







小罗碎碎念
本期推文主题:人工智能在眼科疾病领域的最新研究进展
首先要做一个检讨,我发现自己把路走窄了,自己是研究肿瘤的,就只看肿瘤相关的文献,其他领域的基本不看,这就导致自己容易错过很多创新点,也少了很多可以交流的同行,要取百家之所长,哈哈。
- 昨天的推文讲的是肿瘤治疗中多模态多组学中的应用,今天的第一篇文献就是眼科疾病领域的
多模态,介绍了如何进行特征融合,并且还提出了单模态的信心度排名,这个确实给了我一些启发; - 第三篇文献也要引起注意,我之前写过好几期推文阐述“
医学数据属于小样本数据”以及“数据不平衡”的问题,如果你也关注这个方向,那么第三篇文献或许能给你启发; - 我在肿瘤相关的推文中,经常提
代谢组学,第五篇文献将代谢组学和AI结合,应用到了眼部疾病的鉴别诊断中,也非常有意思。

一、EyeMoS𝑡+:用于眼科疾病筛查的新型多模态学习框架

一作&通讯
| 角色 | 姓名 | 单位(中文) |
|---|---|---|
| 第一作者 | Ke Zou | a. 四川大学基础科学合成视觉国家重点实验室 b. 四川大学计算机科学学院 |
| 通讯作者 | Xuedong Yuan | a. 四川大学基础科学合成视觉国家重点实验室 b. 四川大学计算机科学学院 e. 天津大学智能与计算学院 g. 四川大学数学学院 |
文献概述
这篇文章是关于一种新型的多模态学习框架,即EyeMoS𝑡+,它被设计用于眼科疾病筛查。
该框架通过融合来自不同来源的信息来提高诊断的准确性,特别是针对糖尿病视网膜病变(DR)、糖尿病性黄斑水肿(DME)和年龄相关性黄斑变性(AMD)等眼科疾病。
- 多模态学习:EyeMoS𝑡+利用了
视网膜眼底图像(Fundus)和光学相干断层扫描(OCT)这两种常见的二维和三维成像技术。 - 不确定性估计:该方法不仅关注预测的准确性,还重视预测的信心度和鲁棒性,通过正态逆伽马(Normal-inverse Gamma, NIG)先验分布学习单模态数据的随机性和认知性不确定性。
- 信心感知融合:提出了一种基于信心度感知的融合框架,使用混合学生t分布来有效整合不同模态,增强模型的稳健性和可靠性。
- 信心度排名正则化:引入了一种新的信心度感知排名正则化项,以确保融合模态的信心度始终超过单模态。
- 实验验证:在公共和内部数据集上进行了广泛的实验,验证了模型在稳健性、准确性和可靠性方面的表现,特别是在处理噪声输入、识别缺失模式和处理未见数据方面的能力。
- 代码开源:文章提供了实现EyeMoS𝑡+方法的代码链接。
整体来看,这篇文章提出了一个创新的多模态学习框架,通过融合不同模态的信息,并引入信心度感知机制,提高了眼科疾病筛查的准确性和鲁棒性。
重点关注
Fig. 1 展示了两种不同的多模态分类方法在眼科疾病筛查中的比较:
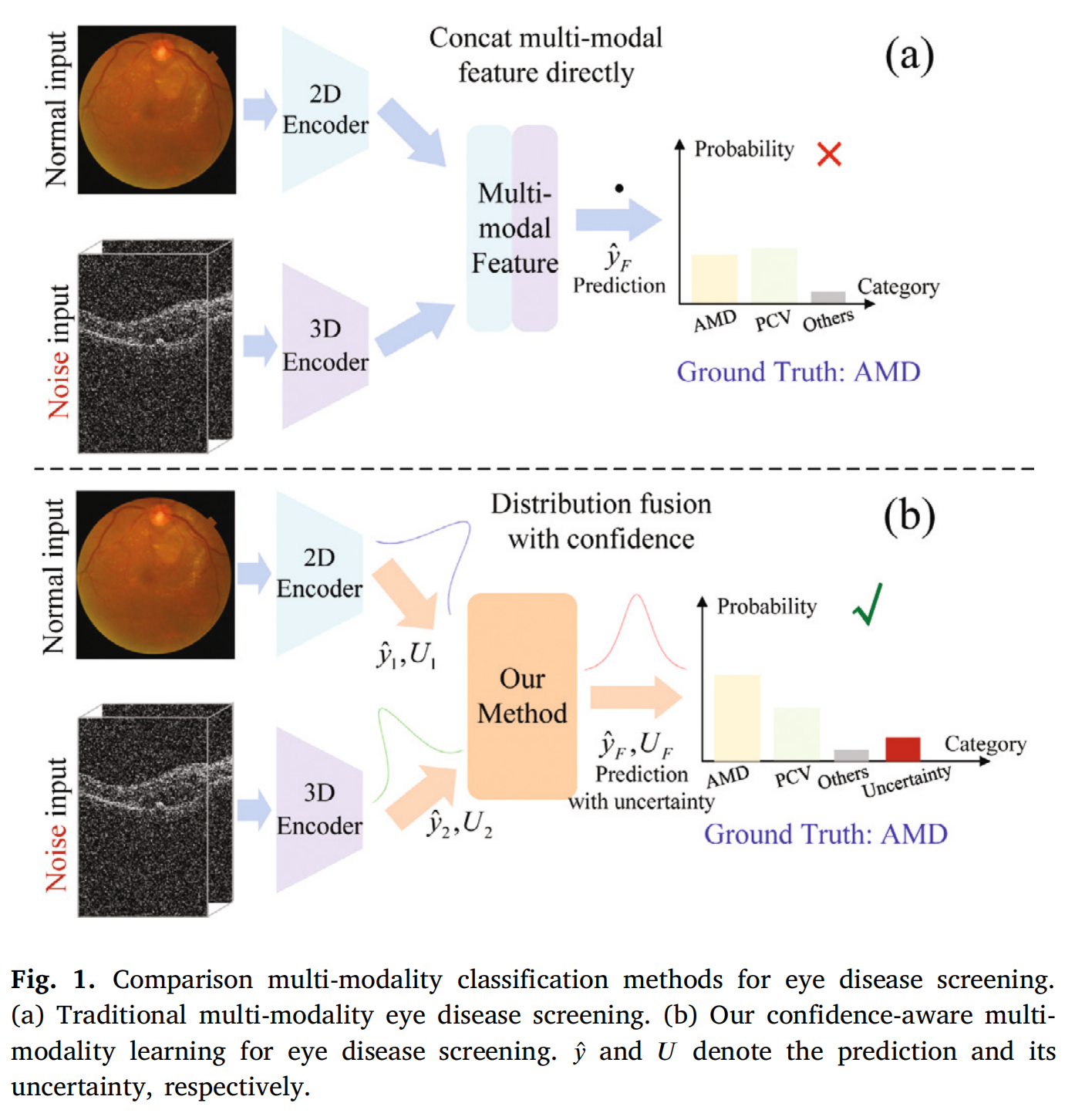
-
传统的多模态眼科疾病筛查 (a):
- 这种方法涉及将来自不同模态的数据(例如,眼底图像和OCT扫描)直接结合。
- 它没有明确考虑数据的不确定性或信心度,这可能导致在某些情况下,尤其是当数据存在噪声或质量不高时,筛查结果的准确性和可靠性受到影响。
-
作者提出的信心感知多模态学习 (b):
- 这种方法提出了一种新颖的框架,即EyeMoS𝑡+,它在多模态数据融合过程中考虑了每个模态的信心度和不确定性。
- 通过使用正态逆伽马分布作为先验,该方法学习了每个单模态数据的随机性(aleatoric)和认知性(epistemic)不确定性。
- 进一步地,该方法使用混合学生t分布来整合不同模态的信息,这赋予了模型重尾特性,增强了其稳健性和可靠性。
- 特别地,信心感知融合框架中引入了一种新的信心度感知排名正则化项,它促使模型更加合理地对噪声单模态和融合模态的信心度进行排序,从而提高了整体筛查的可靠性和准确性。
在Fig. 1中,符号 ̂𝑦 表示预测结果,而 𝑈 表示相应的不确定性。在传统的多模态筛查方法中,没有充分量化和利用不确定性信息,而在信心感知多模态学习方法中,不确定性被视为一个重要的指标,用于提高模型对不同输入数据的信心度评估,从而在面对具有挑战性的情况(如高斯噪声和模态缺失)时,提供更加稳健的筛查结果。
二、探讨在中国实施由数字技术驱动的分层医疗筛查模式带来的成本效益和成本效用

一作&通讯
以下是文章中提到的第一作者和通讯作者以及他们对应的单位,单位英文名称已翻译为中文:
| 角色 | 姓名 | 对应单位 |
|---|---|---|
| 第一作者 | Xiaohang Wu | 1. 眼科国家重点实验室,中山眼科中心,中山大学,广东省眼科和视觉科学重点实验室,广东省眼部疾病临床研究中心,广州,广东,中国。 |
| 第一作者 | Yuxuan Wu | 同上 |
| 第一作者 | Zhenjun Tu | 2. 中山大学,计算机科学与工程学院,广州,广东,中国。 |
| 通讯作者 | Yizhi Liu | 1. 眼科国家重点实验室,中山眼科中心,中山大学,广东省眼科和视觉科学重点实验室,广东省眼部疾病临床研究中心,广州,广东,中国。 |
| 通讯作者 | Rong Pan | 2. 中山大学,计算机科学与工程学院,广州,广东,中国。 |
| 通讯作者 | Haotian Lin | 7. 海南眼科医院,眼科国家重点实验室,中山眼科中心,中山大学,海口,海南,中国。 |
文献概述
这篇文章探讨了在中国实施一种由数字技术驱动的分层医疗筛查模式(DH筛查)的成本效益和成本效用,特别是针对
白内障筛查。
研究使用了决策分析马尔可夫模型来评估不同白内障筛查策略(无筛查、远程筛查、AI筛查和DH筛查)的成本效益和成本效用。模拟了一个由10万人组成的队列,从50岁开始,通过30个1年的马尔可夫周期进行模拟。
主要结果显示,DH筛查在城市和农村中国都优于无筛查、远程筛查和AI筛查。与远程筛查相比,年度DH筛查是最具成本效益的策略,分别在城市和农村避免了341(338至344)年和1326(1312至1340)年的失明。与AI筛查相比,在城市和农村分别避免了37(35至39)年和140(131至148)年的失明。所有敏感性分析都证实了这些发现的稳健性。
研究表明,DH筛查在中国城市和农村都是成本效益的,并且年度筛查是最具有成本效益的选择,为低收入和中等收入国家的决策者促进公共眼部健康提供了经济理由。
数字技术为医疗行业带来了革命性的变革,包括大数据、人工智能(AI)、云计算、物联网(IoT)、5G无线网络和数字安全技术如区块链。这些技术的快速发展可以被用来改善资源配置和医疗效率,特别是在高质量医疗资源稀缺或分布不均的低收入和中等收入国家。
研究还讨论了DH筛查模式的优势,包括易于使用智能手机进行AI筛查、提高转诊依从性以及显著减少人工评估时间和劳动成本,同时通过社区基础的AI确认不牺牲准确性。DH筛查系统通过移动终端将初级筛查带入家庭环境,这对人群更加可访问,特别是在偏远地区。
文章最后指出,尽管研究提供了DH筛查模式在中国具有成本效益的初步证据,并可能在世界其他医学领域进一步实施,但仍存在一些局限性,包括对疾病治疗过程的简化、未来研究将考虑包括多种眼病筛查在内的更全面的眼科检查等。
重点关注
Fig. 1 描述的数字分层筛查模式(DH筛查)是一个综合利用多种数字技术的系统,旨在提高眼科疾病的筛查效率和可及性。
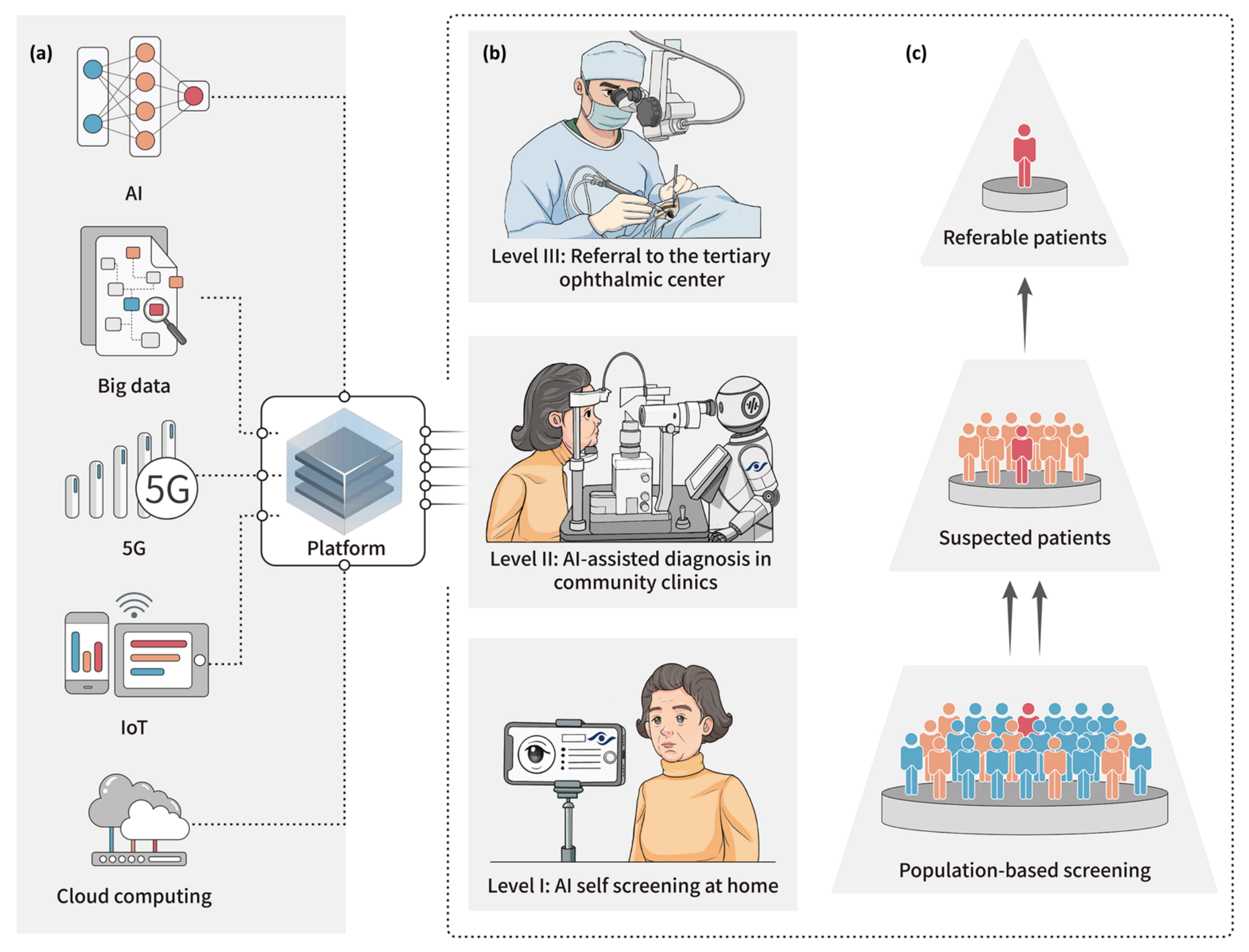
a. 数字技术在分层筛查平台的组成:
这部分展示了组成DH筛查平台的各种数字技术,包括但不限于:
- 人工智能(AI):用于图像识别和疾病诊断的算法和模型。
- 云计算:提供数据存储、处理和分析的服务。
- 物联网(IoT):连接各种医疗设备和传感器,实现远程监控和数据收集。
- 5G无线网络:提供高速、低延迟的网络连接,支持实时数据传输和远程医疗服务。
b. DH筛查和转诊模式的工作流程:
这部分描述了DH筛查的步骤,包括:
- 参与者在家中使用移动设备进行初步的AI筛查。
- 疑似病例被引导到社区医疗机构进行更全面的AI诊断评估。
- 根据AI的阳性结果,需要进一步医疗关注的患者在专业三级医疗机构接受适当治疗。
c. 通过IoT和社区诊所的AI筛查和诊断:
这部分强调了IoT技术和社区诊所在DH筛查中的作用,包括:
- 使用IoT设备在家中进行初步筛查,使用智能设备收集眼部图像。
- 社区诊所使用AI进行更深入的诊断,帮助识别需要转诊的疑似患者。
- 将需要更专业治疗的患者推荐到更高级别的眼科中心进行全面治疗。
整体而言,Fig. 1 展示了一个集成了多种先进技术的筛查系统,目的是提高医疗服务的效率和覆盖面,特别是在初级医疗和偏远地区。通过这种方式,DH筛查有助于早期发现和治疗眼科疾病,减少因治疗不及时导致的视力损害。
三、在眼科领域,如何通过隐式公平学习方法构建一个更公平的AI系统,以减少性别和年龄偏见

一作&通讯
| 角色 | 作者名 | 单位(中文) |
|---|---|---|
| 第一作者 | Weimin Tan | 复旦大学,计算机科学学院,上海智能信息处理重点实验室 |
| Qiaoling Wei | 复旦大学,眼科研究所,复旦大学附属眼耳鼻喉科医院 | |
| 通讯作者 | Bo Yan | 复旦大学,计算机科学学院,上海智能信息处理重点实验室 |
| Chen Zhao | 复旦大学,眼科研究所,复旦大学附属眼耳鼻喉科医院 |
文献概述
这篇文章讨论了在眼科领域中,如何通过一种名为FairerOPTH的隐式公平学习方法来构建一个更公平的人工智能(AI)系统,以减少性别和年龄偏见。
研究团队强调了AI在医疗领域中准确性和公平性的重要性,并指出有偏见的医疗AI系统可能对实现公平和平等的医疗保健构成重大风险。
FairerOPTH系统结合了眼底特征与眼病之间的因果关系,这种关系相对独立于种族、性别和年龄等敏感属性。研究结果表明,在对8,405名患者进行的大规模和多样化的数据集上,FairerOPTH在38种眼底超广角成像和16种眼底窄角成像的眼病诊断的准确性和公平性方面,显著优于几种现有的最先进方法。
文章还探讨了AI在眼科中实现公平性的挑战,包括样本不平衡、眼底图像的内在多样性、与个体属性相关的健康差异以及数据收集方法的偏差。为了解决这些挑战,研究者开发了一种公平意识算法,以考虑样本不平衡、适应疾病多样性、减轻属性偏见,并使用公平的数据收集实践获取的数据。
此外,文章还报告了FairerOPTH在不同年龄和性别组别的患者中筛查眼病的性能,并与其他几种最先进的多标签分类方法进行了比较。结果表明,FairerOPTH在减少性别偏见方面表现更好,特别是在诊断晶状体脱位等疾病时。FairerOPTH还能够在不依赖眼底特征注释的情况下,直接部署在眼底图像数据集上。
最后,文章讨论了FairerOPTH方法的潜在扩展性,以及未来研究的方向,包括开发其他有效的、可推广的隐式公平学习方法,以及评估这种方法是否可以推广到其他全球关注的疾病,以减轻AI带来的不公平问题。
重点关注
Fig. 1 展示了数据集的特征,具体分析如下:
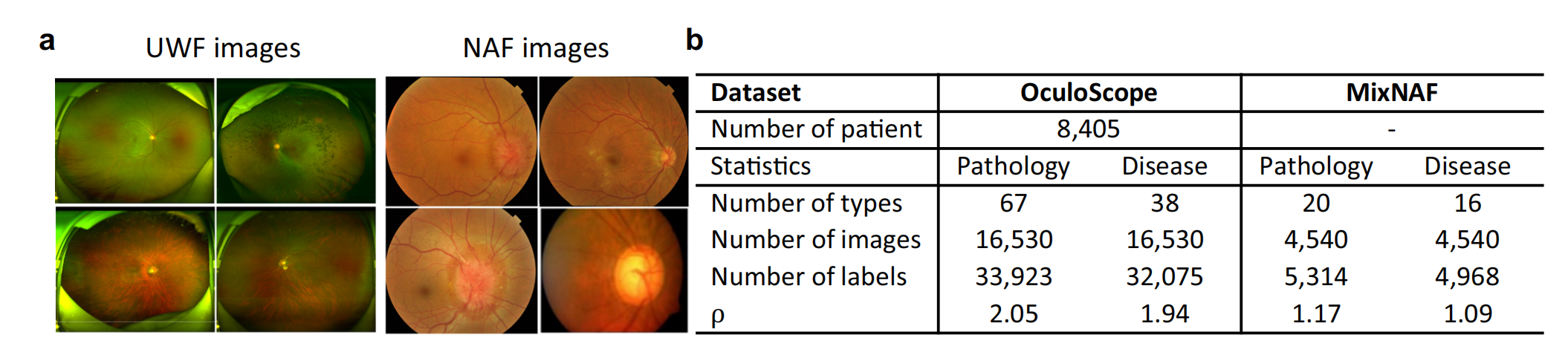
a. 眼底图像类型:图像包括超广角场(UWF)和窄角(NAF)图像,它们在现代临床系统中对各种眼病的诊断起着基础性作用。UWF 成像是一种先进的方法,能够在单次捕获中覆盖高达200°的偏心率,而更常见的NAF 成像的视场角为30-60°。
b. 数据集统计:OculoScope 和 MixNAF 数据集的统计数据显示了标签密度 ($ \rho = \frac{1}{N} \sum_{i=1}^{K} |y_i| KaTeX parse error: Can't use function '\)' in math mode at position 1: \̲)̲ ,这个公式量化地表明单个眼底… y_i KaTeX parse error: Can't use function '\)' in math mode at position 1: \̲)̲ 是第 \( i $) 种疾病的数量,( N N N ) 代表图像的总数, K K K代表疾病类型的数量。
c. OculoScope 数据集疾病分布:OculoScope 数据集中38种疾病的样本分布极其不均衡。这意味着某些疾病类型的图像在数据集中出现的频率比其他疾病高。
d. MixNAF 数据集疾病分布:MixNAF 数据集中16种疾病的样本分布同样极其不均衡。这与 OculoScope 数据集的情况相似,表明在数据集中不同疾病的代表性是不平等的。
e. 眼底图像中的眼底特征可视化:展示了眼底图像中眼底特征的可视化表示。包括各种病理标志,如出血、渗出、血管瘤等,这些特征对于眼病的诊断至关重要。
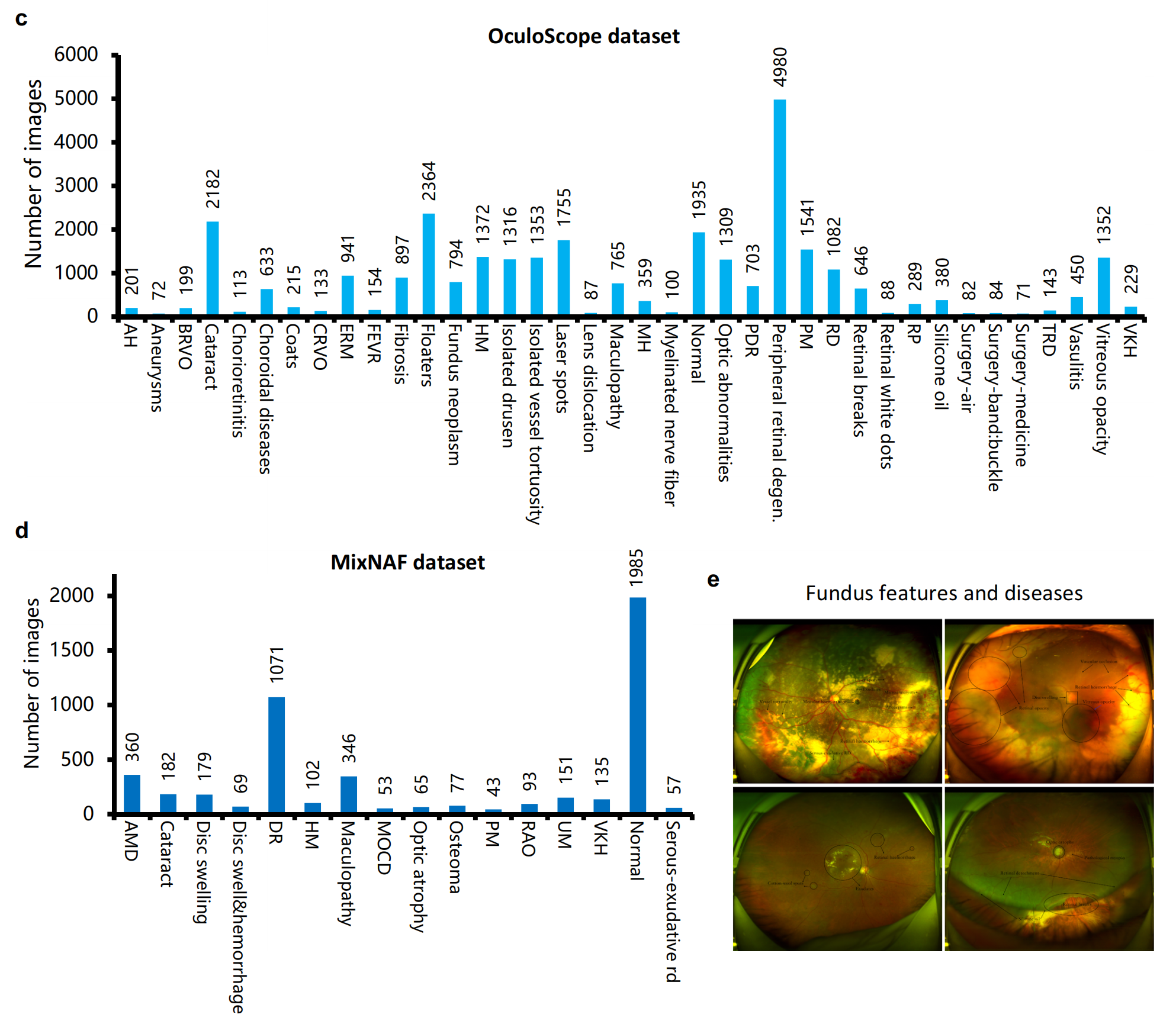
这个图表提供了对数据集特征的深入理解,包括成像技术的差异、数据集的标签密度、疾病分布的不均衡性,以及眼底图像中的关键特征。这对于开发和评估眼病诊断的 AI 系统是至关重要的,因为它影响着模型训练和评估的结果。
四、早期视觉经验对后期使用颜色线索的影响

一作&通讯
| 角色 | 姓名 | 对应单位中文翻译 |
|---|---|---|
| 第一作者 | Marin Vogelsang | 1. 麻省理工学院大脑与认知科学系,美国马萨诸塞州剑桥市 2. 奥斯纳布吕克大学认知科学研究所,德国奥斯纳布吕克 |
| 第一作者(共同) | Lukas Vogelsang | 1. 麻省理工学院大脑与认知科学系,美国马萨诸塞州剑桥市 3. 瑞士洛桑联邦理工学院大脑与心智研究所,瑞士洛桑 |
| 通讯作者 | Lukas Vogelsang | 麻省理工学院大脑与认知科学系,美国马萨诸塞州剑桥市 |
文献概述
这篇文章探讨了早期视觉经验对后来使用颜色线索的影响。
研究基于对10名先天性失明儿童的观察,这些儿童在后期通过手术恢复了视力。研究发现,在去除颜色线索后,这些儿童的识别表现显著下降,而同龄的正常视力儿童则没有这种下降。这可能是因为晚期恢复视力的儿童在视力恢复时,他们的颜色系统比新生儿更为成熟,导致他们过度依赖颜色线索。通过深度神经网络的模拟实验支持了这一假设。
研究还指出,灵长类动物,包括人类,在颜色视觉方面非常出色,仅次于鸟类。颜色处理在灵长类动物的神经生理学中占有重要地位,主要视觉皮层对颜色非常敏感,而且大部分神经元对颜色有选择性。颜色信息与视觉记忆有交互作用,能够增强对视觉场景的记忆,并且物体的颜色外观也会受到记忆的影响。
实验中,参与者被要求识别常见物品的黑白图像和全色图像。结果显示,对于Prakash项目中的失明后恢复视力的个体,颜色和灰度图像的识别表现有显著差异。研究者提出了一个假设:正常发展的婴儿从不成熟的视觉系统开始,新生儿视网膜上的视锥细胞在传导能力上有限,这限制了婴儿体验到的颜色输入。与此相反,Prakash儿童在手术后立即拥有了更成熟的视锥细胞,能够提供接近正常的颜色视觉。尽管一开始拥有良好的颜色视觉可能看起来是理想的,但研究者假设Prakash儿童立即沉浸在丰富的颜色图像中可能实际上对他们不利,可能导致他们对颜色线索的不自然过度依赖。
为了验证这一假设,研究者测试了Prakash儿童手术后的颜色敏感性,并进行了计算模拟。结果显示,Prakash儿童在手术后立即展现出成熟的色觉。使用深度卷积神经网络(DCNNs)的计算研究进一步评估了早期颜色敏感性对后期图像分类性能的影响。研究发现,与立即接受全色图像训练的C2C模型相比,从灰度到颜色训练的G2C模型在灰度图像上的表现更为稳定。
研究结论指出,正常发展过程中的初始颜色感知限制可能是适应性和有益的,而不是不利的。这为正常发展的方式提供了可能的解释,并指出即使那些看似提高输入质量的偏差,也可能对后来的表现产生负面影响。这一假设也可能与理解系统发育发展有关。
研究结果对设计临床干预措施具有潜在意义,特别是在晚期视力恢复的背景下,建议在手术后立即进行有意识的颜色减少,以促进后期分类的稳健性。此外,这些发现表明,从生物发展中汲取见解可以帮助提高机器视觉系统的整体性能。研究还可能与理解哺乳动物视觉系统的关键组织原则有关,即大细胞和锥细胞途径的不同敏感性。
重点关注
Fig. 1中展示的实验结果,涉及对晚期恢复视力的个体进行的实验。
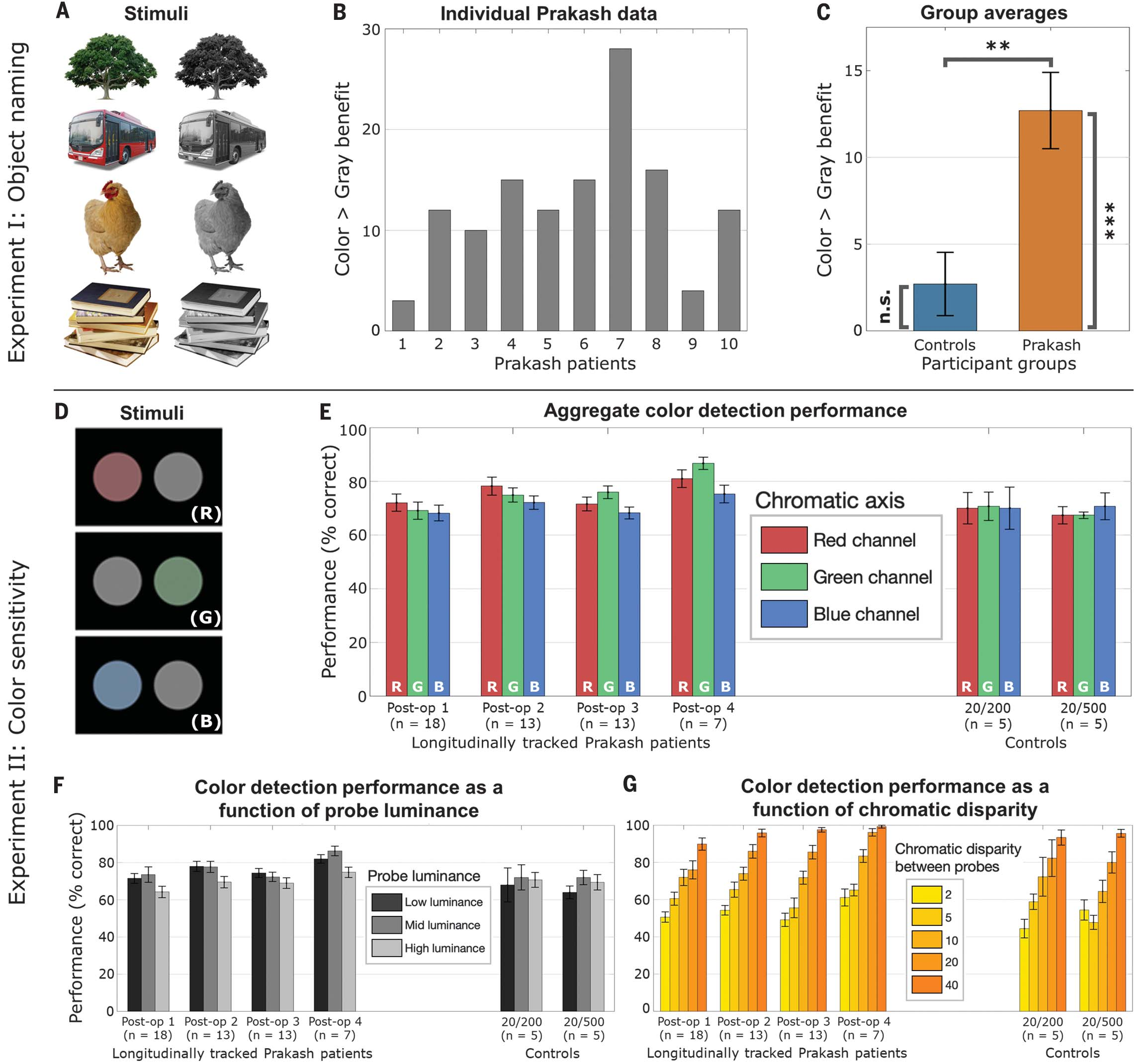
以下是对每个部分的分析:
Fig. 1A: 展示了颜色(左侧)和灰度(右侧)条件下的对象命名实验的样本刺激。这表明实验设计了两种视觉条件来测试参与者对颜色和灰度图像的识别能力。
Fig. 1B: 展示了Prakash儿童的命名结果,图中显示了个别参与者在“color > gray benefit”(颜色优势)度量上的数据。
Fig. 1C: 展示了Prakash儿童和模糊匹配对照组在“color > gray benefit”度量上的组平均值。误差条表示标准误差。t检验的结果显示了统计显著性水平,其中*P < 0.05表示在5%的显著性水平下差异显著,**P < 0.01表示在1%的显著性水平下差异显著,***P < 0.001表示在0.1%的显著性水平下差异显著,而n.s.表示不显著。
Fig. 1D: 展示了颜色敏感性实验的示例刺激。
Fig. 1E: 展示了Prakash患者在手术后四个不同时间点的颜色敏感性测试结果,以及对照组(佩戴20/200和20/500模糊眼镜)的结果。
Fig. 1F和1G: 展示了颜色敏感性测试的结果,分别以(F)亮度强度和(G)两个色盘之间的色相差为函数进行展示。这些图表展示了亮度和色相差如何影响颜色敏感性测试的表现。
整体来看,这些图表和数据提供了对晚期恢复视力个体在颜色和灰度识别能力以及颜色敏感性方面的深入理解。特别是,它们揭示了这些个体在去除颜色线索时识别能力下降的现象,以及他们的颜色敏感性如何随时间恢复和变化。这些发现对于理解视觉发展和感知能力的影响至关重要。
五、关于代谢组学在常见遗传性视网膜退化症鉴别诊断中的应用

一作&通讯
| 角色 | 姓名 | 单位(中文) |
|---|---|---|
| 第一作者 | Wei-Chieh Wang | 1. 台湾大学化学系 2. 长庚纪念医院眼科 |
| 第一作者 | Chu-Hsuan Huang | 3. 清华大学医学院 4. 台湾大学医学院医学基因组学与蛋白质组学研究所 |
| 通讯作者 | Cheng-Chih Hsu | 1. 台湾大学化学系 8. 李文霍克实验室有限公司 |
| 通讯作者 | Ta-Ching Chen | 6. 台湾大学医院眼科 7. 台湾大学医学院眼科 9. 台湾大学医院前沿医学中心 10. 台湾大学发展生物学与再生医学研究中心 11. 台湾大学医院医学研究中心 |
文献概述
这篇文章是关于代谢组学在常见遗传性视网膜退化症(Inherited Retinal Degenerations, IRD)的鉴别诊断中的应用。
研究团队通过分析血清代谢物的轮廓,探索了它们在IRD中的诊断潜力。
-
IRD诊断挑战:由于IRD在表型和基因型上的复杂性,诊断具有挑战性。临床信息在遗传诊断前非常重要。
-
代谢组学的应用:代谢组学研究生物样本中小分子(<1500 Da)的整体构成,这些小分子由遗传密码和生物反应决定。研究显示,IRD的常见类型,包括视网膜色素变性(Retinitis Pigmentosa, RP)、锥杆细胞营养不良(Cone-Rod Dystrophy, CRD)、Stargardt病(STGD)和Bietti结晶体营养不良(BCD),可以根据它们的代谢物热图区分。
-
代谢物的识别:与对照组相比,除了BCD外,每种IRD都在火山图中识别出数百种代谢物,这些代谢物被视为潜在的诊断标记。
-
机器学习模型:研究中利用机器学习模型,以100%的准确率区分CRD和STGD的表型,尽管它们在临床上有重叠。此外,EYS、USH2A相关RP和其他RP类型,尽管在临床上有相似特征,也可以使用机器学习模型以85.7%的准确率诊断。
-
诊断工作流程:文章提出了一个基于代谢组学的诊断工作流程,结合质谱和机器学习,用于IRD的临床和分子诊断。
-
研究局限性:需要在外部数据集中验证结果,并且由于IRD的遗传谱广泛,对每个潜在患者和家庭成员进行全面的基因组分析既耗时又昂贵。
-
未来方向:研究提出,将代谢组学分析纳入临床信息,有助于在进行遗传咨询前对疑似IRD患者进行疾病筛查和诊断。
文章强调了代谢组学在IRD诊断中的潜力,并提出了一个新的诊断方法,该方法可能有助于在基因治疗等治疗策略中实现更早和更准确的诊断。
重点关注
Fig. 5 展示了两方面的内容:代表性病例的眼底摄影和自发荧光图像,以及提出的IRDs诊断流程图。
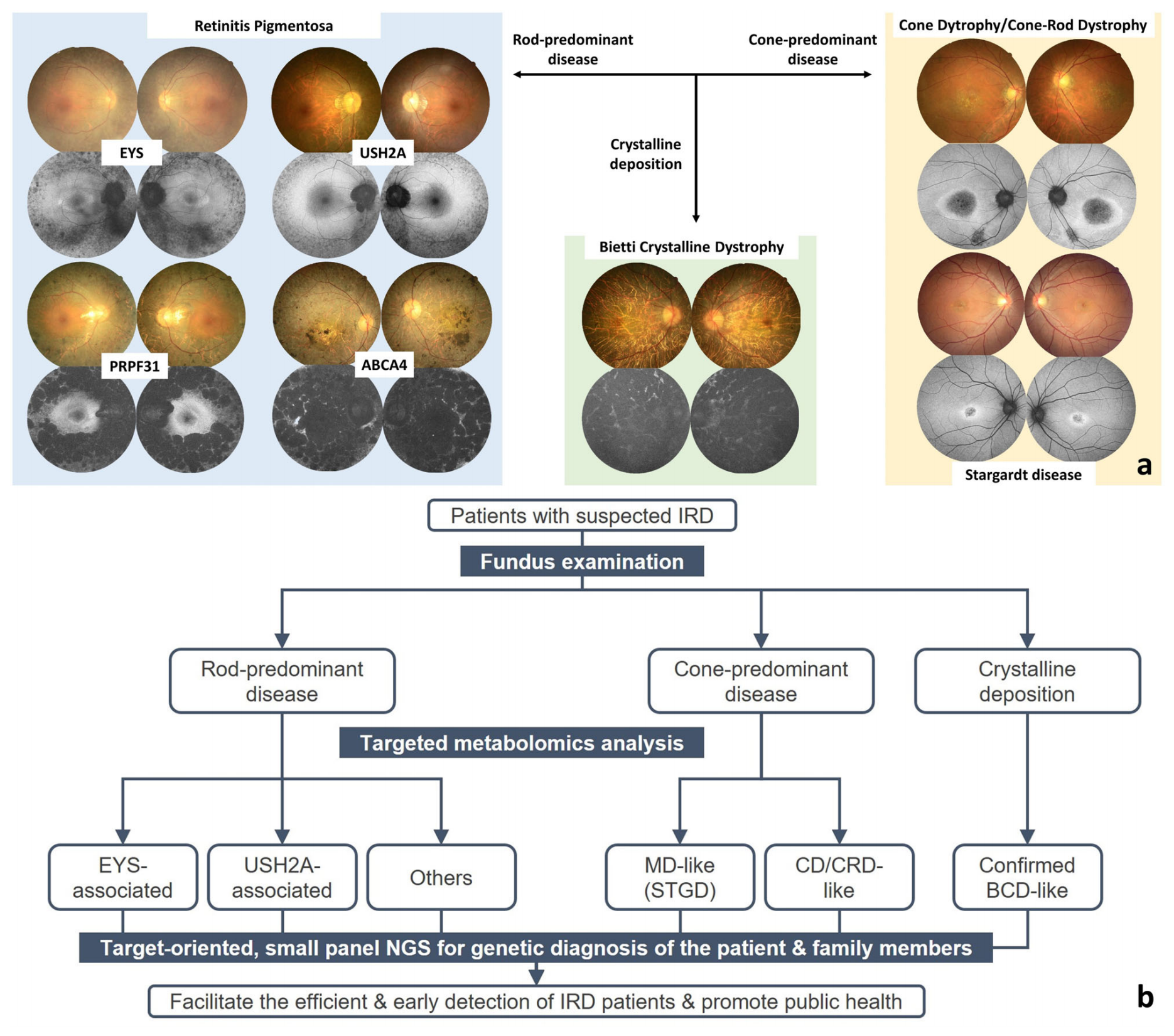
a. 眼底摄影和自发荧光图像分析:
- 不同基因型的视网膜色素变性(RP)通过眼底检查难以区分,它们共享一些特征,如苍白的视盘、血管变细和色素变化,差异仅在于疾病的严重程度。
- 锥杆细胞营养不良(CD/CRD)和Stargardt病(STGD)的眼底外观也无法区分,两者都具有特征性的中心性黄斑病变。
- 然而,Bietti结晶体营养不良(BCD)的眼底外观特征为结晶沉积,可以很容易地区分其他IRDs。
b. 诊断流程图:
- 作者提出了一个诊断流程图,以促进IRDs的早期诊断,该流程图结合了临床信息、代谢组学分析和基因诊断。
- 首先通过眼底检查确定IRDs属于杆细胞优势疾病、锥细胞优势疾病或结晶沉积疾病。
- 然后,通过结合针对性的代谢组学分析和机器学习模型,可以进一步区分杆细胞优势疾病中的EYS和USH2A基因型,以及锥细胞优势疾病中的STGD和CD/CRD。
- 最终,可以进行针对性的小面板下一代测序(NGS),以实现患者及其家庭成员的基因诊断。
关键点:
- 眼底检查是初步诊断IRDs的重要手段,但某些类型的IRDs在眼底表现上具有重叠,难以区分。
- 代谢组学分析和机器学习模型的应用可以提供更精确的疾病亚型区分,有助于临床诊断和治疗决策。
- 通过这种综合诊断流程,可以在分子水平上对IRDs进行更准确的分类,为患者提供个性化的医疗方案。
Fig. 5 强调了在IRDs诊断中结合多种诊断工具的重要性,以及如何通过这些工具提高诊断的准确性和效率。
六、人工智能(AI)从眼底摄影和光学相干断层扫描图像中检测糖尿病性黄斑水肿方面的性能研究

一作&通讯
| 角色 | 姓名 | 单位名称(中文) |
|---|---|---|
| 第一作者 | Ching Lam | 香港中文大学眼科及视觉科学系 |
| 通讯作者1 | An Ran Ran | 香港中文大学眼科及视觉科学系 |
| 通讯作者2 | Carol Y. Cheung | 香港中文大学眼科及视觉科学系 |
文献概述
这篇文章是一项系统综述和元分析,研究了人工智能(AI)在从眼底摄影(Fundus Photography, FP)和光学相干断层扫描(Optical Coherence Tomography, OCT)图像中检测糖尿病性黄斑水肿(Diabetic Macular Edema, DME)方面的性能。
研究发现,基于FP和OCT的AI均展现出令人满意的性能,其中OCT基础的AI表现更佳。
研究还探讨了提高模型性能的潜在因素,包括深度学习技术、更大的训练数据集和更高的数据多样性。
研究结果表明,FP基础的AI算法可以整合到现有的糖尿病视网膜病变筛查项目中,以提高临床工作流程;而OCT基础的AI算法可以用来更准确地检测FP阳性个体中的DME。
研究还指出,需要进一步的外部验证来评估模型的普适性,并提出了未来研究的方向,包括估算最优样本量、OCT体积扫描的影响、报告标准化等。
文章的主要结论包括:
- 基于FP和OCT的AI在检测DME方面都获得了满意的性能。
- 深度学习技术、更大的训练数据集和更多的数据多样性可能提高模型性能。
- FP基础的算法可以整合到现有的糖尿病视网膜病变筛查程序中,以提高临床工作流程。
- OCT基础的算法可以用来更准确地筛查FP阳性个体中的DME。
研究的局限性在于,算法结果的标准化不足,以及在患者人口统计学、OCT体积扫描和外部验证方面的数据不足。未来的研究需要进行外部验证,以评估模型的普适性,并进一步探讨最优样本量、类别平衡、患者人口统计学以及OCT体积扫描的额外益处。
重点关注
Figure 1 展示了文献选择流程的流程图,用于识别和筛选与AI检测糖尿病性黄斑水肿(DME)相关的研究。
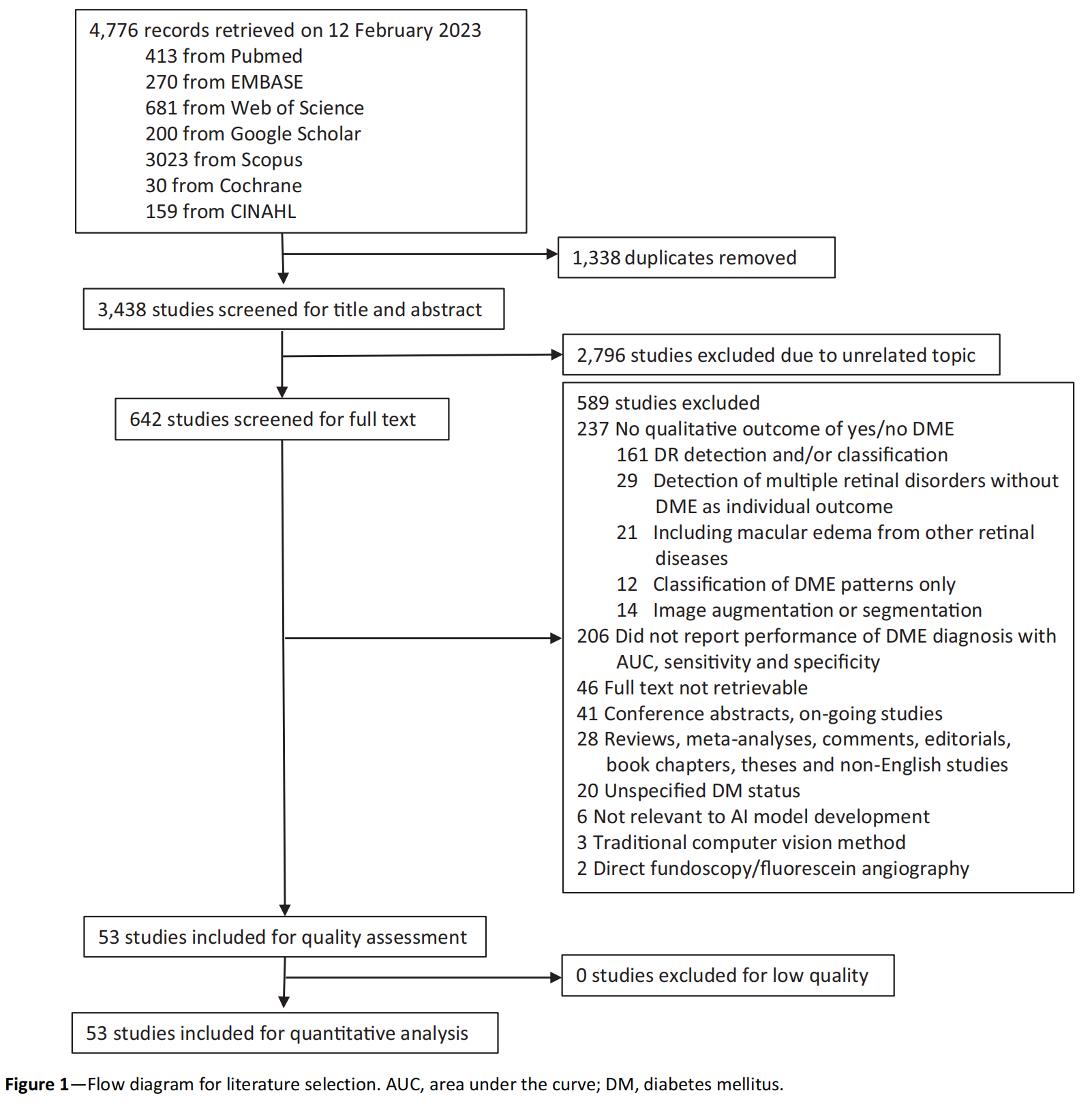
-
检索记录:最初,研究者检索到了4,776条记录,这些记录来自多个数据库,包括PubMed、EMBASE、Web of Science、Google Scholar、Scopus、Cochrane Library和CINAHL。
-
去除重复:在进行初步筛选之前,首先去除了1,338条重复的记录,剩下3,438条研究记录。
-
标题和摘要筛选:对剩余的3,438条记录进行了标题和摘要的筛选,以确定它们是否与研究主题相关。在这一阶段,2,796条记录因为主题不相关而被排除。
-
全文审查:对剩下的642条记录进行了全文审查,以进一步确定它们是否符合纳入标准。
-
排除不符合条件的研究:在全文审查过程中,根据排除标准,排除了589条记录。排除的原因可能包括:没有提供DME的定性结果、使用传统计算机视觉方法而非AI技术、没有报告敏感性、特异性和接收者操作特征曲线下面积(AUROC)等。
-
质量评估:对剩下的53项研究进行了质量评估,没有研究因为质量低而被排除。
-
最终纳入:最终,53项研究被纳入了这项系统综述和元分析。
整体来看,这个流程图提供了一个清晰的视角,展示了研究者如何从大量的文献中筛选出符合特定纳入标准的研究,以进行后续的分析和综述。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









