







小罗碎碎念
最近星球内的提问很活跃,几乎每天都有,部分是和课题设计/项目复现有关,部分是和国自然标书获取相关。
今天想和大家分享一个观点,用好手里的资料,比去找理论上更好的资料更有意义。
我这篇推送就和大家演示一下,如何深度挖掘一篇结题的报告——探索申请者发表了什么文献,有没有公开的算法模型……
例如下面这个项目就提供了四个开源的算法,今天的推送就选择第一个进行分析:
- https://github.com/panxipeng/nuclear_segandcls
- https://github.com/panxipeng/HE-WSI-lungTILs
- https://github.com/linjiatai/PDBL
- https://github.com/ChuHan89/WSSS-Tissue
接下来我将对这个项目展开分析——基于深度学习的多中心HE染色乳腺病理图像细胞核分割与识别方法研究,从论文解读,再到代码解读,最后到项目的复现,全流程呈现给大家。
通过这篇推送,我将和大家补充两个内容:
(1)如何在公开数据集的基础上,构建符合作者算法格式的数据集
(2)如何不受网速限制的下载公开数据集
此外,如果你的设备是A100,那你可能会在最后一步卡住,无法得到最终结果,因为该模型采用pytorch版本不匹配A100的算力(A100算力过强,低于A100的应该都没问题)。

由于我没有除了A100外的设备,所以最后的结果图就用原作者的了。
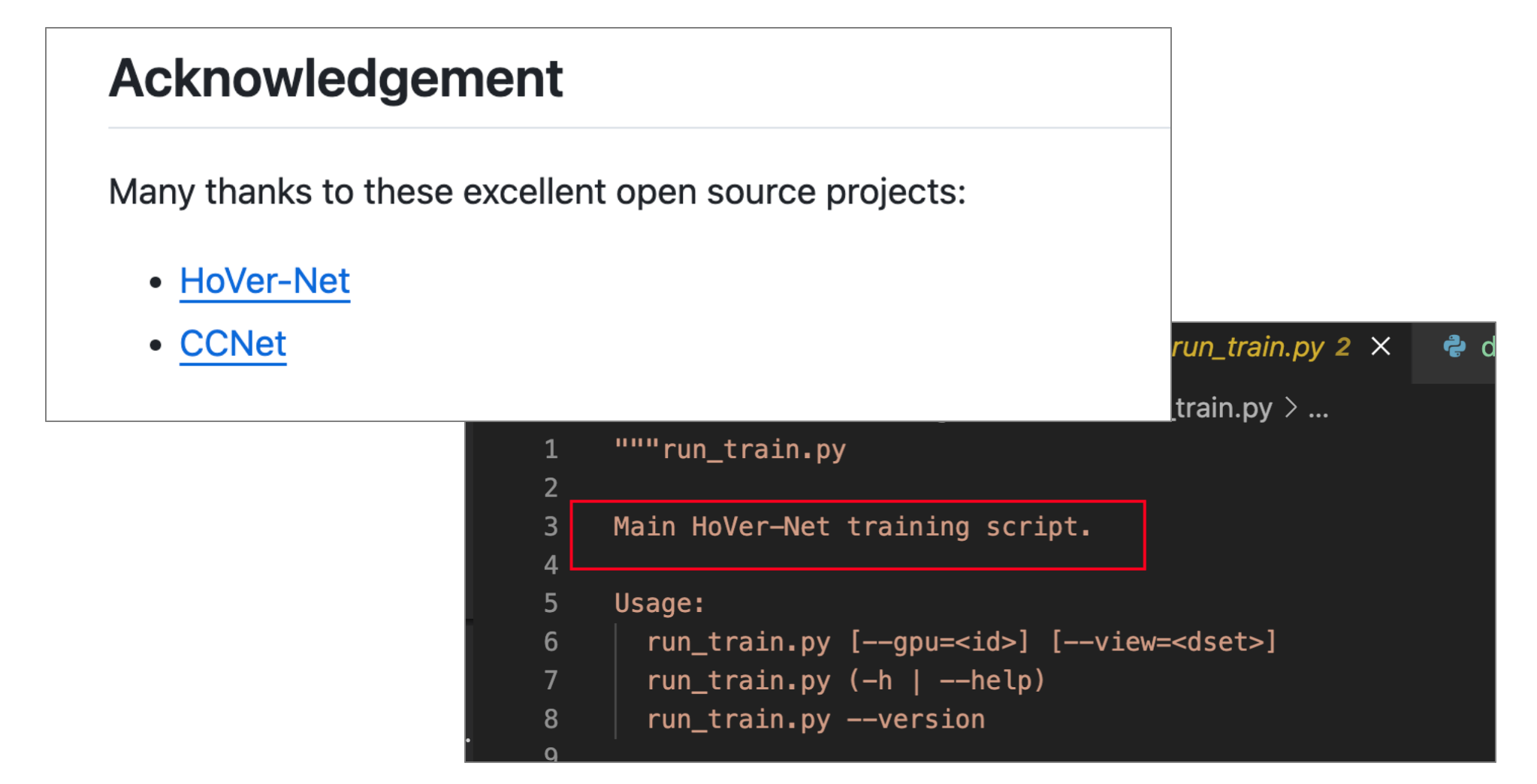
再说句题外话,我在分析这个项目的代码时,觉得架构和Hover-Net超级像,数据处理的方式也很像,不过作者也很实在,直接致谢,并且在代码中指明,所以这也是一个学习如何迁移代码的机会!
知识星球
如需获取推文中提及的各种资料,欢迎加入我的知识星球!
星球用户可以直接获取本篇推送的pdf版本,并且可以在星球中向我提问!
一、论文解读
“SMILE: Cost-sensitive multi-task learning for nuclear segmentation and classification with imbalanced annotations”提出了一种基于成本敏感多任务学习的细胞核分割与分类框架SMILE,有效解决数据不平衡和细胞核形态多样带来的问题,在相关数据集上取得优异性能。

- 研究背景:计算病理学中,全切片图像细胞核分割与分类意义重大,但面临数据不平衡和细胞核形态多样的挑战。少数细胞类别易被多数类别主导,不同类型细胞核大小、形状和纹理差异大,现有方法未充分解决这些问题。
- 相关工作:介绍细胞核语义和实例分割、细胞核分类的已有方法,指出多数研究未考虑细胞类型不平衡问题;阐述成本敏感学习、多任务学习在计算病理学的应用及注意力机制在深度学习中的作用。
- 方法
- 模型架构:采用三分支U型网络,包含编码器、多任务相关注意力(MTCA)、解码器和粗细标记控制分水岭(CFMW)模块,分别进行细胞核语义分割、实例化和分类任务。
- 关键模块:MTCA基于十字交叉注意力构建,减少计算量并融合任务特征;CFMW通过两步标记控制分水岭算法,改善细胞核分割效果;引入成本敏感损失和Alpha-dice损失处理数据不平衡问题。
- 实验
- 数据集:使用MoNuSAC 2020和CoNSeP数据集,二者均存在细胞类型数量不平衡现象。
- 实验设置:基于Pytorch框架,使用Adam优化器,设置初始学习率,进行数据增强,划分训练集和测试集。
- 评估指标:采用Dice、AJI、DQ、SQ、PQ、wPQ等指标评估细胞核分割,用(F_{d})、(F_{c})系列指标评估细胞核检测和分类。
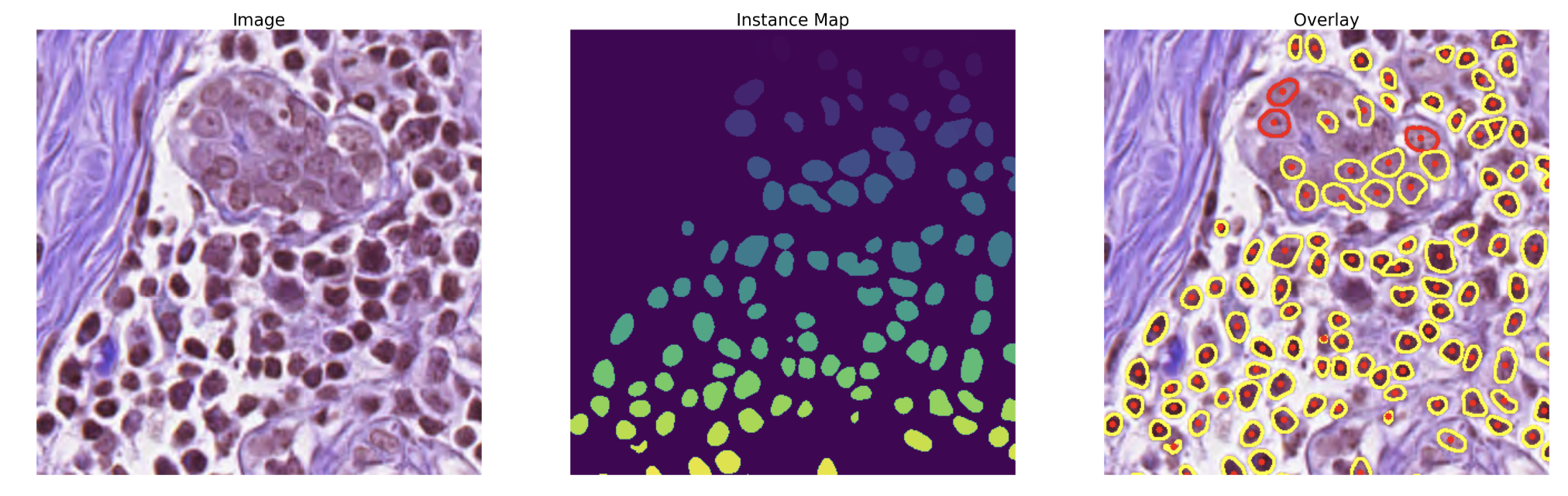
- 结果与分析:与经典模型和同类先进方法相比,所提方法在核分割和分类任务上性能更优;消融实验验证了各模块和损失函数的有效性;交叉验证表明方法性能稳定;针对不完美注释的微调策略可提升模型性能。
- 结论:提出的三分支U型深度学习框架,通过多任务特征融合、成本敏感学习策略和后处理方法,在细胞核分割和分类任务上表现出色,为病理图像分析提供有效支持。
二、SMILE 解读
2-1:项目概述
SMILE 是一个基于 PyTorch 实现的成本敏感多任务学习模型,用于解决核实例分割与分类中的标注不平衡问题。
- 核心功能: 支持在 CoNSeP 和 MoNuSAC 数据集上进行核分割与分类。
- 模型权重: 提供预训练权重(通过 Google Drive 链接获取)。
- 关键特性: 多任务学习框架、动态损失权重调整、兼容 QuPath 的输出格式。
2-2:代码仓库结构
| 目录名称 | 功能描述 | 关键文件示例 |
|---|---|---|
| dataloader/ | 数据加载与增强模块 | loader.py(数据流定义) |
- 定义Dataset类与数据预处理流程 | augmentations.py(增强策略) | |
| - 包含图像增强(旋转、翻转、颜色变换等)实现 | ||
| docs/ | 文档资源 | architecture.png(模型结构图) |
| - 存放项目示意图、模型结构图等说明性文件 | dataset_stats.md(数据统计) | |
| metrics/ | 评估指标计算 | dice_score.py(Dice系数计算) |
| - 实现分割精度(IoU、Dice)、分类准确率等指标 | confusion_matrix.py(分类评估) | |
| misc/ | 通用工具函数 | logger.py(日志记录) |
| - 提供日志记录、可视化、文件操作等辅助工具 | visualize.py(结果可视化) | |
| models/ | 模型定义与训练配置 | unet.py(U-Net模型) |
| - 包含模型架构代码(如U-Net、ResNet等) | train_config.yaml(超参数) | |
| - 存储训练超参数配置(学习率、批次大小等) | ||
| run_utils/ | 训练流程管理 | trainer.py(训练循环) |
| - 定义训练/验证循环逻辑 | callbacks.py(早停、保存检查点) | |
| - 实现回调函数(模型保存、学习率调整等) |
核心脚本说明
| 脚本名称 | 功能描述 | 使用示例 |
|---|---|---|
| config.py | 全局配置文件 | 修改BATCH_SIZE或NUM_EPOCHS |
| - 定义数据路径、超参数、模型类型等可配置项 | ||
| dataset.py | 数据集接口定义 | 自定义数据集时继承BaseDataset类 |
- 实现__getitem__方法返回图像与标签对 | ||
| extract_patches.py | 图像分块预处理 | python extract_patches.py --size 256 |
| - 将大尺寸病理图像切割为小patch以适应模型输入 | ||
| run_train.py | 模型训练入口 | python run_train.py --model unet |
| - 初始化模型、加载数据、启动训练流程 | ||
| run_infer.py | 模型推理入口 | python run_infer.py --checkpoint best_model.pth |
| - 加载训练好的模型权重进行预测,生成分割掩膜或分类结果 |
2-3:快速开始
1. 环境配置
注意,这一部分需要先执行,后续项目复现时,不再提醒执行。
conda env create -f environment.yml # 创建虚拟环境
conda activate smile # 激活环境
pip install torch==1.7.1 torchvision==0.8.2 # 安装指定版本 PyTorch(需 CUDA 11.0 支持)
2. 数据准备
训练数据格式
-
实例分割: 图像块存储为 4 维 numpy 数组
[RGB, inst],inst为实例标注(0 为背景,其他为实例 ID)。 -
分类任务: 图像块存储为 5 维 numpy 数组
[RGB, inst, type],type为类别标注(0 为背景,1-K 为类别)。 -
预处理: 使用
extract_patches.py从原图提取图像块。
3. 配置文件修改
config.py: 设置数据路径和模型保存路径。models/smile/opt.py: 调整超参数(如学习率、训练轮数)。
2-4:训练与推理
注意,这一部分是介绍项目架构,项目复现在后面才会介绍。
训练命令
python run_train.py --gpu='0,1' # 使用 GPU 0 和 1 进行训练
推理命令
python run_infer.py \
--gpu=0 \
--model_path=/data2/data2_mailab015/reproject/2025/02/02-23/nuclear_segandcls/cosep_checkpoint.tar \
--input_dir=/data2/data2_mailab015/reproject/2025/02/02-23/nuclear_segandcls/dataset/Train/Images \
--output_dir=/result \
--nr_types=5 # 类别数(根据数据集调整)
输出格式
- JSON 文件: 包含每个核的边界框、质心、轮廓、类别概率和预测类别。
- MAT 文件: 存储实例分割结果(
inst_map和inst_type)。 - PNG 叠加图: 在原图上绘制核边界。
三、CoNSeP 数据集
此时,我们已经在上一节完成了smile项目的环境安装和依赖项安装,现在我们开始正式复现这个项目。
巧妇难为无米之炊,复现一个项目最重要的,就是要先准备好数据。
在这一节,我将和大家介绍一种非常便捷的数据集下载方法,不仅不需要🪜,还可以无网速限制!
唯一有点难度的就是,我们不再是通过网页点击下载按钮,而是需要通过在终端输入代码实现!不过,小罗都已经给大家写好了详细的步骤,跟着我走就可以一比一复现!
3-1:数据集简介
1. 数据集背景
- 全称:Colorectal Nuclear Segmentation and Phenotypes
- 领域:医学图像分析(病理学)
- 任务目标:结直肠癌组织切片中的细胞核 实例分割 与 表型分类
- 提出时间:2019年(MICCAI会议论文 《NuCLS: A scalable crowdsourcing, deep learning approach and dataset for nucleus classification, localization and segmentation》)
- 核心意义:解决细胞核密集分布、形态多样性和类别不平衡问题,推动病理图像自动分析技术发展。
2. 数据内容
数据来源
- 样本类型:结直肠癌(CRC)H&E染色组织切片
- 采集设备:全切片扫描仪(40倍光学放大)
- 图像分辨率:0.25 µm/pixel → 下采样至 0.5 µm/pixel(平衡细节与计算成本)
数据规模
| 类别 | 数量 |
|---|---|
| 全视野图像(WSI) | 41张 |
| 局部图像块 | 27,907个 |
| 标注细胞核 | 24,319个 |
标注信息
实例级标注(每个细胞核)
- 精确轮廓:多边形顶点坐标(支持像素级分割)
- 表型类别:7种细胞类型(见下表)
- 位置坐标:中心点 (x, y)
| 类别ID | 细胞类型 | 描述 | 样本占比 |
|---|---|---|---|
| 1 | 上皮细胞 | 正常/癌变上皮组织 | 34.7% |
| 2 | 淋巴细胞 | 免疫细胞 | 28.1% |
| 3 | 浆细胞 | 分泌抗体的免疫细胞 | 4.9% |
| 4 | 中性粒细胞 | 急性炎症反应细胞 | 1.2% |
| 5 | 嗜酸性粒细胞 | 过敏/寄生虫反应细胞 | 0.6% |
| 6 | 成纤维细胞 | 结缔组织基质细胞 | 29.1% |
| 7 | 其他 | 未分类/模糊边界细胞 | 1.4% |
3-2:数据集下载
1. 安装与升级
完整版内容请前往公众号付费阅读,或者订阅我的星球。
结束语
本期推文的内容就到这里啦,如果需要获取医学AI领域的最新发展动态,请关注小罗的推送!如需进一步深入研究,获取相关资料,欢迎加入我的知识星球!



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









