







小罗碎碎念
这篇文章聚焦高级别浆液性卵巢癌(HGSOC)的多模态数据整合与风险分层,针对当前临床预后模型对患者结局异质性解释不足的问题,探索了基于机器学习的跨模态信息融合方法。

研究收集444例患者的治疗前CT影像、H&E病理切片、基因组测序及临床数据,分别构建放射组学(大网膜纹理特征如GLCM自相关)、组织病理学(肿瘤核平均面积、基质长轴长度)和临床基因组(HRD状态)单模态模型,并通过晚期融合策略整合为多模态模型。
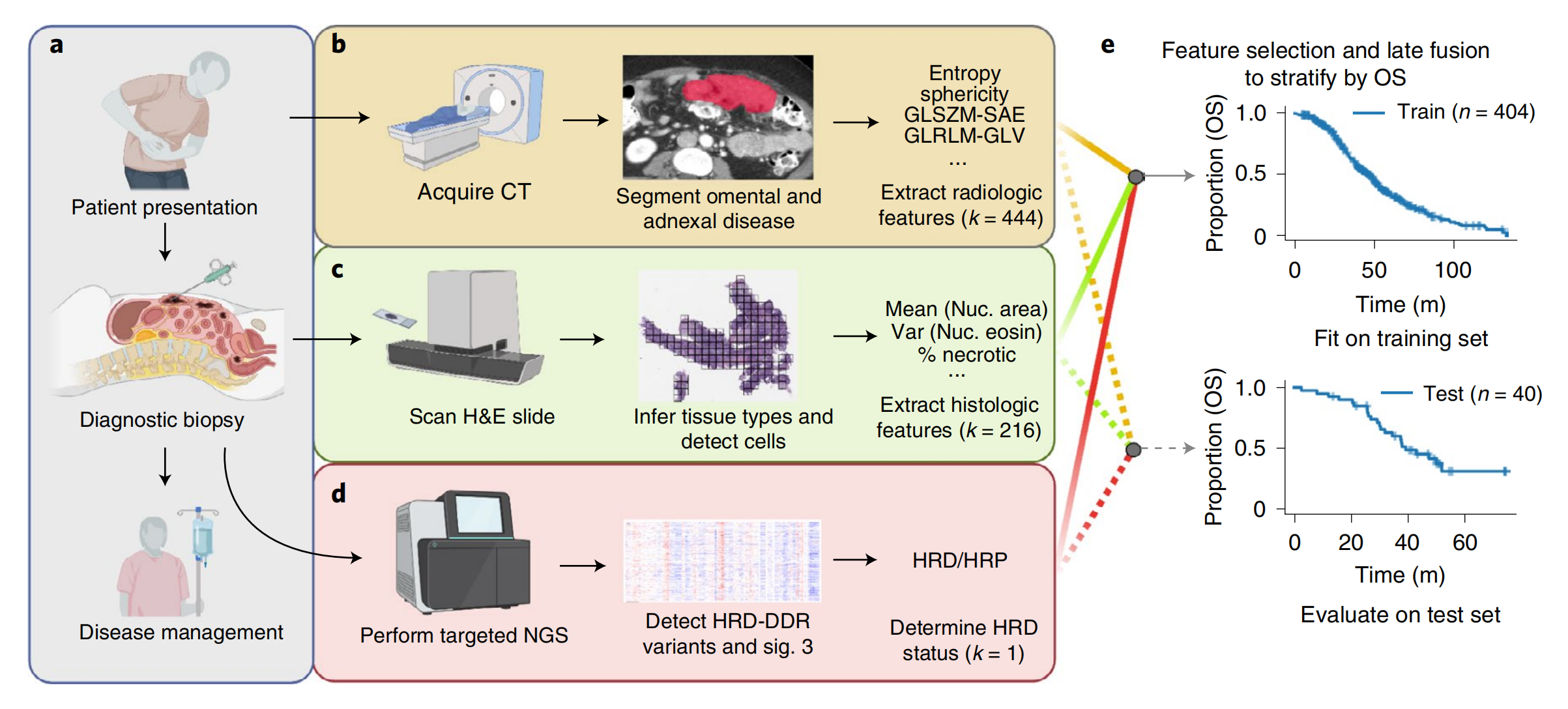
其中,基于大网膜CT特征的放射组学模型在测试集的c-index为0.53,组织病理学模型为0.54,而整合基因组、放射组学和组织病理学的GRH模型将测试集c-index提升至0.61,显著增强了对患者总生存和无进展生存的预测能力。
文章重点验证了多模态数据在肿瘤风险分层中的互补性,发现放射组学与组织病理学特征的风险评分 Kendall’s τ 系数低于0.14,表明两者从宏观纹理(如大网膜密度反映的肿瘤异质性)和微观结构(如细胞核大小关联的基因组不稳定性)提供独立预后信息。
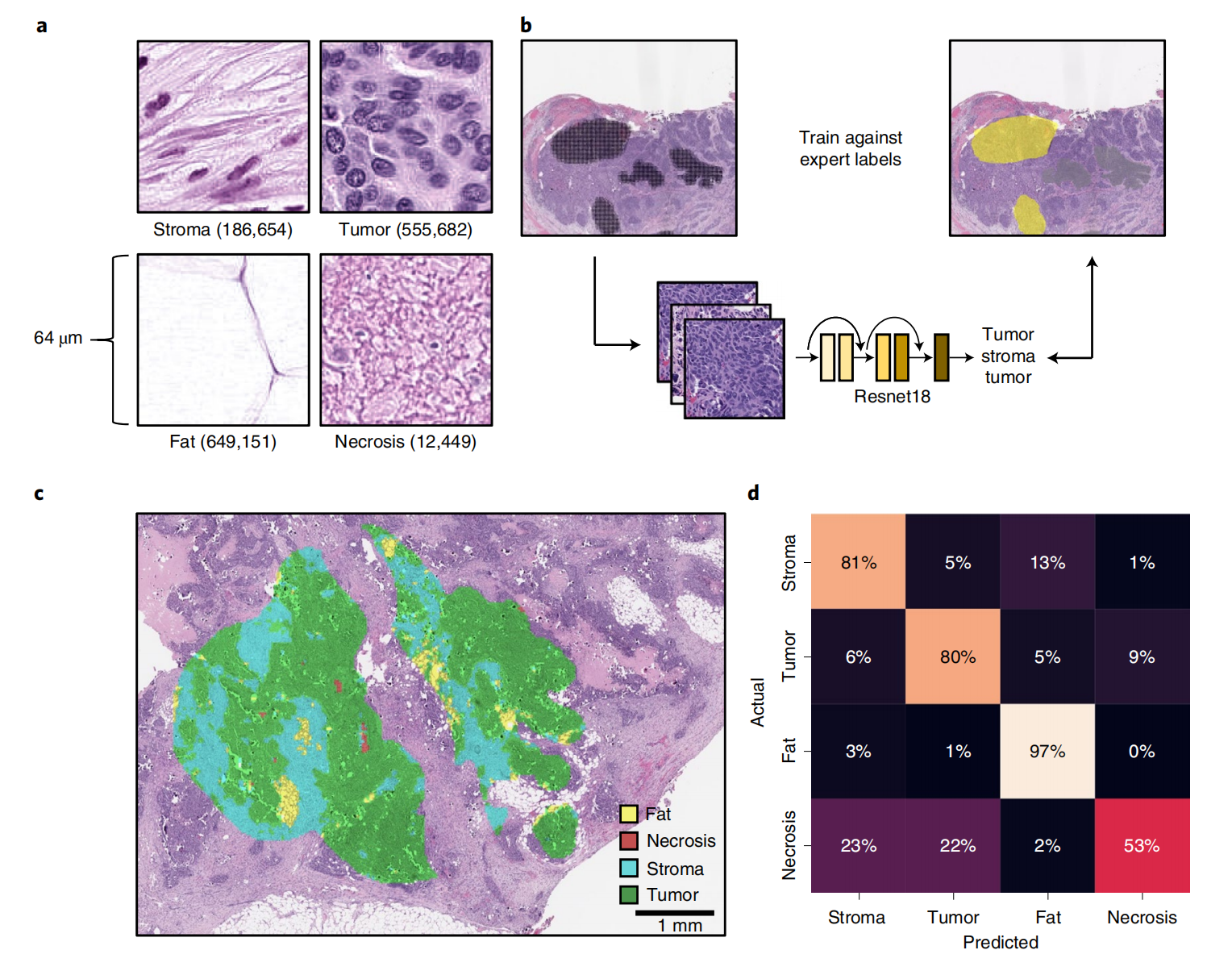
通过弱监督深度学习对H&E切片进行组织类型分类(脂肪、基质、肿瘤等,分类准确率0.88),结合细胞核形态定量分析,建立了可解释的病理特征模型,其核心特征(如核面积)与生存显著相关,为病理图像的自动化分析提供了可复用的技术框架。
对于医学AI研究者,文章展示了从多模态数据采集、特征工程到模型融合的完整技术流程,特别是如何利用临床常规数据(而非专门研究数据)构建可落地模型。
研究采用的晚期融合策略通过分阶段训练单模态模型再整合风险评分,既减少了参数过拟合风险,又能利用部分缺失数据样本,为处理真实世界数据的不完整性提供了参考。
交流群
欢迎大家加入【医学AI】交流群,本群设立的初衷是提供交流平台,方便大家后续课题合作。
目前小罗全平台关注量67,000+,交流群总成员1500+,大部分来自国内外顶尖院校/医院,期待您的加入!!
由于近期入群推销人员较多,已开启入群验证,扫码添加我的联系方式,备注姓名-单位-科室/专业,即可邀您入群。
知识星球
对推文中的内容感兴趣,想深入探讨?在处理项目时遇到了问题,无人商量?加入小罗的知识星球,寻找科研道路上的伙伴吧!
一、文献概述
1-1:研究背景与目的
疾病现状
HGSOC是妇科恶性肿瘤主要死因,5年生存率低于30%,现有预后因素(如HRD状态、年龄、病理分期等)无法充分解释临床结局异质性。
研究目标
探索整合CT影像、组织病理和临床基因组数据,通过机器学习提升HGSOC患者的风险分层准确性。
1-2:研究方法
数据收集
纳入444例HGSOC患者(训练集404例,测试集40例),收集多模态数据:
- 影像数据:治疗前CE-CT扫描,提取大网膜和附件病变的放射组学特征(如纹理、密度)。
- 病理数据:H&E染色全玻片图像(WSIs),通过弱监督深度学习分类组织类型(肿瘤、基质、坏死等),提取细胞核形态特征(如核面积、圆形度)。
- 基因组数据:HRD状态(基于BRCA1/2突变、突变签名3等)。
- 临床数据:年龄、病理分期、治疗方式(PDS/NACT-IDS)、残余病灶(RD)状态等。
模型构建
- 单模态模型:分别建立放射组学(大网膜特征)、组织病理学(核面积、基质长轴长度)和临床基因组(HRD状态)的Cox比例风险模型。
- 多模态整合:采用晚期融合策略,将单模态模型的风险评分整合为多模态模型(如GRH模型:基因组+放射组学+组织病理学)。
1-3:关键结果
单模态模型性能
- 放射组学:大网膜CT纹理的自相关特征(GLCM自相关)与预后显著相关,训练集和测试集的c-index分别为0.55和0.53。
- 组织病理学:肿瘤核平均面积和基质长轴长度构成的模型,训练集和测试集的c-index分别为0.56和0.54。
- 基因组:HRD状态单独分层的c-index为0.55(训练集)和0.52(测试集)。
多模态模型优势
- 整合效果:GRH模型在测试集的c-index为0.61,显著优于单模态模型(如HRD的0.52、放射组学的0.53、组织病理学的0.54)。
- 风险分层:GRH模型将患者分为高/低风险组,测试集OS差异显著(中位生存30个月 vs. 50个月,P=0.023),且与无进展生存期(PFS)相关(P=0.040)。
- 互补性:放射组学与组织病理学特征的风险评分相关性低(Kendall’s τ<0.14),表明两者提供独立预后信息。
1-4:讨论与意义
- 多模态整合价值:影像(宏观纹理+微观核形态)与基因组数据互补,克服了单一模态的局限性(如基因组缺乏空间信息)。
- 临床应用潜力:模型可辅助临床决策,如选择初始治疗、监测频率、维持治疗决策等,且基于常规诊疗数据,易于转化。
- 局限性与展望:依赖回顾性数据,需前瞻性验证;未来可探索更大样本、跨中心数据及注意力机制优化多模态融合。
二、方法
2-1:MSKCC队列筛选
纳入标准为经活检证实的新诊断HGSOC患者,且至少具备以下条件之一:
- (1)治疗前H&E染色全玻片图像(WSIs)显示高级别浆液性癌;
- (2)治疗前腹部/盆腔增强计算机断层扫描(CE-CT)。
MSKCC队列主要来源于在本机构接受诊断性检查和新辅助化疗后间隔减瘤手术(NACT-IDS)的患者回顾性临床数据库,该数据库包含电子病历中的减瘤术后残余病灶(RD)状态、病理分期、新辅助化疗使用情况及患者诊断时年龄等信息。
为扩大队列,研究还从机构数据仓库中检索接受MSK-IMPACT测序且有可用治疗前CT或H&E图像的患者。除回顾性筛选外,36例患者来自前瞻性MSK-SPECTRUM项目34。14例患者缺乏病理分期,改用机构数据库记录的临床分期。
所有患者的种族信息均从机构数据仓库中收集。总生存期(OS)和无进展生存期(PFS)的计算以CT日期(如有)为起始日期,否则以病理诊断日期为准。
在H&E图像收集方面,通过电子健康记录检索伴有腹膜病变(主要为大网膜)的病理病例,由病理专家阅片筛选高质量标本进行数字化。
同时检索机构数据存储库中与诊断性活检相关的扫描玻片,纳入含肿瘤的样本,所有H&E成像均在治疗前完成。
CE-CT扫描需符合以下纳入标准:
- (1)门静脉期静脉注射对比剂图像;
- (2)无遮挡感兴趣病变的条纹伪影或运动相关图像模糊;
- (3)足够的信噪比(补充表7),所有CE-CT成像均在治疗前完成,且以DICOM格式存储于机构影像存档与通信系统(PACS,Centricity,GE医疗系统v.7.0)。
2-2:TCGA队列选择
从TCGA-OV项目35中筛选符合以下条件的患者:TCGA临床数据资源库23中有临床数据注释、病理分级为3级,且在TCIA36中至少有诊断性福尔马林固定石蜡包埋(FFPE)H&E全玻片图像或腹部/盆腔CE-CT扫描。
所有临床和人口学信息均从TCGA CDR中提取,仅纳入TCGA-OV项目中诊断性FFPE H&E染色标本的全玻片图像,且所有H&E成像均在治疗前完成。
CE-CT扫描需满足与MSKCC队列相同的纳入标准,所有CE-CT成像亦在治疗前完成。
2-3:同源重组缺陷(HRD)状态推断
在MSKCC队列中,利用MSK-IMPACT临床测序37(如有)推断HRD状态,使用标准MSK-IMPACT临床流程(https://github.com/mskcc/Innovation-IMPACT-Pipeline)进行基因变异检测和CCNE1拷贝数分析。
对于同意进一步基因组再分析的患者,使用SigMA28推断COSMIC单碱基替换签名3(SBS3)活性(适用于所有505个基因中至少有5个突变的病例),并通过自有流程(https://github.com/jrflab/modules/)39搜索大规模状态转变(LST)38。
采用OncoKB和Hotspot注释40-42评估HRD-DDR相关基因变异的显著性,以分配HRD亚型:具有高置信度显性签名3或HRD-DDR基因中至少一个显著变异或深度缺失的患者被分配至HRD亚型,但存在折返倒位或串联重复富集亚组证据(具体通过CCNE1扩增或CDK12单核苷酸变异)5,27的患者除外。
证据冲突的患者被分配至“模糊”亚型并排除分析,低置信度签名3结果不用于HRD状态定义。纳入LST阈值定义HRD状态会削弱训练集中HRD与HRP组的生存区分度(扩展数据图2a,f),故最终HRD状态定义未采用该方法。来自临床HRD-DDR Panel或BRCA1/2外送检测的结果,除非至少一个报告基因中存在已知显著性变异(由检测方判定),否则分配为HRP。
在TCGA队列中,从cBioPortal下载TCGA-OV项目中HRD-DDR相关基因25、CDK12和CCNE1的拷贝数变异(CNA)和单核苷酸变异(SNV)数据,并按OncoKB标准筛选显著变异。符合以下标准的患者被分配至HRD亚型:HRD-DDR基因中至少存在一个SNV或深度缺失。
无HRD-DDR相关基因变异的患者分配至HRP亚型。存在CDK12 SNV或CCNE1扩增且同时至少一个HRD-DDR基因存在SNV的患者,分配至“模糊”亚型并排除分析。cBioPortal中缺乏SNV和CNA数据的患者亦分配至“模糊”亚型并排除。
此外,从Synapse(syn11801889)下载COSMIC SBS3频率43,其呈现明显双峰分布(扩展数据图3c),SBS3频率大于15%且无HRP冲突证据的患者分配至HRD亚型。
2-4:附件和大网膜病变分割
三名具有专科资质的放射科医师对所有患者(MSKCC及TCGA-OV/TCIA队列)的治疗前CE-CT扫描图像进行卵巢病变和代表性大网膜种植灶的手动分割。
使用Insight分割与配准工具包-SNAP v.3.8.0软件,每位医师在每个含肿瘤的轴位断层上描绘卵巢和大网膜病变的外轮廓,分割过程中出现的争议通过联合阅片和共识解决。
2-5:训练-测试集划分
总体而言,从具备可用H&E全玻片图像、明确HRD状态、已知分期及CE-CT显示大网膜病变的患者中,在分析前随机抽取40例作为测试集。
采用该策略旨在确保单模态与多模态模型间的公平比较,避免因部分模型排除患者而导致测试一致性指数出现假阳性差异。
训练集和测试集同时纳入TCGA-OV和MSKCC病例,原因在于仅有4例TCGA病例具备所有模态的完整信息,无法支持完全独立的外部测试集。
2-6:放射组学特征提取
将所有DICOM序列转换为以Hounsfield单位(HU)表示的容积图像,并应用腹部窗宽窗位(窗位50,窗宽400)。
使用PyRadiomics44,通过Simple ITK B样条插值器将图像重采样为各向同性的1 mm³体素,并以25 HU的 bin 大小对图像进行分箱。
从Coif小波变换图像中提取三维特征,具体包括灰度大小区域矩阵45、相邻灰度色调差异矩阵46、灰度游程长度矩阵47、灰度依赖矩阵48和灰度共生矩阵49特征,从而生成每个病例的代表性大网膜病变或单个附件病变的特征表示。
2-7:组织病理学标注
两名病理专家使用MSK Slide Viewer50对60张H&E全玻片图像进行部分标注,标注内容包括坏死区、富淋巴细胞肿瘤、贫淋巴细胞肿瘤、富淋巴细胞基质、贫淋巴细胞基质、静脉、动脉和脂肪等区域(标注准确性合理但非完全精确)。
将标注结果导出为位图并转换为GeoJSON对象,合并富/贫淋巴细胞肿瘤标签及富/贫淋巴细胞基质标签用于训练,并从训练数据中排除血管结构。
随后利用这些标注生成组织类型图块。
2-8:组织病理学组织类型分类器训练
采用上述标注划定待切割区域,生成尺寸为64 µm×64 µm(128×128像素)、重叠率50%的图块。
未探索其他图块尺寸,该尺寸因既能提供良好分辨率又可在每个图块中显示多个细胞而被选用。通过Otsu算法评估,标注区域内前景占比<20%的潜在图块不予切割。
使用Macenko染色归一化处理后,基于ImageNet预训练的ResNet-18模型进行训练,设置学习率5×10⁻⁴、L2正则化系数1×10⁻⁴,采用Adam优化器,目标函数为类别平衡交叉熵,在单个NVIDIA Tesla V100 GPU上以96图块的小批量进行训练。
通过四折玻片级交叉验证进行模型评估和超参数调优,根据交叉验证F1分数的均值和标准差估计的95%置信区间下限最高值选择最终模型训练的 epoch 数,对所有60张玻片的图块训练21个 epoch。
2-9:组织病理学特征提取与选择
对队列中患者的全玻片图像进行无重叠切割,通过四个NVIDIA Tesla V100 GPU以800图块的小批量进行推理。
由于训练队列以MSKCC病例为主,染色强度差异可能干扰推理,故对所有玻片均进行Macenko染色归一化。
将图块预测结果组装为降采样位图,基于先前研究20的方法计算组织类型特征,包括来自scikit-image51的最大连通组件和各组织类型整体的区域属性,同时计算组织类型面积比、肿瘤和基质熵等特征。
使用QuPath53中的StarDist方法52对单个细胞核进行分割和特征化,保留检测概率>0.5的细胞核。通过手动标注迭代训练淋巴细胞分类器,以区分淋巴细胞与其他细胞。
利用推断的组织类型图为每个细胞核分配组织父类型,并按组织类型和细胞类型计算QuPath提取的细胞核形态学和染色特征(如 eosin 染色方差、圆形度)的聚合统计量,这些细胞类型特征和基于肿瘤、基质、坏死的组织类型特征共同构成每张玻片的组织病理学嵌入表示。
2-10:临床数据编码
减瘤术后残余病灶(RD)状态被编码为二元变量,其中RD≤1 cm(包括完全肉眼切除)的患者赋值为1,RD>1 cm的患者赋值为0。
CE-CT上附件病变的存在与否也作为二元变量纳入分析。诊断时年龄被建模为连续变量,按训练集范围进行标准化。
肿瘤分期采用独热编码为I、II、III、IV期及未知分类变量,同理,主要治疗方式(NACT-IDS、PDS及未知)也采用独热编码处理。
2-11:特征选择
采用统一策略进行放射组学、组织病理学和临床特征的选择。
对于每个特征,使用Python的Lifelines包在完整训练集上拟合单变量Cox比例风险模型(不使用正则化),并绘制单变量系数和显著性置信度。
对于模型未能收敛的特征,尝试使用L2正则化(c=0.2)重新拟合,仍无法收敛的特征被赋予log(HR)=0和P=1。在组织病理学分析中,通过在每个Cox模型中纳入相对标本大小以控制混杂。随后移除标准化四分位距(IQR)低于0.1的特征。
对于特征空间最大的放射组学数据,采用Benjamini–Hochberg方法54进行多重假设检验校正。在获得95%置信度的显著特征有序列表后,应用Algorithm 1筛选特征,生成具有低多重共线性的模态特征集。
多变量模型特征选择算法
- 输入:是按P值排序的唯一候选特征列表 f i f_i fi , i i i的取值范围是 [ 1 , k ] [1, k] [1,k] ,这里 k k k表示候选特征的数量。
- 输出:是在多变量回归中置信度为 α \alpha α的显著特征列表 g j g_j gj , j j j的取值范围是 [ 1 , l ] [1, l] [1,l] ,且 l ≤ k l \leq k l≤k ,即输出的显著特征数量小于等于输入的候选特征数量。
- 运行过程:
- 初始化条件要求 k ≥ 1 k \geq 1 k≥1 ,并设定 i = 1 i = 1 i=1 (用于遍历候选特征列表的索引) , j = 1 j = 1 j=1 (用于记录显著特征列表的索引) 。
- 进入循环,只要
i
≤
k
i \leq k
i≤k ,就执行以下操作:
- 将当前候选特征 f i f_i fi赋值给 g j g_j gj 。
- 通过Cox回归评估 g g g(这里 g g g就是当前的 g j g_j gj )的显著性,得到 P j P_j Pj 。
- 如果 P j < α P_j < \alpha Pj<α ,说明当前特征在置信度 α \alpha α下显著,此时 j = j + 1 j = j + 1 j=j+1 ,准备记录下一个显著特征;否则不进行操作。
- 然后 i = i + 1 i = i + 1 i=i+1 ,继续遍历下一个候选特征。
- 当 i > k i > k i>k时,循环结束,得到最终的显著特征列表 g j g_j gj 。
消融实验中的修改
在消融实验中,对该算法进行了修改:
- 对于临床特征,由于没有特征的 P < 0.05 P < 0.05 P<0.05 ,所以采用了 0.31 0.31 0.31作为阈值来判断其是否显著。
- 在对大网膜放射组学特征进行消融实验时,没有进行多重假设检验校正,因为按照此指标没有特征会达到显著水平。 这样做是为了测试从部分信息病例中学习的重要性。
2-12:生存建模
本研究对所有单模态及多模态模型采用带L2正则化(c=0.5)、无L1正则化的线性Cox比例风险模型。
基因组模态未拟合子模型,HRP亚型患者被定义为高风险(风险评分1.0),HRD亚型患者定义为低风险(风险评分0),未使用交互项。采用Kaplan–Meier分析评估各模型是否将患者分层为具有临床意义的组别,通过测试百分位阈值集合{0.33, 0.34, …, 0.64, 0.65, 0.66},选择使训练集对数秩检验分层显著性最大化的值划分风险组(适用于OS和PFS分析)。
一致性指数(c-Index)的P值通过1000次置换检验计算,其95%置信区间采用100次留一法自举法估计。Kaplan–Meier分析的所有P值通过多变量对数秩检验获得,Cox比例风险模型中协变量显著性的P值基于c=0.5的拟合结果报告,生存概率通过线性插值法估算。
2-13:多模态整合
为增加单模态参数估计的样本量,研究采用晚期融合策略8。
单模态子模型的参数通过所有可用单模态数据估计(放射组学参数基于251例含大网膜病变的训练CT病例估计,组织病理学参数基于243例训练H&E病例估计),每个子模型推断患者的部分风险值。
为与lifelines Python包55中实现的一致性指数兼容,使用负部分风险值。
在第二阶段晚期融合模型中,仅利用患者交集集,对整合各模态推断的负对数部分风险值的多变量Cox模型进行参数估计。
2-14:统计与可重复性
研究未采用统计方法预先确定样本量,仅按上述标准在机器学习建模前排除数据。
训练集和测试集从具备全部四种模态数据的患者中随机选取,结局评估时研究者未对分组设盲。所有检验均未假设数据服从正态分布,生存建模中假定风险比例成立但未进行正式检验。
分析使用QuPath v.0.2.3(含StarDist扩展)、ITK SNAP v.3.8.0及Python v.3.9.4编写的自定义代码(依赖Pandas v.1.2.4、NumPy v.1.20.2、PyTorch v.1.5.1、TorchVision v.0.6、OpenSlide v.1.1.1、Seaborn v.0.11.1、Matplotlib v.3.4.2、SciPy v.1.6.3、scikit-learn v.0.24.0、PyRadiomics v.3.0及Lifelines v.0.25.7等库)完成。
2-15:数据可用性
支持本研究结果的DNA测序、H&E全玻片图像(WSI)和CT数据已存储于Synapse(Sage Bionetworks),访问编号为syn25946117。
额外的H&E WSI、CT影像和基因组数据来源于TCGA研究网络(http://cancergenome.nih.gov/)和癌症影像存档库(The Cancer Imaging Archive,https://www.cancerimagingarchive.net/)。
由于机构层面仍在讨论伦理和法律影响,病理科CLIA实验室进行的MSK-IMPACT原始测序数据目前暂不允许公开存储,因此存储库中仅共享与HRD状态相关的衍生特征。
源数据已作为Source Data文件提供,其他支持本研究结果的数据可通过合理请求联系通讯作者获取。
三、OncoFusion模型概述
OncoFusion 是一款综合性机器学习流水线,旨在通过多模态数据整合对患者的总生存期进行风险分层。
该系统从以下四种关键数据模态中提取并整合特征:
- 组织病理学全玻片图像(H&E WSIs)
- 增强计算机断层扫描(CT)
- 靶向测序面板(基因组数据)
- 临床协变量
3-1:系统架构
OncoFusion 采用晚期融合(late-fusion)方法,先从每种模态独立提取特征,再将其组合用于生存建模。流水线包含以下关键阶段:
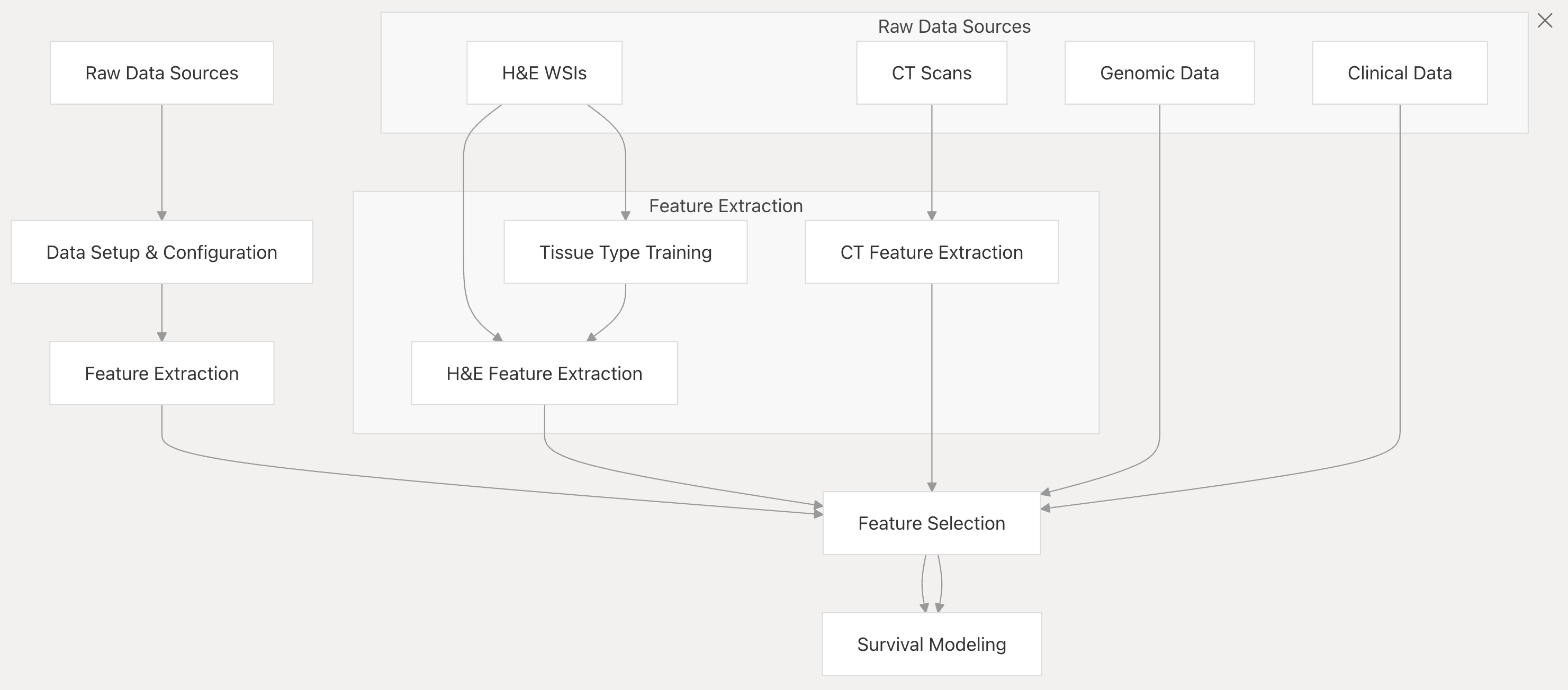
原始数据源
包含H&E全玻片图像(H&E WSIs)、CT扫描(CT Scans)、基因组数据(Genomic Data)和临床数据(Clinical Data) ,是整个流程的数据起点。
数据设置与配置
原始数据源的数据先进入“数据设置与配置(Data Setup & Configuration)”环节 ,在此设置全局参数,定义数据和代码目录路径等,为后续处理做准备。
特征提取
- H&E相关:H&E WSIs一方面可直接进入“H&E特征提取(H&E Feature Extraction)” ;另一方面可先经过“组织类型训练(Tissue Type Training)” ,训练语义分割模型以识别组织类型,再进行H&E特征提取。
- CT相关:CT Scans进入“CT特征提取(CT Feature Extraction)”环节,从扫描图像中提取相关特征。
特征选择
经过特征提取后,来自H&E WSIs、CT Scans、Genomic Data和Clinical Data的数据所提取的特征,都汇总到“特征选择(Feature Selection)”步骤 ,通过对数部分风险比和单变量Cox回归等方法,筛选出有价值的特征。
生存建模
筛选后的特征进入“生存建模(Survival Modeling)”阶段 ,利用这些特征构建和评估生存模型,实现对患者生存情况的分析和预测。
3-2:关键组件
数据设置与配置
OncoFusion 需要以下数据源和配置步骤:
- 配置:全局参数在
global_config.yaml中设置,定义数据和代码目录的路径。 - H&E WSIs:使用 GDC 数据传输工具从清单文件下载。
- Synapse 代码库:包含注释、CT 扫描和预处理后的临床/基因组数据。
- Singularity 容器:用于可复现的 QuPath 和 StarDist 执行。
组织类型训练(可选)
此组件训练语义分割模型以识别 H&E 图像中的不同组织类型:
- 目的:训练模型从 H&E 图像推断组织类型。
- 输入:妇科病理学家的注释。
- 输出:模型权重存储于
tissue-type-training/checkpoints/tissue_type_classifier_weights.torch。 - 说明:提供预训练权重,此步骤可选。
3-3:H&E 特征提取
H&E 特征提取流水线包含三个主要步骤:
- 组织类型推断:应用训练好的模型分割组织类型并提取基于组织的特征。
- 目标检测:使用 QuPath 中的 StarDist 分割细胞核并分类淋巴细胞。
- 特征整合:配准组织类型和细胞核特征,提取综合统计信息。
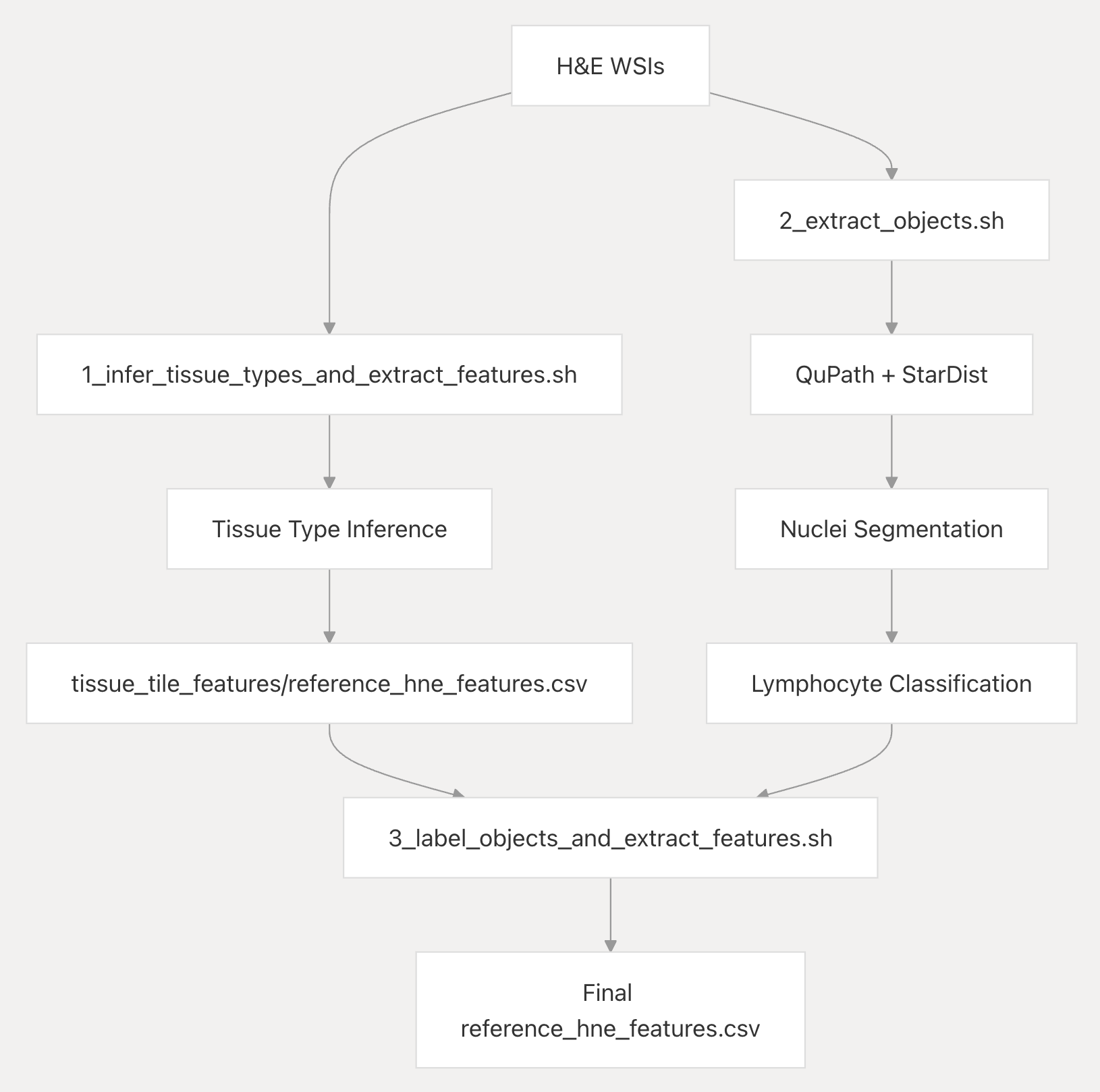
组织类型推断路径
- H&E WSIs 首先可以通过脚本“1_infer_tissue_types_and_extract_features.sh”进行处理,进入“组织类型推断(Tissue Type Inference)”环节 。
- 经过组织类型推断后,生成“tissue_tile_features/reference_hne_features.csv”文件,该文件记录了基于组织类型推断得到的特征信息。
目标提取路径
- H&E WSIs 也可以通过脚本“2_extract_objects.sh”进行处理,借助QuPath和StarDist工具 。
- 先进行“细胞核分割(Nuclei Segmentation)” ,将细胞核从图像中分割出来,然后进行“淋巴细胞分类(Lymphocyte Classification)” ,对淋巴细胞进行分类识别。
整合与最终特征生成
- 上述两条路径生成的结果(“tissue_tile_features/reference_hne_features.csv”文件和目标提取相关结果),会通过脚本“3_label_objects_and_extract_features.sh”进行整合处理。
- 最终生成“Final reference_hne_features.csv”文件,该文件包含了经过综合处理和提取的H&E图像特征,可用于后续的分析,如生存建模等。
整个流程图体现了对H&E WSIs特征提取的分步处理过程,通过不同脚本和工具的协同作用,从图像中提取出全面且有价值的特征信息。
3-4:CT 特征提取
- 目的:从 CT 扫描中的大网膜和附件病变提取特征。
- 输入:经放射科医生勾勒轮廓的 CT 扫描。
- 输出:特征以 CSV 文件形式存储于
features子目录。
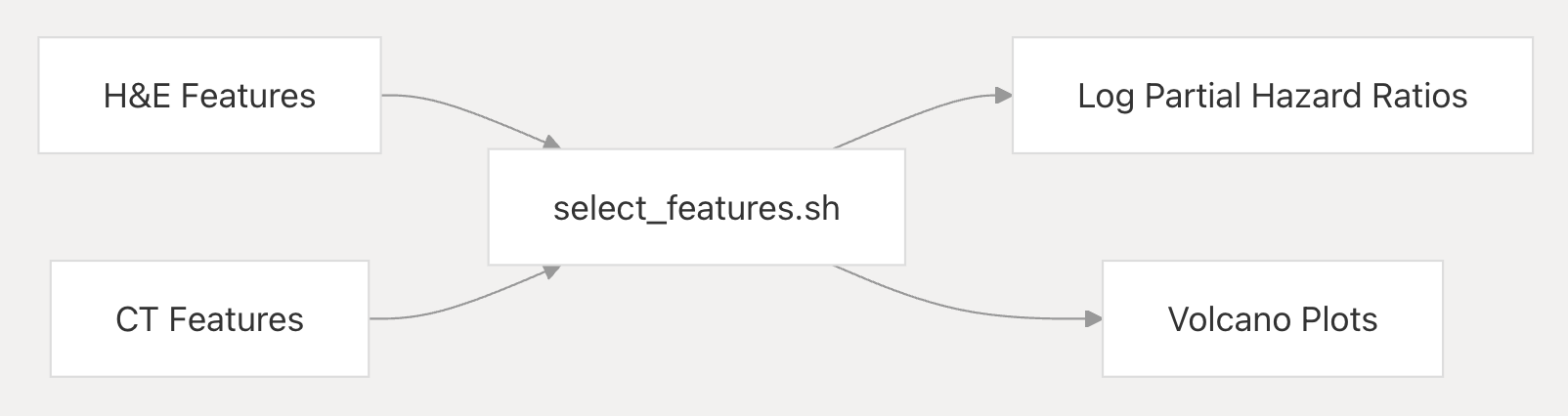
3-5:特征选择
- 目的:从 CT 和 H&E 特征空间中选择信息性特征。
- 方法:使用对数部分风险比和单变量 Cox 回归。
- 输出:结果子目录中的火山图。
3-6:生存建模
- 目的:使用所有模态的特征构建并评估生存模型。
- 方法:多模态整合的晚期融合框架。
- 输出:各子目录中的结果和图表。
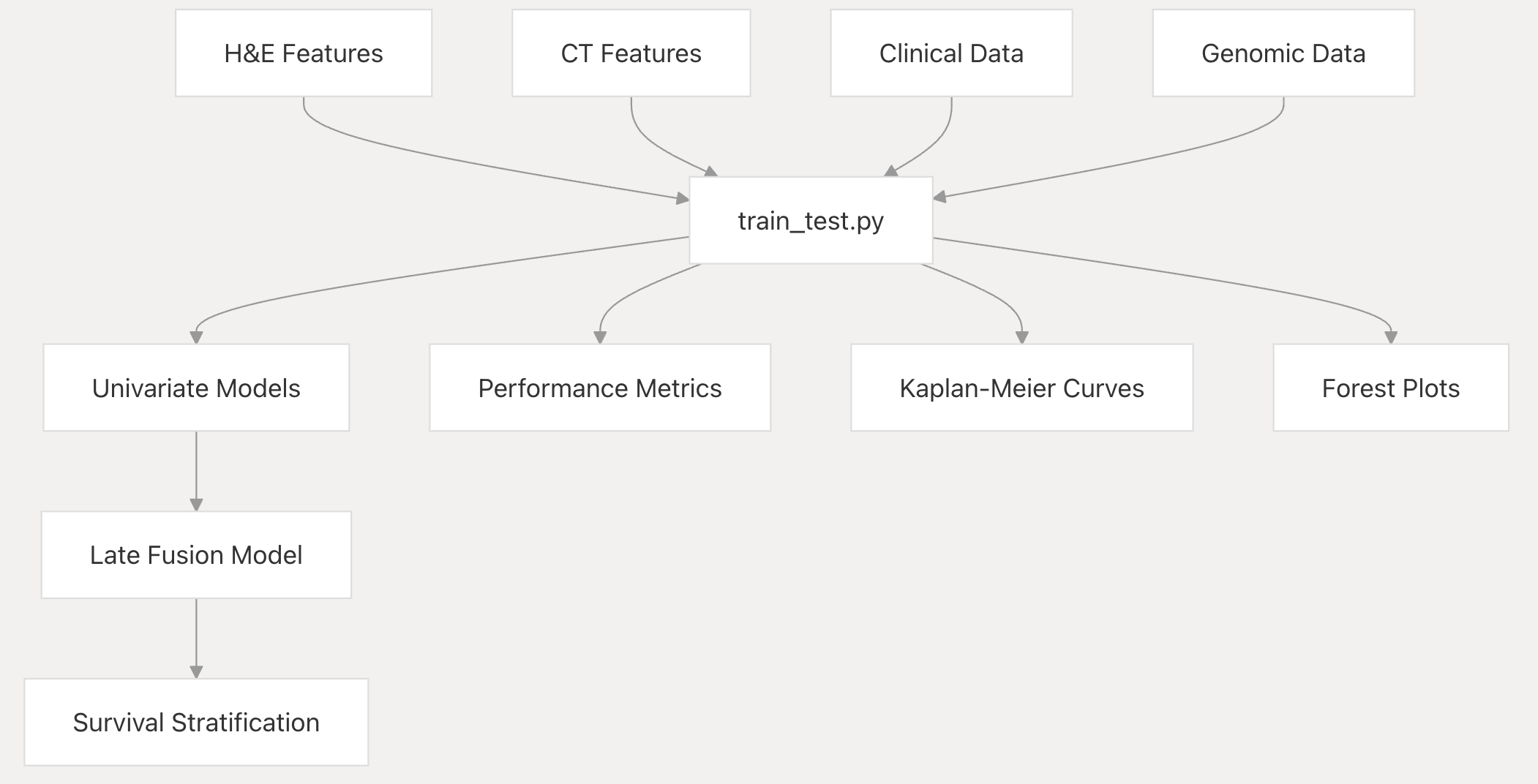
数据输入
H&E特征(H&E Features)、CT特征(CT Features)、临床数据(Clinical Data)和基因组数据(Genomic Data) ,这些来自不同模态的数据特征,作为输入提供给“train_test.py”脚本。
模型训练与分析
“train_test.py”脚本对输入的数据进行处理,生成多种结果:
- 单变量模型(Univariate Models):基于输入数据分别构建单变量模型,用于初步分析各模态数据特征与生存情况的关系。
- 性能指标(Performance Metrics):计算模型的相关性能指标,如准确性、灵敏度等,用以评估模型的表现。
- Kaplan - Meier曲线(Kaplan - Meier Curves):绘制Kaplan - Meier曲线,用于展示不同组别的生存概率随时间的变化情况。
- 森林图(Forest Plots):生成森林图,直观呈现各因素对生存结果影响的效应量及置信区间等信息。
晚期融合模型与生存分层
- 由单变量模型进一步构建“晚期融合模型(Late Fusion Model)” ,该模型整合多模态数据特征,综合考虑不同来源信息对生存的影响。
- 最终通过晚期融合模型实现“生存分层(Survival Stratification)” ,将患者按生存情况进行分层,帮助了解不同患者群体的生存风险差异。
该流程图体现了OncoFusion系统在生存建模时,如何利用多模态数据进行综合分析,逐步构建模型并得出有临床意义的生存分层结果。
3-7:系统要求
OncoFusion 已在以下硬件和软件配置上测试通过:
| 组件 | 要求 |
|---|---|
| CPU | 96 核 |
| 内存 | 500GB CPU RAM |
| GPU | 4 块 Tesla V100(CUDA 11.4) |
| GPU 内存 | 64GB |
| 存储 | 1TB |
| 操作系统 | Redhat Enterprise Linux v7.8 |
| Python | v3.9 |
| Conda | v4.12 |
| Singularity | v3.8.3 |
流水线的每个组件在各自的 environment.yml 文件中指定了独立的 Conda 环境。
结束语
本期推文的内容就到这里啦,如果需要获取医学AI领域的最新发展动态,请关注小罗的推送!如需进一步深入研究,获取相关资料,欢迎加入我的知识星球!



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









