(DOX)的藻类。DOX在藻红蛋白(PE)通道中被测量。
整体而言,图1提供了藻类-NP(DOX)-机器人制备过程的详细视图,包括其物理特性、药物载药量和包封效率,以及通过共价结合实现的纳米粒子与藻类之间的连接。此外,还包括了对藻类-NP(DOX)-机器人的光学特性和药物载药能力的量化分析。
三、计算机辅助检测(CADe)系统在结直肠息肉检测中的应用

文献概述
这篇文章是一项关于计算机辅助检测(CADe)系统在结直肠息肉检测中的临床后果的原创研究。
研究的背景是随机试验显示,CADe能提高息肉检测率,尤其是小病变,但可能存在操作员和选择偏差,其真正的益处尚未完全阐明。该多中心试验使用结合卷积和循环神经网络的CADe进行息肉检测,通过第二观察者实时监测盲端镜医生,CADe检测提示重新检查。研究测量了研究前后的腺瘤检测率(ADR)和息肉检测率,并通过独立的组织病理学家进行组织学评估。
研究结果显示,在946名患者中,共识别出2141个息肉,包括989个腺瘤。CADe在检测息肉方面并不比人类医生更优越(敏感性分别为94.6%和96.0%),但在仅限于腺瘤的情况下表现更好。通过揭示(unblinding)额外发现了86个真正的阳性息肉检测(每患者ADR增加1.1%;73.8%的息肉<5毫米)。CADe还将非肿瘤性息肉检测增加了4.9%的绝对值(整个息肉负荷增加了1.8%)。程序时间增加了6.6±6.5分钟(增加了42.6%)。在22/946患者中,额外检测到的腺瘤改变了监测间隔(2.3%),主要是通过增加超过截止值的小腺瘤数量。
研究结论是,即使CADe比人类内镜医生稍微更敏感,ADR的额外增益是最小的,后续间隔很少改变。对非肿瘤性病变的额外检查增加了,增加了检查和/或息肉切除的工作量。
文章还讨论了结直肠癌(CRC)是第三大诊断出的癌症和第二大癌症相关死亡原因,筛查结肠镜检查在预防CRC的发生率和死亡率方面是有效的。研究还提到了CADe系统的发展,包括使用卷积神经网络(CNN)和循环神经网络(RNN)的结合,以及实时盲检测的试验设计。
研究的限制包括内镜医生知道CADe在房间里使用,可能导致他们在息肉识别方面表现更好,从而可能低估了CADe的额外检测收益。尽管如此,研究强调了CADe在提高结肠镜检查质量方面的潜力,尤其是在ADR较低的医生中。
重点关注
图2展示了CADe(计算机辅助检测)系统在息肉检测中可能出现的两种误报情况:临床无关的误报和临床相关的误报。
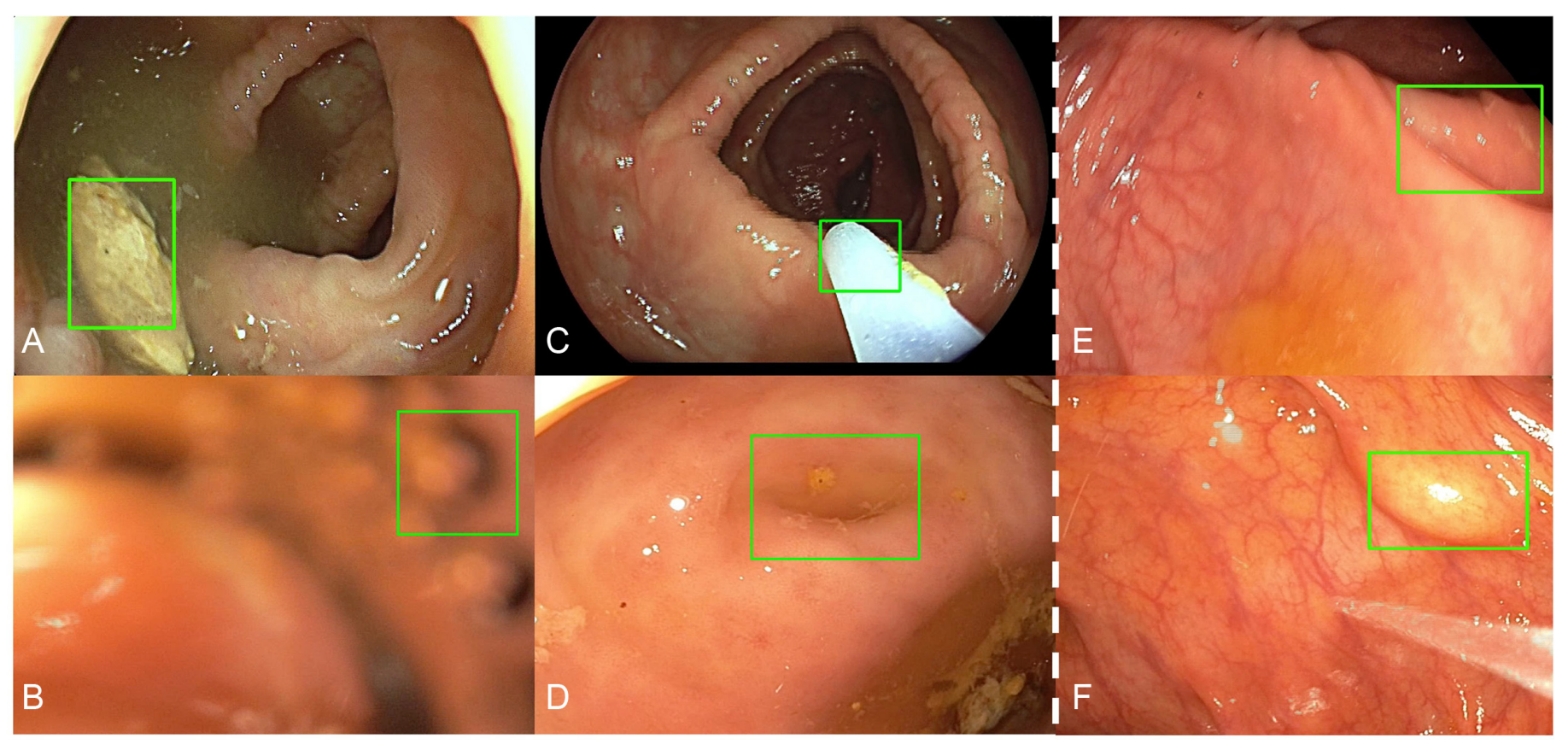
临床无关的误报(Clinically irrelevant false positive detections)包括:
- (A) 粪便残留(stool remnants):CADe系统可能会错误地将结肠中的粪便残留识别为息肉,但实际上它们不是息肉。
- (B) 气泡(air bubble):有时肠道内的气体泡沫也可能被CADe误判为息肉。
- © 内镜设备(instrument):在某些情况下,内镜或其附件可能被错误地识别为息肉。
- (D) 解剖结构(anatomical structure),例如阑尾开口(appendiceal opening):结肠的某些正常解剖特征可能被CADe错误地识别为息肉。
临床相关的误报(Clinically relevant false positive detections)包括:
- (E) 增厚的褶皱(thickened fold):肠道的某些褶皱或隆起可能被CADe系统错误地识别为息肉,需要进一步的内镜检查来确认。
- (F) 其他(other),例如脂肪瘤(lipoma):某些情况下,肠道中的其他类型的良性生长,如脂肪瘤,也可能被CADe系统误认为是息肉。
这些误报情况说明CADe系统虽然在提高息肉检测率方面具有潜力,但仍存在一定的局限性,尤其是在区分真实息肉和非息肉结构方面。临床医生需要结合CADe的提示和自身的专业判断,以确保准确的诊断和适当的治疗决策。
四、TRACERx-PHLEX:用于多重成像数据的深度细胞表型分析和空间分析的工具

文献概述
这篇文章介绍了一个名为TRACERx-PHLEX的新型计算流程,它是一个用于多重成像数据的深度细胞表型分析和空间分析的工具。
PHLEX包含三个独立但可互操作的模块:
- deepimcyto(基于深度学习的细胞分割)
- TYPEx(自动化的细胞类型注释)
- Spatial-PHLEX(可解释的空间分析)
这个流程是为了应对多重成像数据规模和维度的增长,同时提供一个用户友好、可重复且全面的解决方案。
PHLEX的开发使用了成像质谱细胞术(IMC)技术,并在TRACERx研究中得到验证。它通过自动化和容器化的Nextflow流程,使得用户无需手动评估、编程技能或病理学专业知识即可使用。PHLEX在不同类型的组织、组织固定条件、图像尺寸和抗体板上进行了评估,并与最先进的方法进行了基准测试。
文章详细描述了PHLEX的工作流程,包括deep-imcyto的细胞核和全细胞分割、TYPEx的细胞亚型和状态的深入识别,以及Spatial-PHLEX的空间分析方法。这些模块被设计为独立的Nextflow流程,并包含在所有软件依赖项的容器中,以确保可重复性和可移植性。
研究者还展示了PHLEX在TRACERx 100队列(ClinicalTrials.gov标识符:NCT01888601)中的非小细胞肺癌(NSCLC)患者中的236个组织微阵列(TMA)核心上的应用。此外,他们还使用公开的人类和小鼠数据、IMC和CODEX平台、较小的TMA和较大的全切片图像以及不同的组织类型、组织固定条件和抗体板来评估和基准测试PHLEX的性能。
文章还讨论了PHLEX在自动化多重成像分析中的优势,包括提高可重复性和可访问性,以及在不需要高水平专业知识的情况下提供端到端的解决方案。PHLEX的模块化设计允许它适用于其他多重成像技术,并且可以独立使用。PHLEX的代码和文档可在GitHub和相关文档网站上找到。
重点关注
Fig. 1 展示了 TRACERx-PHLEX 工作流程的概览以及其在多重成像研究中的应用。
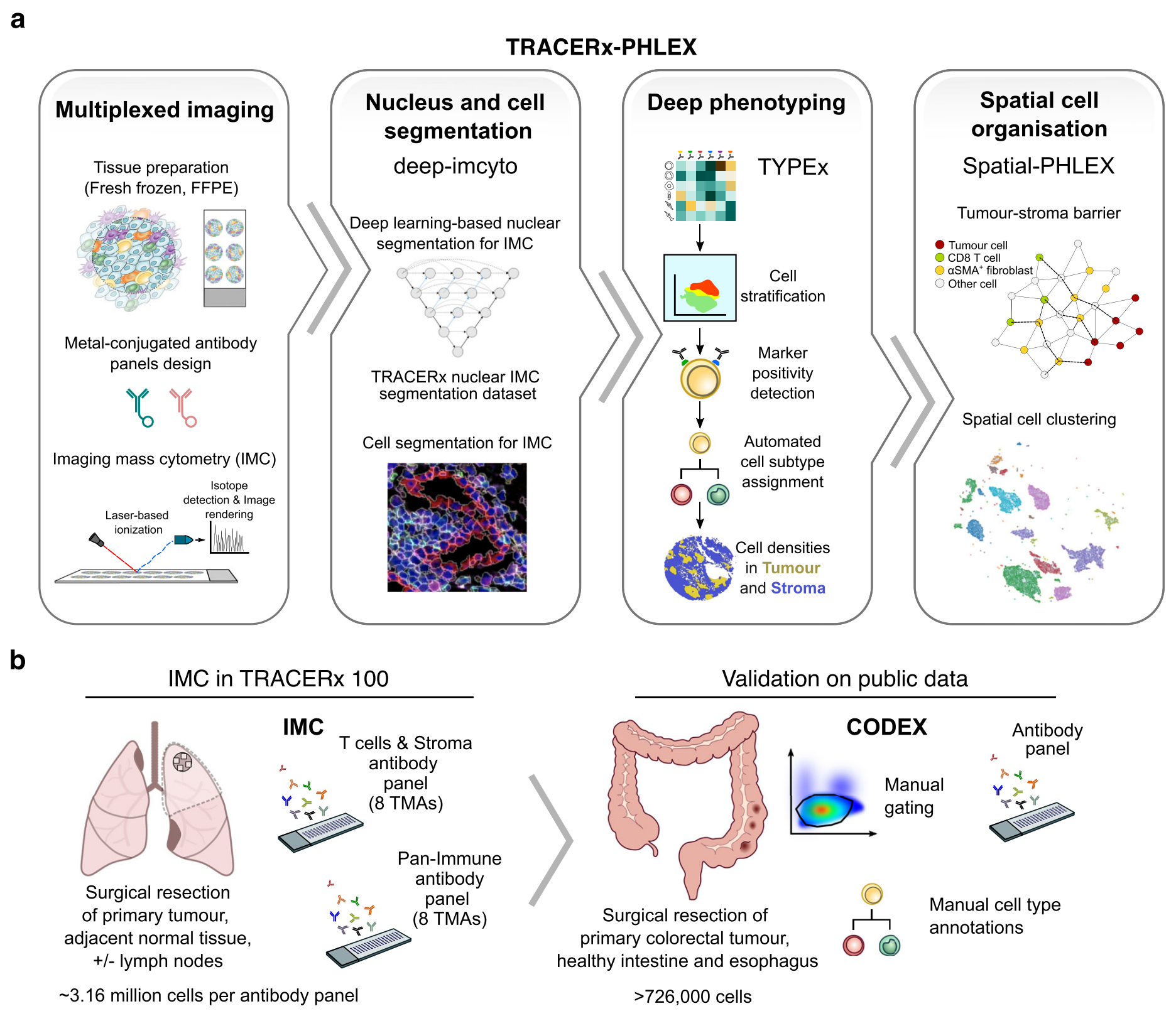
该图分为两个主要部分:
a部分:PHLEX集成的三个模块
- deep-imcyto:负责细胞核和全细胞的分割。这个模块执行图像预处理、分割以及图像质量控制。
- TYPEx:基于标记物的强度对细胞类型和状态进行深度表型分析和注释。
- Spatial-PHLEX:负责检测和量化组织结构中的空间模式。
这些模块共同涵盖了多重成像分析中的主要任务,并且是相互独立但可以协同工作的。
b部分:PHLEX的应用实例
- PHLEX 在成像质谱细胞术(IMC)中被开发和应用,使用了来自 TRACERx 100 队列的非小细胞肺癌(NSCLC)患者的切除肿瘤、淋巴结和肿瘤相邻的正常组织。
- 该队列包括 60 个标记物、83 名患者、236 个核心组织样本,每个抗体面板约有 316 万个细胞。
- 研究中使用了两种抗体面板:T细胞和基质面板(T cells & Stroma panel)以及全免疫面板(Pan-Immune panel)。
- 为了验证 PHLEX 的有效性,研究者使用了来自 TRACERx 研究的正交数据以及三个公开的共检测索引(CODEX)成像数据集。这些数据集包括手动策划的细胞类型注释。
- 结直肠癌数据集还包括手动门控信息(Schürch 等人,56 个标记物,来自 35 名 CRC 患者的 140 个 TMA 核心)。
- 来自 Barrett 食管(Brbić 等人)和健康肠道(HuBMAP)的数据集包括新鲜的冷冻全切片组织(44-48 个标记物,超过 726,000 个细胞)。
此外,FFPE 是指甲醛固定石蜡包埋(formalin-fixed paraffin-embedded),而 TMA 是组织微阵列(tissue microarray)。
总的来说,Fig. 1 强调了 PHLEX 作为一个集成的多重成像分析工具的能力,它可以处理大规模的单细胞数据,并提供了一种从原始图像数据到可解释的定量细胞和空间信息的端到端计算框架。
五、克隆性造血的驱动突变识别

文献概述
这篇文章讨论了克隆性造血(Clonal Hematopoiesis, CH)的驱动突变的识别。
CH是一种造血干细胞的克隆性扩张现象,由体细胞突变驱动,影响特定基因。近年来,CH与血液恶性肿瘤、心血管疾病和其他疾病的发展有关。尽管已经识别出一些常见的CH驱动基因,但系统性的突变景观,特别是能够启动这一现象的突变,仍然缺乏。
研究者们训练了机器学习模型,针对12个最常见的CH基因来识别它们的驱动突变。这些模型的表现优于基于这些基因功能先验知识专家策划的规则。当这些模型应用于近50万英国生物银行(UK Biobank)捐赠者的CH驱动突变识别时,它们再现了已知的CH驱动突变与年龄、几种疾病和条件的流行率之间的关联。因此,研究者们提出这些模型可以支持健康个体中CH的准确识别。
研究者们开发并验证了特定于基因的机器学习模型,以识别CH驱动突变,并证明了它们相对于专家策划规则的优势。这些模型可以帮助识别和临床解释新测序个体中的CH突变。
文章还介绍了CH的背景,包括在健康造血过程中,造血干细胞(HSCs)如何贡献于所有血液相关谱系,以及随着年龄的增长,这一过程如何经常转变为CH状态。此外,文章讨论了如何使用高质量的血液体细胞突变数据集来训练机器学习模型,并使用这些模型来识别CH驱动突变。研究者们还比较了boostDM-CH模型与专家策划规则集的性能,并发现boostDM-CH模型在识别CH驱动突变方面表现更好。
最后,文章讨论了使用boostDM-CH模型在大型人群队列中识别CH驱动突变的潜力,并验证了这些模型在识别新的CH驱动突变方面的有效性。研究者们还提供了这些模型和相关数据的公共访问链接,以促进CH研究社区的进一步研究。
重点关注
Figure 1 提供了关于构建和评估 BoostDM-CH 模型的详细信息,这些模型用于识别与克隆性造血(CH)相关的驱动突变。
以下是对图表各部分的分析:
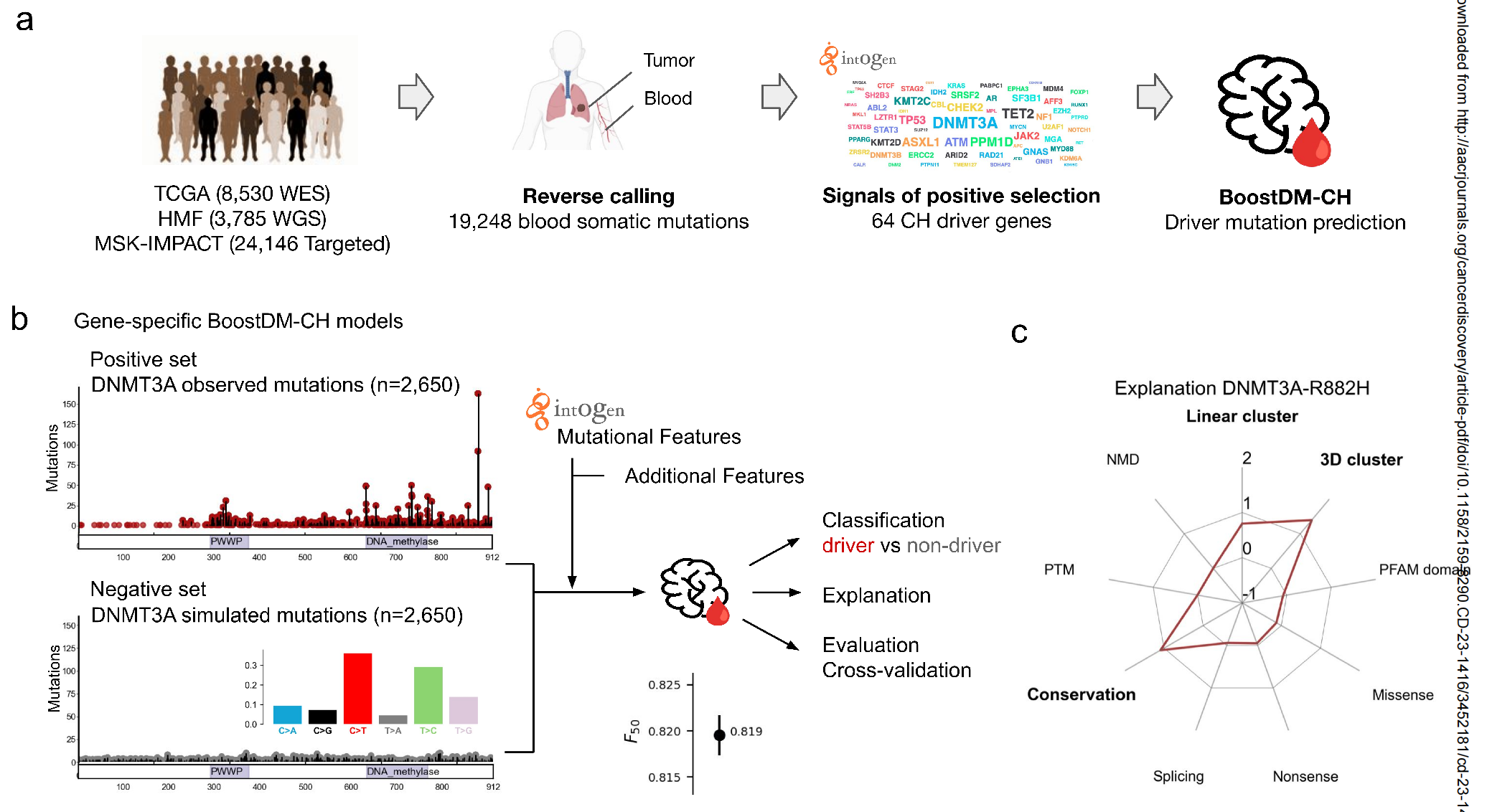
a) 训练数据的来源:BoostDM-CH 模型使用的训练数据是通过反向调用(blood vs tumor sample)在三个癌症基因组队列中识别出的血液体细胞突变。这些数据用于后续识别 CH 驱动基因,这是通过 IntOGen 流程揭示正向选择信号来完成的。最终,基于这些数据构建了用于识别 CH 驱动突变的模型。
b) 模型训练与交叉验证:展示了基于机器学习的 BoostDM-CH 模型的训练和交叉验证过程,以 DNMT3A 基因为例。模型的输出将得分等于或大于 0.5 的突变判定为 CH 驱动突变。
c) 突变分类的解释:解释了 DNMT3A-R882H 突变如何基于模型训练中使用的特征的贡献被分类为驱动突变。雷达图中的数字对应于每个特征的 SHAP 值。具有正 SHAP 值的特征(即对将突变分类为驱动因素有积极贡献)在雷达图的 ‘0’ 线以上,主要贡献特征以粗体显示。
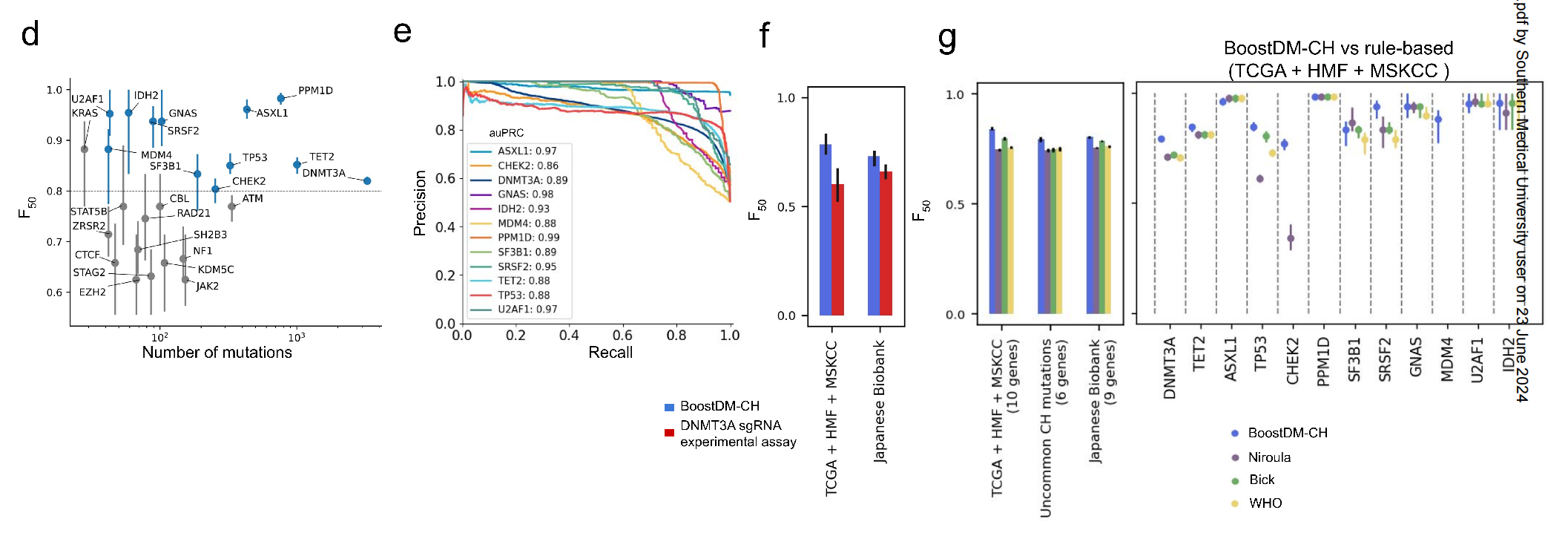
d) 交叉验证性能:展示了 25 个 CH 模型的交叉验证性能(中位数 ± 四分位间距(IQR)F50),作为观察到的突变数量的函数。蓝点代表那些 F50 高于 0.8 并且具有足够发现指数的基因模型,这些模型认为癌症基因组队列中的突变集合能够代表它们的 CH 驱动突变(高质量模型)。
e) 精确率-召回率曲线:展示了 12 个高质量 BoostDM-CH 模型的精确率-召回率曲线(以及区域值),这些曲线衡量了模型在不同阈值下的性能。
f) 模型与实验方法的性能比较:展示了 DNMT3A boostDM-CH 模型与 DNMT3A 实验基础编辑分析在 DNMT3A 血液体细胞突变分类中的性能(中位数 ± IQR F50)。
g) 模型与专家规则的性能比较:展示了 BoostDM-CH 模型与三组专家策划规则在血液体细胞突变分类中的性能(中位数 ± IQR F50)。左侧显示了三个 CH 数据集中的整体性能;右侧显示了其中一个数据集中特定基因的性能。PTM:翻译后修饰;NMD:无意义介导的衰变。
整体而言,Figure 1 展示了 BoostDM-CH 模型的开发流程、评估方法以及它们相对于传统专家规则的优势。通过这些模型,研究人员能够更准确地识别出与 CH 相关的驱动突变,这有助于我们理解 CH 的分子机制,并可能为临床诊断和治疗提供新的见解。
六、TORCH:基于细胞学图像的深度学习方法,区分未知原发部位的肿瘤起源

文献概述
这篇文章开发了一种基于细胞学图像的深度学习方法,名为TORCH(Tumor Origin differentiation using cytological histology),用于区分未知原发部位的肿瘤(CUP)的起源。
CUP是一种难以诊断的恶性肿瘤,因为其原发部位不明。研究者利用来自四家医院的57,220例患者的细胞学图像,训练了TORCH模型,以识别恶性肿瘤并预测肿瘤起源。
该模型在内部和外部测试集上的表现都非常好,癌症诊断的AUROC(接收者操作特征曲线下面积)值在0.953到0.991之间,肿瘤起源定位的AUROC值在0.953到0.979之间。TORCH在预测原发肿瘤起源方面表现出色,top-1准确率达到82.6%,top-3准确率为98.9%。
与病理学家的结果相比,TORCH显示出更好的预测效果,显著提高了初级病理医生的诊断分数。此外,与TORCH预测的肿瘤起源一致的患者,其总体生存期比接受不一致治疗的患者要好(27个月对比17个月)。研究强调了TORCH作为临床实践中有价值的辅助工具的潜力,尽管需要在随机试验中进一步验证。
研究还探讨了模型的解释性,使用注意力热图来解释模型预测结果,显示了模型预测中最重要的细胞学特征。此外,研究还对模型进行了消融实验,以评估临床变量与细胞学图像对模型性能的影响。最后,研究通过回顾性生存分析,评估了TORCH模型预测与患者治疗响应之间的关系。
整体而言,这项研究展示了深度学习在病理诊断领域的应用潜力,尤其是在处理未知原发肿瘤的诊断难题上。
重点关注
Fig. 1 展示了所提出的 TORCH 模型框架,该框架是一个深度学习系统,用于分析细胞学图像并预测未知原发肿瘤的起源。
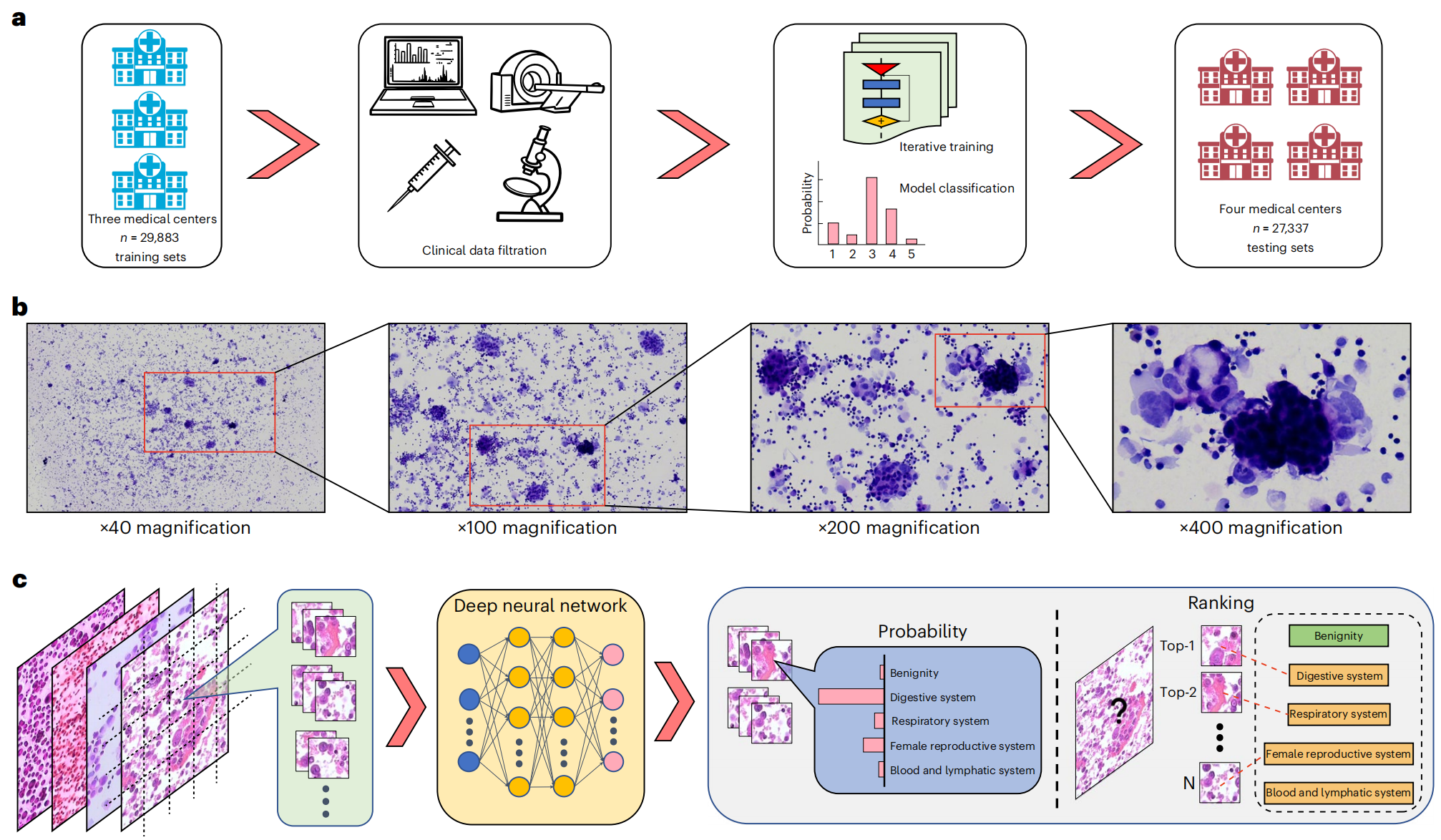
a. 模型训练集的构建:
研究者从三家大型三级转诊机构收集了总共 42,682 例病例数据,其中 70%(29,883 例)被用作训练集。这些临床病理数据是从放射影像科、病历系统和病理数字数据库中获取的。这表明研究者拥有一个大规模、多源的数据集来训练他们的深度学习模型。
b. 诊断过程中的图像放大:
在诊断过程中,大多数图像被放大到 ×200 或 ×400 的倍数进行观察。这通常是为了更清晰地观察细胞的形态特征,这些特征对于区分不同类型的肿瘤细胞至关重要。
c. 深度学习网络的目标和验证:
训练的深度学习网络使用细胞学图像,旨在根据最高预测概率分数将目标图像分为五个类别。这意味着模型将输出一个概率最高的类别,作为预测的肿瘤起源。分类结果在包括三个内部测试集(12,799 例)和两个外部测试集(14,538 例)的四个机构中进一步进行了验证。这显示了模型的泛化能力和在不同数据集上的可靠性。
N 代表第 N 个图像瓦片:在深度学习模型中,图像通常被分割成多个小的瓦片(tiles),每个瓦片都是模型输入的一部分。这有助于模型更细致地分析图像的不同区域,并提高整体的预测精度。
总体而言,Fig. 1 描述了一个综合的深度学习模型开发和验证流程,包括数据收集、图像处理、模型训练和多中心测试验证,旨在提高未知原发肿瘤诊断的准确性。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









