






写在前面
笔记内容是根据B站上面的一位老师的视频而记录了,因为我也还在学习,所以个人理解可能会出现错误,若有错误请指出。另外这篇文章会很长
B站视频连接
环境准备
这个参考另外一篇博客 python+pycharm+anconda环境搭建
我这里虽然装了jupyter notebook,但是我还是以pycharm为主
numpy常见函数详解
array
numpy.array(object,dtype=None,copy=True,order=None,subok=False,ndmin=0)
各个参数的作用
| 参数名称 | 可选否 | 作用 |
|---|---|---|
| object | 必选 | 表示一个序列,只要是序列都可以 |
| dtype | 可选 | 可以更改数组的数据类型 |
| copy | 可选 | 当数据源是ndarray时表示数组能否被复制,默认为True |
| order | 可选 | 以哪种内存布局创建数组在C(行序列),F(列序列),A(默认)中选择 |
| ndmin | 可选 | 用来指定数组的维度 |
| subok | 可选 | 类型:bool,默认:False,为True使用object的内部数据类型,False使用object数组的数据类型 |
例子
# 最简单的一种
a=np.array([1,2,3,'1',(1,2)],dtype=object) #想表达的意思是,元素数据类型可以不一致,不一致强制转换为一维的
#copy的用法
b=np.array(a,copy=False)# copy=False,不会生成副本,就是说改变a的同时也会改变b
# ndmin的作用,就是加一个[]
np.array([1,2,3,4],ndmin=2) #最后的结果是[[1 2 3 4]]
# subok的作用
c=np.mat([1,2])
d=np.array(c,subok=True) # 就是c的数据类型 numpy.matrix
d=np.array(c,subok=False)# 就是c里面的数据类型:numpy.ndarray
# 其余的参数,老师说用的不是很多,不再详细解释
arange
numpy.arange(start,end,step,dtype)
- start:起始值
- end:终止值 到不了end
- step:步长
np.arange(4) 生成[0,1,2,3]这个列表
np.arange(1,3) 生成[1,2]这个列表,到不了3
np.arange(1,10,2)生成[1,3,5,7,9]没了
可以指定赋值
np.arange(15,21,step=5) 生成[15,20]
linspace和logspace
前者是构造等差数列,后者是构造等比数列
linspace(start,stop,num,endpoint,retstep,dtype)
| 参数 可选否 | 说明 | |
|---|---|---|
| start | 必选 | 等差数列的首项 |
| stop | 必选 | 终止值,到不了 |
| num | 可选 | 把start,stop之间的数据划分num份,默认为50 |
| endpoint | 可选 | 为True包含终止值,反之不包含 |
| restep | 可选 | 为True显示步长,为False,不显示步长 |
| dtype | 可选 | 指定数据类型的 |
logspace(start,stop,num,endpoint=True,base=1)
和linspace差不多,唯一不同的就是base,这个的意思就是指数函数y=a^x的a,好像是底数,忘了哈
例子
np.linspace(1,10,num=10,endpoint=True) 生成[ 1. 2. 3. 4. 5. 6. 7. 8. 9. 10.]
np.logspace(0,8,num=9,endpoint=True,base=2)生成[ 1. 2. 4. 8. 16. 32. 64. 128. 256.]
zeros和ones
这两个比较简单哈,就直接举一个例子了
np.zeros(5)生成5个元素全为0的列表(一维)
np.zeros((2,2))生成4个元素全为0的列表(二维,两行两列)
np.zeros_like([
[1,2,3],[4,5,6]
]) 生成两行三列的列表(二维)
ones和上面的一样,ones是生成全部都为1的序列的
mean
取平均值,axis=0时,计算各个列的平均值,axis=1时,计算各个行的平均值
例子 nums=np.arange(20).reshape((4,5))
nums.mean() 结果是9.5
np.mean(nums,axis=0) 结果是[ 7.5 8.5 9.5 10.5 11.5]
median
计算中位数的 np.median(nums)
std
计算标准差的,这个是反应离散程度的
np.std(nums)
max和min和sum
就是字面意思
average
加权平均值
举一个例子,期末成绩等于平时成绩0.2+期中成绩0.3+期末成绩*0.5
scores=np.array([80,90,95]
np.average(scores,weights=[.2,.3.5])
属性操作
a=np.array([1,2])
b=np.array([[1,2,],[3,4]]
c=np.array([[[1,2,3],[4,5,6]]]
| 函数/属性 | 描述 | 例子 |
|---|---|---|
| shape | 根据维度返回对应的 | shape:如果是三维则返回块数,行数,列数,如果是二维,返回行数,列数,如果是一维,返回行数. a的shape是(1,),b的shape是(2,2) c的shape是(2,2,3) |
| ndmin | 返回维度 | a的ndmin:1 b的是2,c的是3 |
| reshape | 调整维度,不影响元数据,元素不够了会报错 | np.arange(20).reshape((4,5)) |
| resize | 改变形状,影响元数据,用原来的元素来填充给 | a=np.array([[1,2],[3,4]]) b=np.resize(a,(2,3))#23>22 |
| astype | 改变数据类型的,不影响元数据 | a=np.array([1,2]).astype(‘float32’) |
| itemsize | 每一个元素所占的字节大小 | a.itemsize |
unique
numpy.unique(arr, return_index, return_inverse, return_counts)
| 参数 | 说明 |
|---|---|
| arr | 输入数组(如果是多维数组以一维数组形式展开) |
| return_index | 为True,则返回新数组元素在原数组中的位置(索引) |
| return_inverse | 为True,则返回原数组元素在新数组中的位置(索引) |
| return_counts | 为True,则返回去重后的数组元素在原数组中出现的次数 |
a = np.array([5, 2, 6, 2, 7, 5, 6, 8, 2, 9])
uq=np.unique(a)
uq,index=np.unique(a,return_index=True) #返回元素在原数组的索引
print(uq,index) #[2 5 6 7 8 9] [1 0 2 4 7 9] uq,index=np.unique(a,return_inverse=True) #返回元素在新数组的索引
print(uq,index) # [2 5 6 7 8 9] [1 0 2 0 3 1 2 4 0 5]
uq,index=np.unique(a,return_counts=True) #返回元素出现的个数
print(uq,index) # [2 5 6 7 8 9] [3 2 2 1 1 1]
sort
sort(a,axis,kind,order)
| 参数名称 | 说明 |
|---|---|
| a | 要排序的数组 |
| axis | 沿着指定轴进行排序,若无则在最后一个轴上排序,0则按照列排序,1按照行排序 |
| kind | 默认为quicksort |
| order | 若设置了字段,则order表示要排序的字段 |
a=np.array([[3,7,5],[6,1,4]])
print(np.sort(a)) /*[[3 5 7] [1 4 6] */
print(np.sort(a,axis=0))#按列排序 [[3 1 4] [ 6 7 5]]
print(np.sort(a,axis=1))#按行排序 [[3 5 7] [ 1 4 6]]
#设置在sort函数中排序字段
dt = np.dtype([('name', 'S10'),('age', int)])
a = np.array([("raju",21),("anil",25),("ravi", 17), ("amar",27)], dtype = dt)
#再次打印a数组
# print(a)
# print('--'*10)
#按name字段排序
# print(np.sort(a, order='name'))
a=np.array([90,29,89,12])
sort_index=np.argsort(a)
print('sort_index:',sort_index) # [3 1 2 0]
print(a[sort_index])# [12 29 89 90]
argwhere(condition)
这个很简单
a=np.arange(6).reshape((2,3))
# numpy.argwhere([condition]) condition不写就是返回非0元素的索引
# 函数返回数组中非 0 元素的索引,若是多维数组则返回行、列索引组成的索引坐标。
# print(np.argwhere(a>1)) #返回大于1的索引
切片操作
Tips:对切片操作切出来的列表进行赋值操作,会影响到原来的列表
a=[0,1,2,3,4,5,6,7]
b=[[0,1,2],[3,4,5],[6,7,8],[9,10,11]]
a[1:] 从索引值1开始到最后,也就是[1,2,3,4,5,6,7]
a[1:3]从索引值1开始到2,因为到不了3,也就是[1,2]
a[::]全切
a[1:6:3] 从1开始到5,步长为3 即[1,4]
a[::-1] 到着取
a[:-2] 取到倒数第二个(不含)
多维数组操作
b[…,1] 只要第一列的数据
b[…,1:]只要第二列后的所有数据
b[1,1]只要第2行第2列的数据
b[…][1]返回第二列后的数据
数组作为下标
x=np.array([[1,2],[3,4],[5,6]])
y=x[[0,1,2],[0,1,0]]
# 等同于[x[0,0],x[1,1],x[2,0]]
b=np.array([
[0,1,2],
[3,4,5],
[6,7,8],
[9,10,11]
])
a=np.array(b[[0,0,3,3],[0,2,0,2]]).reshape((2,2))
# print(a)
# 等同于b[0,0] b[0,2],b[3,0],b[3,2]
a=np.array([[1,2,3],[4,5,6],[7,8,9]])
b=a[1:3,1:3]#行取第二行与第三行,列取第一列与第二列
c=a[...,1:]#取所有行,列取第二列以后的
布尔数组索引
x=np.array([[0,1,2,3],[4,5,6,7],[8,9,10,11]])
# print(x[x>6]) # 筛出比6大的元素的值 最终结果是一维的
# x[x%2==0]=-1
# print(x) 多条件&|
# print(x[(x>4)&(x<9)])
# print(x[(x<4) | (x>9)])
print(x[[0,-1],:][:,[0,2,3]])
x=np.arange(12).reshape((3,4))
temp=np.array([False,True,True]) #行坐标,因为该列表元素的个数与行数匹配
print(x[temp])# True为要取出的,反之不取出
temp=np.array([True,False,True,False]) #列坐标,因为该列表元素的个数与列数匹配
print(x[:,temp])
随机函数
都是在random下面
| 函数 | 说明 | 例子 |
|---|---|---|
| rand([n]) | 返回0~1之间的数,n产生随机数的个数,不写就是1 | np.random.rand(1) |
| randn(n) | 返回符合正态分布的 均值为0,1为标准的 n是随机数的个数 | np.random.randn(1) |
| randint(low,high,size,dtype) | 这个看例子,size就是返回的形状,如果是(2,2)就是返回两行两列的随机数,不写就是1 | 只有一个参数就是返回[0~low)之间的,两个就是返回[low,high)之间的 三个就是返回满足size的且在[low,high)之间的随机数,例如:np.random.randint(2,9,(2,2)) |
| sample(size) | 返回符合size的在0~1之间随机数列表 | np.random.sample((1,2)) |
| normal(loc,scale,size) | 返回符合该正太分布的随机数 这里的loc就是μ,scale就是那个长得像6一样的 μ决定对称轴的位置,scale越大,数据不稳定,反之稳定 | np.random.normal(1,3,(2,2)) |
对文件的一些操作
这个通过例子来记录
data.csv的内容
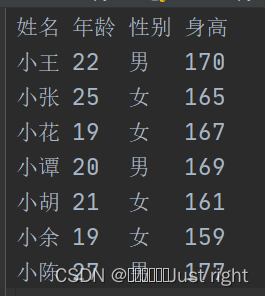
读取的内容默认会转换成float类型,
loadtxt参数说明
| 参数名称 | 作用 |
|---|---|
| fname | 文件的路径 或者字符串 |
| dtype | 数据类型默认就是float |
| comments | 表示注释字符集开始的标志,默认为# |
| delimiter | 字符串分割符号 |
| converters | 字典,将特定列的数据转换为字典中对应的浮点型数据 |
| skiprows | 跳过特定行数据,默认为0 |
| usecol | 元组,指定要读取的数据列,第一列为0,默认为空 |
| encoding | 指定编码 |
# data=np.loadtxt('../data.txt',dtype=np.int0)
#默认是浮点型
people=np.dtype([('姓名',np.str_,8),('年龄',np.int0),('性别',np.str_,3),('身高',np.int0)])
# data=np.loadtxt('../data.csv',encoding='utf-8',skiprows=1,dtype=people)
#只要年龄
# data=np.loadtxt('../data.csv',encoding='utf-8',skiprows=1,usecols=(1,)) #只取第二列
# data=np.loadtxt('../data.csv',encoding='utf-8',skiprows=1,dtype=people) #只取第二列
# print(np.mean(data['年龄']))
# print(np.median(data['年龄']))
data = np.loadtxt('../data.csv',dtype=people,encoding='utf-8',skiprows=1)
isgirl = data['性别']=='女'
print("女生的平均身高为:{:.2f}".format(float(np.mean(data[isgirl]['身高']))))
print('男生的平均身高为:{:.2f}'.format(float(np.mean(data[isgirl]['身高']))))
matplotlib画图库的常见函数
matplotlib的基本方法
| 函数名称 | 说明 | 例子 |
|---|---|---|
| title(name) | 设置图标的名称 | plt.title(“画图程序1”) |
| xlabel(text) | 设置x轴名称 | plt.xlabel(‘x轴’) |
| ylabel(text) | 设置y轴名称 | plt.ylabel(‘y轴’) |
| xticks(ticks,label,rotation) | 设置x轴的刻度(ticks),显示文本(text),旋转角度(rotation) | plt.xticks(ticks,label,rotation=45) 这个看下面的代码 |
| yticks() | 设置y轴的刻度 | 这个看下面的代码 |
| show() | 显示图表 | plt.show() |
| legend() | 显示图例 | plt.legend() |
| text(x,y,text) | 显示每条数据的值 x,y值的位置 | plt.text(1,10,10) |
中文,负号不显示的问题
plt.rcParams['font.sans-serif']=['SimHei'] #设置字体,处理中文的问题
plt.rcParams['axes.unicode_minus']=False #解决负号的问题
字体如下表
| 中文字体 | 说明 |
|---|---|
| ’SimHei‘ | 中文黑体 |
| ‘Kaiti’ | 中文楷体 |
| ‘LiSu’ | 中文隶书 |
| ‘FangSong’ | 中文仿宋 |
| ‘YouYuan’ | 中文幼圆 |
| ’STSong’ | 华文宋体 |
一些配置的东西 比如分辨率
| 欲达成的效果 | 操作 |
|---|---|
| 设置画布的大小 | plt.rcParams[‘figure.figsize’]=(8.0,4.0) 这个8是英寸 |
| 设置分辨率 | plt.rcParams[‘figure.dpi’] = 300 |
| 设置尺寸 |
柱状图
高度与其表示的数值成正比关系
bar(x, height, width: float = 0.8, bottom = None, *, align: str = ‘center’, data = None, **kwargs)
| 参数 | 说明 |
|---|---|
| x | 表示x轴坐标,类型float |
| height | 就是y轴的值 |
| width | 柱状图的宽度,在[0~1]之间,默认是0.8 |
| bottom | 柱状图的起始位置,默认为None |
| align | 柱状图中心位置 ‘center’,‘lede’,默认为’center’ |
| color | 柱状图颜色,默认为蓝色 |
| alpha | 透明度,取值在0~1之间,默认为1 |
| label标签 | 需要调用legend()生成 |
| edgecolor | 边框颜色 缩写:ec |
| linewidth | 边框宽度 默认为为none,缩写为:lw |
| tick_label | 柱子的刻度标签,字符串或者字符串列表,默认值为None |
| linestyle | 线条样式.缩写为ls |
bottom参数的例子
import matplotlib.pyplot as plt
x = range(5)
data = [5, 20, 15, 25, 10]
plt.title("基本柱状图")
# bottom 就是从y轴的那里开始画
plt.bar(x, data, bottom=[10, 20, 5, 0, 10])
plt.show()
效果图不做展示
垂直同位置多柱状图
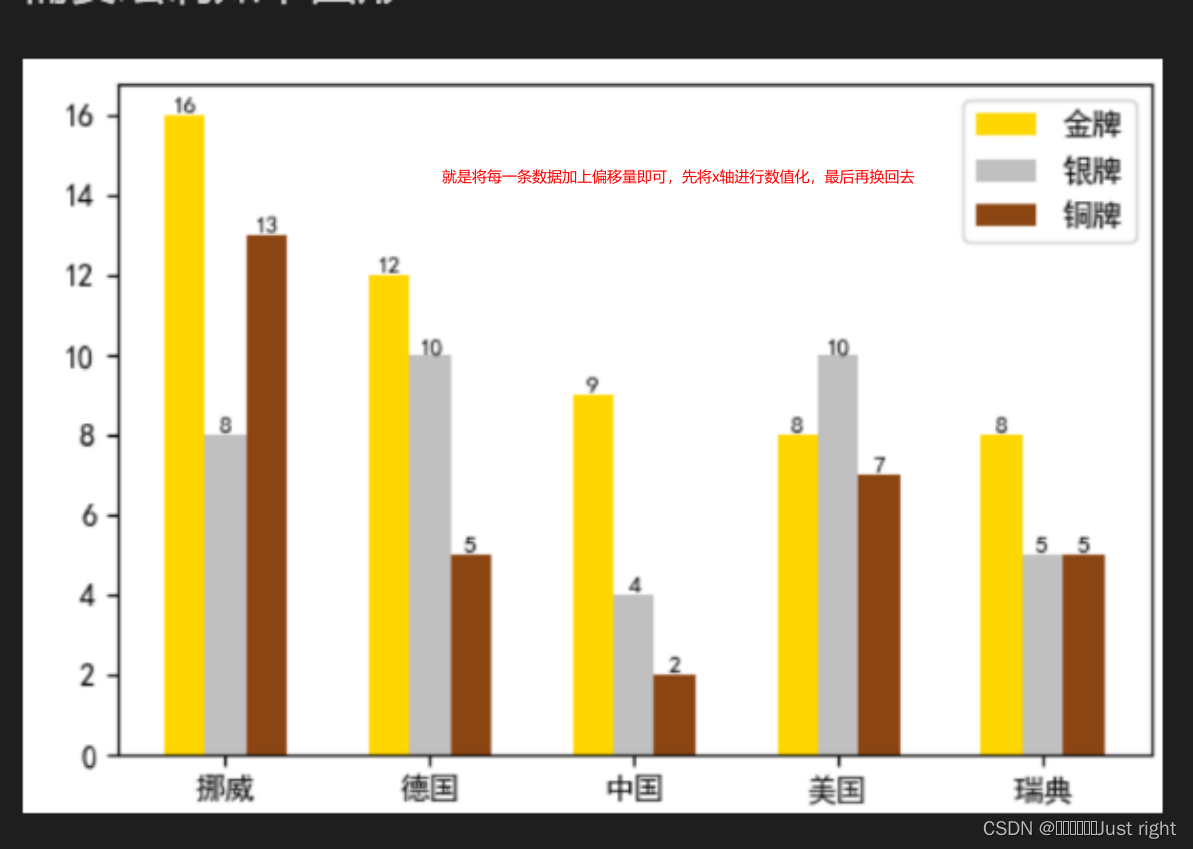
from matplotlib import pyplot as plt
import numpy as np
# 国家
countries = ['挪威', '德国', '中国', '美国', '瑞典']
# 金牌个数
gold_medal = [16, 12, 9, 8, 8]
# 银牌个数
silver_medal = [8, 10, 4, 10, 5]
# 铜牌个数
bronze_medal = [13, 5, 2, 7, 5]
x = np.arange(len(countries))
gold = x
silver=x + 0.2
bronze = x + 0.4
plt.bar(gold,gold_medal,width=0.2)
plt.bar(silver,silver_medal,width=0.2)
plt.bar(bronze,bronze_medal,width=0.2)
plt.xticks(x+0.2,labels=countries)
# 显示高度文本
for i in range(len(countries)):
plt.text(gold[i],gold_medal[i],gold_medal[i],ve='bottom',ha='center')
plt.text(silver[i],silver_medal[i],silver_medal[i],ve='bottom',ha='center')
plt.text(bronze[i],bronze_medal[i],bronze_medal[i],ve='bottom',ha='center')
水平堆叠柱状图
先看效果图,这个就是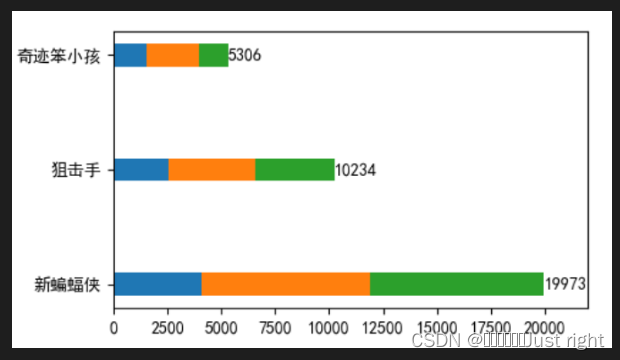
这个需要学习一个函数
plt.barh(y, width, height=0.8, left=None, *, align='center', **kwargs)
这个我就不说明了,看英文字面意思了
看例子,前面的那个搞懂了,这个也差不多,走个过程
分析:就是需要确定图形距离左侧的位置(left参数)
movie = ['新蝙蝠侠', '狙击手', '奇迹笨小孩']
# 第一天
real_day1 = np.array( [4053, 2548, 1543])
# 第二天
real_day2 = np.array([7840, 4013, 2421])
# 第三天
real_day3 = np.array([8080, 3673, 1342])
day2 = real_day1
day3 = real_day1 + real_day2
plt.barh(movie,real_day1,height=0.2)
plt.barh(movie,day2,height=0.2)
plt.barh(movie,day3,height=0.2)
plt.xticks(range(len(movie)),labels=movie)
result = real_day1+real_day2+real_day3
for i in range(len(countries)):
plt.text(result[i],movie[i],result[i],va='center',ha='left')
plt.xlim(0,result.max()+2000)
plt.show()
水平同位置柱状图
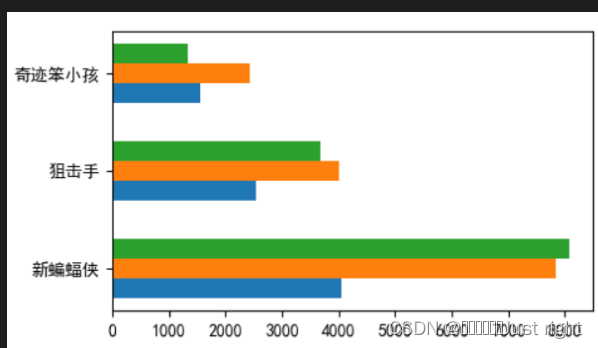
movie = ['新蝙蝠侠', '狙击手', '奇迹笨小孩']
# 第一天
real_day1 = np.array( [4053, 2548, 1543])
# 第二天
real_day2 = np.array([7840, 4013, 2421])
# 第三天
real_day3 = np.array([8080, 3673, 1342])
y = np.arange(len(movie))
height = 0.2
movie1_y = y
movie2_y = y + 0.2
movie3_y = y + 0.4
plt.barh(movie1_y,real_day1,height=0.2)
plt.barh(movie2_y,real_day2,height=0.2)
plt.barh(movie3_y,real_day3,height=0.2)
plt.yticks(y + 0.2,labels=movie)
plt.show()
颜色设置
直接在bar中加facecolor='颜色’即可 这种只能设置一种颜色
多种颜色设置就是使用color参数
如 plt.bar(x,data,color=[‘r’,‘g’,‘b’]
折线图
易于显示数据变化趋势,以及变化幅度,可以直观地反映这种变化以及各组之间的差别
plt.plot(x,y,color=‘red’,alpha=0.3,linestyle=‘-’,linewidth=5,marker=‘o’,markeredgecolor=‘r’,markersize=‘20’,markeredgewidth=10)
| 参数 | 说明 |
|---|---|
| color | 颜色,下面会详细说明,这个参数有点多 |
| alpha | 透明度,0~1,0:完全透明,1完全不透明 |
| linestyle | 折线样式 |
| marker | 标记点 |
color参数的设置
| 字符 | 颜色 | 英文全称 |
|---|---|---|
| ‘b’ | 蓝色 | blue |
| ‘g’ | 绿色 | green |
| ‘r’ | 红色 | red |
| ‘c’ | 青色 | cyan |
| ;‘m’ | 品红 | magenta |
| ‘y’ | 黄色 | yellow |
| ‘k’ | 黑色 | black |
| ‘w’ | 白色 | white |
linestyle的设置
| 字符 | 描述 |
|---|---|
| ’-‘ | 实线 |
| ‘–’ | 虚线 |
| ‘-.’ | 点划线 |
| ‘:’ | 虚线 |
marker的设置
| 符号 | 描述 |
|---|---|
| ’.’ | 点标记 |
| ‘o’ | 圆圈标记 |
| ‘x’ | x标记 |
| ‘D’ | 钻石标记 |
| ‘H’ | 六角标记 |
| ‘s’ | 正方形标记 |
| ‘+’ | 加号标记 |
直方图
这个柱子之间没有间隔
这个函数参数有很多,我就只写几个常用的
plt.hist(x,bins,weight,bottom,histtype,align,color,edgecolor,alpha)
| 参数 | 说明 |
|---|---|
| x | 就是数据,可以是多维,多维先进行展开 |
| bins | 直方图的柱数,默认为10 |
| weights | 如果有权重就带上这个参数,权重数组必须与x的元素个数一样 |
| bottom | 相对于y=0的位置 |
| histtype | 从bar(条形直方图),barstacked(堆叠的),step(未填充的),stepfilled(填充的) 进行选择 |
| align | 对齐方式 left,mid,right |
| color | 颜色,可以传递一个数组 |
| edgecolor,alpha | 边框颜色,透明度:0(完全透明)~1(完全不透明) |
该函数有返回值
| 返回值 | 说明 |
|---|---|
| n | 数组或数组列表,也就是直方图的值 |
| bins | 数组,返回各个bin的区间范围(起始值) |
| patches | 返回bin里面包含的数据 |
绘制折线直方图
fig,ax = plt.subplots()
num, bins, patches = plt.hist(x, bins=10, edgecolor='white')
# len(num) = 10 len(bins) = 11
ax.plot(bins,np.append(num,num[-1]),marker='o')
plt.xticks(bins,rotation=45)
plt.show()
不等距分组
不等距分组
fig,ax = plt.subplots()
x = np.random.normal(100,200,100)
bins = [40,50,60,70,100,120,140,160]
ax.hist(x,bins=bins,color='c')
ax.set_title("不等距分组")
plt.show()
多个数据
# 生成多个数据
fig,ax = plt.subplots()
# [array(1000),array(5000),] 就是二维数组里面套了三个一维数组,就是二维数组
xs=[np.random.randn(n) for n in [1000,5000,2000]]
ax.hist(xs,10,label=list('ABC'))
ax.set_title("多类型直方图")
plt.show()
堆叠直方图
# 堆叠直方图
x1 = np.random.randint(140,200,300)
x2 = np.random.randint(140,200,300)
# 不是一维数组的时候展开变成一维数组 stacked=True允许数据覆盖
plt.hist([x1,x2],bins=10,stacked=True)
plt.show()
饼状图
pyplot.pie(x, explode=None, labels=None, colors=None, autopct=None)
| 参数 | 说明 |
|---|---|
| x | 数组序列,就是数据 |
| labels | 为每个扇形区域备注一个标签名字 |
| colors | 可以是列表,设置颜色的 |
| autopact | 就是设置百分比的,保留几位小数 格式:‘%.小保留的小数点位数%%’ |
| pctdistance | 设置百分比标签与圆心的距离 |
| labeldistance | 设置各扇形标签(图例)与圆心的距离 |
| explode | 指定某些部分的突出显示 |
| shadow | 为True添加阴影,反之不添加 |
labels=['娱乐','育儿','饮食','房贷','交通','其他']
x = [200,500,1200,7000,200,900]
explode=(0.03,0.05,0.06,0.04,0.08,0.09)
# label是标签,autopct是显示百分比(保留2位小数)
# plt.pie(x,labels=labels,autopct='%.2f%%',explode=(0.03,0.05,0.06,0.04,0.08,0.09))
# labeldistance:设置各扇形标签(图例)与圆心的距离
# pctdistance:设置百分比标签与圆心的距离
#
plt.pie(x, labels=labels, autopct='%3.2f%%', explode=explode, labeldistance=0.5, pctdistance=0.85)
plt.legend()
plt.show()
线条样式缩写
颜色 标记 样式
plt.plot([1,2,3],[4,7,6],‘r*-.’)
plt.xlabel("x 轴", fontsize=15)#设置x轴的名称 设置字号(fontsize)
plt.ylabel("y 轴", fontsize=15)#设置y轴的名称
times=['2015/6/26', '2015/8/1', '2015/9/6', '2015/10/12', '2015/11/17','2015/12/23','2016/1/28','2016/3/4','2016/4/9',
'2016/5/15','2016/6/20','2016/7/26','2016/8/31','2016/10/6','2016/11/11','2016/12/17']
# 随机生成收入
income=np.random.randint(500,2000,size=len(times))
# 随机生成支出
expenses=np.random.randint(300,1500,size=len(times))
# # xticks 第一个参数中元素的值,代表原始数据的索引 labels表示显示的文本 第一个参数与labels的元素必须相同
plt.xticks(range(1,len(income),2),rotation=45,labels=['日期:%s'%times[i] for i in range(1,len(income),2]))
plt.plot(times,income,label="收入") # 这里的label是控制图例的文字的
plt.plot(times,expenses,label="支出")
texts=zip(times,income) # 将两个列表压缩成一个元组
texts1=zip(times,expenses)
# 下面的操作是将值标注上去,这个方法不是很好
a=True
for x,y in texts:
for a,b in texts1:
plt.text(a,b,'%s元'%y)
if not a:
break
plt.text(x,y,'%s元'%y)
a=False
plt.legend(loc="upper right") #采用label作为图例的名称 loc是控制图例的位置的
plt.show()
散点图
这个了解下
matplotlib.pyplot.scatter(x, y, s=None, c=None, marker=None, cmap=None, norm=None, vmin=None, vmax=None, alpha=None, linewidths=None, *, edgecolors=None, plotnonfinite=False, data=None, **kwargs)
x,y是输入参数,s是散点的面积,c是散点的颜色,marker是散点样式,alpha 散点透明度[0,1]
linewidths:散点的边缘线宽,edgecolors:散点的边缘颜色
x = np.array([1, 2, 3, 4, 5, 6, 7, 8])
y = np.array([1, 4, 9, 16, 7, 11, 23, 18])
s = (20 * np.random.rand(8))**2
# s是散点的面积 alpha 0 完全透明 1 完全不透明
# plt.scatter(x, y, s, alpha=0.4)
# 如果只需要3种颜色
# colors = np.resize(np.array([1,2,3]),100)
colors = np.random.rand(8)
# plt.scatter(x,y,s,c=colors)
# 也可以使用cmap virdis | plasma | inferno | magma | cividis
plt.scatter(x, y, s, c=colors, cmap='cividis')
if not os.path.exists("test"):
os.mkdir("my")
plt.savefig('my/first.jpg')
plt.show()
涉及到的零碎的知识点
cmap是颜色条

词云图
需要先安装wordcloud,jieba
pip install wordcloud
pip install jieba
WordCloud(font_path,background_color,width,height,max_words).generate(txt)
font_path是字体路径,如果是中文就需要指明路径
windows的字体路径:C:/Windows/Fonts
background_color:背景颜色
width,height:宽高
max_words:词语的个数
txt:文本数据
结合jieba库来进行
def demo():
txt = open("../data/新蝙蝠侠评论.txt",encoding='utf-8').read()
txt_cut = jieba.analyse.extract_tags(txt,topK=100,allowPOS=("a"))
txt = ' '.join(txt_cut)
wordcloud = WordCloud(font_path="C:/Windows/Fonts/simfang.ttf",
collocations=False,
background_color="black",
width=1200,
height=600,
max_words=100).generate(txt)
# 生成图片
image = wordcloud.to_image()
# 展示图片
image.show()
# 写入文件
wordcloud.to_file("新蝙蝠侠评论.jpg")
箱线图
这个了解一下,以后再写
碰到的错误
ValueError: The number of FixedLocator locations (8), usually from a call to set_ticks, does not match the number of ticklabels (5).
出现原因:ticks与label的元素个数不一致
解决办法:让他们变成一致
创建图形对象
说白了就是看一下figure这个方法的用法
plt.figure(num=None,figsize=None,dpi=None,facecolor=None,edgecolor=None,frameon=True)
什么都不写,直接plt.figure()也是可以的
| 参数 | 说明 |
|---|---|
| num | 图像编号或者名称,若是数值就是编号,字符串就是名称,就是每次弹出来了那个窗口的标题 |
| figsize | 指定figure的宽和高,单位为英寸 |
| dpi | 分辨率,默认就是72 |
| facecolor | 背景颜色 |
| edgecolor | 边框颜色 |
| frameon | 为True显示边框,反之不显示边框 |
from matplotlib import pyplot as plt
# 创建图形对象即画布
fig = plt.figure() # 这样也可以
fig = plt.figure('f1',figsize=(3,2),dpi=100,facecolor='gray')
绘制多子图
先来弄清楚一个问题,figure是一个绘制对象,就是一个空白的画布,这个画布上有很多区域(axes),我们画图的时候是在axes上面进行操作的
区域基本函数地使用
就几个东西,
set_title(),设置区域图标名称地
set_xlabel() set_ylabel 设置x轴与y轴地名称地
set_xticks() 设置刻度的
legend() 显示图例的
add_axes()
由于这个我不是很懂,我就写的比较粗略点
add_axes(rect)
用来生成一个axes轴对象
rect是位置参数,接受一个由4个元素组成地浮点数列表,形如[left,bottom,width,heigh]都是百分比left是距离真正地左边地距离,bottom同理,width与heigh地值是占画布地多少百分比
如:[ 0.2, 0.2, 0.5, 0.6],它代表着从画布 20% 的位置开始绘制, 宽度是画布地50%,高度是画布的 60%
看例子吧
fig = plt.figure(figsize=(4,2),facecolor='g')
# ax1从画布起始位置绘制,宽高和画布一致
ax1=fig.add_axes([0,0,1,1])
# ax2 从画布 20% 的位置开始绘制, 宽高是画布的 50%
#ax2=fig.add_axes([0.2,0.2,0.5,0.5])
#ax2=fig.add_axes([0.5,0.5,0.5,0.5])
ax2=fig.add_axes([0.1,0.6,0.3,0.3])
ax3=fig.add_axes([0.5,0.6,0.2,0.3])
ax1.plot(x, y)
ax2.plot(x, y)
ax3.plot(x, y)
plt.show()
subplot()
这个只创建了一个包含子图区域的画布
ax = plt.subplot(nrows, ncols, index,*args, **kwargs)
| 参数名称 | 说明 |
|---|---|
| nrows | 行 |
| ncols | 列 |
| index | 索引,注意这里从1开始 |
| kwargs:title/xlabel等 | 设置标题,x轴等 |
也可以写成subplot(233),意思就是将画布分成2行3列,当前区域在第三个位置
如果新建的子图与现有的子图重叠,重叠部分会自动删除,如果不想共享的部分删除,就需要再创建一个画布
fig=plt.figure(figsize=(3,2))
fig.add_subplot(111)
plt.plot(range(20))
fig.add_subplot(211)
plt.plot(range(13))
设置区域的一些信息
第一种方法
plt.subplot(211,title='first',xlabel='x轴')
plt.plot(range(10,20))# x轴可以省略,默认是[0,1...,n-1]递增
plt.subplot(212,title='second',xlabel='x轴')
plt.plot(np.arange(12)**2)
子标题重叠:
plt.tight_layout()就行了,这个需要放到最后
第二种方法
#现在创建一个子图,它表示一个有2行1列的网格的顶部图。
#--------------- 第一个区域---------------
plt.subplot(211)
# 使用图形对象:
plt.title("ax1")
# x可省略,默认[0,1..,N-1]递增
plt.plot(range(50,70))
#--------------------第二区域-----------
plt.subplot(212)
plt.title("ax2")
plt.plot(np.arange(12)**2)
# 紧凑的布局
plt.tight_layout()
第三种
#现在创建一个子图,它表示一个有2行1列的网格的顶部图。
#--------------- 第一个区域 ax1---------------
ax1 = plt.subplot(211)
# 使用区域对象:
ax1.set_title("ax1")
# x可省略,默认[0,1..,N-1]递增
ax1.plot(range(50,70))
#--------------------第二区域 ax2-----------
ax2 = plt.subplot(212)
ax2.set_title("ax2")
ax2.plot(np.arange(12)**2)
# 紧凑的布局
plt.tight_layout()
subplots()
这个创建了以恶搞包含子图区域的画布,又创建了一个figure图形对象
fig,ax = plt.subplots(nrows,ncols)
nrows和ncols分别指定行数和列数,每个axes对象可以提供过索引值进行访问
# 创建2行2列的子图,返回图形对象(画布),所有子图的坐标轴
fig, axes = plt.subplots(2,2)
x = np.arange(1,5)
#绘制平方函数
axes[0][0].plot(x, x*x)
axes[0][0].set_title('square')
#绘制平方根图像
axes[0][1].plot(x, np.sqrt(x))
axes[0][1].set_title('square root')
#绘制指数函数
axes[1][0].plot(x, np.exp(x))
axes[1][0].set_title('exp')
#绘制对数函数
axes[1][1].plot(x,np.log10(x))
axes[1][1].set_title('log')
# 处理标题遮挡
plt.tight_layout()
plt.show()
小练习
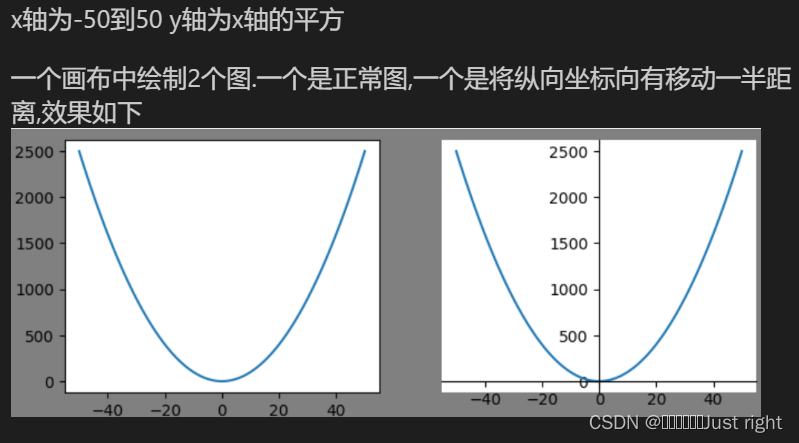
fig,axes = plt.subplots(1,2)
fig.set_figheight(3) # 实际高度 73*3
fig.set_figwidith(8) #实际宽度为 73*8
fig.set_facecolor('gray')# 设置北京
x = np.arange(-50,51)
y = x ** 2
axes[0].plot(x,y)
axes[1].spines['right'].set_color('none')
axes[1].spines['top'].set_color('none')
# data表示按数值移动,后面的数字代表挪动到y轴的刻度值
a[1].spines['bottom'].set_position(('data',0.0)
a[1].plot(x,y)
plt.show()
例子 多区域绘图
import matplotlib.pyplot as plt
import numpy as np
fig,axes=plt.subplots(2,2)
x = np.arange(1,8)
axes[0][0].plot(x,x**2)
axes[0][0].set_title('square')
axes[0][1].plot(x,np.sqrt(x))
axes[0][1].set_title('square root')
axes[1][0].plot(x, np.exp(x))
axes[1][0].set_title('exp')
axes[1][1].plot(x,np.log10(x))
axes[1][1].set_title('log')
plt.tight_layout()
plt.show()
其他元素可视化
grid 显示网格
plt.grid(True, linestyle = “–”,color = “gray”, linewidth = “0.5”,axis = ‘x’)
| 参数名称 | 描述 |
|---|---|
| linestyle | 线性 |
| color | 颜色 |
| linewidth | 宽度 |
| axis | x,y,both 显示x/y两者的格网 |
| 直接写个True也行,就是plt.grid(True) |
对坐标轴的操作
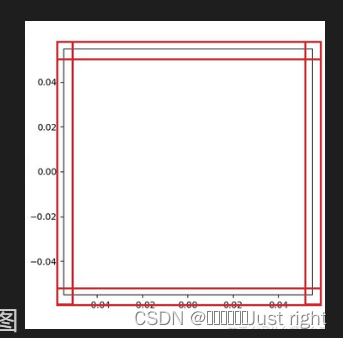
就是那几条红线
# 首先需要获取支柱
x = np.arange(-50,51)
y = x**2
ax = plt.gca() # 获取坐标轴
# 不需要右边和上面的线条
ax.spines['right'].set_color("none")
ax.spines['top'].set_color("none")
# axes:0.0 - 1.0之间的值,整个轴上的比例
ax.spines['left'].set_position(('axes',0.5))
# 移动下轴到指定位置
# 'data'表示按数值挪动,其后数字代表挪动到Y轴的刻度值
#ax.spines['bottom'].set_position(('data',0.0))
plt.ylim(0, y.max()) # 设置轴取值范围
plt.plot(x,y)
plt.show()
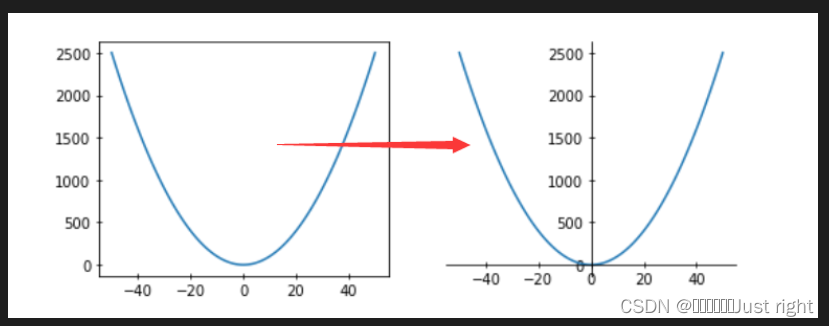
最终结果(箭头所指向的就是啦)
本人小白一个,若有错误请指出














 5053
5053











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









