







小罗碎碎念
今天这期推文收纳了人工智能在鼻咽癌领域的最新研究进展,既涉及影像组学也涉及病理组学。
在写这期推文的时候,刚好看到了国自然基金放榜的消息,在这里也祝各位关注小罗的老师能如愿上榜!!
正在积极备战的老师们,也可以多关注关注小罗的推文,也许哪天就找到灵感了呢,哈哈。

一、全自动跨域互助学习框架提升鼻咽癌磁共振成像诊断

一作&通讯
| 角色 | 姓名 | 单位 | 单位(中文) |
|---|---|---|---|
| 第一作者 | 董 | School of Biomedical Engineering, Southern Medical University | 南方医科大学生物医学工程学院 |
| 第一作者 | 杨 | Department of Medical Imaging Center, Nanfang Hospital, Southern Medical University | 南方医科大学南方医院医学影像中心 |
| 通讯作者 | 张 | School of Biomedical Engineering, Southern Medical University | 南方医科大学生物医学工程学院 |
| 通讯作者 | 梁 | School of Biomedical Engineering, Southern Medical University | 南方医科大学生物医学工程学院 |
文献概述
这篇文章提出了一种用于鼻咽癌(Nasopharyngeal Carcinoma, NPC)原发肿瘤全自动诊断的跨域互助学习框架。
该框架利用头颈部磁共振成像(H&N MR images)进行准确的T分期,这对于指导治疗决策和预测不同风险组患者结果至关重要。
研究团队设计了一个基于卷积神经网络的系统,包含3D跨域知识感知网络(CKP net)和多域互信息共享融合网络(M2SF net),以自动化整个原发肿瘤诊断过程。
CKP net利用双判别器生成对抗网络(GAN)架构,将输入图像转换到分割图域和距离变换图域,专注于肿瘤强度变化和内部异质性。M2SF net通过双路径领域特定表示模块和互信息融合模块,智能地衡量和整合多域、多尺度T分期诊断导向特征。
通过内部和外部MR图像数据集的评估,实验结果表明,该方法在肿瘤分割和T分期方面超越了现有算法,展现出临床应用的潜力,为临床医生在治疗决策和预后预测方面提供了有价值的帮助。
重点关注
Fig. 1 展示了鼻咽癌原发肿瘤在四个不同T分期的二维轴向视图。
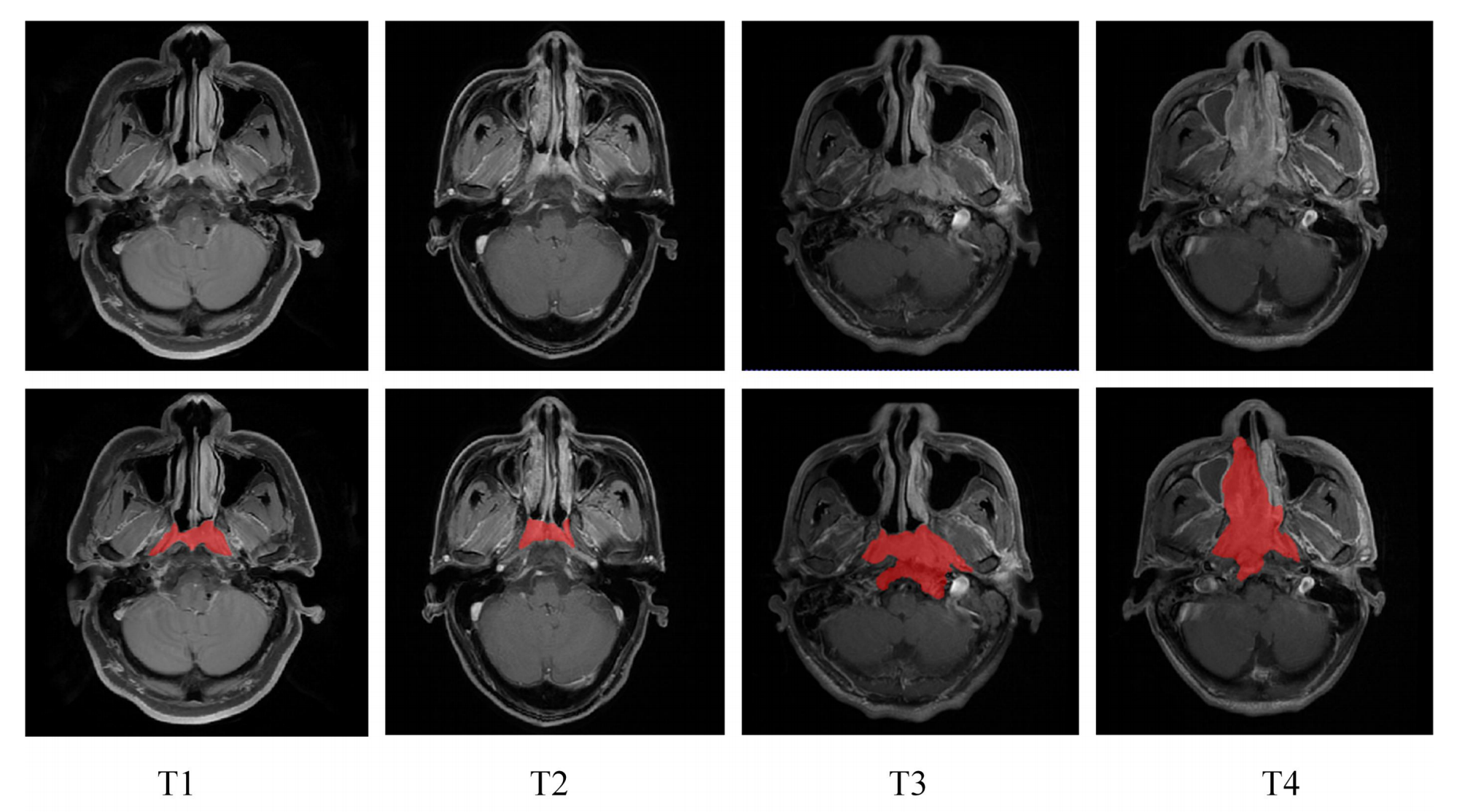
图中的红色区域表示了通过手动分割得到的鼻咽癌毛肿瘤体积(Gross Tumor Volumes, GTV)。
- 二维轴向视图:指的是从患者身体的轴向切面,也就是从头顶到脚底的方向进行的横截面图像,这通常是医学成像中的常规视图。
- 四个不同T分期:根据肿瘤的大小、位置和侵袭范围,肿瘤-淋巴结-转移(Tumor-Node-Metastasis, TNM)分期系统将肿瘤分为不同的T分期(T1至T4),每个分期代表不同的肿瘤发展阶段。
- 红色区域:在图像中用红色标出,这通常在医学成像中用来表示肿瘤的位置和范围,便于观察和分析。
- 手动分割:意味着这些GTV边界是由医生或放射科技师手动在图像上定义的,这需要专业知识和经验来准确识别肿瘤的边界。
- 毛肿瘤体积(GTV):指的是在医学成像中识别出的肿瘤的实际物理体积,它是制定放疗计划时确定照射区域的重要依据。
分析这样的图表有助于理解鼻咽癌在不同分期的形态学特征,以及如何通过影像学方法来评估肿瘤的侵袭程度。这对于临床治疗计划的制定至关重要,因为不同的T分期可能需要不同的治疗方法和策略。
二、提高放疗精确度:VCE-MRI在鼻咽癌原发肿瘤勾画中的临床评估

一作&通讯
| 角色 | 姓名 | 单位名称(中文) |
|---|---|---|
| 第一作者 | Wen Li | 香港理工大学健康科技与信息学系 |
| 并列第一作者 | Dan Zhao | 北京大学肿瘤医院放射肿瘤科 |
| 通讯作者 | Jing Cai | 香港理工大学健康科技与信息学系 |
| 通讯作者 | Tian Li | 香港理工大学健康科技与信息学系 |
文献概述
这篇文章通过回顾性分析,验证了虚拟对比增强磁共振成像(VCE-MRI)在鼻咽癌放疗中原发肿瘤勾画中的潜力,显示其有望替代传统基于钆的对比增强MRI。
研究目的是探索VCE-MRI在多中心数据集中勾画鼻咽癌(NPC)毛细血肿瘤区(GTV)的潜力。
研究使用了348名经过活组织检查证实的NPC患者的T1加权(T1w)、T2加权(T2w)、基于钆的对比增强MRI(CE-MRI)和计划CT扫描数据。通过一个多模态引导的协同神经网络(MMgSN-Net)训练模型,利用T1w和T2w MRI数据来合成VCE-MRI,并在60名患者中进行了独立评估。
临床评估包括:合成VCE-MRI的图像质量评估、VCE-MRI辅助靶区勾画以及基于VCE-MRI的轮廓在治疗计划中的有效性。
图像质量评估结果显示,VCE-MRI与实际CE-MRI在图像质量上高度相似,平均区分准确性为31.67%,表明VCE-MRI在显示解剖结构、纹理和对比度方面与真实CE-MRI相似。
此外,VCE-MRI在肿瘤侵袭风险区域的对比增强真实性方面取得了85.8%的准确度。
研究结论是,VCE-MRI在NPC患者的肿瘤勾画中具有很高的应用前景,有可能替代基于钆的CE-MRI。
重点关注
Figure 1 描述的是多模态引导的协同神经网络(MMgSN-Net)的架构,这种网络设计用于从T1加权(T1w)和T2加权(T2w)MRI图像中学习映射到对比增强MRI(CE-MRI)。
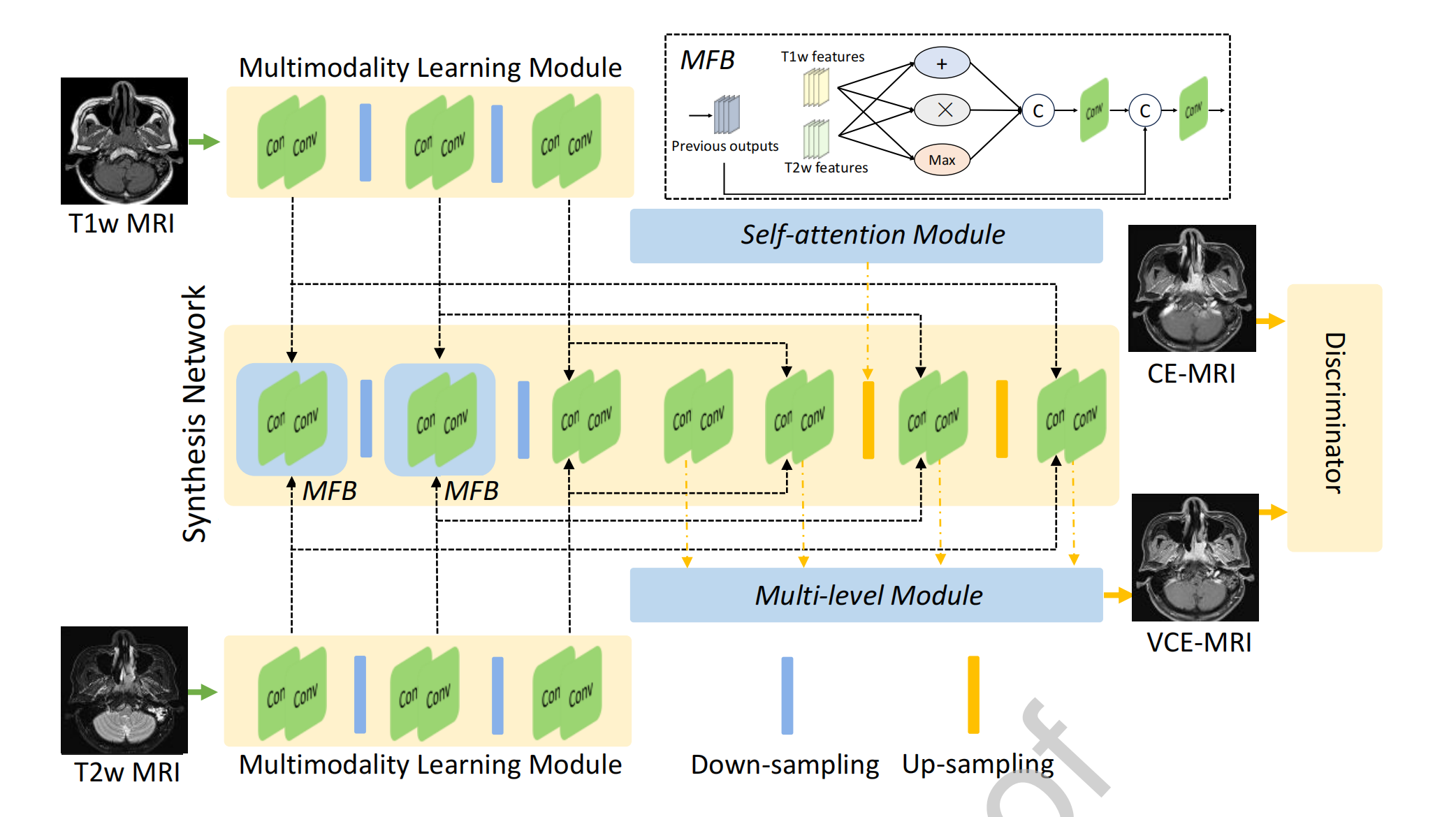
下面是对图1中网络架构的分析:
-
多模态学习模块(Multimodality Learning Module):
- 这个模块的目的是分别从T1w MRI和T2w MRI中提取互补信息。
- 这些特征随后通过混合融合块(Mixed Fusion Block, MFB)自动融合。
-
合成网络(Synthesis Network):
- 合成网络由两个混合融合块(MFB)、一个自注意力模块(Self-attention Module)和一个多级模块(Multi-level Module)组成。
- 这些模块共同工作以提高模型的对比增强性能。
-
鉴别器(Discriminator):
- 鉴别器使用PatchGAN架构,这是一种条件对抗网络,用于进一步增强合成性能。
-
混合融合块(MFB):
- MFB中包含的“+”表示像素级的加法操作,用于合并不同模态的信息。
- “×”表示像素级的乘法操作,可能用于强调特征间的相互作用。
- “Max”表示最大值操作,用于选择最有信息量的特征。
- “C”表示连接(concatenation),用于合并不同层级或模态的特征。
-
上采样和下采样(Up-sampling and Down-sampling):
- 这些操作通常用于调整特征图的空间分辨率,以匹配输入和输出数据的维度。
-
自注意力模块(Self-attention Module):
- 自注意力机制允许网络在处理图像时关注不同位置的相关特征,有助于捕捉长距离依赖关系。
-
多级模块(Multi-level Module):
- 这个模块可能涉及多尺度或多深度级别的特征融合,以增强模型对细节的捕捉能力。
整体来看,MMgSN-Net的设计考虑了从不同模态的MRI数据中提取和融合信息,并通过对抗性训练来提高合成图像的质量。
这种设计有助于生成高质量的VCE-MRI图像,这些图像在临床评估中显示出与传统的基于钆的CE-MRI相当的图像质量。
三、MMCA-Net:一种新型多模态跨注意力网络,用于鼻咽癌肿瘤分割

一作&通讯
| 角色 | 姓名 | 单位名称(中文) |
|---|---|---|
| 第一作者 | Wenjie Zhao | 中国科学院深圳先进技术研究院医学影像研究中心 |
| 第一作者(共同) | Zhenxing Huang | 中国科学院深圳先进技术研究院医学影像研究中心 |
| 第一作者(共同) | Si Tang | 中山大学肿瘤防治中心核医学科 |
| 通讯作者 | Zhanli Hu | 中国科学院深圳先进技术研究院医学影像研究中心 |
文献概述
这篇文章介绍了一种名为MMCA-Net的新型多模态跨注意力变换器网络,它基于全身PET/CT系统,用于鼻咽癌肿瘤的分割。
该网络结合了创新的多模态跨注意力变换器(MCA-Transformer)和改进的U-Net架构,以提高CT和PET数据之间的模态融合效果。
通过交叉注意力机制,MMCA-Net能够有效地改善肿瘤的边界识别、大规模肿瘤体积变化问题,并减少放射治疗中手动分割的工作量。
研究者们在中山大学肿瘤中心的样本和公开的HECKTOR数据集上测试了该方法,并通过五折交叉验证与十种算法进行比较。
MMCA-Net在所有四个评估指标上均取得了最佳性能,平均Dice相似系数分别达到了0.815和0.7944。此外,通过消融实验进一步证明了该方法在PET/CT融合用于鼻咽癌分割方面的优越性。
文章还讨论了MMCA-Net在多模态特征选择方面的潜力,并展示了其在其他医学成像领域的应用前景。
研究者们还进行了广泛的比较研究,证明了MMCA-Net与最新方法相比在鼻咽癌分割方面的优越性,并进行了消融研究来评估MCA-Transformer在PET/CT融合中的效果。
实验结果不仅突出了MMCA-Net在提高鼻咽癌分割精度方面的潜力,还为MCA-Transformer在其他医学成像领域的应用提供了有价值的见解。
重点关注
在文章中,图1提供了对提出的MMCA-Net架构和MCA-Transformer的概览。
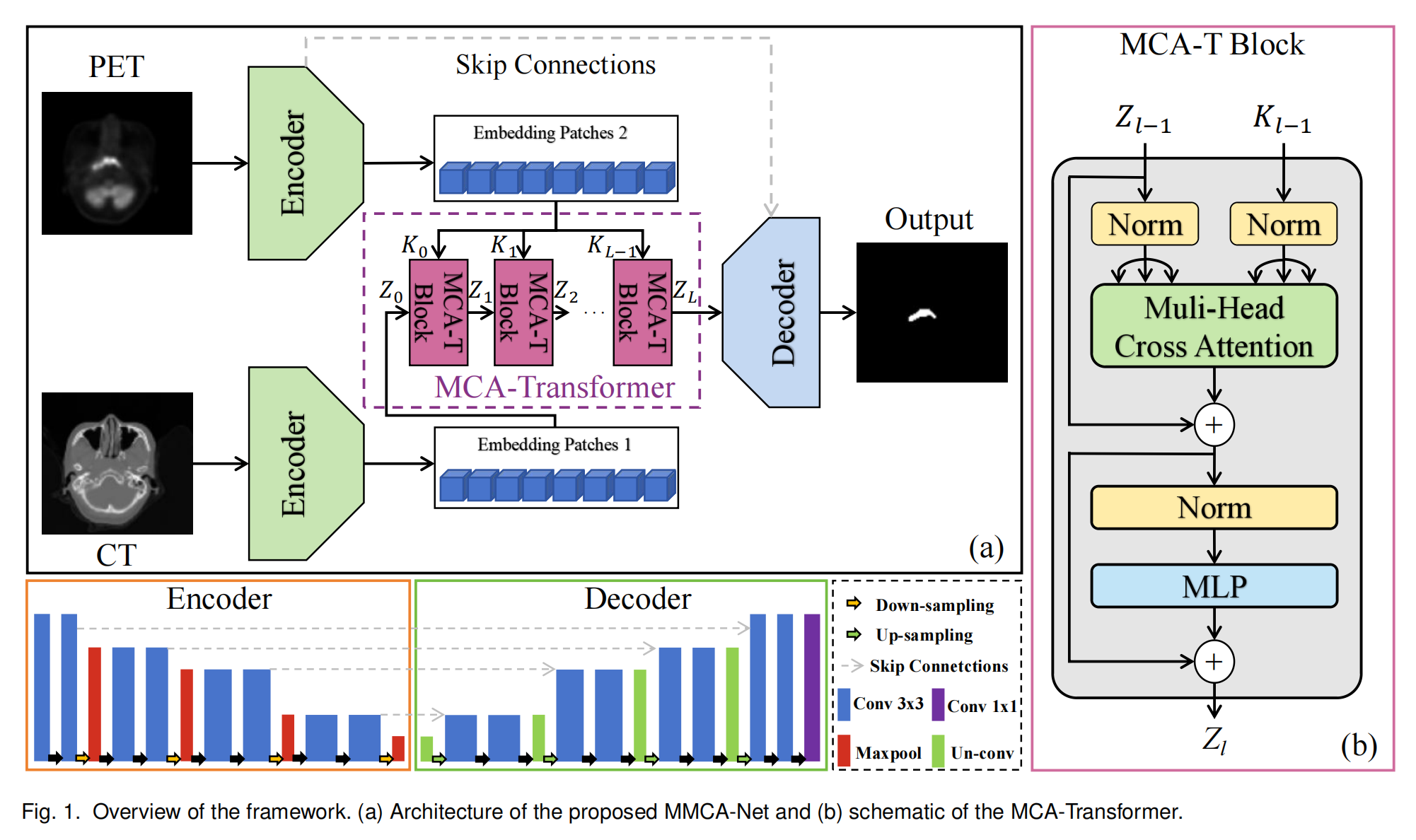
图1(a) MMCA-Net架构概览:
- MMCA-Net是基于改进的U-Net架构,专为PET/CT图像中的鼻咽癌肿瘤分割设计。
- 网络包含跳跃连接(Skip Connections),这些连接有助于在训练过程中保持梯度流动,从而提高分割精度。
- 网络由编码器(Encoder)、解码器(Decoder)和MCA-Transformer组成。编码器和解码器负责提取浅层特征,而MCA-Transformer则专注于深层特征的融合和多模态数据提取。
- 输入图像首先通过U-Net编码器进行独立编码,然后通过MCA-Transformer进行跨模态深度特征提取。
- 之后,U-Net解码器将浅层和深层特征整合起来,生成分割掩模。
图1(b) MCA-Transformer示意图:
- MCA-Transformer是MMCA-Net的核心组件,用于融合CT和PET模态信息。
- MCA-Transformer采用多头交叉注意力模块(MHCA),替代了传统变换器结构中的自注意力机制。
- MHCA模块通过计算CT和PET模态之间的交叉注意力向量,并通过平均池化层来选择由MHCA模块生成的注意力特征。
- 所选的注意力特征随后被送入多层感知器(MLP)层以提取相关信息,并通过残差连接来确保梯度下降。
- 在MCA-Transformer中,PET模态作为保真项,通过跨层堆栈保持主校正,而CT模态则被深入挖掘以提取更有效的特征。
整体而言,图1展示了MMCA-Net如何通过结合U-Net和MCA-Transformer的优势,实现对PET和CT图像中鼻咽癌肿瘤的精确分割。这种设计利用了跨注意力机制来加强模态间的信息融合,提高了分割性能。
四、PGMGVCE模型:一种新型的MRI虚拟对比增强技术

一作&通讯
| 角色 | 姓名 | 单位 |
|---|---|---|
| 第一作者 | Ka-Hei Cheng | 香港理工大学健康科技与信息学系 |
| 通讯作者 | Jing Cai | 香港理工大学健康科技与信息学系及深圳研究院 |
文献概述
这篇文章提出了一种新型的深度学习模型PGMGVCE,用于在不使用对比剂的情况下,通过模拟增强(Virtual Contrast Enhancement, VCE)MRI图像的纹理和形状,提高鼻咽癌(Nasopharyngeal Carcinoma, NPC)诊断的准确性和安全性。
该方法名为Pixelwise Gradient Model with GAN for Virtual Contrast Enhancement (PGMGVCE),它利用像素级梯度方法与生成对抗网络(Generative Adversarial Networks, GANs)结合来增强T1加权(T1-weighted, T1-w)和T2加权(T2-weighted, T2-w)MRI图像。这种方法模拟了基于钆的对比剂的效果,同时减少了与之相关的风险。
PGMGVCE模型在保持与现有模型相似的准确性的同时,在再现接近真实对比增强图像的纹理方面显示出优势。
研究通过多种措施进行了测试——评估相似性准确性:
- 平均绝对误差(Mean Absolute Error, MAE)
- 均方误差(Mean Square Error, MSE)
- 结构相似性指数(Structural Similarity Index, SSIM)
评估纹理
- 总均方变化均强度(Total Mean Square Variation Per Mean Intensity, TMSVPMI)
- 总绝对变化均强度(Total Absolute Variation Per Mean Intensity, TAVPMI)
- Tenengrad函数均强度(Tenengrad Function Per Mean Intensity, TFPMI)
- 方差函数均强度(Variance Function Per Mean Intensity, VFPMI)
此外,文章还探讨了模型的不同变体,包括超参数的微调、图像的归一化方法以及使用单一模态的测试,以寻找最优性能。
研究表明,PGMGVCE是一个创新且安全的方法,用于MRI中的VCE,展示了深度学习在增强医学成像方面的强大能力。该模型为更准确、无风险的医学成像诊断工具铺平了道路。
重点关注
Figure 1 描述的是深度学习模型PGMGVCE的架构。
PGMGVCE模型结合了像素级梯度方法和生成对抗网络(GAN)来实现虚拟对比增强。
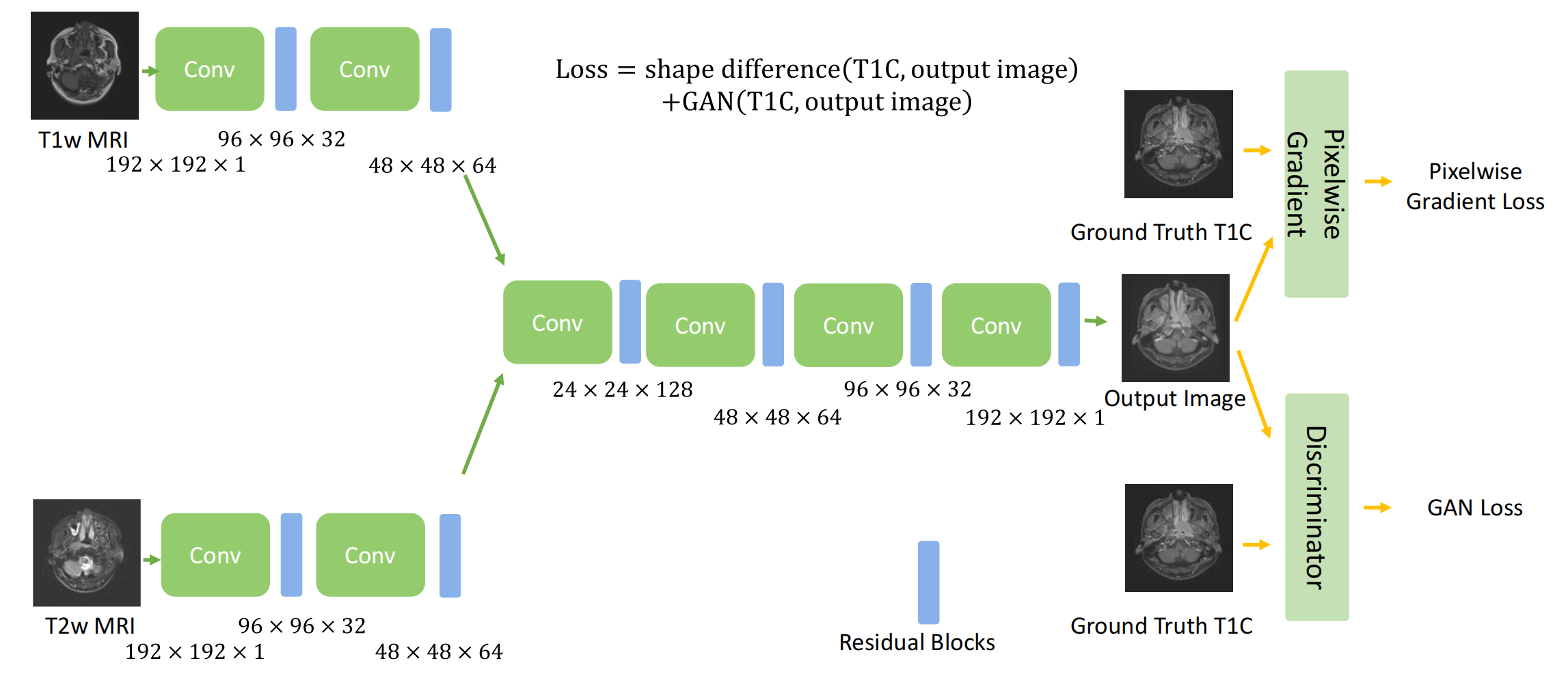
以下是对模型架构的分析:
-
输入层:模型接受T1加权(T1-w)和T2加权(T2-w)MRI图像作为输入。
-
特征提取:使用一系列卷积层进行初始特征提取。这些层在逐步降低图像尺寸的同时增加特征图的深度。
-
信息整合模块:设计了一个模块来有效整合T1-w和T2-w图像的信息。该模块从每种模态中提取和组合特征,利用它们的互补性质来增强对比度和细节。
-
动态可训练权重:在训练过程中动态调整的一组权重,根据融合目标优化每种模态的贡献。
-
特征融合层:独立于每种模态的卷积路径之后,有特征融合层智能地合并提取的特征,确保保留每种模态的独特特征。
-
判别器:采用基于局部评估的方法,分别评估图像不同区域的真实性,以提高融合图像的现实感和诊断质量。
-
损失函数:模型使用像素级梯度损失和GAN损失。像素级梯度损失用于确保输出图像与输入图像的形状一致性,而GAN损失则用于学习图像对比度,这里使用的是最小二乘生成对抗网络(LSGAN)。
-
优化器:模型使用Adam优化器进行训练,学习率为0.0002,beta1值为0.5。
-
训练过程:采用小批量训练,每个批次包含等量的T1-w和T2-w图像,并应用梯度惩罚以鼓励生成图像中的平滑梯度。共进行了14,000次迭代训练。
-
输出层:最终输出是经过对比增强的MRI图像。
图中的乘法符号表示该层的维度和通道数,这有助于理解模型在不同层级的深度和复杂性。
五、结合TabNet和Cox模型的鼻咽癌患者生存预测

一作&通讯
| 角色 | 姓名 | 单位 |
|---|---|---|
| 第一作者 | Huamei Qi | … |
| 通讯作者 | Lei Deng | 中南大学高性能计算中心 (Central South University High Performance Computing Center) |
文献概述
这篇文章提出了一个结合深度学习和传统生存分析的新型可解释模型Tab-Cox,用于提高鼻咽癌患者生存预测的准确性和可解释性。
Tab-Cox模型利用TabNet的顺序注意力机制提取可解释特征,提供了一种识别疾病风险因素的可解释方法。这使得模型在确保准确生存预测的同时,也让结果对患者和医生更易于理解。
通过在不同数据集上进行的实验,Tab-Cox模型展示了其准确性,并且在与经典Cox模型的比较中,展现了其在可解释性方面的优势。
研究的主要内容包括:
- 提出Tab-Cox模型,结合了深度学习与生存分析。
- 利用TabNet的注意力机制处理表格数据,增强模型的解释性。
- 在多个数据集上测试模型的有效性,并与其他生存模型比较。
- 进行了模型的可解释性分析,与传统Cox模型进行比较。
实验结果表明,Tab-Cox模型在所有测试数据集上都达到了最高或接近最高的准确性,并且在可解释性方面提供了优势,有助于医生识别难以用人工方法捕捉的风险因素。
此外,文章还讨论了模型在未来可能的改进方向,包括整合更多与疾病相关的医学知识以及将该方法应用于更多的医学场景。
重点关注
Fig. 1 展示了 Tab-Cox 模型的架构,这是一个深度生存分析模型,它结合了 TabNet 和 Cox 模型的特点。
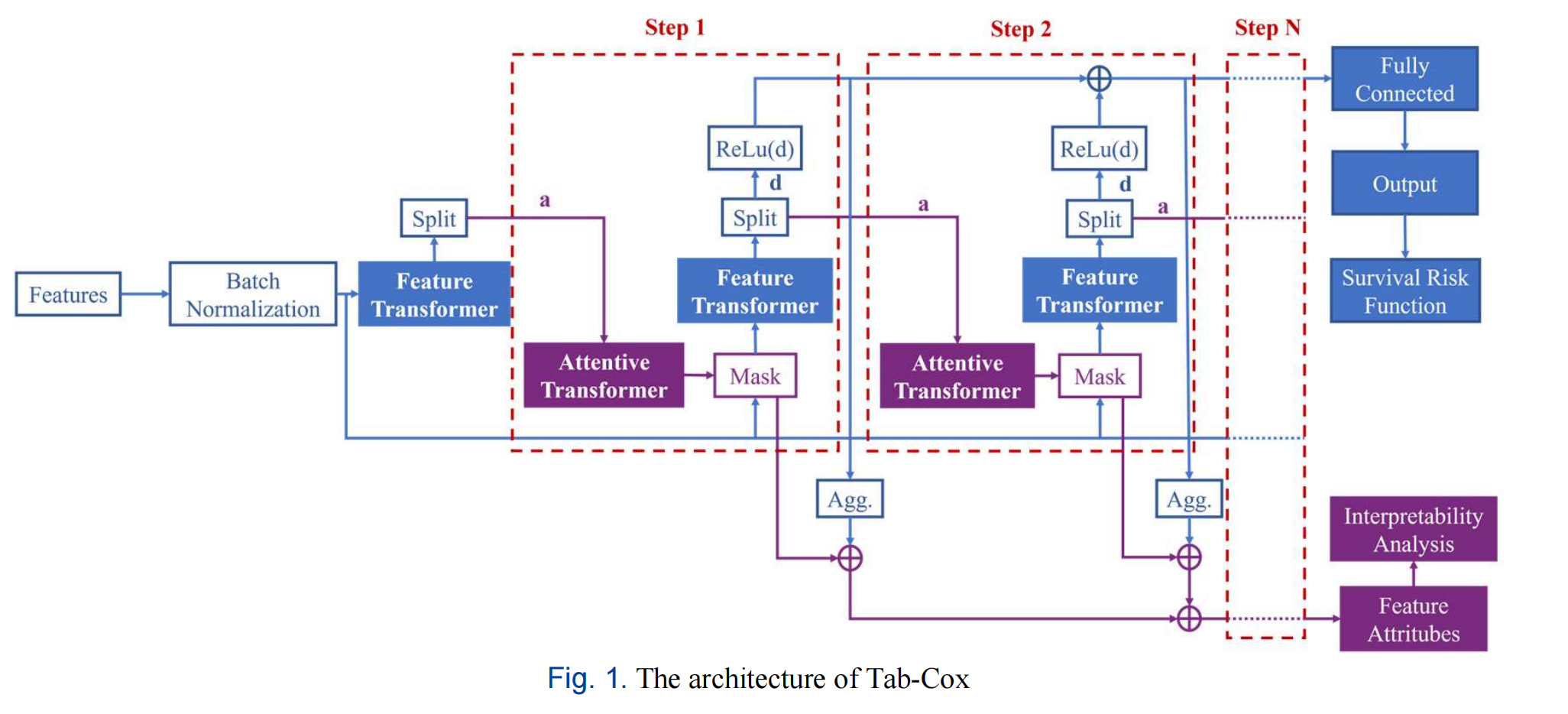
下面是对架构图的分析:
-
输入层:模型的输入是患者的医疗数据,这些数据通常是表格形式的,包含了多种特征,例如年龄、性别、临床指标等。
-
批量归一化层 (Batch Normalization, BN):输入数据首先通过批量归一化层,这有助于模型训练过程中的稳定性和加速收敛。
-
特征提取 (Feature Extraction):经过 BN 层的数据进入特征提取模块。Tab-Cox 模型使用 TabNet 的顺序注意力机制来识别每一步决策所需的特征。
-
多步决策 (Multi-step Decision):模型采用多步决策过程,每一步都会根据前一步的信息来决定使用哪些特征。这个过程通过注意力机制实现,使得模型可以逐步关注数据中最重要的部分。
-
注意力变换器 (Attentive Transformer) 和 特征变换器 (Feature Transformer):这是模型中的两个关键模块。Attentive Transformer 用于生成特征掩码,评估每个特征的重要性;而 Feature Transformer 则负责基于这些特征进行特征提取。
-
特征块 (Feature Block):Feature Transformer 的核心是特征块,它由全连接层 (Fully Connected Layer, FC)、批量归一化层 (BN) 和门控线性单元 (Gated Linear Unit, GLU) 组成,用于捕捉长期依赖信息。
-
生存风险损失函数 (Survival Risk Loss):模型使用特定的损失函数来评估生存风险,这是基于 Cox 模型的非线性扩展。
-
解释性风险因素评估 (Explainable Risk Factor Evaluation):Tab-Cox 模型能够提供对每个风险因素重要性的评估,这与传统的 Cox 模型提供的全局重要性不同,Tab-Cox 可以提供更细粒度的分析。
-
输出层:最终,模型输出生存风险的预测结果,这可以用于评估患者的预后。
整个架构设计考虑了模型的解释性和预测准确性,特别是在处理表格医疗数据时。Tab-Cox 模型通过整合深度学习的优势和传统生存分析的稳健性,旨在提供一种新的、更有效的患者生存分析工具。
六、WS-T2T-ViT:一种新型的鼻咽癌病理图像分类方法

一作&通讯
| 角色 | 姓名 | 单位 |
|---|---|---|
| 第一作者 | Ziwei Hu | 福州大学物理与信息工程学院 |
| 通讯作者 | Tong Tong | 福建医科大学附属福建省肿瘤医院 |
文献概述
这篇文章是关于一种新的基于Transformer的弱监督框架(WS-T2T-ViT),用于对鼻咽癌(NPC)的全切片图像(WSIs)进行分类。
这项研究的动机是传统的、完全监督的NPC诊断算法需要在全切片图像上手动划分感兴趣的区域,这不仅耗时而且可能存在偏差。
该框架只需要切片级别的标签,通过多分辨率金字塔、T2T-ViT模块和多尺度注意力模块来提高分类性能。
实验结果表明,该框架在NPC数据集上的分类性能达到了0.989的AUC(接收者操作特征曲线下面积),并且在CAMELYON16数据集上的实验结果展示了该框架在WSI级别分类中的鲁棒性和泛化能力。
研究使用了802名患者的NPC数据集和CAMELYON16数据集进行广泛的实验。提出的WS-T2T-ViT框架包括多分辨率金字塔机制,模仿病理学家从粗糙到精细的分析过程,学习不同放大级别的特征;T2T模块捕获局部和全局特征以克服缺乏全局信息的问题;多尺度注意力模块通过权衡不同粒度级别的贡献来提高分类性能。
文章还进行了消融研究,探讨了多分辨率金字塔、T2T模块和多尺度注意力模块对框架性能的影响,并讨论了WS-T2T-ViT在NPC分类中的有效性。
重点关注
Fig. 1 展示了所提出的弱监督框架(WS-T2T-ViT)的架构图,该框架由两个子网络组成,分别对应 ×40 和 ×20 的放大倍数。
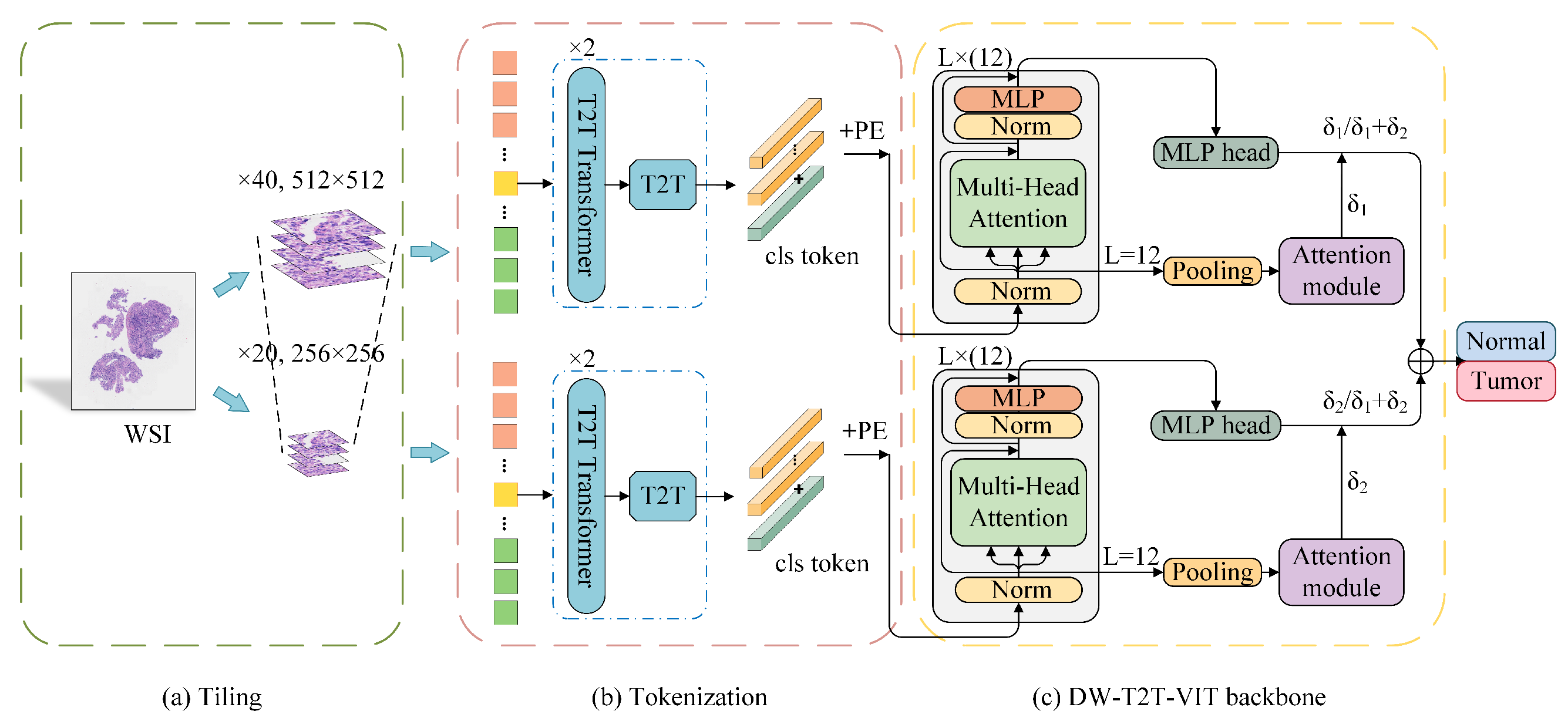
以下是对框架的分析:
-
WSI 分割:全切片图像(Whole Slide Image, WSI)首先被分割成小块的平铺图像(patch images)。
-
T2T 模块:这些平铺图像随后被送入 Tokens-to-Token Vision Transformer(T2T-ViT)模块,该模块将图像转换成一系列的“tokens”。Tokens 是 Transformer 模型中用于处理图像的基本单元。
-
WS-T2T-ViT 骨干网络:转换后的固定长度的 tokens 被输入到 WS-T2T-ViT 的骨干网络中。这个网络利用这些 tokens 来提取特征,并进行初步的分类判断。
-
多尺度注意力模块:该模块接收来自不同放大倍数子网络的特征,并计算每个子网络对最终分类决策的贡献权重。这个权重分配过程考虑了不同尺度的信息,以提高分类的准确性。
-
分类输出:最后,多尺度注意力模块为每个子网络分配的概率权重与该子网络的分类结果相结合,以产生最终的分类输出。
整体来看,这个框架通过结合不同分辨率的图像信息和 Transformer 模型的强大特征提取能力,实现了对鼻咽癌组织的弱监督分类。
这种设计模仿了病理学家在诊断过程中从宏观到微观逐步分析的过程,通过多尺度分析提高了模型对不同区域和特征的捕捉能力。
















 1401
1401

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









