







小罗碎碎念
在医学AI领域,组织病理学报告自动生成意义重大。
目前,病理学家手动撰写报告耗时费力且易出错,而深度学习技术虽发展迅速,但在全切片图像(WSI)报告生成方面仍面临诸多挑战,如缺乏基准数据集、图像尺寸大导致编码困难以及跨模态交互复杂等。
过往研究中,相关方法存在局限性,现有WSI分析的MIL方法多聚焦于预测任务,图像字幕和放射学报告生成方法难以直接用于WSI数据。为解决这些问题,下面这篇文章提出了HistGen框架。

首先,构建了约7800对的基准WSI - 报告数据集,确保数据的高质量和可用性。其次,设计了局部 - 全局分层编码器(LGH)和跨模态上下文模块(CMC)。LGH能从区域到全切片的视角有效聚合视觉特征,捕捉不同粒度信息;CMC则促进视觉编码和文本解码间的交互,利用跨模态信息提升性能。此外,还预训练了通用的MIL特征提取器,增强特征编码能力。
实验结果充分验证了HistGen框架的优势。在WSI报告生成任务上,它远超现有先进模型;在癌症亚型分类和生存分析任务中,同样展现出卓越的性能和强大的迁移学习能力。
这一成果为医学AI中组织病理学报告生成提供了新的有效解决方案,也为后续在其他医学领域的拓展研究奠定了坚实基础,有望推动医学AI在临床应用中的进一步发展。
交流群
欢迎大家加入【医学AI】交流群,本群设立的初衷是提供交流平台,方便大家后续课题合作。
目前小罗全平台关注量52,000+,交流群总成员1100+,大部分来自国内外顶尖院校/医院,期待您的加入!!
由于近期入群推销人员较多,已开启入群验证,扫码添加我的联系方式,备注姓名-单位-科室/专业,即可邀您入群。
知识星球
如需获取推文中提及的各种资料,欢迎加入我的知识星球!
已订阅星球用户无需二次付费,可以直接获取本篇推送的pdf版本,并且可以在星球中向我提问!
一、文献概述
“HistGen: Histopathology Report Generation via Local-Global Feature Encoding and Cross-modal Context Interaction”提出了HistGen框架用于生成组织病理学报告,通过构建数据集、设计模块和预训练模型,实验证明其在报告生成及相关任务上性能优异,为该领域研究奠定基础。
- 研究背景与挑战:组织病理学在癌症诊断中至关重要,但病理学家撰写报告的工作繁琐且易出错,自动生成报告意义重大。与放射学报告生成不同,全切片图像(WSI)报告生成面临缺乏基准数据集、图像像素巨大、跨模态交互困难以及多实例学习(MIL)方法存在瓶颈等挑战。
- 相关工作:MIL框架常用于WSI分析,但多聚焦于WSI级别的预测任务,对报告生成的研究不足。图像字幕和放射学报告生成方法因WSI的巨大尺寸难以直接应用,现有WSI报告生成工作也存在忽视视觉与文本模态联系的问题。
- 方法
- 数据集构建:基于TCGA平台数据,经报告下载、文本提取、GPT-4清洗和病例ID匹配,构建了包含7753对WSI - 报告的数据集。
- HistGen框架:包括局部 - 全局分层编码器(LGH)、跨模态上下文模块(CMC)和解码器模块。LGH从局部到全局处理视觉特征,CMC促进视觉与文本模态交互,利用交叉注意力选择关键补丁,模型训练采用交叉熵损失和Adam优化器。
- 预训练特征提取器:用超过55,000张WSI和DINOv2策略预训练ViT - L模型,为MIL特征编码提供有力支持。
- 实验
- 设置:报告生成任务使用自建数据集和NLG指标评估;癌症亚型分类在三个外部数据集上用准确率和AUC评估;生存分析在六个TCGA数据集上用一致性指数(c - Index)评估,模型采用特定参数设置和训练策略。
- 结果:在WSI报告生成方面,预训练的DINOv2 ViT - L远超其他预训练方法,HistGen框架大幅优于现有方法;在癌症亚型分类和生存分析任务中,HistGen也表现出色,证明其强大的迁移学习能力。
- 结论:HistGen框架有效提升了组织病理学报告生成能力,实验验证了其优越性和迁移学习能力。未来研究将拓展到放射学和眼科学等领域,在统一框架下处理不同领域的报告生成问题。
二、重点关注
2-1:HistGen框架
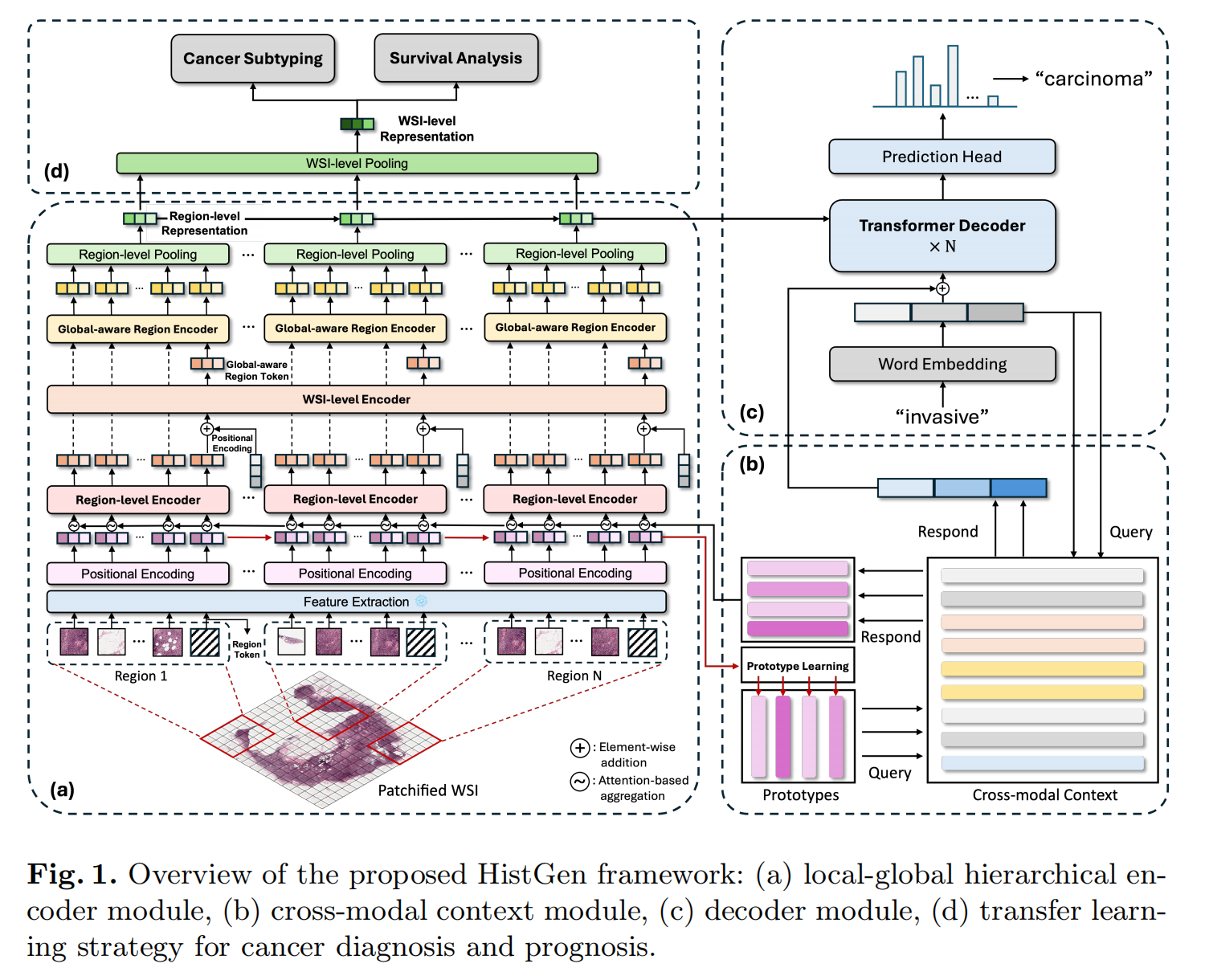
- 局部 - 全局分层编码器模块(a部分):对全切片图像(WSI)进行分块(Patchified WSI),经过特征提取、位置编码后,由区域级编码器处理,再通过WSI级编码器聚合信息,还包括全局感知区域编码器和区域级池化,最终得到区域级和WSI级表示,用于癌症诊断和预后的迁移学习。
- 跨模态上下文模块(b部分):通过原型学习(Prototype Learning),基于查询(Query)和响应(Respond)机制,在视觉和文本模态间建立联系,生成跨模态上下文(Cross-modal Context)。
- 解码器模块(c部分):接收跨模态上下文信息,经过词嵌入(Word Embedding)后,由多个Transformer解码器层处理,最终通过预测头(Prediction Head)生成如“carcinoma”(癌)、“invasive”(浸润性)等文本信息。
- 癌症诊断和预后的迁移学习策略(d部分):利用WSI级表示,应用于癌症亚型分类(Cancer Subtyping)和生存分析(Survival Analysis)任务。
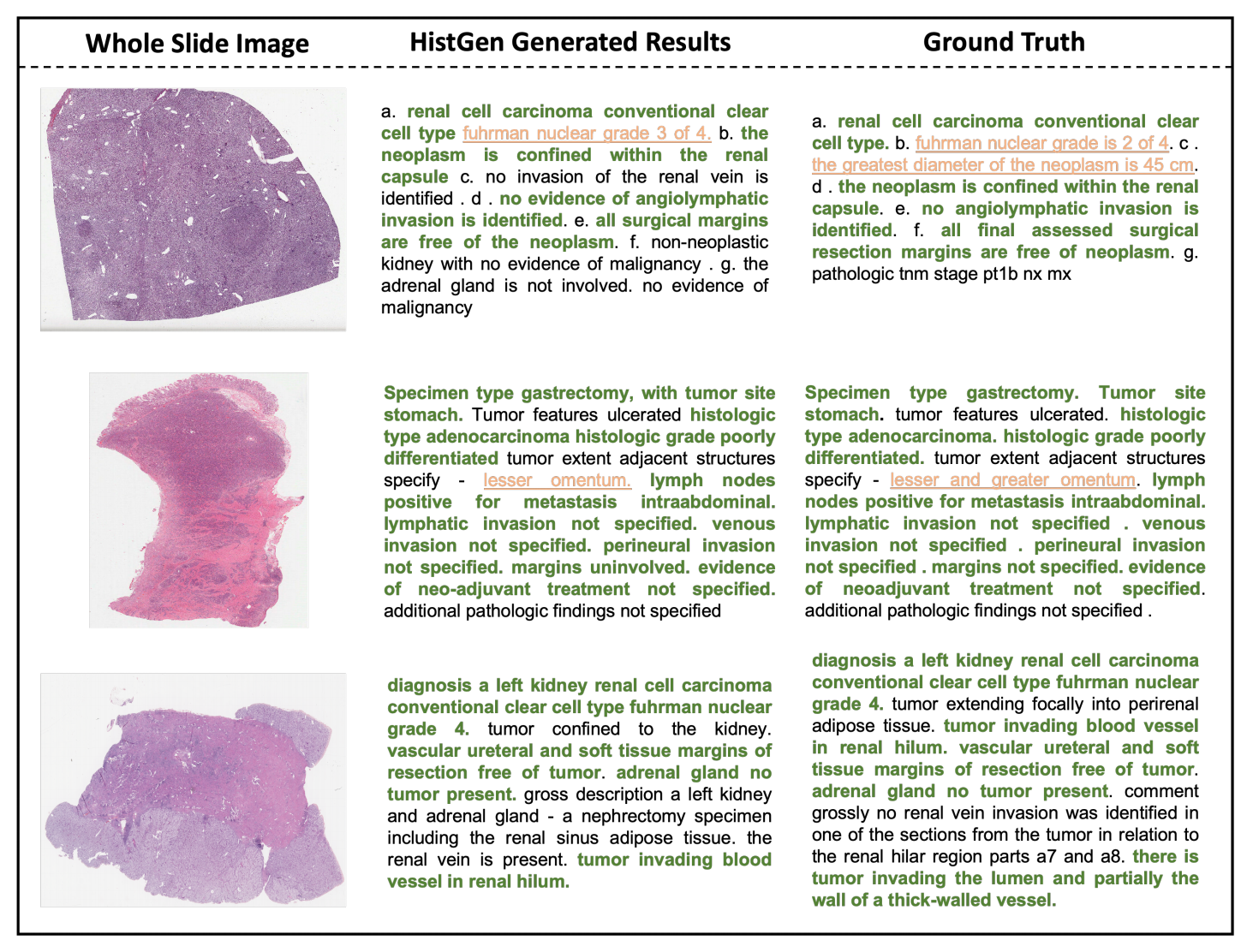
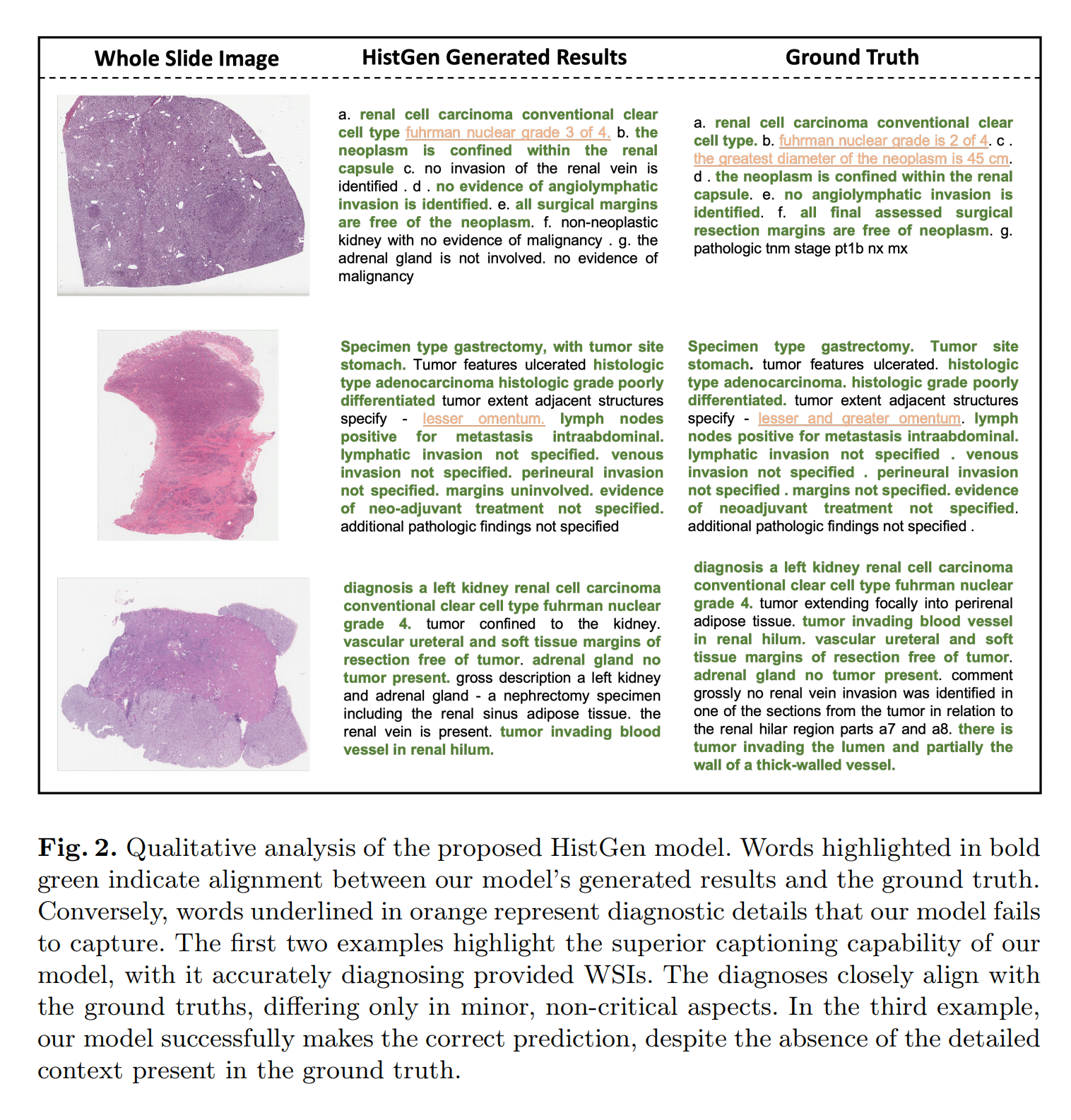
2-2:HistGen模型的定性分析
这张图展示了全切片图像(Whole Slide Image)、HistGen生成的结果(HistGen Generated Results)以及真实情况(Ground Truth):
-
第一组例子中,图像对应的是肾脏相关切片。HistGen生成结果准确诊断出“renal cell carcinoma conventional clear cell type”(肾细胞癌普通透明细胞型),与真实情况在主要诊断上相符,只是在核分级等细节上有差异。
-
第二组例子是胃部手术标本图像。HistGen生成结果和真实情况大部分一致, 但在一些具体细节描述上有缺失。
-
第三组例子是左肾相关切片图像。HistGen生成结果成功做出了正确的主要诊断,尽管相比真实情况,缺少一些详细背景描述。
图中加粗绿色文字表示模型生成结果与真实情况一致的部分,橙色下划线文字表示模型未能捕捉到的诊断细节。分析表明,HistGen模型在主要诊断方面表现出色,但在捕捉详细诊断信息上还有提升空间 。
2-3:用于DINOv2 ViT-L特征提取器预训练的全切片图像(WSI)的分布情况
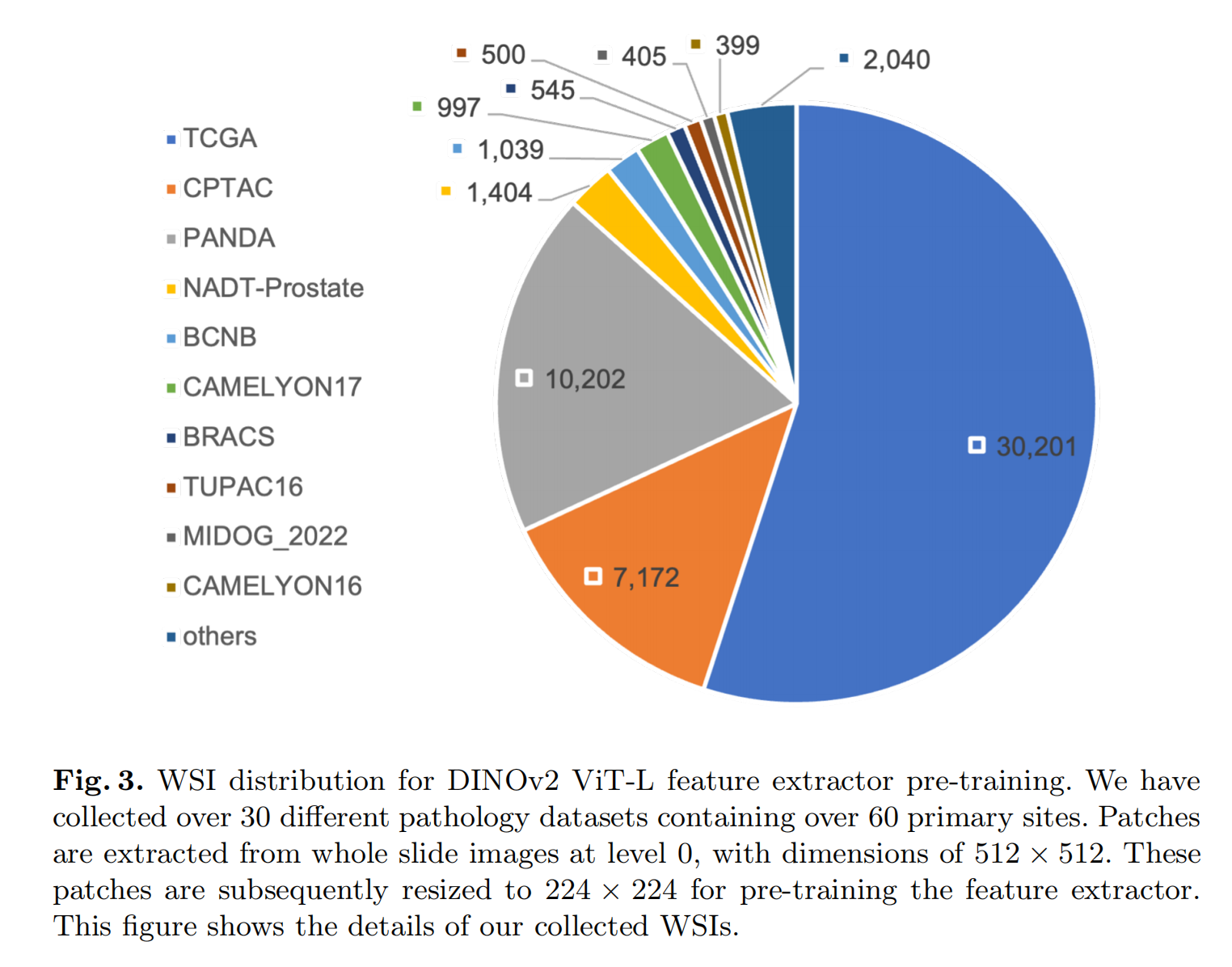
- TCGA数据集的WSI数量最多,为30,201 张。
- 其次是PANDA数据集,有10,202张。
- CPTAC数据集有7,172 张。
- 其他数据集如NADT-Prostate有1,404张,BCNB有1,039张等,另外还有一些数据集汇总为“others”,其中不同数量的WSI分别有2,040张、545张等 。
文中提到,研究者收集了超30个不同的病理数据集,涵盖超60个原发部位。从全切片图像中提取尺寸为512×512的图像块,然后将其调整为224×224用于特征提取器的预训练。
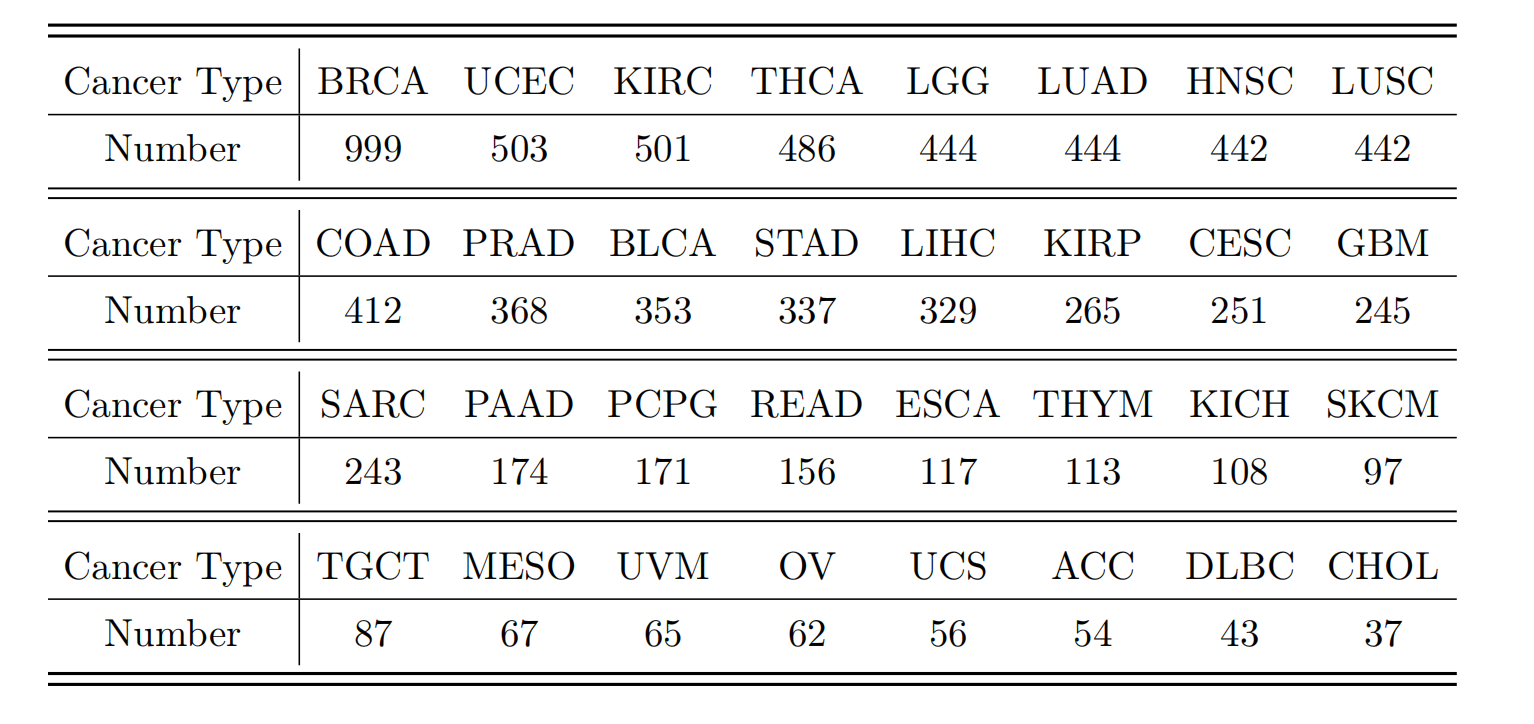
2-4:经过整理的全切片图像-报告(WSI-Report)数据集的构成
三、项目复现流程
3-1:环境配置
git clone https://github.com/dddavid4real/HistGen.git
cd HistGen
conda env create -f requirements.yml # 创建名为histgen的虚拟环境
conda activate histgen # 激活环境
3-2:数据集准备
更多内容请见公众号/知识星球。
结束语
本期推文的内容就到这里啦,如果需要获取医学AI领域的最新发展动态,请关注小罗的推送!如需进一步深入研究,获取相关资料,欢迎加入我的知识星球!



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









