







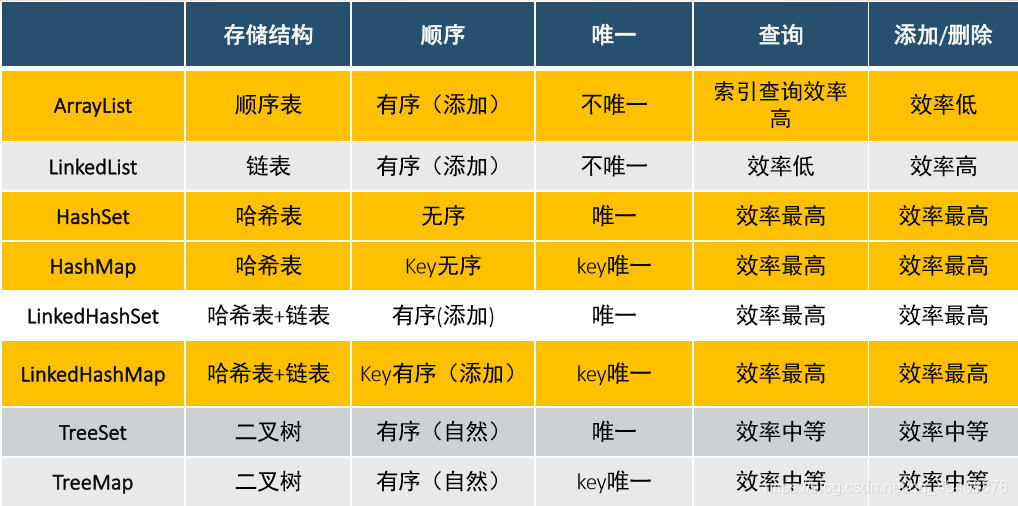
 本文总结了Java中集合框架的Collection接口及其子接口List、Set的使用,包括ArrayList、LinkedList、HashSet、LinkedHashSet、TreeSet等具体实现类的特性与应用场景。分析了集合与数组的区别,以及不同集合类在数据存储、增删查改操作上的效率差异。
本文总结了Java中集合框架的Collection接口及其子接口List、Set的使用,包括ArrayList、LinkedList、HashSet、LinkedHashSet、TreeSet等具体实现类的特性与应用场景。分析了集合与数组的区别,以及不同集合类在数据存储、增删查改操作上的效率差异。
容器Collection的学习总结
容器:就是存放东西的载体,现实中杯子、碗、盆等等,而在Java中也是有容器。不过在Java中就是存放各种各样的数据。之前也学过数组它也是一种容器,只不过数组有固定的尺寸,在某些场景中就不方便存储对象。所以就衍生出了容器这一概念也称集合。
首先谈谈为什么使用集合而不是数组?
数组和集合都相似,都可以存储多个对象,对外是一个整体的存在。
但数组的缺点是:
- 长度必须在初始化时定义,且固定不变
- 数组采用连续存储空间,删除和添加的效率低
- 数组无法直接保存映射关系
- 数组缺乏封装,操作繁琐
而集合弥补了数组的一些缺点,在使用中更灵活更实用,可大大提高软件的开发效率而且不同的集合框架适合不同的场景。
那我们在来了解有哪些常用的容器吧!
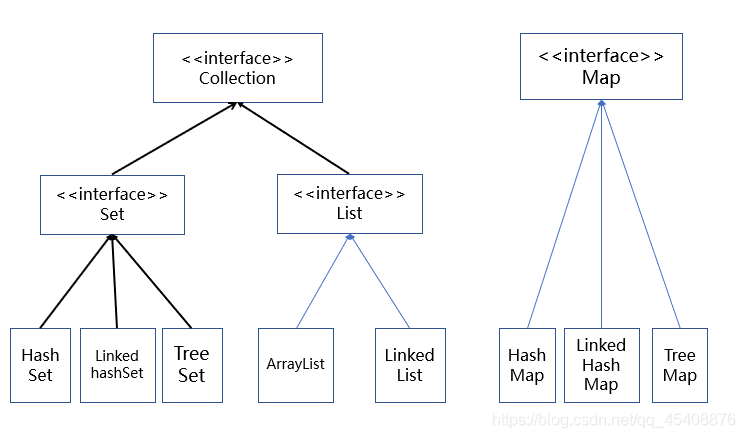
常用的容器有接口有Collection、List、Set、Map
Collection接口存储一组不唯一,无序的对象。
List和Set继承了Collection是其子接口,
但不同点是:
List是有顺序,可重复的,原理是底层实现源于数组。其常用实现类有(ArrayList 和 LinkedList)
Set是没有顺序,不可重复的,原理是底层实现来源于HashMap。常用实现类有(HashSet、LinkedHashSet、TreeSet)
Map是将唯一键映射到值,键是以后用于检索值的对象。给定键和值,可以在Map对象中存储值;存储值以后,可以使用相应的键来检索值。其常用实现类有(HashMap、LinkedHashMap、TreeMap)
这下来挨着讲解各个集合类吧
List:
List接口扩展了Collection,并声明了用来存储一连串元素的集合的行为。在列表中,可以使用从零开始的索引,通过元素的位置插入或访问元素。
特点:有序 不唯一(可重复)
实现类是 ArrayList 、 LinkedList
ArrayList:
本质上,Array List就是元素为对象引用的长度可变的数组。在Java中,标准数组的长度是固定的。数组在创建后,就不能增长或缩短,而ArrayList可以动态增加或减少大小。它是线性表中的顺序表
特点:
- 在内存中分配连续的空间,实现了长度可变的数组
- 优点:遍历元素和随机访问元素的效率高
- 缺点:添加和删除需要大量移动元素效率低,按照内容查询效率低

import java.util.ArrayList;
import java.util.List;
public class TestList {
public static void main(String[] args) {
test01();
}
public static void test01() {
List<String> list=new ArrayList<>();
list.add("盖伦");//在容器中新增值
list.add("剑姬");
list.add("提莫");
list.add("大虫子");
list.add("薇恩");
list.add("玛尔扎哈");
System.out.println(list);
List<String> list1=new ArrayList<>();
list1.addAll(list);//将list里的元素合并在list1中
System.out.println(list1);
list.remove("大虫子");//删除值为大虫子的元素
System.out.println(list);
System.out.println(list.get(3));//得到索引为3的值
list.add(2, "光辉");//在索引2处添加值,将原有值覆盖。
System.out.println(list);
list.clear();//清空容器里的所有值
System.out.println(list);
System.out.println(list.size());//容器的大小
System.out.println("list是否为空:"+list.isEmpty());//容器是否为空
}
}
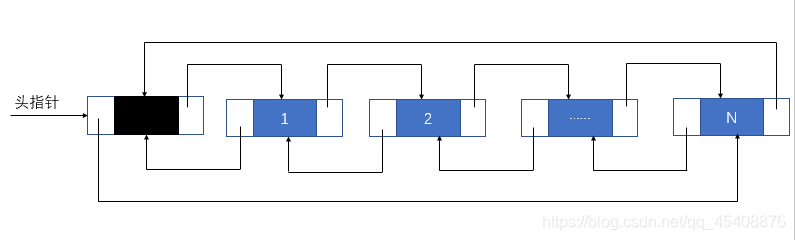
LinkedList :
原理采用的线性表中双向链表,当数据量很大或者操作很频繁的情况下,添加和删除元素时具有比ArrayList更好的性能。但在元素的查询和修改方面要弱于ArrayList。LinkedList类每个结点用内部类Node表示,LinkedList通过first和last引用分别指向链表的第一个和最后一个元素,当链表为空时,first和last都为NULL值。
特点:
- 采用双向链表存储方式
- 缺点:遍历和随机访问元素效率低下
- 优点:插入、删除元素效率比较高(但是前提也是必须先低效率查询才可以。如果插入删除发生在头尾可以减少查询次数)
import java.util.LinkedList;
import java.util.List;
public class testLinkedList {
public static void main(String[] args) {
test();
}
public static void test() {
List<String> linkedList=new LinkedList<>() ;
linkedList.add("曹操");
linkedList.add("张飞");
linkedList.add("孙权");
linkedList.add("刘备");
System.out.println(linkedList);
System.out.println(linkedList.indexOf("刘备"));//找到值所在的索引位置
linkedList.set(3, "典韦");
System.out.println(linkedList);
}
}
.
.
.
.
Set
Set接口定义了组。它扩展了Collection接口,并声明了集合中不允许有重复元素的组行为。所以添加重复的元素,add()方法就会返回为false。Set接口没有定义自己的其他方法。
HashSet:
HashSet简单的理解就是该集合中不能存储相同的数据,存储数据是无序的。但HashSet存储元素的顺序并不是按照存入时的顺序,是按照哈希值来存的所以取数据也是按照哈希值取得。
特点:
- 采用HashTable哈希表存储结构
- 优点:添加速度快 查询速度快 删除速度快
- 缺点: 无序
LinkedHashSet:
LinkedHashSet存储结构是一个双向链表,因此它存储的元素是有序的。LinkedHashSet继承自HashSet,源码更少、更简单,唯一的区别是LinkedHashSet内部使用的是LinkHashMap。这样做的意义或者好处就是LinkedHashSet中的元素顺序是可以保证的,也就是说遍历序和插入序是一致的。
特点:
- 采用哈希表存储结构,同时使用链表维护次序
- 有序(添加顺序)
TreeSet:
特点:
- 采用二叉树(红黑树)的存储结构
- 优点:有序 查询速度比List快(按照内容查询)
- 缺点: 查询速度没有HashSet快
.
.
.
Map(key-value映射)
HashMap:
HashMap是基于哈希表实现的Map接口实现类。这个实现提供所有的map相关的操作,允许使用null的键和null的值。(HashMap与Hashtable大致是一样的,只是HashMap是不同步的,且它允许你null的键和值。);另外,HashMap内部元素排列是无序的。
特点:
- Key无序 唯一
- Value无序 不唯一
LinkedHashMap:
特点:
- 有序的HashMap 速度快
TreeMap:
TreeMap可以实现存储元素的自动排序。在TreeMap中,键值对之间按键有序,TreeMap的实现基础是平衡二叉树。
平衡二叉树详解可以参考娜娜娜娜小姐姐的红黑树原理和算法介绍
特点:
- 有序 速度没有Hash快
集合总结
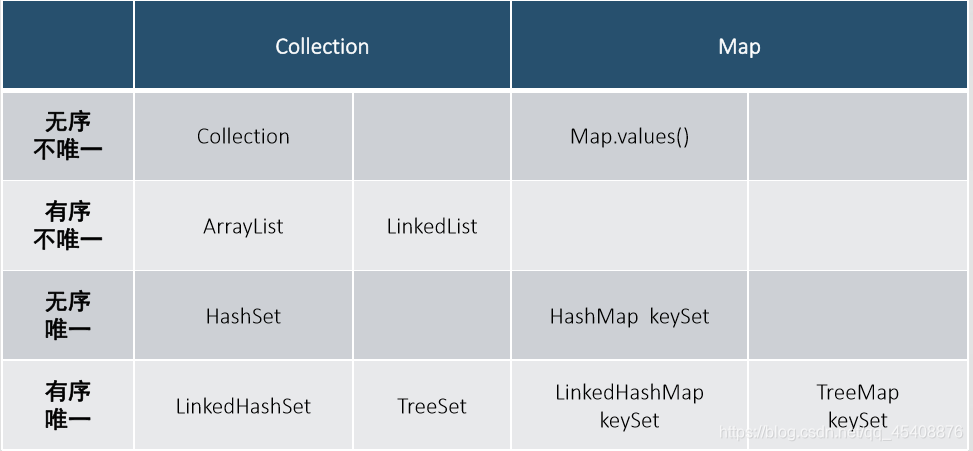
集合区别

















 320
320

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









