






1. 数据仓库建模模型
数据模型分层
ODS:贴源层
DWD:确定模型(星、雪花),维度
DWS:按要求写SQL语句
ADS:按要求展示数据
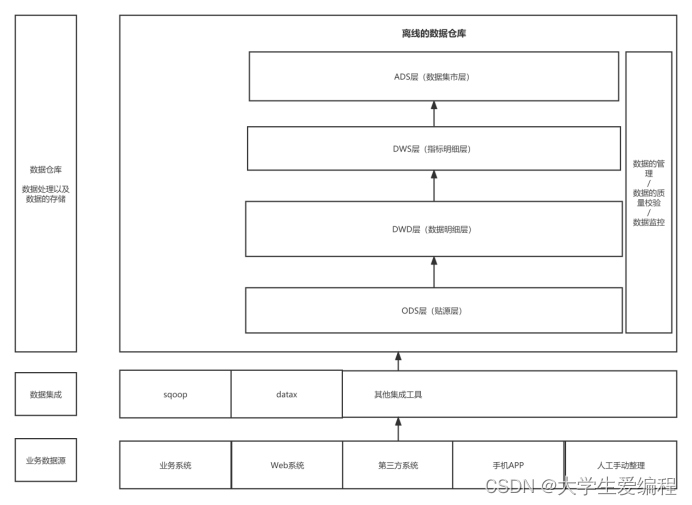
1.1 数据仓库(数据中台一部分)特点和痛点
面向主题,随时间变化的(三到十年,不会删除因为可以分区查),集成的,非易失的
1:对域进行划分,每个主题基本对应一个宏观分析领域
2:与面向主题密切相关,将分散的数据源统一为无歧义的数据,再放到仓库中
3:反应某一段时期的数据,存在较长的生命周期但是也会被清除的
4: 数据落实进入数据仓库中不应该再有变化,较多的操作是增加数据,此时会产生新的记录,会保留数据变化的历史轨迹,更多的是查询操作。
传统数据开发的痛点:
数据资产模糊:命名不规范,只知道存数据不知道管理数据
数据质量低:
重复建设:多人开发,开发过的表有些表需要关联,我们进行一次关联多次使用
问题定位难
无法应对频繁的临时需求:要重新开发,不能基于已有的表进行开发
代码耦合性高:代码的依赖性高
OLTP:面向事务处理 少量数据的查询修改
OLAP:面向分析处理 通过历史数据针对某些主题进行分析以支持管理决策
1.2 DW层常见模型:(优缺点)
都是围绕事实表
1.维表:不经常变化,维表连接维表成雪花模型
2.星模型:(企业多用:能更快回溯定位到问题所在)
{非正规化,不用过多考虑正规化因素,设计维护简单;不存在渐变维度;有冗余数据;查询效率可能会比较高}
3.雪花模型:将某些维度表抽取成粒度更细的维度表,让维度表之间进行关联(构建周期长,人力物力资源)(省市区县模型)
{正规化但维护复杂,数据冗余少;有些数据要经过维表连接才能获取效率低;}
混合使用:
4.经验:星型多用,可能会减少麻烦
1.3 维度设计流程
(DIM维表:抽出不经常变化的数据构建维表,尽可能多拿字段)
1.选择维度
2.确定主维表
3.梳理维度关系
4.定义维度属性
1.4 数据仓库维度建模流程
- 选择业务过程:通过对业务需求和数据源综合考虑确定对哪种业务过程开展数据建模
- 声明粒度:粒度就是数据分的层级,能支持较粗的粒度不可支持较细的粒度,因为查询希望以很精确的方式对细节进行抽取,所以数据仓库总是要求每个维度对最低粒度进行表示,但是粒度越细事实表的数据量越大,我们还是根据需求综合分析
- 确定维度:维度就是观察数据的角度即分析问题的角度,经常作为分组的条件,合理的粒度可以确定事实表的基本维度,某些维度的附加可能会生成新的事实从而违背当初粒度的定义,此时要修改粒度以适应。(维度表也成称查找表,与事实表相对应,可与事实表相关联,相当于将事实表中经常反复用到的数据抽取出来规范为一张表,缩小了事实表的大小,变化通常不会太大)
- 确定事实:确定将哪些事实放入表中,事实要与粒度吻合,此时可能需要调整粒度和维度,都是处于动态平衡中。(事实表:存储有事实记录的表,事实表是动态增长的比如销售记录用户访问日志,是数据仓库中最大的表,星型模型的核心,)
1.5 事实表
设计原则:
事实完整性
粒度一致性
事实可加性
维度退化
事实易用性
单位统一
业务相关
空值处理
事务事实表:记录实体的一个事务(订单的时间设备,以一个完整事务为数据)
周期快照事实表:每隔段时间进行存储(熔炉)
累计快照事实表:交易全流程事实表(从下单到客户收货全过程,字段非常多)
设计事实表的流程:
(倒推思想)
业务调研
1.6 数仓模型层级调用原则:
禁止逆向调用:下层禁止调用上层的表(死循环)
避免同层调用
优先使用公共层调用:(DWS,DWD,DIM)
避免跨层调用:特定情况下ADS层可以直接调用ODS层的表
1.7 专有名词解释
OneData:
业务过程:指企业的业务活动事件,如下单,支付,退款都是业务过程。请注意,业务过程是一个不可拆分的行为事件,通俗地讲,业务过程就是企业活动中的事件
原子指标:最小粒度,数据不可再细分了
业务限定:统计业务范围(条件),筛选出符合业务规则的记录,区分统计角度
比如:我们想统计pc访客数,可以先创建pc端的业务限定,后期还可以进行相似规则的指标,比如pc端浏览次数
派生指标:即常见的统计指标,为了使其标准规范无异义地生成,加限定条件,(包含多个原子指标)
指标都是经过这四部分组成的,但是到不同表或者层中去取数据
指标生成体系:原子指标+统计周期(时间)+统计粒度+业务限定=派生指标
举例: 签约金额+最近一周+楼栋+西湖区=最近一周西湖区各楼栋的签约金
这样规范以后写sql就清晰许多了
1.8 数据采集和同步
-
批流一体 离线增量与全量的同步 支持实时数据采集
-
断点续传:先产生的数据因为网络等原因而后被采集,如何恢复顺序(Flink)
-
插件式架构 支持新的数据源插件
数据采集流程和同步场景:
拉链表:
拉链表是一种数据模型,主要是针对数据仓库设计中表存储数据的方式而定义的,顾名思义,所谓拉链,就是记录历史。记录一个事物从开始,一直到当前状态的所有变化的信息
1.9 数据加工和清洗
- 元数据不一致:取值不统一,单位不统一
统一规则,比如性别在某些表中用01表示,有些用wm表示,所以要在开发之前进行一次统一,定义转换规则,清洗数据 - 数据缺失: 字段取值为NULL,比如性别不能 为NULL
比如不知道性别的NULL值用-1代替,或者填充数据均值极值等,或者填充拟合后最可能的数据 - 数据错误: 格式错误(类型),取值异常(根据统计信息判断),逻辑错误(记录不同,确认不同数据来源的可信度,横向对比,根据其他对象信息判断,纵向对比,结合该对象的其他信息进行判断)
- 数据冗余:
2. 数据中台(国外叫数据湖)
大数据架构师很少,大数据硕博也少
阿里提出概念,数据中台方法论,数据仓库周围多了一些组件
技术角度:多了任务调度管理元数据管理数据地图
业务角度:将公司各个业务部门的数据统一到一个平台中,集中开发出数据的价值
数据中台落地五步,企业数据化建设的最佳实践
数据资源的盘点 技术情况,数据情况,业务情况
数据应用规划 企业架构梳理 应用场景规划 指标的制定与管理
数据中台的设计 技术平台框架产品的选择 数据模型的设计 算法模型的设计
数据中台的开发 数据同步和数据建模的实施 数据应用的实施 数据资产管理构建
数据中台的运营 组织体系建设 数据指标项和标签体系的完善 数据应用的运营丰富化
项目是长期持久分期更新的,站在尽可能高的视角看一下项目的全局
数据治理:在大数据平台内部,对数据的质量,数据安全,元数据管理,数据生命周期等进行有效的管理
3. DataWorks介绍
阿里云:
快速上线产品,减少成本,功能强大
数据应用:API接口,BI展示,datav,帆软BI,quickBI
分布式计算:Max Compute
分布式存储系统:盘古
资源调度框架:伏羲(mesos,yarn类似)
数据集成,数据开发(Data Studio),运维中心(生产环境),数据质量,数据服务
简单模式:开发生产空间一体
标准模式:空间隔离,需要提交,不互相影响
4. 基于DataWorks的智慧地铁项目
4.1 ods层一个工作空间对应一个库
数据接入的时候进行了 一次过滤,
replace函数 替换目标字符 REPLACE(substr(deal_date,1,10),‘-’,‘’)
substr函数 切分 哪个字段,从哪开始切到哪
-
平台搭建买合适的配置就可以了
-
开通DataWorks和MaxComputer,开通数据库,创建交换机,建立外网,白名单,navicat创建连接
-
创建MySQL建表语句去建表,导入数据,数据采集
阿里云平台中因为网络不通,连接不上本地数据库的
创建数据源,域名而且注意指定库名 ,在进行同步选择数据源时如果没指定数据库的库名,即使有表也选不到
连接串模式是连接共用的数据库的 实例模式是连接自己创建的数据库
数据同步时一键生成表
生命周期指的是数据的周期而非表的周期
开发环境运行测试
离线数据采集底层就是用datax,经过封装的
开发环境的表是测试运行后就有数据了,在数据地图中是能查到的,而生产环境中的表是提交任务上线后才能看到数据
发布到生产环境的数据是很敏感的,多次按钮避免误操作
提交 发布 发布包 调度配置 资源组
4.2 dwd层
进行过滤,脱敏,处理
新建sql,基于源表构建dwd层的表
日期类型的处理:见笔记
deal_date>=CONCAT(from_unixtime(unix_timestamp(
b
i
z
d
a
t
e
,
′
y
y
y
y
M
M
d
d
′
)
,
′
y
y
y
y
−
M
M
−
d
d
′
)
,
′
06
:
14
:
0
0
′
)
d
e
a
l
d
a
t
e
<
=
C
O
N
C
A
T
(
f
r
o
m
u
n
i
x
t
i
m
e
(
u
n
i
x
t
i
m
e
s
t
a
m
p
(
{bizdate},'yyyyMMdd'),'yyyy-MM-dd'),' 06:14:00') deal_date<=CONCAT(from_unixtime(unix_timestamp(
bizdate,′yyyyMMdd′),′yyyy−MM−dd′),′06:14:00′)dealdate<=CONCAT(fromunixtime(unixtimestamp({bizdate},‘yyyyMMdd’),‘yyyy-MM-dd’),’ 23:59:00’)
from_unixtime unix_timestamp这两个日期函数是区分大小写的
而且使用的是hive中的函数,需要提前使用前开启一次支持 set odps.sql.hive.compatible=true
传入的参数格式为yyyyMMdd的,所以先识别年月日后再转为时间戳类型,然后转为对应的带-的格式,拼接上空格和时间,然后进行where条件过滤
根据事件时间增量同步
新建dwd层的表,根据时间等条件过滤后导入新表,注意哦:ods层是表中是没有pt字段的,如果使用select * 查询的话会导致字段对应不上,因为dwd层的建表字段是没有pt字段的
FAILED: ODPS-0130071:[1,24] Semantic analysis exception - wrong columns count 12 in data source, requires 11 columns (includes dynamic partitions if any)
注意上调度的时机,此时这张表只在开发环境中有,生产环境中还没有,我们先把将表提交到生产环境中去,然后在将任务上调度
提交 执行开发环境的任务
发布 执行生产环境的任务此时不会再执行开发环境的任务
任务下线需要先下线生产环境的任务再下线开发环境中的任务
4.3 构建事实宽表 dws
地铁出入站宽表 一个人一天的进出站数据集合到一张表中
按照卡号进行聚合,行的多转一
不仅仅是字段多,而且一个字段可以合并成一个数组,数据量也很大
合并成一个字段数据 collect_set (去重) collect_list (不去重)
dataworks不分内外部表,也不需要关注存储路径,我们只需要关注建表即可,底层是按列压缩
4.4 指标统计 dim
线路单日运送乘客总次数排行榜
先交流好业务,地铁有中转站,是否认定为一个人次?
select * fro,
select company_name,
sum(case when deal_type='地铁入站'or (deal_type='地铁出战')and
conn_mark='1') then 1 else 0)
from
dwd___
where pt=${bizdate}
group by company_name;
sum函数内搭配case when进行统计,count也可以搭配这个case when
区别在于,sum更加灵活,可以对字段进行求和,累加值也可以更改
避免多次子查询,关联合并的操作
统计车站区间之间的总人数排行
1.面对这个需求,先将单个人的单日进出站数据进行观察,根据时间排序,上次入这次出说明是一次乘车,上次出这次入说明是两次乘车,所以我用到lag函数
进行开窗,然后将每个人每天的每次进出站的信息汇聚成一行,一目了然
根据这个再进行计数变简单很多
2.取出本次为出站,last_type为入站的数据
select * from
(
select
card_no,
station,
deal_type,
deal_date,
LAG(deal_type,1,null) over (partition by card_no order by deal_date) as last_type
FROM dwd_fact_szt_in_out_detail
WHERE pt = max_pt('dwd_fact_szt_in_out_detail')
AND card_no = 'AEAAACBHI'
) as a
where deal_type='地铁出战' and last_type='地铁入站';
3.同样的函数我们利用lag函数取到新的字段,上次进站站点
lag(station,1,null) over (partition by card_no order by deal_type) as in_station
4.利用concat函数进行连接,组成需求中的标识
concat(in_station,'->',station) as short_station
5.进出站站点为空的要过滤掉
6.根据线路区间 short_station 进行分组后进行统计 count(a) as `cou nt`
7.加上排名字段 row_number() over(order by `count`)
线程单程直达乘客耗时平均值排行榜
指标拆分:
派生指标=原子指标+统计周期+统计维度+业务限定
线程单程直达乘客耗时平均值排行榜=通勤时间+每天+线路+单程直达
1.取字段 公司名称 平均值
2.直达 联程标识为0
3. 使时间函数之前要开启一个函数支持 set odps.sql.type.sustem.deps2=false
4. 同样要确定进出站,使用lag函数得到上一条数据
lag(deal_type,1,null) over(partition by card_no order by deal_date) as in_deal_date
日期函数 datediff(end,start,'ss') 结束时间减去开始时间,设置计量单位
5.得到这个结果 avg(datediff(deal_date,in_deal_date,'mi')) as avg_time
每日运输乘客最多的车站区间排行榜
5. 面试点
- 如何使用hive构建数据仓库的?
- 工具之间的区别?先分别描述(是什么,做什么的,优缺点),再尽量找区别
- hive和DataWorks之间的区别?
数据仓库构建工具之一,传入一条sql在海量数据中进行查询
DataWorks是集数据采集,计算运维等一体的数据中台的产品 - 一堆组件和工具搭配起来使用















 4858
4858











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









